Approaches for maximizing PTU utilization
Enterprises often face the challenge of efficiently managing Azure OpenAI Resources to handle varying workloads without compromising performance for high-priority tasks. This solution addresses the need for a dynamic system that can maximize the following things:
- Utilization of Azure Open AI Provisioned Throughput Units (PTUs)
- Optimal performance for critical requests
Business problem
Azure OpenAI PTUs provide dedicated capacity for processing AI workloads. The PTUs are billed for the capacity reserved, regardless of the actual usage. To maximize the value of the PTUs, it's essential to ensure that the capacity is utilized efficiently. However, the workload on the AI resources can vary significantly, with some requests being more critical than others. The challenge is to manage use of PTUs effectively while ensuring that high-priority requests are processed promptly. Therefore, it is essential to ensure efficient use of that capacity even though workload requests vary significantly with some requests being more critical (high priority) than others.
Solution overview
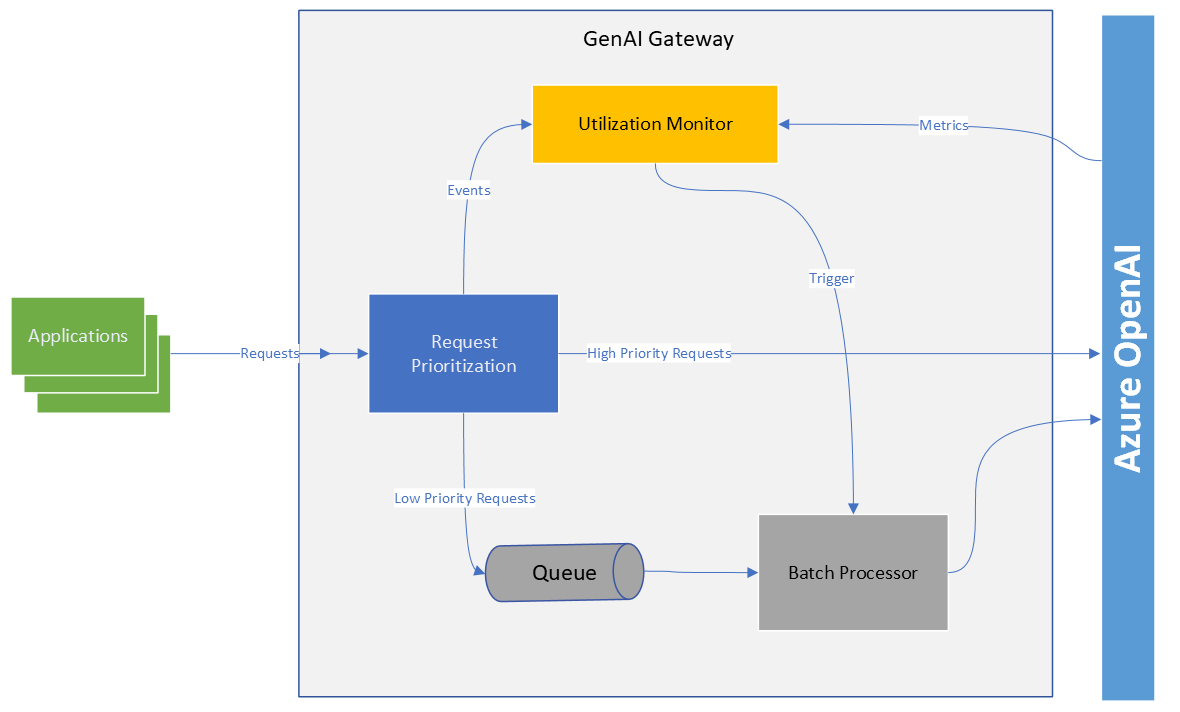
Azure API Management (APIM) can be integrated with the GenAI Gateway to route requests based on priority. Categorizing requests as high priority ensures immediate handling. Low-priority requests are queued to regulate throughput and a queue consumer processes these requests only if there's sufficient PTU capacity. If capacity diminishes, the queue consumer slows down, reducing the rate of low-priority requests. When hits a critical threshold, the queue consumer stops processing low priority requests.
The GenAI Gateway solution supports two methods for monitoring PTU utilization:
- Using Azure Monitor to track PTU utilization, adjusting throughput for low-priority requests accordingly.
- Triggering custom events from APIM that allow PTU consumption to be evaluated and updated in almost real-time.
Value proposition
The GenAI Gateway solution provides the following benefits:
- Efficient use of Azure OpenAI PTUs
- Priority handling of high-priority requests
- Dynamic adjustment of throughput based on PTU utilization
- Almost real-time monitoring of PTU utilization
Logical architecture
 |
|---|
| Figure 1: Logical Architecture |
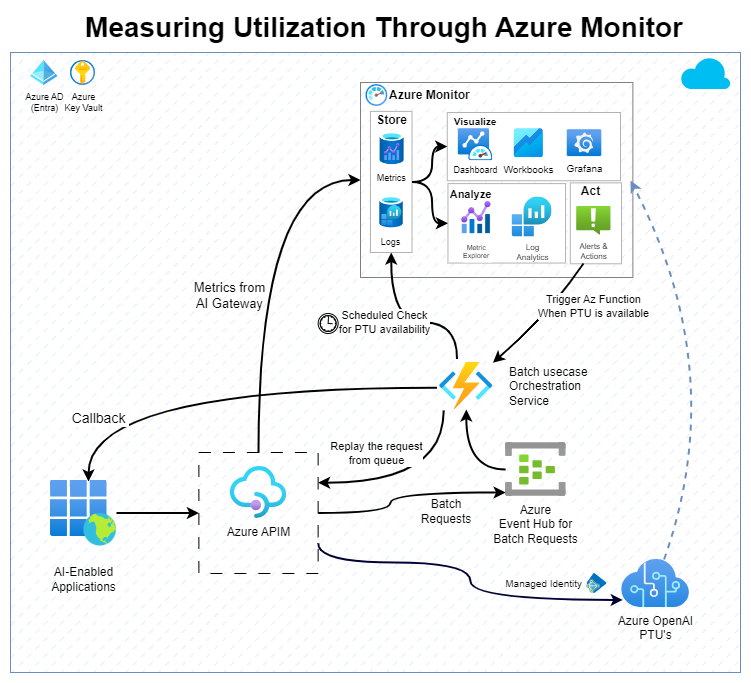
Measuring PTU utilization with Azure Monitor
 |
|---|
| Figure 2: Measuring PTU Utilization via Azure Monitor |
One approach to measure PTU utilization is by using Azure OpenAI resource capability to send metrics into Azure Monitor. The key metrics we're interested in are Azure OpenAI Requests, Processed Inference Tokens and Provision-managed Utilizations.
APIM can be used as a gateway for any calls to Azure OpenAI and manage each request based on their priority. As mentioned above, each request can be classified as high priority or low priority based on the header or the request path. All high priority requests go straight to Azure OpenAI and all low-priority requests are put into an Azure Event Hub queue. An orchestration service pulls requests from the queue when PTU capacity is available, processes the requests with Azure OpenAI, and sends the result back to the requestor.
The orchestration service can be configured to calculate available PTU capacity in one of two ways:
Azure Alert: The Azure Alerts service can monitor key metrics and notify the orchestration service when the metrics exceed a certain range. The service uses the information to determine the available capacity and adjust the rate at which low-priority requests are being processed.
Periodic check of PTU availability: The orchestration service can periodically query the Azure Metrics API to get current PTU usage. It then adjusts the throughput of low priority requests as needed.
Key considerations
When deciding which PTU measurement method to use, you should consider that there is latency in Azure Monitor data. It can take between 30 seconds and 15 minutes for metrics from Azure OpenAI resource to be ready for querying.
There is also latency in Azure Alert messages. So, this approach works well for situations where the ratio of high and low-priority requests have the following characteristics:
- the ratio changes gradually over time
- there's no need to balance the capacity in near real-time.
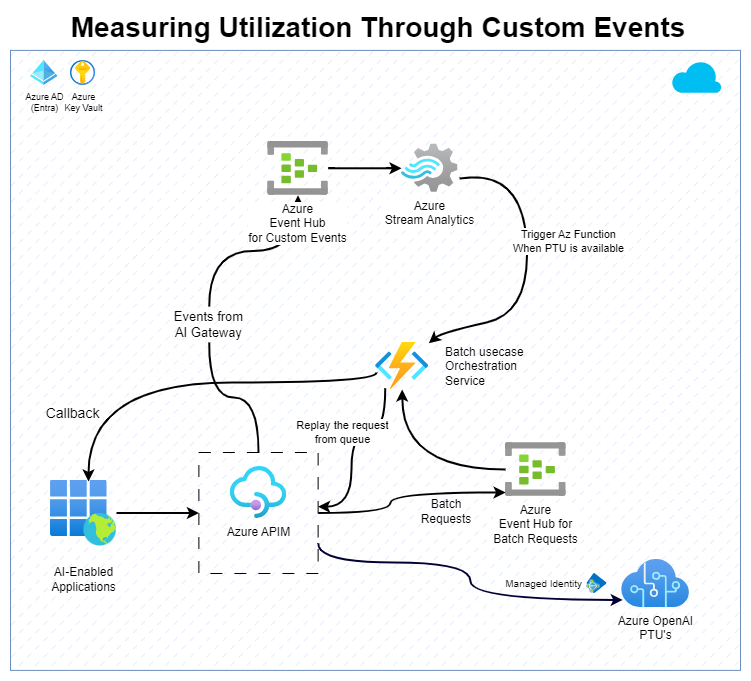
Measuring PTU utilization using custom events
If the delay in the approach using Azure Monitor isn't acceptable, an alternative approach could be to use GenAI Gateway to capture the metrics. The metrics are then processed to calculate the utilization of the PTUs.
This approach involves APIM generating custom events that count the tokens used in both input and output and sending them to Azure Event Hubs. Azure Stream Analytics can then aggregate the token usage within a specified window period to estimate the PTU consumption. Azure Stream Analytics can then store the consumption in a state store that can be accessed by the orchestration service to regulate its throughput. This approach will let near real-time balancing of PTU utilization between different priorities messages.
 |
|---|
| Figure 3: Measuring PTU Utilization through custom events |
Key considerations
It's important to remember that the utilization calculation is performed by a different system than Azure OpenAI Metrics. Having a different system perform utilization calculation means that the calculated utilization won't be the same. To allow for differences, the gateway and orchestration service should take these differences into account and allow for enough buffer to avoid a rate limiting error from Azure OpenAI Service.
Graceful degradation of throughput of low-priority requests
After computing the utilization of PTU with either one of the two methods, orchestration service should reduce the number of low-priority requests being processed as the utilization goes up. Reducing the number of low-priority requests being processed frees PTUs for high-priority processing.
Here are the steps the solution uses to allocate PTU capacity among different priority levels of requests:
- Determine the maximum number of low priority requests that can be processed simultaneously without compromising the high priority ones, based on the demand trends and potential peaks of our organization.
- Define a lower and upper limit for low-priority PTU consumption. These limits are used to regulate throughput of low priority requests depending on available capacity.
- Change the pace of low priority requests according to the PTU consumption. When consumption is below the lower limit, it processes at the highest speed. When the consumption is between the lower and upper limits, it reduces the speed. When the consumption is above the upper limit, it pauses processing. The upper limit acts as a cushion to avoid being throttled by Azure OpenAI service.
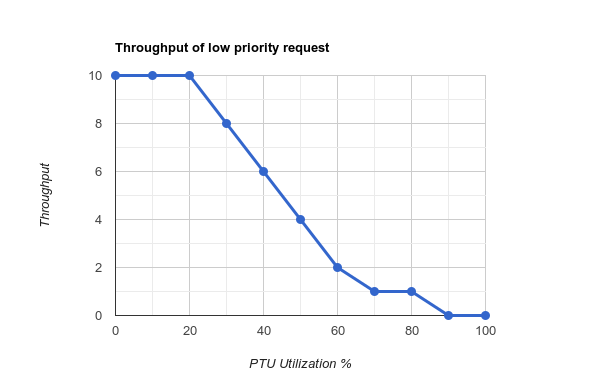
For example, suppose it can handle up to 10 low-priority requests at the same time. And set our lower limit at 20% with the upper limit at 90% of total PTU consumption. Then it decreases the number of low priority requests processed concurrently when PTU consumption exceeds 20% and stops when it reaches 90%. This example is illustrated below.
 |
|---|
| Figure 4: Throughput graph |