Behandeln von Clusterproblemen mit der Ereignis-ID 1135
Dieser Artikel unterstützt Sie beim Diagnostizieren und Auflösen der Ereignis-ID 1135, die während des Starts des Clusterdiensts in der Umgebung der Failoverclusterunterstützung protokolliert werden kann.
Gilt für: Windows Server 2022, Windows Server 2019, Windows Server 2016, Azure Stack HCI, Versionen 21H2 und 20H2
Testen Sie unseren Virtual Agent – Er kann Ihnen helfen, häufige Probleme bei der Active Directory-Replikation schnell zu erkennen und zu beheben.
Startseite
Ereignis-ID 1135 gibt an, dass mindestens ein Clusterknoten aus der aktiven Failoverclustermitgliedschaft entfernt wurde. Sie kann von folgenden Symptomen begleitet werden:
Clusterfailover\Knoten, die aus der aktiven Failoverclustermitgliedschaft entfernt werden:
Problem mit Knoten, die aus der aktiven Failoverclustermitgliedschaft entfernt werden
Ereignis-ID 1069:
Ereignis-ID 1069 – Clustered Service or Application Availability
Ereignis-ID 1177 für Quorumverlust:
Ereignis-ID 1177 – Quorum und Konnektivität erforderlich für Quorum
Ereignis-ID 1006 für den Clusterdienst wurde angehalten:
Als einer der ersten Schritte zur Problembehandlung werden eine Validierung und die Netzwerktests empfohlen, um sicherzustellen, dass keine Konfigurationsprobleme vorliegen, die möglicherweise eine Problemursache sind.
Überprüfen, ob die empfohlenen Hotfixes installiert sind
Der Clusterdienst ist die wesentliche Softwarekomponente, die alle Aspekte des Failoverclusterbetriebs steuert und die Datenbank für die Clusterkonfiguration verwaltet. Wenn die Ereignis-ID 1135 angezeigt wird, empfehlen wir Ihnen, die in den folgenden Artikeln erwähnten Fixes zu installieren und alle Knoten des Clusters neu zu starten, und beobachten Sie, ob das Problem erneut auftritt.
- Empfohlene Hotfixes und Updates für Windows Server 2012 R2-basierte Failovercluster
- Empfohlene Hotfixes und Updates für Windows Server 2012-basierte Failovercluster
- Empfohlene Hotfixes und Updates für Windows Server 2008 R2 SP1-Failovercluster
Überprüfen, ob der Clusterdienst auf allen Knoten ausgeführt wird
Führen Sie den folgenden Befehl gemäß Ihrem Windows-Betriebssystem aus, um zu überprüfen, ob der Clusterdienst kontinuierlich ausgeführt wird und verfügbar ist.
Für Windows Server 2008 R2-Cluster
Führen Sie an einer Eingabeaufforderung mit erhöhten Rechten den Befehl cluster.exe node /stat aus.
Für Windows Server 2012- und Windows Server 2012 R2-Cluster
Führen Sie das folgende PowerShell-Cmdlet aus: Get-ClusterResource
Wird der Clusterdienst kontinuierlich ausgeführt, und ist er auf allen Knoten verfügbar?
Mehrere Szenarien der Ereignis-ID 1135
Wir möchten, dass Sie sich die Systemereignisprotokolle auf allen Knoten Ihres Clusters genauer ansehen. Überprüfen Sie die Ereignis-ID 1135, die auf den Knoten angezeigt wird, und kopieren Sie alle Instanzen dieses Ereignisses. Dies erleichter Ihnen, sie zu betrachten und zu überprüfen.
Event ID 1135
Cluster node ' **NODE A** ' was removed from the active failover cluster membership. The Cluster service on this node may have stopped.
This could also be due to the node having lost communication with other active nodes in the failover cluster.
Run the Validate a Configuration wizard to check your network configuration.
If the condition persists, check for hardware or software errors related to the network adapters on this node.
Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Es gibt drei typische Szenarien:
Szenario A
Sie sehen sich alle Ereignisse an, und alle Knoten im Cluster geben an, dass NODE A die Kommunikation verloren hat.
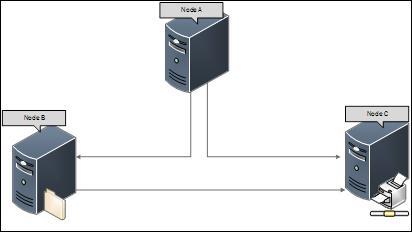

Es könnte möglich sein, dass beim Anzeigen der Systemprotokolle auf NODE A Ereignisse für alle verbleibenden Knoten im Cluster vorhanden sind.
Lösung
Dies deutet darauf hin, dass zum Zeitpunkt des Auftretens des Problems entweder aufgrund einer Netzwerküberlastung oder aus anderen Gründen die Kommunikation mit NODE A verloren ging.
Sie sollten die Netzwerkkonfigurations- und Kommunikationsprobleme überprüfen und validieren. Denken Sie daran, nach Problemen im Zusammenhang mit Node A zu suchen.
Szenario B
Sie betrachten die Ereignisse auf den Knoten, und lassen Sie uns sagen, dass Ihr Cluster an zwei Standorten verteilt ist. NODE A, NODE B und NODE C an Standort 1 und NODE D & NODE E an Standort 2.
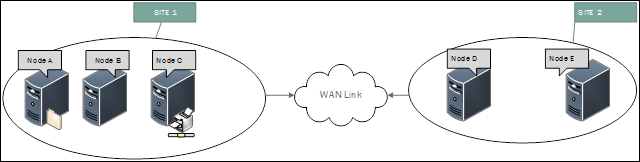
Auf Knoten A,B und C sehen Sie, dass die protokollierten Ereignisse für die Verbindung mit Knoten D & E sind. Ebenso deuten die Ereignisse auf Knoten D & E darauf hin, dass wir die Kommunikation mit A, B und C verloren haben.
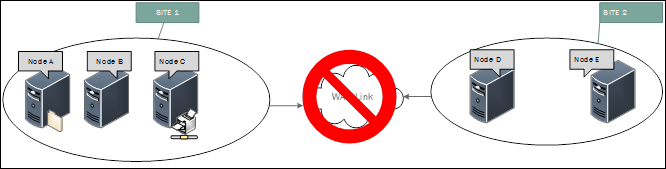
Lösung
Wenn Sie ähnliche Aktivitäten feststellen, ist dies ein Hinweis darauf, dass die Kommunikation über die Verbindung dieser Standorte gestört ist. Sie sollten die Verbindung zwischen den Standorten überprüfen. Wenn es sich um eine WAN-Verbindung handelt, sollten Sie sich bei Ihrem ISP über die Konnektivität informieren.
Szenario C
Sie betrachten die Ereignisse auf den Knoten, und Sie sehen, dass die Namen der Knoten nicht mit einem bestimmten Muster veralten. Nehmen wir an, dass Ihr Cluster auf zwei Standorte verteilt ist NODE A, NODE B und NODE C an Standort 1 und NODE D & NODE E an Standort 2.
- Auf Node A: Es werden Ereignisse für Node B, D, E angezeigt.
- Auf Node B: Es werden Ereignisse für Node C, D, E angezeigt.
- Auf Node C: Es werden Ereignisse für Node A, B, E angezeigt.
- Auf Node D: Es werden Ereignisse für Node A, C, E angezeigt.
- Auf Node E: Es werden Ereignisse für Node B, C, D angezeigt.
- Oder beliebige andere Kombinationen.
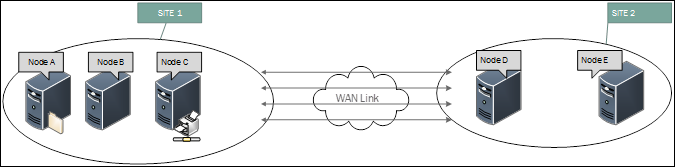
Lösung
Solche Ereignisse sind möglich, wenn die Netzwerkkanäle zwischen den Knoten verstopft sind und die Clusterkommunikationsnachrichten nicht rechtzeitig eintreffen, sodass der Cluster annimmt, die Kommunikation zwischen den Knoten sei verloren gegangen, was dazu führt, dass Knoten aus der Clustermitgliedschaft entfernt werden.
Überprüfen von Clusternetzwerken
Sie sollten Ihre Clusternetzwerke überprüfen, indem Sie die folgenden drei Optionen einzeln überprüfen, um diesen Leitfaden zur Problembehandlung fortzusetzen.
Überprüfen auf Virenschutzausschluss
Schließen Sie die folgenden Dateisystemspeicherorte von der Virenüberprüfung auf einem Server aus, auf dem Clusterdienste ausgeführt werden:
- Der Pfad des Dateifreigabenzeugen
- Der %Systemroot%\Cluster-Ordner
Konfigurieren Sie die Echtzeitüberprüfungskomponente in Ihrer Antivirensoftware, um die folgenden Verzeichnisse und Dateien auszuschließen:
Standardkonfigurationsverzeichnis für virtuelle Computer (C:\ProgramData\Microsoft\Windows\Hyper-V)
Konfigurationsverzeichnisse für benutzerdefinierte virtuelle Computer
Standardverzeichnis für virtuelle Festplatten (C:\Users\Public\Documents\Hyper-V\Virtual Hard Disks)
Verzeichnisse für benutzerdefinierte virtuelle Festplattenlaufwerke
Benutzerdefinierte Replikationsdatenverzeichnisse, wenn Sie Hyper-V-Replikat verwenden
Momentaufnahmenverzeichnisse
mms.exe
Hinweis
Diese Datei muss möglicherweise innerhalb der Antivirensoftware als Prozessausschluss konfiguriert werden.
Vmwp.exe
Hinweis
Diese Datei muss möglicherweise innerhalb der Antivirensoftware als Prozessausschluss konfiguriert werden.
Wenn Sie die Livemigration zusammen mit freigegebenen Clustervolumes verwenden, schließen Sie außerdem den CSV-Pfad C:\Clusterstorage und alle zugehörigen Unterverzeichnisse aus. Wenn Sie Failoverprobleme oder allgemeine Probleme mit Clusterdiensten und Antivirensoftware beheben, deinstallieren Sie die Antivirensoftware vorübergehend, oder wenden Sie sich an den Hersteller der Software, um zu ermitteln, ob die Antivirensoftware mit Clusterdiensten funktioniert. Das Deaktivieren der Antivirensoftware reicht in den meisten Fällen nicht aus. Auch wenn Sie die Antivirensoftware deaktivieren, wird der Filtertreiber weiterhin geladen, wenn Sie den Computer neu starten.
Überprüfen der Netzwerkportkonfiguration in der Firewall
Der Clusterdienst steuert Serverclustervorgänge und verwaltet die Clusterdatenbank. Ein Cluster ist eine Sammlung unabhängiger Computer, die als einzelner Computer fungieren. Manager, Programmierer und Benutzer sehen den Cluster als ein einzelnes System. Die Software verteilt Daten auf die Knoten des Clusters. Wenn ein Knoten ausfällt, stellen andere Knoten die Dienste und Daten bereit, die zuvor vom fehlenden Knoten bereitgestellt wurden. Wenn ein Knoten hinzugefügt oder repariert wird, migriert die Clustersoftware einige Daten zu diesem Knoten.
Name des Systemdiensts: ClusSvc
| Anwendung | Protokoll | Ports |
|---|---|---|
| Clusterdienst | UDP | 3343 |
| Clusterdienst | TCP | 3343 (Dieser Port ist während einer Knotenverknüpfungsoperation erforderlich.) |
| RPC | TCP | 135 |
| Clusteradministrator | UDP | 137 |
| Kerberos | UDP/TCP | 464* |
| SMB | TCP | 445 |
| Zufällig zugeordnete hohe UDP-Ports** | UDP | Zufällige Portnummer zwischen 1024 und 65535 Zufällige Portnummer zwischen 49152 und 65535*** |
Hinweis
Für eine erfolgreiche Überprüfung auf Windows-Failoverclustern unter Windows Server 2008 und höher lassen Sie außerdem eingehenden und ausgehenden Datenverkehr für ICMP4 und ICMP6 zu.
- Weitere Informationen finden Sie unter Fehler 0xc000005e beim Erstellen eines Failoverclusters.
- Weitere Informationen zum Anpassen dieser Ports finden Sie im Abschnitt "Verweise" in service overview and network port requirements for Windows.
Dies ist der Bereich in Windows Server 2012, Windows 8, Windows Server 2008 R2, Windows 7, Windows Server 2008 und Windows Vista.
Führen Sie außerdem den folgenden Befehl aus, um die Netzwerkportkonfiguration in der Firewall zu überprüfen. Beispiel: Mit diesem Befehl wird ermittelt, ob der für den Failovercluster verwendete Port 3343 verfügbar\geöffnet ist:
netsh advfirewall firewall show rule name="Failover Clusters (UDP-In)" verbose
Ausführen des Clustervalidierungsberichts für Fehler oder Warnungen
Das Clustervalidierungstool führt eine Reihe von Tests aus, um zu überprüfen, ob Ihre Hardware und Einstellungen mit dem Failoverclustering kompatibel sind.
Befolgen Sie diese Anweisungen:
Führen Sie den Clustervalidierungsbericht für Fehler oder Warnungen aus. Weitere Informationen finden Sie unter Grundlegendes zu Clustervalidierungstests: Netzwerk.
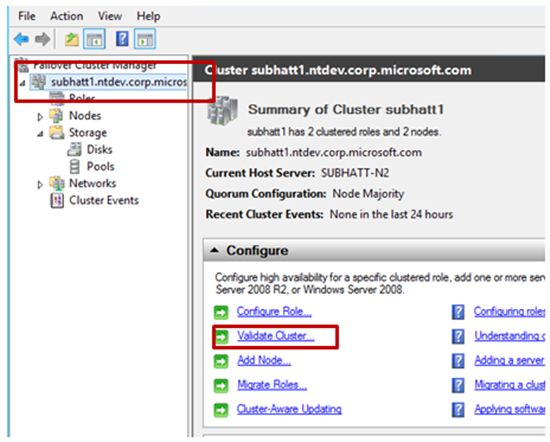
Überprüfen Sie, ob Warnungen und Fehler für Netzwerke vorliegen. Weitere Informationen finden Sie unter Grundlegendes zu Clustervalidierungstests: Netzwerk.
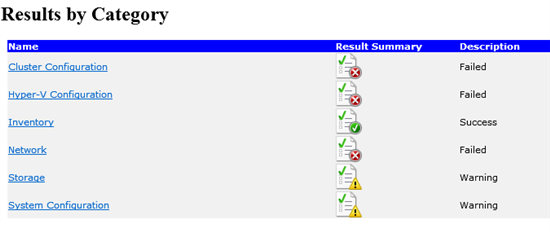
Überprüfen der Listen-Netzwerkbindungsreihenfolge
Dieser Test listet die Reihenfolge auf, in der Netzwerke auf jedem Knoten an die Adapter gebunden werden.
Auf der Registerkarte "Adapter" und "Bindungen " werden die Verbindungen in der Reihenfolge aufgelistet, in der von Netzwerkdiensten auf die Verbindungen zugegriffen wird. Die Reihenfolge dieser Verbindungen gibt die Reihenfolge an, in der generische TCP/IP-Aufrufe/Pakete an das Netz gesendet werden.
Führen Sie die folgenden Schritte aus, um die Bindungsreihenfolge von Netzwerkadaptern zu ändern:
- Wählen Sie "Start" aus, wählen Sie "Ausführen" aus, geben Sie ncpa.cpl ein, und wählen Sie dann "OK" aus. Die verfügbaren Verbindungen werden im Abschnitt LAN und High-Speed-Internet des Fensters Netzwerkverbindungen angezeigt.
- Wählen Sie im Menü "Erweitert" die Option "Erweiterte Einstellungen" und dann die Registerkarte "Adapter" und "Bindungen" aus.
- Wählen Sie im Bereich Verbindungen die Verbindung aus, die Sie in der Liste nach oben verschieben möchten. Verwenden Sie die Pfeiltasten, um die Verbindung zu verschieben. In der Regel sollte die Karte, die mit dem Netzwerk spricht (Domänenkonnektivität, Routing an andere Netzwerke usw.), die erste gebundene Karte (oben in der Liste) sein.
Clusterknoten sind Multihomingsysteme. Die Netzwerkpriorität wirkt sich auf den DNS-Client für ausgehende Netzwerkkonnektivität aus. Für die Clientkommunikation verwendete Netzwerkadapter sollten sich in der Bindungsreihenfolge ganz oben befinden. Nicht geroutete Netzwerke können mit niedrigerer Priorität platziert werden. In Windows Server 2012 und Windows Server 2012 R2 wird der Clusternetzwerktreiber (NETFT.SYS) automatisch unten in der Bindungsreihenfolgenliste platziert.
Überprüfen der Netzwerkkommunikations-Validierung
Latenz in Ihrem Netzwerk kann auch eine Ursache sein. Die Pakete gehen möglicherweise nicht zwischen den Knoten verloren, aber sie gelangen möglicherweise nicht schnell genug zu den Knoten, bevor der Timeoutzeitraum abläuft.
Dieser Test überprüft, ob getestete Server mit akzeptabler Latenz in allen Netzwerken kommunizieren können.
Beispiel: Unter „Netzwerkkommunikations-Validierung“ werden möglicherweise die folgenden Meldungen für Netzwerklatenzprobleme angezeigt:
Succeeded in pinging network interface node003.contoso.com IP Address 192.168.0.2 from network interface node004.contoso.com IP Address 192.168.0.3 with maximum delay 500 after 1 attempt(s).
Either address 10.0.0.96 is not reachable from 192.168.0.2 or **the ping latency is greater than the maximum allowed 2000 ms**
This may be expected, since network interfaces node003.contoso.com - Heartbeat Network and node004.contoso.com - Production Network are on different cluster networks
Either address 192.168.0.2 is not reachable from 10.0.0.96 or **the ping latency is greater than the maximum allowed 2000 ms**
This may be expected, since network interfaces node004.contoso.com - Production Network and node003.contoso.com - Heartbeat Network for MSCS are on different cluster networks
Bei standortübergreifenden Clustern können Sie die Timeoutwerte erhöhen. Weitere Informationen finden Sie unter Konfigurieren von Heartbeat- und DNS-Einstellungen in einem standortübergreifenden Failovercluster.
Klären Sie ggf. WAN-Konnektivitätsprobleme mit dem ISP.
Überprüfen Sie, ob eines der folgenden Probleme auftritt.
Zwischen Knoten verloren gegangene Netzwerkpakete
Überprüfen von Paketverlusten anhand der Leistung
Wenn das Paket irgendwo zwischen den Knoten im Netzwerk verloren geht, tritt ein Heartbeatfehler auf. Wir können leicht herausfinden, ob dies ein Problem ist, indem wir mit dem Leistungsmonitor den Leistungsindikator „Netzwerkschnittstelle\Empfangene/verworfene Pakete“ betrachten. Nachdem Sie diesen Leistungsindikator hinzugefügt haben, prüfen Sie die Werte von „Durchschnitt“, „Minimum“ und „Maximum“, und wenn es sich um einen Wert über 0 handelt, muss der Empfangspuffer für den Adapter angepasst werden.
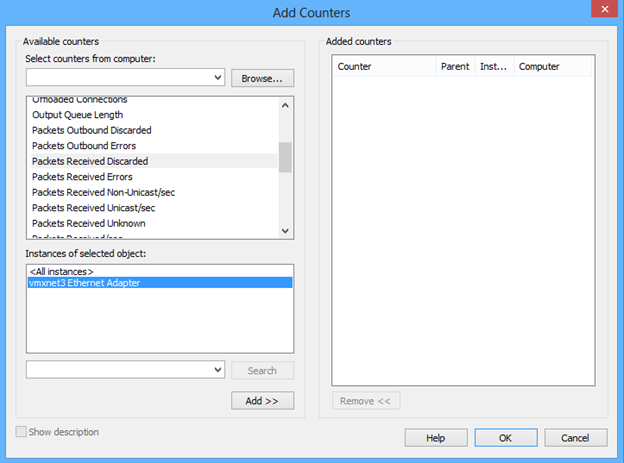
Wenn auf der VMware-Virtualisierungsplattform Netzwerkpakete verloren gehen, lesen Sie den Abschnitt "Cluster installiert in der VMware-Virtualisierungsplattform".
Upgraden der NIC-Treiber
Dieses Problem kann aufgrund veralteter NIC-Treiber\Integrationskomponenten (IC)\VmTools oder fehlerhafter NIC-Adapter auftreten. Wenn Netzwerkpakete zwischen Knoten auf physischen Computern verloren gehen, aktualisieren Sie den Netzwerkadaptertreiber. Alte oder veraltete Netzwerkkartentreiber und/oder Firmware. Manchmal kann eine einfache Fehlkonfiguration der Netzwerkkarte oder des Switches auch zu einem Heartbeatverlust führen.
Auf der VMware-Virtualisierungsplattform installierter Cluster
Überprüfen Sie in einer VMware-Umgebung, ob Probleme mit dem VMware-Adapter vorliegen.
Dieses Problem kann auftreten, wenn die Pakete bei Bursts mit hohem Datenverkehr gelöscht werden. Stellen Sie sicher, dass keine Datenverkehrsfilterung erfolgt (z. B. mit einem E-Mail-Filter). Nachdem Sie diese Möglichkeit ausgeschlossen haben, erhöhen Sie schrittweise die Anzahl der Puffer im Gastbetriebssystem, und setzen Sie die Überprüfung fort.
Führen Sie die folgenden Schritte aus, um Ausfälle im Burstdatenverkehr zu reduzieren:
- Wählen Sie "Start", wählen Sie "Ausführen" aus, geben
devmgmt.mscSie die EINGABETASTE ein. - Erweitern Sie Netzwerkadapter, klicken Sie mit der rechten Maustaste auf vmxnet3, und wählen Sie "Eigenschaften" aus.
- Wählen Sie die Registerkarte Erweitert.
- Wählen Sie kleine Rx-Puffer aus, und erhöhen Sie den Wert. Der Standardwert beträgt 512, der Maximalwert 8192.
- Wählen Sie Rx Ring #1 Größe aus, und erhöhen Sie den Wert. Der Standardwert beträgt 1024, der Maximalwert 4096.
Überprüfen Sie die folgenden Artikel, um VMware-Adapterprobleme bei VMware-Umgebung zu überprüfen:
- Wurden unter VMware ESX Knoten aus der Failoverclustermitgliedschaft entfernt?
- Großer Paketverlust auf Gastbetriebssystem-Ebene auf VMXNET3 vNIC in ESXi
Beachten von Netzwerküberlastungen
Netzwerküberlastungen können auch zu Problemen mit der Netzwerkkonnektivität führen.
Überprüfen Sie, ob Ihr Netzwerk gemäß MS- und Anbieterempfehlungen konfiguriert ist, siehe auch Konfigurieren von Windows-Failoverclusternetzwerken.
Überprüfen Sie die Netzwerkkonfiguration.
Wenn es immer noch nicht funktioniert, überprüfen Sie, ob Sie ein partitioniertes Netzwerk in der Cluster-GUI gesehen haben oder ob die NIC-Teamerstellung auf der Takt-NIC aktiviert ist.
Wenn in der Cluster-GUI ein partitioniertes Netzwerk angezeigt wird, beheben Sie das Problem mithilfe der Informationen unter „Partitionierte“ Clusternetzwerke.
Wenn Sie den NIC-Teamvorgang für die Heartbeat-NIC aktiviert haben, überprüfen Sie die Funktionalität der Teamvorgangsoftware gemäß der Empfehlung des Teamvorganganbieters.
Upgraden der NIC-Treiber
Dieses Problem kann aufgrund veralteter NIC-Treiber oder fehlerhafter NIC-Adapter auftreten.
Wenn Netzwerkpakete zwischen Knoten auf physischen Computern verloren gehen, aktualisieren Sie den Netzwerkadaptertreiber. Alte oder veraltete Netzwerkkartentreiber und/oder Firmware.
Manchmal kann eine einfache Fehlkonfiguration der Netzwerkkarte oder des Switches auch zu einem Heartbeatverlust führen.
Überprüfen Sie die Netzwerkkonfiguration.
Wenn es immer noch nicht funktioniert, überprüfen Sie, ob Sie ein partitioniertes Netzwerk in der Cluster-GUI gesehen haben oder ob die NIC-Teamerstellung auf der Takt-NIC aktiviert ist.