The deployment pipelines process
The deployment process lets you clone content from one stage in the deployment pipeline to another, typically from development to test, and from test to production.
During deployment, Microsoft Fabric copies the content from the source stage to the target stage. The connections between the copied items are kept during the copy process. Fabric also applies the configured deployment rules to the updated content in the target stage. Deploying content might take a while, depending on the number of items being deployed. During this time, you can navigate to other pages in the portal, but you can't use the content in the target stage.
You can also deploy content programmatically, using the deployment pipelines REST APIs. You can learn more about this process in Automate your deployment pipeline using APIs and DevOps.
Note
The new Deployment pipeline user interface is currently in preview. To turn on or use the new UI, see Begin using the new UI.
There are two main parts of the deployment pipelines process:
Define the deployment pipeline structure
When you create a pipeline, you define how many stages you want and what they should be called. You can also make one or more stages public. The number of stages and their names are permanent, and can't be changed after the pipeline is created. However, you can change the public status of a stage at any time.
To define a pipeline, follow the instructions in Create a deployment pipeline.
Add content to the stages
You can add content to a pipeline stage in two ways:
Assign a workspace to an empty stage
When you assign content to an empty stage, a new workspace is created on a capacity for the stage you deploy to. All the metadata in the reports, dashboards, and semantic models of the original workspace is copied to the new workspace in the stage you're deploying to.
After the deployment is complete, refresh the semantic models so that you can use the newly copied content. The semantic model refresh is required because data isn't copied from one stage to another. To understand which item properties are copied during the deployment process, and which item properties aren't copied, review the item properties copied during deployment section.
For instructions on how to assign and unassign workspaces to deployment pipeline stages, see Assign a workspace to a Microsoft Fabric deployment pipeline.
Create a workspace
The first time you deploy content, deployment pipelines checks if you have permissions.
If you have permissions, the content of the workspace is copied to the stage you're deploying to, and a new workspace for that stage is created on the capacity.
If you don't have permissions, the workspace is created but the content isn’t copied. You can ask a capacity admin to add your workspace to a capacity, or ask for assignment permissions for the capacity. Later, when the workspace is assigned to a capacity, you can deploy content to this workspace.
If you're using Premium Per User (PPU), your workspace is automatically associated with your PPU. In such cases, permissions aren't required. However, if you create a workspace with a PPU, only other PPU users can access it. In addition, only PPU users can consume content created in such workspaces.
Workspace and content ownership
The deploying user automatically becomes the owner of the cloned semantic models, and the only admin of the new workspace.
Deploy content from one stage to another
There are several ways to deploy content from one stage to another. You can deploy all the content, or you can select which items to deploy.
You can deploy content to any adjacent stage, in either direction.
Deploying content from a working production pipeline to a stage that has an existing workspace, includes the following steps:
Deploying new content as an addition to the content already there.
Deploying updated content to replace some of the content already there.
Deployment process
When content from the source stage is copied to the target stage, Fabric identifies existing content in the target stage and overwrites it. To identify which content item needs to be overwritten, deployment pipelines uses the connection between the parent item and its clones. This connection is kept when new content is created. The overwrite operation only overwrites the content of the item. The item's ID, URL, and permissions remain unchanged.
In the target stage, item properties that aren't copied, remain as they were before deployment. New content and new items are copied from the source stage to the target stage.
Autobinding
In Fabric, when items are connected, one of the items depends on the other. For example, a report always depends on the semantic model it's connected to. A semantic model can depend on another semantic model, and can also be connected to several reports that depend on it. If there's a connection between two items, deployment pipelines always tries to maintain this connection.
Autobinding in the same workspace
During deployment, deployment pipelines checks for dependencies. The deployment either succeeds or fails, depending on the location of the item that provides the data that the deployed item depends on.
Linked item exists in the target stage - Deployment pipelines automatically connect (autobind) the deployed item to the item it depends on in the deployed stage. For example, if you deploy a paginated report from development to test, and the report is connected to a semantic model that was previously deployed to the test stage, it automatically connects to the semantic model in the test stage.
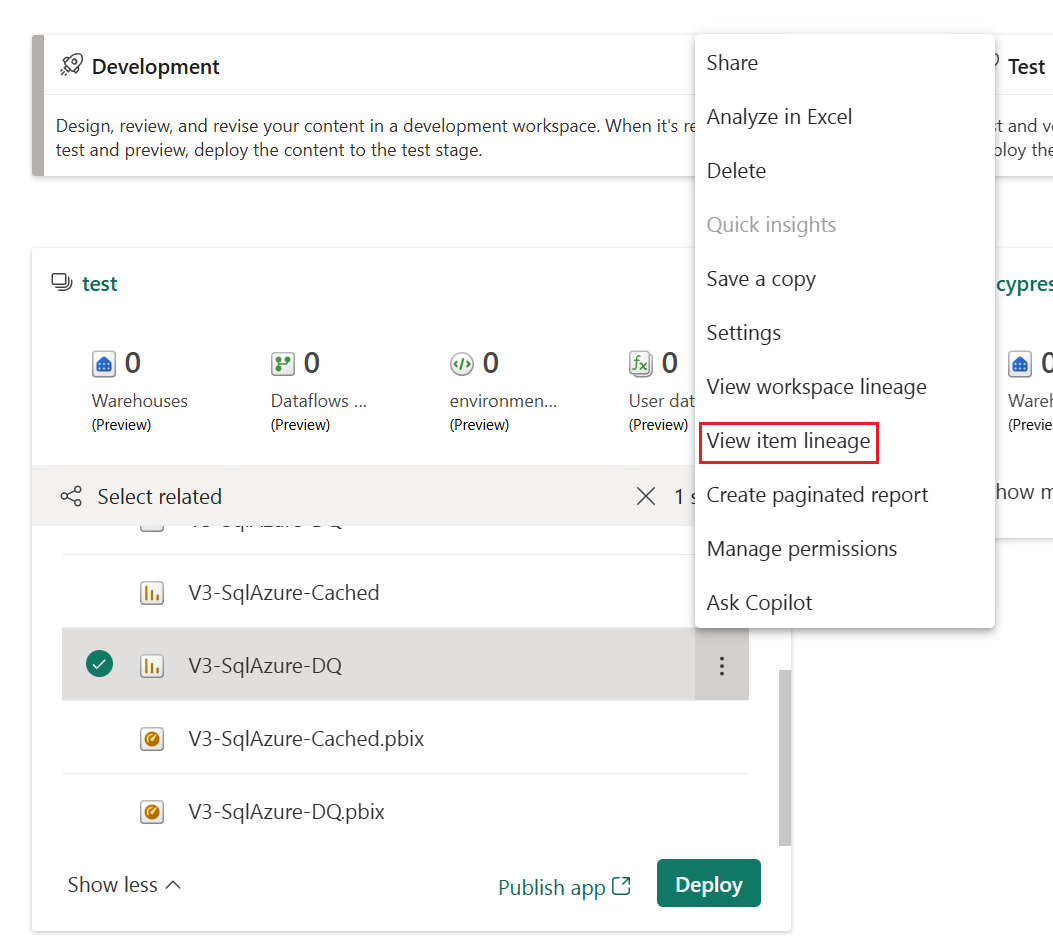
Linked item doesn't exist in the target stage - Deployment pipelines fail a deployment if an item has a dependency on another item, and the item providing the data isn't deployed and doesn't reside in the target stage. For example, if you deploy a report from development to test, and the test stage doesn't contain its semantic model, the deployment fails. To avoid failed deployments due to dependent items not being deployed, use the Select related button. Select related automatically selects all the related items that provide dependencies to the items you're about to deploy.
Autobinding works only with items that are supported by deployment pipelines and reside within Fabric. To view the dependencies of an item, from the item's More options menu, select View lineage.
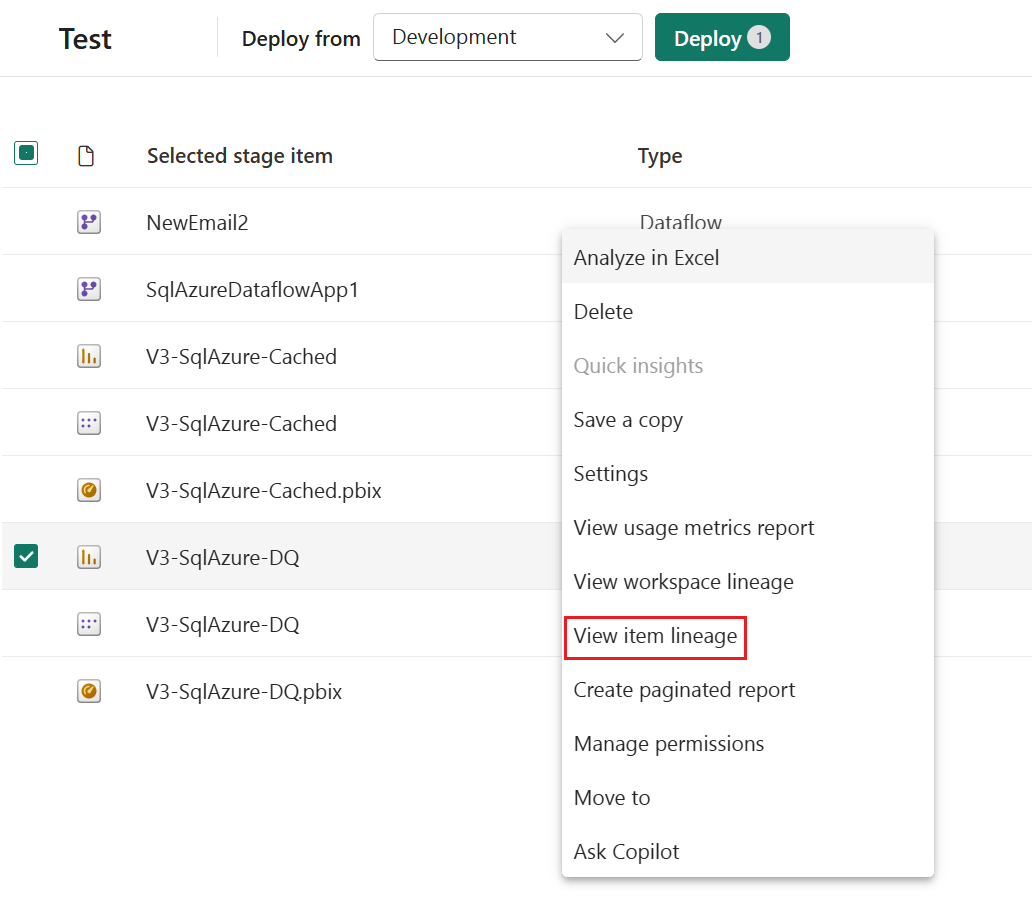
Autobinding across workspaces
Deployment pipelines automatically binds items that are connected across pipelines, if they're in the same pipeline stage. When you deploy such items, deployment pipelines attempts to establish a new connection between the deployed item and the item it's connected to in the other pipeline. For example, if you have a report in the test stage of pipeline A that's connected to a semantic model in the test stage of pipeline B, deployment pipelines recognizes this connection.
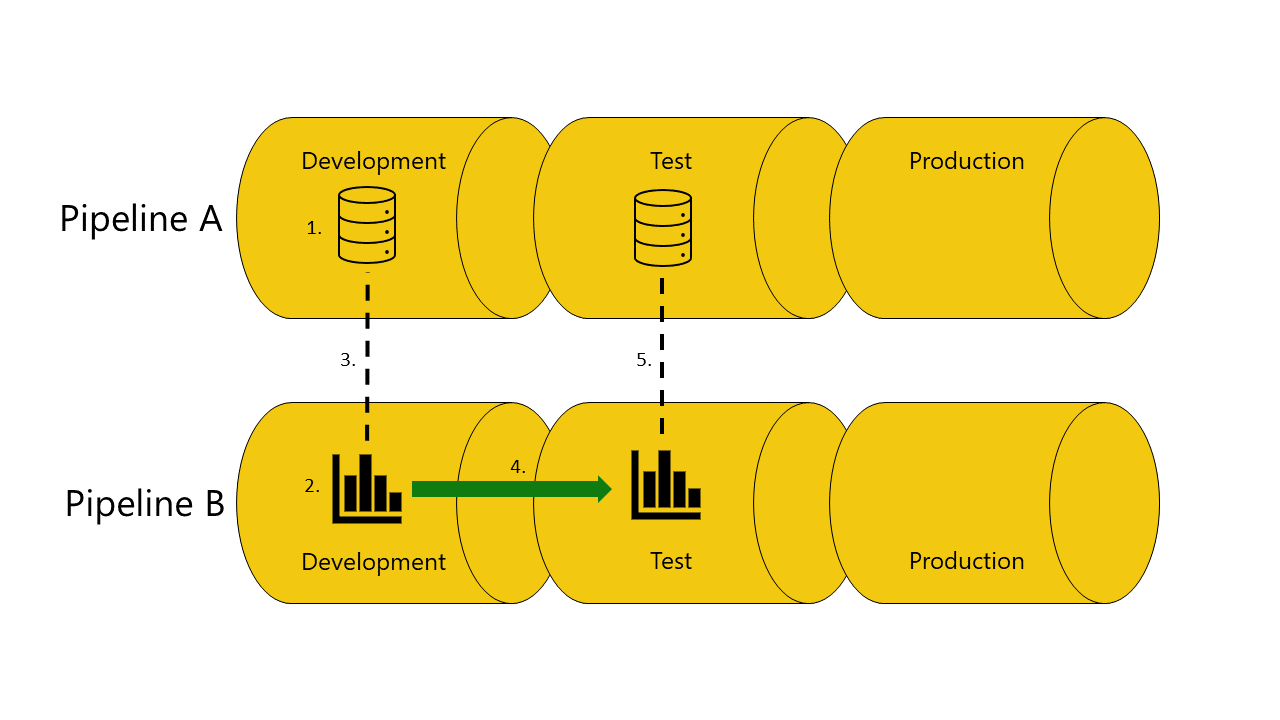
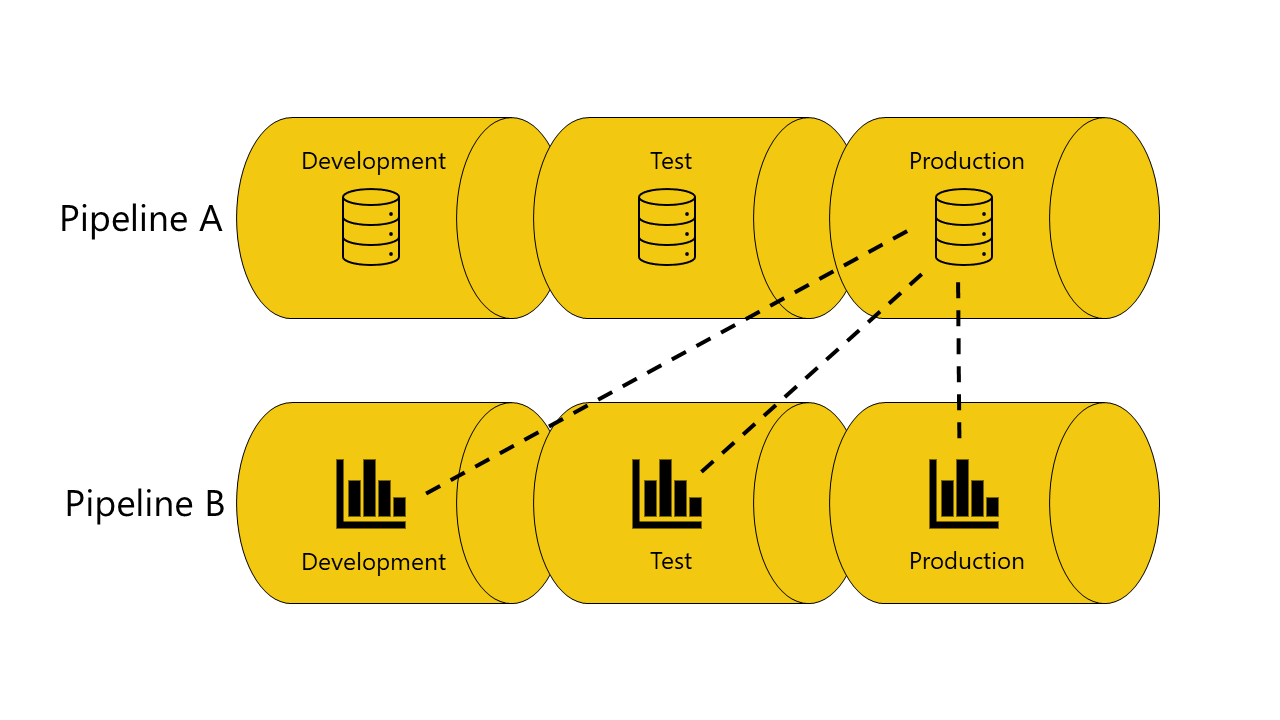
Here's an example with illustrations that to help demonstrate how autobinding across pipelines works:
You have a semantic model in the development stage of pipeline A.
You also have a report in the development stage of pipeline B.
Your report in pipeline B is connected to your semantic model in pipeline A. Your report depends on this semantic model.
You deploy the report in pipeline B from the development stage to the test stage.
The deployment succeeds or fails, depending on whether or not you have a copy of the semantic model it depends on in the test stage of pipeline A:
If you have a copy of the semantic model the report depends on in the test stage of pipeline A:
The deployment succeeds, and deployment pipelines connects (autobind) the report in the test stage of pipeline B, to the semantic model in the test stage of pipeline A.
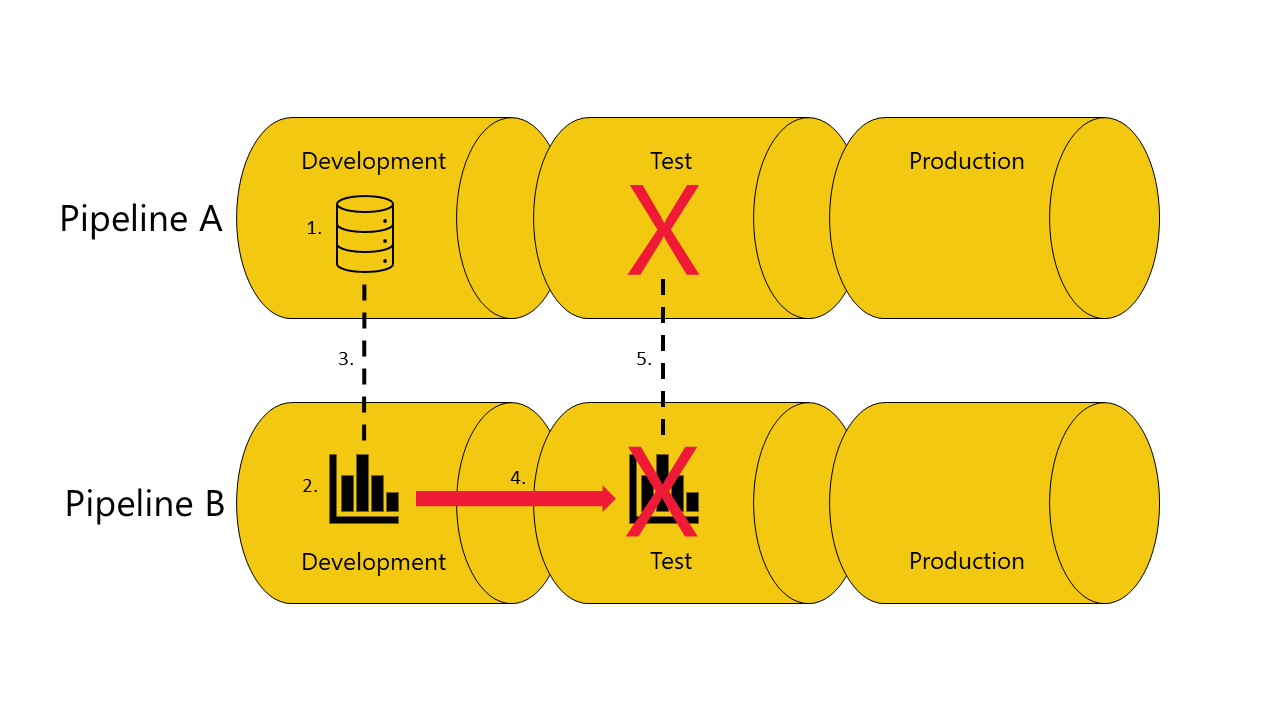
If you don't have a copy of the semantic model the report depends on in the test stage of pipeline A:
The deployment fails because deployment pipelines can't connect (autobind) the report in the test stage in pipeline B, to the semantic model it depends on in the test stage of pipeline A.
Avoid using autobinding
In some cases, you might not want to use autobinding. For example, if you have one pipeline for developing organizational semantic models, and another for creating reports. In this case, you might want all the reports to always be connected to semantic models in the production stage of the pipeline they belong to. In this case, avoid using the autobinding feature.
There are three methods you can use to avoid using autobinding:
Don't connect the item to corresponding stages. When the items aren't connected in the same stage, deployment pipelines keeps the original connection. For example, if you have a report in the development stage of pipeline B that's connected to a semantic model in the production stage of pipeline A. When you deploy the report to the test stage of pipeline B, it remains connected to the semantic model in the production stage of pipeline A.
Define a parameter rule. This option isn't available for reports. You can only use it with semantic models and dataflows.
Connect your reports, dashboards, and tiles to a proxy semantic model or dataflow that isn't connected to a pipeline.
Autobinding and parameters
Parameters can be used to control the connections between semantic models or dataflows and the items that they depend on. When a parameter controls the connection, autobinding after deployment doesn't take place, even when the connection includes a parameter that applies to the semantic model’s or dataflow's ID, or the workspace ID. In such cases, you'll need to rebind the items after the deployment by changing the parameter value, or by using parameter rules.
Note
If you're using parameter rules to rebind items, the parameters must be of type Text.
Refreshing data
Data in the target item, such as a semantic model or dataflow, is kept when possible. If there are no changes to an item that holds the data, the data is kept as it was before the deployment.
In many cases, when you have a small change such as adding or removing a table, Fabric keeps the original data. For breaking schema changes, or changes in the data source connection, a full refresh is required.
Requirements for deploying to a stage with an existing workspace
Any licensed user who's a contributor of both the target and source deployment workspaces, can deploy content that resides on a capacity to a stage with an existing workspace. For more information, review the permissions section.
Folders in deployment pipelines (preview)
Folders enable users to efficiently organize and manage workspace items in a familiar way. When you deploy content that contains folders to a different stage, the folder hierarchy of the applied items is automatically applied.
Folders representation
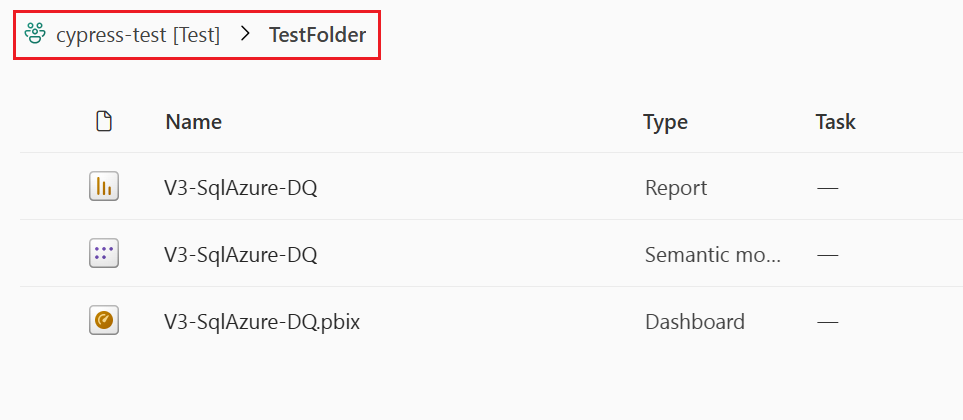
The workspace content is shown as it's structured in the workspace. Folders are listed, and in order to see their items you need to select the folder. An item’s full path is shown at the top of the items list. Since a deployment is of items only, you can only select a folder that contains supported items. Selecting a folder for deployment means selecting all its items and subfolders with their items for a deployment.
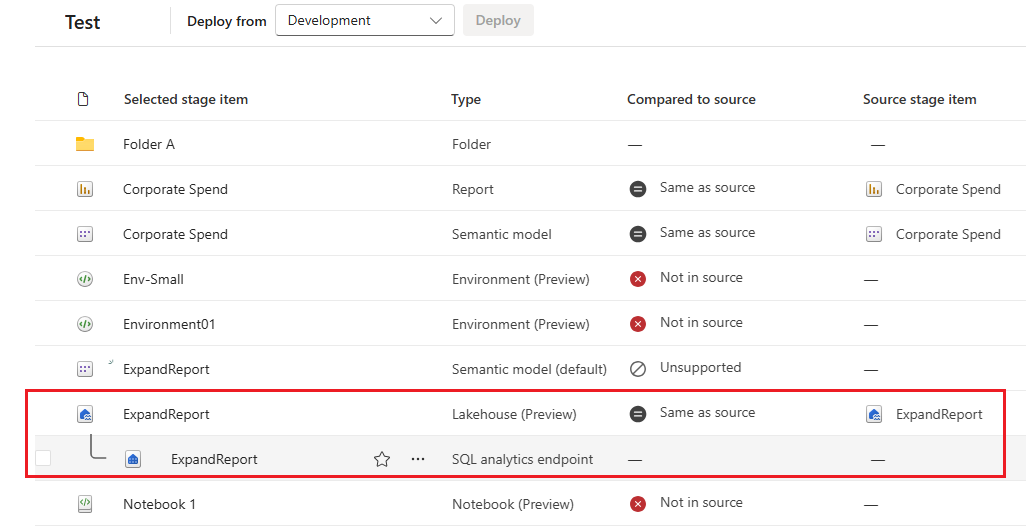
This picture shows the contents of a folder inside the workspace. The full pathname of the folder is shown at the top of the list.
In Deployment pipelines, folders are considered part of an item’s name (an item name includes its full path). When an item is deployed, after its path was changed (moved from folder A to folder B, for example), then Deployment pipelines applies this change to its paired item during deployment - the paired item will be moved as well to folder B. If folder B doesn't exist in the stage we're deploying to, it's created in its workspace first. Folders can be seen and managed only on the workspace page.
Deploy items inside a folder from that folder. You can't deploy items from different hierarchies at the same time.
Identify items that were moved to different folders
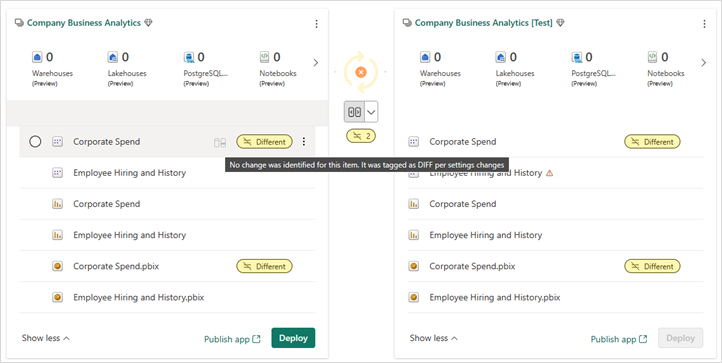
Since folders are considered part of the item’s name, items moved into a different folder in the workspace, are identified on Deployment pipelines page as Different when compared. This item doesn't appear in the compare window since it isn't a schema change but settings change.

Individual folders can't be deployed manually in deployment pipelines. Their deployment is triggered automatically when at least one of their items is deployed.
The folder hierarchy of paired items is updated only during deployment. During assignment, after the pairing process, the hierarchy of paired items isn't updated yet.
Since a folder is deployed only if one of its items is deployed, an empty folder can't be deployed.
Deploying one item out of several in a folder also updates the structure of the items that aren't deployed in the target stage even though the items themselves aren't be deployed.
Parent-child item representation
These appear only in the new UI. Looks same as in the workspace. Child isn't deployed but recreated on the target stage
Item properties copied during deployment
For a list of supported items, see Deployment pipelines supported items.
During deployment, the following item properties are copied and overwrite the item properties at the target stage:
Data sources (deployment rules are supported)
Parameters (deployment rules are supported)
Report visuals
Report pages
Dashboard tiles
Model metadata
Item relationships
Sensitivity labels are copied only when one of the following conditions is met. If these conditions aren't met, sensitivity labels aren't copied during deployment.
A new item is deployed, or an existing item is deployed to an empty stage.
Note
In cases where default labeling is enabled on the tenant, and the default label is valid, if the item being deployed is a semantic model or dataflow, the label is copied from the source item only if the label has protection. If the label isn't protected, the default label is applied to the newly created target semantic model or dataflow.
The source item has a label with protection and the target item doesn't. In this case, a pop-up window asks for consent to override the target sensitivity label.
Item properties that are not copied
The following item properties aren't copied during deployment:
Data - Data isn't copied. Only metadata is copied
URL
ID
Permissions - For a workspace or a specific item
Workspace settings - Each stage has its own workspace
App content and settings - To update your apps, see Update content to Power BI apps
The following semantic model properties are also not copied during deployment:
Role assignment
Refresh schedule
Data source credentials
Query caching settings (can be inherited from the capacity)
Endorsement settings
Supported semantic model features
Deployment pipelines supports many semantic model features. This section lists two semantic model features that can enhance your deployment pipelines experience:
Incremental refresh
Deployment pipelines supports incremental refresh, a feature that allows large semantic models faster and more reliable refreshes, with lower consumption.
With deployment pipelines, you can make updates to a semantic model with incremental refresh while retaining both data and partitions. When you deploy the semantic model, the policy is copied along.
To understand how incremental refresh behaves with dataflows, see why do I see two data sources connected to my dataflow after using dataflow rules?
Note
Incremental refresh settings aren't copied in Gen 1.
Activating incremental refresh in a pipeline
To enable incremental refresh, configure it in Power BI Desktop, and then publish your semantic model. After you publish, the incremental refresh policy is similar across the pipeline, and can be authored only in Power BI Desktop.
Once your pipeline is configured with incremental refresh, we recommend that you use the following flow:
Make changes to your .pbix file in Power BI Desktop. To avoid long waiting times, you can make changes using a sample of your data.
Upload your .pbix file to the first (usually development) stage.
Deploy your content to the next stage. After deployment, the changes you made will apply to the entire semantic model you're using.
Review the changes you made in each stage, and after you verify them, deploy to the next stage until you get to the final stage.
Usage examples
The following are a few examples of how you can integrate incremental refresh with deployment pipelines.
Create a new pipeline and connect it to a workspace with a semantic model that has incremental refresh enabled.
Enable incremental refresh in a semantic model that's already in a development workspace.
Create a pipeline from a production workspace that has a semantic model that uses incremental refresh. For example, assign the workspace to a new pipeline's production stage, and use backwards deployment to deploy to the test stage, and then to the development stage.
Publish a semantic model that uses incremental refresh to a workspace that's part of an existing pipeline.
Incremental refresh limitations
For incremental refresh, deployment pipelines only supports semantic models that use enhanced semantic model metadata. All semantic models created or modified with Power BI Desktop automatically implement enhanced semantic model metadata.
When republishing a semantic model to an active pipeline with incremental refresh enabled, the following changes result in deployment failure due to data loss potential:
Republishing a semantic model that doesn't use incremental refresh, to replace a semantic model that has incremental refresh enabled.
Renaming a table that has incremental refresh enabled.
Renaming noncalculated columns in a table with incremental refresh enabled.
Other changes such as adding a column, removing a column, and renaming a calculated column, are permitted. However, if the changes affect the display, you need to refresh before the change is visible.
Composite models
Using composite models you can set up a report with multiple data connections.
You can use the composite models functionality to connect a Fabric semantic model to an external semantic model such as Azure Analysis Services. For more information, see Using DirectQuery for Fabric semantic models and Azure Analysis Services.
In a deployment pipeline, you can use composite models to connect a semantic model to another Fabric semantic model external to the pipeline.
Automatic aggregations
Automatic aggregations are built on top of user defined aggregations and use machine learning to continuously optimize DirectQuery semantic models for maximum report query performance.
Each semantic model keeps its automatic aggregations after deployment. Deployment pipelines doesn't change a semantic model's automatic aggregation. This means that if you deploy a semantic model with an automatic aggregation, the automatic aggregation in the target stage remains as is, and isn't overwritten by the automatic aggregation deployed from the source stage.
To enable automatic aggregations, follow the instructions in configure the automatic aggregation.
Hybrid tables
Hybrid tables are tables with incremental refresh that can have both import and direct query partitions. During a clean deployment, both the refresh policy and the hybrid table partitions are copied. When you're deploying to a pipeline stage that already has hybrid table partitions, only the refresh policy is copied. To update the partitions, refresh the table.
Update content to Power BI apps
Power BI apps are the recommended way of distributing content to free Fabric consumers. You can update the content of your Power BI apps using a deployment pipeline, giving you more control and flexibility when it comes to your app's lifecycle.
Create an app for each deployment pipeline stage, so that you can test each update from an end user's point of view. Use the publish or view button in the workspace card to publish or view the app in a specific pipeline stage.
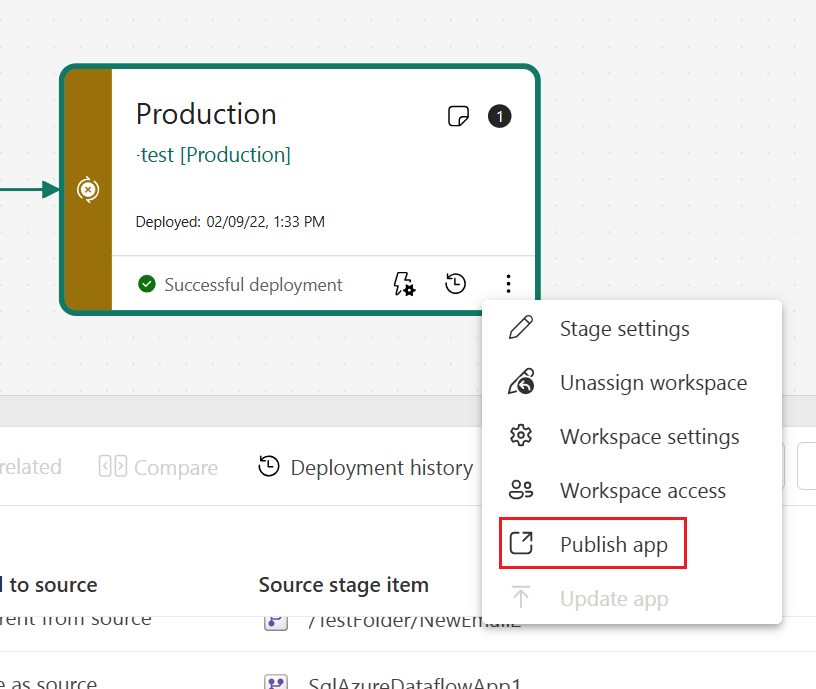

In the production stage, you can also update the app page in Fabric, so that any content updates become available to app users.

Important
The deployment process doesn't include updating the app content or settings. To apply changes to content or settings, you need to manually update the app in the required pipeline stage.
Permissions
Permissions are required for the pipeline, and for the workspaces that are assigned to it. Pipeline permissions and workspace permissions are granted and managed separately.
Pipelines only have one permission, Admin, which is required for sharing, editing and deleting a pipeline.
Workspaces have different permissions, also called roles. Workspace roles determine the level of access to a workspace in a pipeline.
Deployment pipelines doesn't support Microsoft 365 groups as pipeline admins.
To deploy from one stage to another in the pipeline, you must be a pipeline admin, and either a contributor, member, or admin of the workspaces assigned to the stages involved. For example, a pipeline admin that isn't assigned a workspace role, can view the pipeline and share it with others. However, this user can't view the content of the workspace in the pipeline, or in the service, and can't perform deployments.
Permissions table
This section describes the deployment pipeline permissions. The permissions listed in this section might have different applications in other Fabric features.
The lowest deployment pipeline permission is pipeline admin, and it's required for all deployment pipeline operations.
| User | Pipeline permissions | Comments |
|---|---|---|
| Pipeline admin |
|
Pipeline access doesn't grant permissions to view or take actions on the workspace content. |
| Workspace viewer (and pipeline admin) |
|
Workspace members assigned the Viewer role without build permissions, can't access the semantic model or edit workspace content. |
| Workspace contributor (and pipeline admin) |
|
|
| Workspace member (and pipeline admin) |
|
If the block republish and disable package refresh setting located in the tenant semantic model security section is enabled, only semantic model owners are able to update semantic models. |
| Workspace admin (and pipeline admin) |
|
Granted permissions
When you're deploying Power BI items, the ownership of the deployed item might change. Review the following table to understand who can deploy each item and how the deployment affects the item's ownership.
| Fabric Item | Required permission to deploy an existing item | Item ownership after a first time deployment | Item ownership after deployment to a stage with the item |
|---|---|---|---|
| Semantic model | Workspace member | The user who made the deployment becomes the owner | Unchanged |
| Dataflow | Dataflow owner | The user who made the deployment becomes the owner | Unchanged |
| Datamart | Datamart owner | The user who made the deployment becomes the owner | Unchanged |
| Paginated report | Workspace member | The user who made the deployment becomes the owner | The user who made the deployment becomes the owner |
Required permissions for popular actions
The following table lists required permissions for popular deployment pipeline actions. Unless specified otherwise, for each action you need all the listed permissions.
| Action | Required permissions |
|---|---|
| View the list of pipelines in your organization | No license required (free user) |
| Create a pipeline | A user with one of the following licenses:
|
| Delete a pipeline | Pipeline admin |
| Add or remove a pipeline user | Pipeline admin |
| Assign a workspace to a stage |
|
| Unassign a workspace to a stage | One of the following roles:
|
| Deploy to an empty stage (see note) |
|
| Deploy items to the next stage (see note) |
|
| View or set a rule |
|
| Manage pipeline settings | Pipeline admin |
| View a pipeline stage |
|
| View the list of items in a stage | Pipeline admin |
| Compare two stages |
|
| View deployment history | Pipeline admin |
Note
To deploy content in the GCC environment, you need to be at least a member of both the source and target workspace. Deploying as a contributor isn't supported yet.
Considerations and limitations
This section lists most of the limitations in deployment pipelines.
- The workspace must reside on a Fabric capacity.
- The maximum number of items that can be deployed in a single deployment is 300.
- Downloading a .pbix file after deployment isn't supported.
- Microsoft 365 groups aren't supported as pipeline admins.
- When you deploy a Power BI item for the first time, if another item in the target stage has the same name and type (for example, if both files are reports), the deployment fails.
- For a list of workspace limitations, see the workspace assignment limitations.
- For a list of supported items, see supported items. Any item not on the list isn't supported.
- The deployment fails if any of the items have circular or self dependencies (for example, item A references item B and item B references item A).
- PBIR reports aren't supported.
Semantic model limitations
Datasets that use real-time data connectivity can't be deployed.
A semantic model with DirectQuery or Composite connectivity mode that uses variation or auto date/time tables, isn’t supported. For more information, see What can I do if I have a dataset with DirectQuery or Composite connectivity mode, that uses variation or calendar tables?.
During deployment, if the target semantic model is using a live connection, the source semantic model must use this connection mode too.
After deployment, downloading a semantic model (from the stage it was deployed to) isn't supported.
For a list of deployment rule limitations, see deployment rules limitations.
If autobinding is engaged, then:
- Native query and DirectQuery together isn't supported. This includes proxy datasets.
- The datasource connection must be the first step in the mashup expression.
When a Direct Lake semantic model is deployed, it doesn't automatically bind to items in the target stage. For example, if a LakeHouse is a source for a DirectLake semantic model and they're both deployed to the next stage, the DirectLake semantic model in the target stage will still be bound to the LakeHouse in the source stage. Use datasource rules to bind it to an item in the target stage. Other types of semantic models are automatically bound to the paired item in the target stage.
Dataflow limitations
Incremental refresh settings aren't copied in Gen 1.
When you're deploying a dataflow to an empty stage, deployment pipelines creates a new workspace and sets the dataflow storage to a Fabric blob storage. Blob storage is used even if the source workspace is configured to use Azure data lake storage Gen2 (ADLS Gen2).
Service principal isn't supported for dataflows.
Deploying common data model (CDM) isn't supported.
For deployment pipeline rule limitations that affect dataflows, see Deployment rules limitations.
If a dataflow is being refreshed during deployment, the deployment fails.
If you compare stages during a dataflow refresh, the results are unpredictable.
Datamart limitations
You can't deploy a datamart with sensitivity labels.
You need to be the datamart owner to deploy a datamart.