Χρήση Tidyverse
Το Tidyverse είναι μια συλλογή πακέτων R που χρησιμοποιούν συνήθως οι επιστήμονες δεδομένων σε καθημερινές αναλύσεις δεδομένων. Περιλαμβάνει πακέτα για την εισαγωγή δεδομένων (readr), την απεικόνιση δεδομένων (ggplot2), τον χειρισμό δεδομένων (dplyr, ), tidyrτον συναρτησιακό προγραμματισμό (purrr) και τη δημιουργία μοντέλων (tidymodels) κ.λπ. Τα πακέτα στο tidyverse έχουν σχεδιαστεί για να συνεργάζονται απρόσκοπτα και να ακολουθούν ένα συνεπές σύνολο αρχών σχεδίασης.
Το Microsoft Fabric διανέμει την πιο πρόσφατη σταθερή έκδοση του tidyverse με κάθε έκδοση χρόνου εκτέλεσης. Εισαγάγετε και ξεκινήστε να χρησιμοποιείτε τα γνωστά πακέτα R σας.
Προαπαιτούμενα στοιχεία
Λάβετε μια συνδρομή Microsoft Fabric. Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση του Microsoft Fabric.
Εισέλθετε στο Microsoft Fabric.
Χρησιμοποιήστε την εναλλαγή εμπειρίας στην κάτω αριστερή πλευρά της αρχικής σελίδας σας για να μεταβείτε σε Fabric.

Ανοίξτε ή δημιουργήστε ένα σημειωματάριο. Για να μάθετε τον τρόπο, ανατρέξτε στο θέμα Τρόπος χρήσης σημειωματάριων Microsoft Fabric.
Ορίστε την επιλογή γλώσσας σε SparkR (R) για να αλλάξετε την κύρια γλώσσα.
Επισυνάψτε το σημειωματάριό σας σε ένα lakehouse. Στην αριστερή πλευρά, επιλέξτε Προσθήκη για να προσθέσετε μια υπάρχουσα λίμνη ή για να δημιουργήσετε μια λίμνη.
Φορτίο tidyverse
# load tidyverse
library(tidyverse)
Εισαγωγή δεδομένων
readr Το είναι ένα πακέτο R που παρέχει εργαλεία για την ανάγνωση ορθογώνιων αρχείων δεδομένων, όπως αρχεία CSV, TSV και σταθερού πλάτους.
readr Παρέχει έναν γρήγορο και φιλικό τρόπο ανάγνωσης ορθογώνιων αρχείων δεδομένων, όπως η παροχή συναρτήσεων read_csv() και read_tsv() για την ανάγνωση αρχείων CSV και TSV αντίστοιχα.
Ας δημιουργήσουμε πρώτα ένα R data.frame, θα το γράψουμε στο lakehouse χρησιμοποιώντας readr::write_csv() το και θα το διαβάσουμε ξανά με readr::read_csv()το .
Σημείωμα
Για να αποκτήσετε πρόσβαση σε αρχεία Lakehouse χρησιμοποιώντας readrτο , πρέπει να χρησιμοποιήσετε τη διαδρομή API αρχείου. Στην εξερεύνηση Lakehouse, κάντε δεξί κλικ στο αρχείο ή στον φάκελο στον οποίο θέλετε να αποκτήσετε πρόσβαση και να αντιγράψετε τη διαδρομή του API αρχείου από το μενού περιβάλλοντος.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Στη συνέχεια, ας γράψουμε τα δεδομένα στο lakehouse χρησιμοποιώντας τη διαδρομή API Αρχείο.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Διαβάστε τα δεδομένα από το Lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Τακτοποιημένα δεδομένα
tidyr Το είναι ένα πακέτο R που παρέχει εργαλεία για εργασία με ακατάστατα δεδομένα. Οι κύριες συναρτήσεις στο tidyr έχουν σχεδιαστεί για να σας βοηθήσουν να αναδιαμορφώσετε τα δεδομένα σε τακτοποιημένη μορφή. Τα τακτοποιημένα δεδομένα έχουν μια συγκεκριμένη δομή όπου κάθε μεταβλητή είναι μια στήλη και κάθε παρατήρηση είναι μια γραμμή, το οποίο διευκολύνει την εργασία με δεδομένα της R και άλλων εργαλείων.
Για παράδειγμα, η gather() συνάρτηση στο tidyr μπορεί να χρησιμοποιηθεί για τη μετατροπή μεγάλων δεδομένων σε δεδομένα μεγάλου μήκους. Ακολουθεί ένα παράδειγμα:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Συναρτησιακός προγραμματισμός
purrr Το είναι ένα πακέτο R που ενισχύει το κιτ εργαλείων λειτουργικού προγραμματισμού της R, παρέχοντας ένα πλήρες και συνεπές σύνολο εργαλείων για εργασία με συναρτήσεις και διανύσματα. Το καλύτερο μέρος για να ξεκινήσετε purrr είναι η οικογένεια συναρτήσεων map() που σας επιτρέπουν να αντικαταστήσετε πολλές για βρόχους με κώδικα που είναι πιο συνοπτικός και πιο ευανάγνωστος. Ακολουθεί ένα παράδειγμα χρήσης map() για την εφαρμογή μιας συνάρτησης σε κάθε στοιχείο μιας λίστας:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Χειρισμός δεδομένων
dplyr Το είναι ένα πακέτο R που παρέχει ένα συνεπές σύνολο ρημάτων που σας βοηθούν να επιλύσετε τα πιο συνηθισμένα προβλήματα χειρισμού δεδομένων, όπως η επιλογή μεταβλητών με βάση τα ονόματα, η επιλογή υποθέσεων με βάση τις τιμές, η μείωση πολλών τιμών σε μία σύνοψη και η αλλαγή της σειράς των γραμμών κ.λπ. Δείτε ορισμένα παραδείγματα:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Απεικόνιση δεδομένων
ggplot2 Το είναι ένα πακέτο R για τη δηλωτική δημιουργία γραφικών στοιχείων, με βάση τη Γραμματική των γραφικών. Μπορείτε να καταχωρήσετε τα δεδομένα, να πείτε ggplot2 πώς να αντιστοιχίζετε μεταβλητές στην αισθητική, ποια στοιχειώδη γραφικά θα χρησιμοποιήσετε και φροντίζει για τις λεπτομέρειες. Ακολουθούν μερικά παραδείγματα:
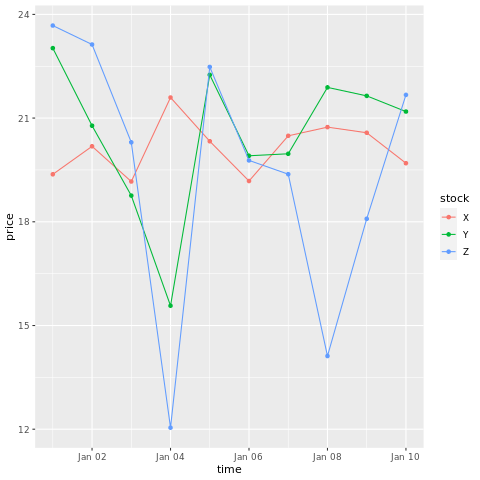
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
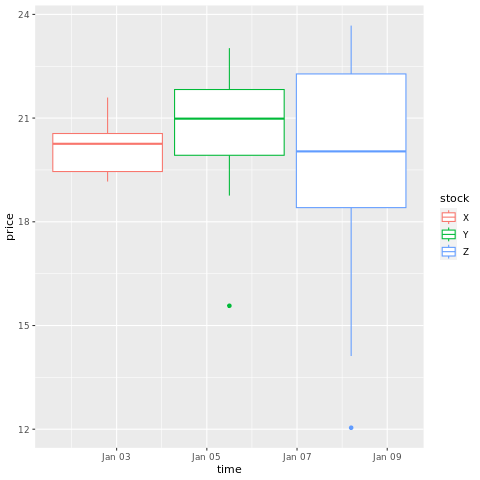
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Δόμηση μοντέλου
Το tidymodels πλαίσιο είναι μια συλλογή πακέτων για μοντελοποίηση και εκμάθηση μηχανής με χρήση tidyverse αρχών. Καλύπτει μια λίστα με βασικά πακέτα για μια μεγάλη ποικιλία εργασιών δημιουργίας μοντέλων, όπως rsample για τη διαίρεση του δείγματος εκπαίδευσης/δοκιμής, parsnip για προδιαγραφές μοντέλου, recipes για προεπεξεργασία δεδομένων, workflows για μοντελοποίηση ροών εργασιών, tune για ρύθμιση υπερπαραμέτρων, yardstick για αξιολόγηση μοντέλου, broom για τον προσδιορισμό των εξόδων μοντέλου και dials για τη διαχείριση παραμέτρων ρύθμισης. Μπορείτε να μάθετε περισσότερα σχετικά με τα πακέτα μεταβαίνοντας στην τοποθεσία web tidymodels. Ακολουθεί ένα παράδειγμα κατασκευής ενός γραμμικού μοντέλου παλινδρόμησης για την πρόβλεψη των μιλίων ανά γαλόνι (χιλιόμετρα) ενός αυτοκινήτου με βάση το βάρος του (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
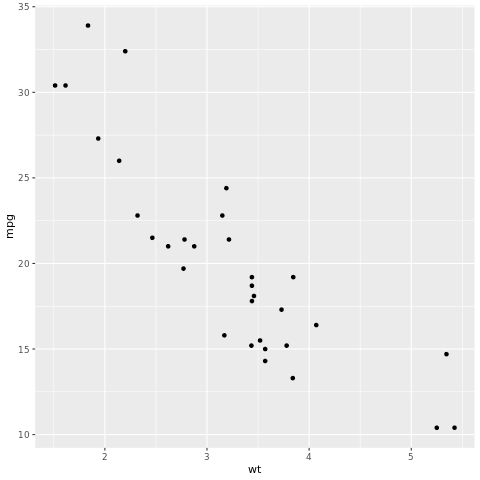
Από το γράφημα διασποράς, η σχέση φαίνεται περίπου γραμμική και η διακύμανση φαίνεται σταθερή. Ας δοκιμάσουμε να το μοντελσουμε χρησιμοποιώντας γραμμική παλινδρόμηση.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Εφαρμόστε το γραμμικό μοντέλο παλινδρόμησης για πρόβλεψη στο σύνολο δεδομένων δοκιμής.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
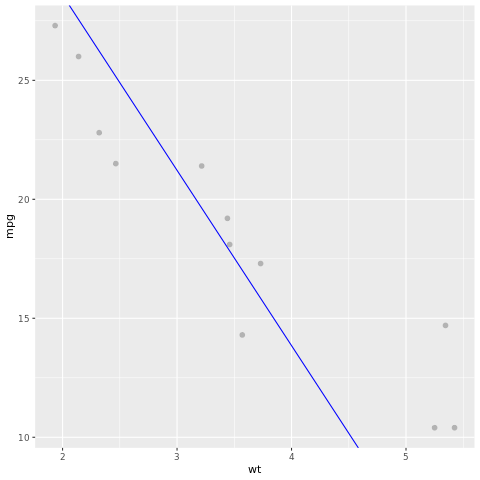
Ας ρίξουμε μια ματιά στο αποτέλεσμα του μοντέλου. Μπορούμε να σχεδιάσουμε το μοντέλο ως γράφημα γραμμών και τα δεδομένα αλήθειας εδάφους δοκιμής ως σημεία στο ίδιο γράφημα. Το μοντέλο φαίνεται καλό.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")