Εκμάθηση: Χρήση R για πρόβλεψη καθυστέρησης πτήσης
Αυτό το εκπαιδευτικό βοήθημα παρουσιάζει ένα τελικό παράδειγμα μιας ροής εργασιών Synapse Data Science στο Microsoft Fabric. Χρησιμοποιεί τα δεδομένα nycflights13 και R, για να προβλέψει αν ένα αεροπλάνο φτάνει με καθυστέρηση άνω των 30 λεπτών. Στη συνέχεια, χρησιμοποιεί τα αποτελέσματα πρόβλεψης για τη δημιουργία ενός αλληλεπιδραστικού πίνακα εργαλείων Power BI.
Σε αυτή την εκμάθηση, θα μάθετε πώς μπορείτε να κάνετε τα εξής:
- Χρησιμοποιήστε tidymodels πακέτα (συνταγές, ανάλυσης , rsample , ροές εργασιών) για την επεξεργασία δεδομένων και την εκπαίδευση ενός μοντέλου εκμάθησης μηχανής
- Εγγραφή των δεδομένων εξόδου σε μια λίμνη ως πίνακα δέλτα
- Δημιουργία μιας αναφοράς απεικόνισης Power BI για απευθείας πρόσβαση σε δεδομένα σε αυτή τη λίμνη
Προϋποθέσεις
Λάβετε μια συνδρομής Microsoft Fabric . Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση microsoft Fabric.
Εισέλθετε για να το Microsoft Fabric.
Χρησιμοποιήστε την εναλλαγή εμπειρίας στην κάτω αριστερή πλευρά της αρχικής σελίδας σας για να μεταβείτε σε Fabric.

Ανοίξτε ή δημιουργήστε ένα σημειωματάριο. Για να μάθετε πώς, ανατρέξτε στο θέμα Τρόπος χρήσης σημειωματάριων Microsoft Fabric.
Ορίστε την επιλογή γλώσσας για να το SparkR (R) για να αλλάξετε την κύρια γλώσσα.
Επισυνάψτε το σημειωματάριό σας σε ένα lakehouse. Στην αριστερή πλευρά, επιλέξτε Προσθήκη για να προσθέσετε μια υπάρχουσα λίμνη ή για να δημιουργήσετε ένα lakehouse.
Εγκατάσταση πακέτων
Εγκαταστήστε το πακέτο nycflights13 για να χρησιμοποιήσετε τον κώδικα σε αυτό το πρόγραμμα εκμάθησης.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Εξερεύνηση των δεδομένων
Τα nycflights13 δεδομένα έχουν πληροφορίες για περίπου 325.819 πτήσεις που έφτασαν κοντά στη Νέα Υόρκη το 2013. Πρώτα, δείτε την κατανομή των καθυστερήσεων των πτήσεων. Αυτό το γράφημα δείχνει ότι η κατανομή των καθυστερήσεων άφιξης είναι σωστά παραμορφωμένη. Έχει μεγάλη ουρά στις υψηλές τιμές.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
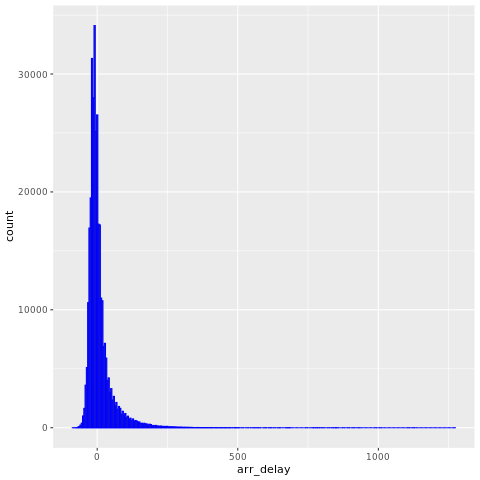
Φορτώστε τα δεδομένα και κάντε μερικές αλλαγές στις μεταβλητές:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Πριν από τη δημιουργία του μοντέλου, εξετάστε μερικές συγκεκριμένες μεταβλητές που είναι σημαντικές τόσο για την προεπεξεργασία όσο και για τη μοντελοποίηση.
Η μεταβλητή arr_delay είναι μια μεταβλητή παράγοντα. Για την εκπαίδευση μοντέλου λογιστικής παλινδρόμησης, είναι σημαντικό η μεταβλητή αποτελέσματος να είναι μια μεταβλητή παράγοντα.
glimpse(flight_data)
Περίπου 16% των πτήσεων σε αυτό το σύνολο δεδομένων έφτασαν με καθυστέρηση άνω των 30 λεπτών.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
Η dest δυνατότητα έχει 104 προορισμούς πτήσεων.
unique(flight_data$dest)
Υπάρχουν 16 διακριτοί μεταφορείς.
unique(flight_data$carrier)
Διαίρεση των δεδομένων
Διαιρέστε το μοναδικό σύνολο δεδομένων σε δύο σύνολα: ένα σύνολο εκπαίδευσης
Χρησιμοποιήστε το πακέτο rsample για να δημιουργήσετε ένα αντικείμενο που περιέχει πληροφορίες σχετικά με τον τρόπο διαίρεσης των δεδομένων. Στη συνέχεια, χρησιμοποιήστε δύο ακόμα συναρτήσεις rsample για να δημιουργήσετε DataFrames για τα σύνολα εκπαίδευσης και δοκιμών:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Δημιουργία συνταγής και ρόλων
Δημιουργήστε μια συνταγή για ένα απλό μοντέλο λογιστικής παλινδρόμησης. Πριν από την εκπαίδευση του μοντέλου, χρησιμοποιήστε μια συνταγή για να δημιουργήσετε νέους παράγοντες πρόβλεψης και διεξάγετε την προεπεξεργασία που απαιτεί το μοντέλο.
Χρησιμοποιήστε τη συνάρτηση update_role() ώστε οι συνταγές να γνωρίζουν ότι flight και time_hour είναι μεταβλητές, με έναν προσαρμοσμένο ρόλο που ονομάζεται ID. Ένας ρόλος μπορεί να έχει οποιαδήποτε τιμή χαρακτήρα. Ο τύπος περιλαμβάνει όλες τις μεταβλητές στο σύνολο εκπαίδευσης, εκτός από arr_delay, ως παράγοντες πρόβλεψης. Η συνταγή διατηρεί αυτές τις δύο μεταβλητές αναγνωριστικού, αλλά δεν τις χρησιμοποιεί είτε ως αποτελέσματα είτε ως παράγοντες πρόβλεψης.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Για να προβάλετε το τρέχον σύνολο μεταβλητών και ρόλων, χρησιμοποιήστε τη συνάρτηση summary():
summary(flights_rec)
Δημιουργία δυνατοτήτων
Εκτελέστε κάποια μηχανική δυνατοτήτων για να βελτιώσετε το μοντέλο σας. Η ημερομηνία της πτήσης μπορεί να έχει εύλογες επιπτώσεις στην πιθανότητα καθυστερημένης άφιξης.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Μπορεί να σας βοηθήσει να προσθέσετε όρους μοντέλου που προέρχονται από την ημερομηνία που ενδεχομένως έχει σημασία για το μοντέλο. Αντλήστε τα παρακάτω χαρακτηριστικά χαρακτηριστικά από τη μεταβλητή μοναδικής ημερομηνίας:
- Ημέρα της εβδομάδας
- Μήνας
- Εάν η ημερομηνία αντιστοιχεί ή όχι σε μια γιορτή
Προσθέστε τα τρία βήματα στη συνταγή σας:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Προσαρμογή μοντέλου με συνταγή
Χρησιμοποιήστε την λογιστική παλινδρόμηση για να μοντελοποιήσετε τα δεδομένα πτήσης. Πρώτα, δημιουργήστε μια προδιαγραφή μοντέλου με το πακέτο parsnip:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Χρησιμοποιήστε τη συσκευασία workflows για να ομαδοποιήσετε το parsnip μοντέλο (lr_mod) με τη συνταγή σας (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Εκπαίδευση του μοντέλου
Αυτή η συνάρτηση μπορεί να προετοιμάσει τη συνταγή και να εκπαιδεύσει το μοντέλο από τις προβλέψεις που προκύπτουν:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Χρησιμοποιήστε τις βοηθητικές συναρτήσεις xtract_fit_parsnip() και extract_recipe() για να εξαγάγετε τα αντικείμενα μοντέλου ή συνταγής από τη ροή εργασιών. Σε αυτό το παράδειγμα, τραβήξτε το αντικείμενο μοντέλου και, στη συνέχεια, χρησιμοποιήστε τη συνάρτηση broom::tidy() για να λάβετε μια τακτοποιημένη κνήμη των συντελεστή μοντέλου:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Πρόβλεψη αποτελεσμάτων
Μία μόνο κλήση προς predict() χρησιμοποιεί την εκπαιδευμένη ροή εργασιών (flights_fit) για να κάνει προβλέψεις με τα μη οροθετικά δεδομένα δοκιμής. Η predict() μέθοδος εφαρμόζει τη συνταγή στα νέα δεδομένα και, στη συνέχεια, διαβιβάζει τα αποτελέσματα στο τοποθετημένο μοντέλο.
predict(flights_fit, test_data)
Λάβετε την έξοδο από predict() για να επιστρέψετε την προβλεπόμενη κλάση: late έναντι on_time. Ωστόσο, για τις προβλεπόμενες πιθανότητες κλάσης για κάθε πτήση, χρησιμοποιήστε augment() με το μοντέλο, σε συνδυασμό με δεδομένα δοκιμής, για να τις αποθηκεύσετε μαζί:
flights_aug <-
augment(flights_fit, test_data)
Εξετάστε τα δεδομένα:
glimpse(flights_aug)
Αξιολόγηση του μοντέλου
Τώρα έχουμε μια κιβωδία με τις προβλεπόμενες πιθανότητες κλάσης. Στις πρώτες γραμμές, το μοντέλο προέβλεψε σωστά πέντε πτήσεις εγκαίρως (οι τιμές των .pred_on_time είναι p > 0.50). Ωστόσο, έχουμε 81.455 γραμμές συνολικά να προβλέψουμε.
Χρειαζόμαστε ένα μετρικό που υποδεικνύει πόσο καλά το μοντέλο προέβλεψε καθυστερημένες αφίξεις, σε σύγκριση με την πραγματική κατάσταση της μεταβλητής αποτελέσματός σας, arr_delay.
Χρησιμοποιήστε το χαρακτηριστικό λειτουργίας Area Under the Curve Receiver (AUC-ROC) ως μετρικό. Υπολογίστε την με roc_curve() και roc_auc(), από το πακέτο yardstick:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Δημιουργία αναφοράς Power BI
Το αποτέλεσμα του μοντέλου φαίνεται εντάξει. Χρησιμοποιήστε τα αποτελέσματα πρόβλεψης καθυστέρησης πτήσης για να δημιουργήσετε έναν αλληλεπιδραστικό πίνακα εργαλείων Power BI. Ο πίνακας εργαλείων εμφανίζει τον αριθμό των πτήσεων κατά μεταφορέα και τον αριθμό των πτήσεων κατά προορισμό. Ο πίνακας εργαλείων μπορεί να φιλτράρει με βάση τα αποτελέσματα της πρόβλεψης καθυστέρησης.
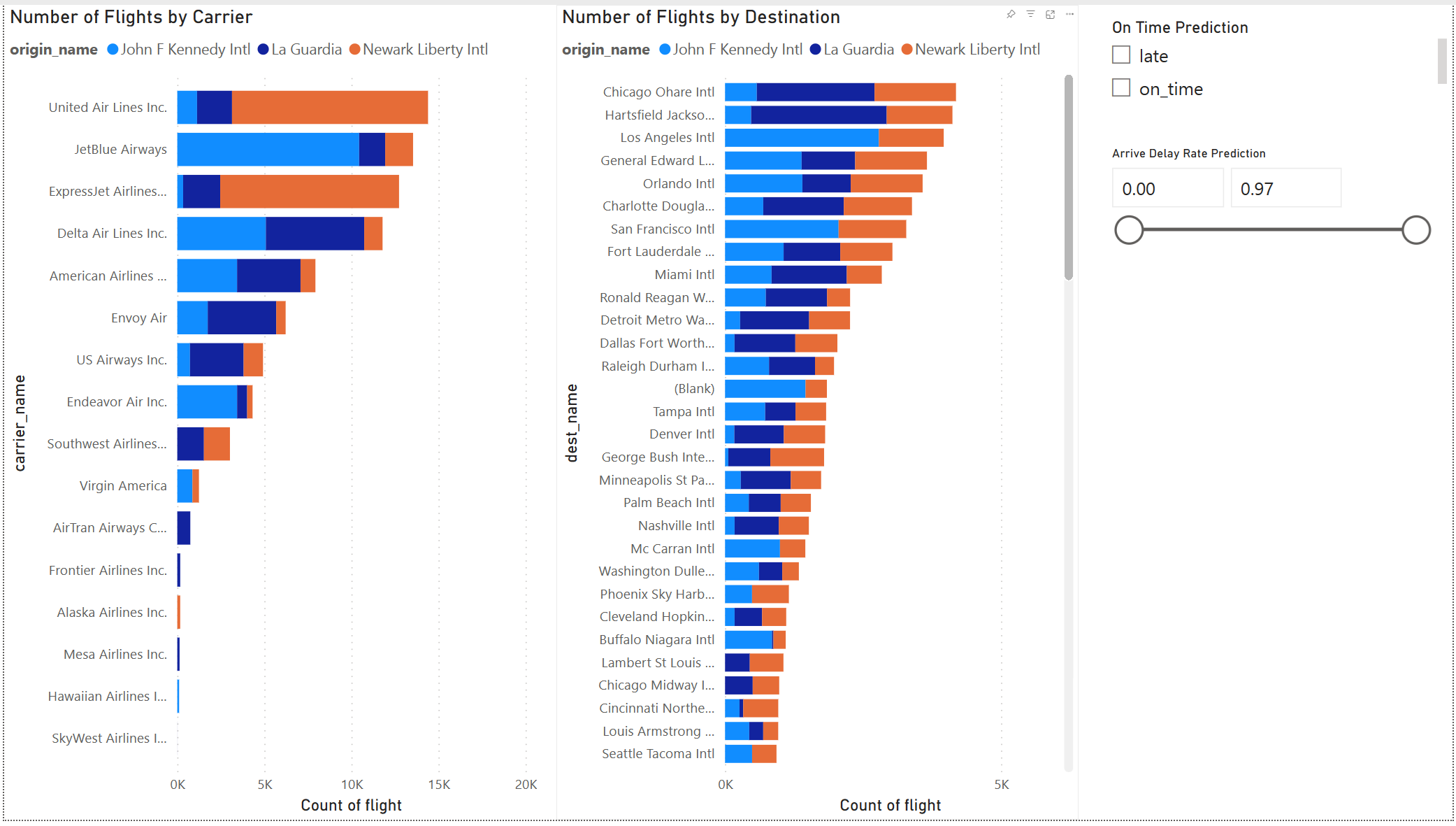
Συμπεριλάβετε το όνομα του μεταφορέα και το όνομα του αεροδρομίου στο σύνολο δεδομένων αποτελέσματος πρόβλεψης:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Εξετάστε τα δεδομένα:
glimpse(flights_clean)
Μετατρέψτε τα δεδομένα σε ένα Spark DataFrame:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Γράψτε τα δεδομένα σε έναν πίνακα δέλτα στο lakehouse σας:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Χρησιμοποιήστε τον πίνακα δέλτα για να δημιουργήσετε ένα μοντέλο σημασιολογίας.
Στην αριστερή πλευρά, επιλέξτε OneLake
Επιλέξτε τη λίμνη που επισυνάψετε στο σημειωματάριό σας
Επιλέξτε Άνοιγμα
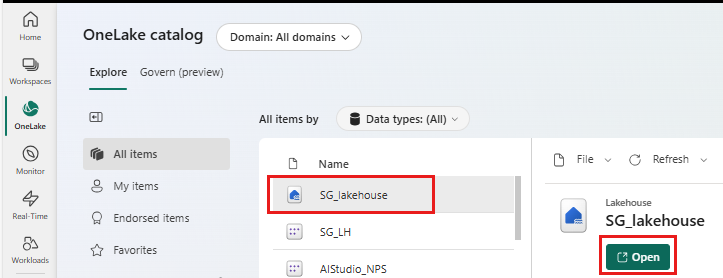
Επιλέξτε νέο μοντέλο σημασιολογίας
Επιλέξτε nycflight13 για το νέο μοντέλο σημασιολογίας και, στη συνέχεια, επιλέξτε Επιβεβαίωση
Το σημασιολογικό μοντέλο σας δημιουργείται. Επιλέξτε νέα αναφοράς
Επιλέξτε ή σύρετε πεδία από το δεδομένων
και τμήματα παραθύρου "Απεικονίσεις" στον καμβά αναφορών, για να δημιουργήσετε την αναφορά σας
Για να δημιουργήσετε την αναφορά που εμφανίζεται στην αρχή αυτής της ενότητας, χρησιμοποιήστε αυτές τις απεικονίσεις και δεδομένα:
-
 γραφήματος σωρευμένων ράβδων με:
γραφήματος σωρευμένων ράβδων με: - Άξονας Υ: carrier_name
- Άξονας Χ:πτήσης
. Επιλέξτε πλήθους για τη συνάθροιση - Υπόμνημα: origin_name
-
γραφήματος σωρευμένων ράβδων με:
- Άξονας Υ: dest_name
- Άξονας Χ:πτήσης
. Επιλέξτε πλήθους για τη συνάθροιση - Υπόμνημα: origin_name
-
 αναλυτή με:
αναλυτή με: - Πεδίο: _pred_class
-
αναλυτή με:
- Πεδίο: _pred_late
Σχετικό περιεχόμενο
- Τρόπος χρήσης του SparkR
- Τρόπος χρήσης με sparklyr
- Πώς να χρησιμοποιήσετε το Tidyverse
- διαχείρισης βιβλιοθήκης R
- Απεικόνιση δεδομένων σε R
- Εκμάθηση : Χρησιμοποιήστε την R για να προβλέψετε τις τιμές αβοκάντο