Problem beim Entfernen von Knoten aus der aktiven Failoverclustermitgliedschaft
In diesem Artikel erfahren Sie, wie Sie die Probleme lösen, bei denen Knoten zufällig aus der aktiven Failoverclustermitgliedschaft entfernt werden.
Symptome
Wenn das Problem auftritt, werden Ereignisse wie dieses Ereignis in Ihrem Systemereignisprotokoll protokolliert:
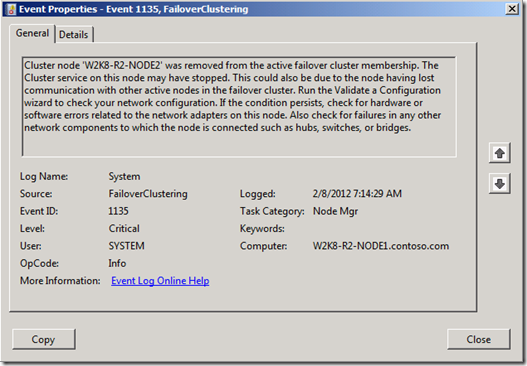
Dieses Ereignis wird auf allen Knoten im Cluster protokolliert, mit Ausnahme des Knotens, der entfernt wurde. Der Grund für dieses Ereignis besteht darin, dass einer der Knoten im Cluster diesen Knoten als ausgefallen markiert hat. Er benachrichtigt dann alle anderen Knoten über das Ereignis. Wenn die Knoten benachrichtigt werden, unterbrechen und löschen sie ihre Heartbeatverbindungen mit dem ausgefallenen Knoten.
Warum wurde der Knoten als „Ausgefallen“ gekennzeichnet?
Alle Knoten in einem Windows Server-Failovercluster kommunizieren über die Netzwerke, die für die Clusternetzwerkkommunikation in diesem Netzwerk festgelegt sind. Die Knoten senden Taktpakete über diese Netzwerke hinweg an alle anderen Knoten. Diese Pakete sollen von den anderen Knoten empfangen werden und dann wird eine Antwort zurückgesendet. Jeder Knoten im Cluster verfügt über eigene Takte, die überwacht werden, um sicherzustellen, dass das Netzwerk hoch ist und die anderen Knoten hoch sind. Das folgende Beispiel sollte dabei helfen, dieses Verhalten zu verdeutlichen:
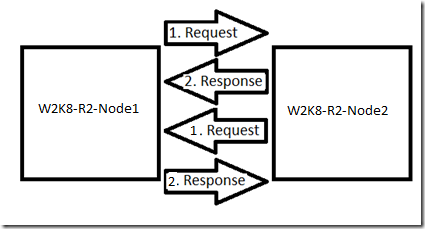
Wenn eines dieser Pakete nicht zurückgegeben wird, wird der spezifische Takt als fehlgeschlagen betrachtet. Beispielsweise sendet W2K8-R2-NODE2 eine Anforderung und empfängt eine Antwort von W2K8-R2-NODE1 auf ein Heartbeatpaket, sodass das Netzwerk und der Knoten aktiv sind. Wenn W2K8-R2-NODE1 eine Anforderung an W2K8-R2-NODE2 sendet und W2K8-R2-NODE1 die Antwort nicht erhält, wird sie als verlorener Takt betrachtet, und W2K8-R2-NODE1 verfolgt sie. Diese fehlende Antwort kann dazu führen, dass W2K8-R2-NODE1 das Netzwerk als „Ausgefallen“ anzeigt, bis eine weitere Heartbeatanforderung empfangen wird.
Für Clusterknoten gilt standardmäßig eine Grenze von fünf Fehlern innerhalb von fünf Sekunden, bevor die Verbindung als „Ausgefallen“ gekennzeichnet wird. Wenn also W2K8-R2-NODE1 die Antwort fünfmal im Zeitraum nicht empfängt, ist es der Ansicht, dass eine bestimmte Route zu W2K8-R2-NODE2 nach unten geleitet wird. Wenn andere Routen noch als aktiv betrachtet werden, bleibt W2K8-R2-NODE2 als aktives Mitglied erhalten.
Wenn alle Routen für W2K8-R2-NODE2 gekennzeichnet sind, wird sie aus der aktiven Failoverclustermitgliedschaft entfernt, und das Ereignis 1135, das im ersten Abschnitt angezeigt wird, wird protokolliert. Auf W2K8-R2-NODE2 wird der Clusterdienst beendet und dann neu gestartet, sodass er versuchen kann, dem Cluster wieder beizutreten.
Weitere Informationen darüber, wie wir mit bestimmten Routen umgehen, die bei drei oder mehr Netzwerken ausfallen, finden Sie im Blog „Partitionierte“ Clusternetzwerke, der von Jeff Hughes geschrieben wurde.
Nachdem wir wissen, wie der Heartbeatprozess funktioniert: Was sind einige der bekannten Ursachen für das Scheitern des Prozesses?
Tatsächliche Ausfälle von Netzwerkhardware. Wenn das Paket an einer beliebigen Stelle zwischen den Knoten verloren geht, schlagen die Takte fehl. Eine Netzwerkablaufverfolgung von beiden beteiligten Knoten wird dies offenbaren.
Das Profil für Ihre Netzwerkverbindungen springt möglicherweise von „Domäne“ zu „Öffentlich“ und wieder zurück zu „Domäne“. Während des Übergangs dieser Änderungen kann die Netzwerk-E/A blockiert werden. Sie können überprüfen, ob dies der Fall ist, indem Sie sich das Betriebsprotokoll des Netzwerkprofils ansehen. Sie finden dieses Protokoll, indem Sie die Ereignisanzeige öffnen und zu Anwendungs- und Dienstprotokollen\Microsoft\Windows\NetworkProfile\Operational navigieren. Sehen Sie sich die Ereignisse in diesem Protokoll auf dem Knoten an, der in der Ereignis-ID 1135 erwähnt wurde, und überprüfen Sie, ob das Profil zu diesem Zeitpunkt geändert wurde. Wenn ja, lesen Sie die Änderungen des Netzwerkspeicherortprofils von "Domäne" in "Öffentlich" in Windows 7 oder in Windows Server 2008 R2.
Sie haben IPv6 auf den Servern aktiviert, aber in der Windows-Firewall sind die folgenden beiden Regeln für ein- und ausgehende Verbindungen deaktiviert:
- Kernnetzwerk – Nachbarermittlungsankündigung
- Kernnetzwerk – Nachbarermittlungsaufforderung
Auch Antivirensoftware könnte mit diesem Prozess in Konflikt stehen. Wenn Sie dies vermuten, testen Sie die Software, indem Sie sie deaktivieren oder deinstallieren. Führen Sie dies auf eigene Gefahr aus, da Sie an diesem Punkt nicht vor Viren geschützt sind.
Latenz in Ihrem Netzwerk kann auch eine Ursache sein. Die Pakete gehen möglicherweise nicht zwischen den Knoten verloren, aber sie gelangen möglicherweise nicht schnell genug zu den Knoten, bevor der Timeoutzeitraum abläuft.
IPv6 ist das Standardprotokoll, das Failoverclustering für seine Heartbeats verwendet. Der Heartbeat selbst ist ein UDP-Unicast-Netzwerkpaket, das über Port 3343 kommuniziert. Wenn Switches, Firewalls oder Router nicht richtig konfiguriert sind, um diesen Datenverkehr durchzulassen, kann es zu Problemen wie diesem kommen.
Auch die Aktualisierung der IPsec-Sicherheitsrichtlinien kann dieses Problem verursachen. Das spezifische Problem besteht darin, dass während einer Aktualisierung der IPSec-Gruppenrichtlinien alle IPsec-Sicherheitszuordnungen (SAs) von der Windows Firewall mit erweiterter Sicherheit (WFAS) abgebrochen werden. Während dies geschieht, wird die Netzwerkkonnektivität blockiert. Beim Neuverhandeln der Sicherheitszuordnungen, wenn es Verzögerungen bei der Authentifizierung mit Active Directory gibt, werden diese Verzögerungen (bei denen die gesamte Netzwerkkommunikation blockiert ist) auch das Abrufen von Clustertakten blockieren und die Clusterintegritätsüberwachung dazu führen, Knoten als abwärts zu erkennen, wenn sie nicht innerhalb des Schwellenwerts von 5 Sekunden reagieren.
Alte oder veraltete Netzwerkkartentreiber und/oder Firmware. Manchmal kann eine einfache Fehlkonfiguration der Netzwerkkarte oder des Switches auch zu einem Heartbeatverlust führen.
Moderne Netzwerkkarten und virtuelle Netzwerkkarten können paketverlusten. Dies kann nachverfolgt werden, indem sie Leistungsmonitor öffnen und den Zähler "Netzwerkschnittstelle\Empfangene Pakete verworfen" hinzufügen. Dieser Leistungsindikator ist kumulativ und erhöht sich nur, bis der Server neu gestartet wird. Eine große Anzahl von Paketen, die hier abgelegt wurden, könnte ein Zeichen sein, dass die Empfangspuffer auf der Netzwerkkarte zu niedrig festgelegt sind oder dass der Server langsam ausgeführt wird und den eingehenden Datenverkehr nicht verarbeiten kann. Jeder Hersteller von Netzwerkkarten entscheidet, ob er diese Einstellungen in den Eigenschaften der Netzwerkkarte verfügbar macht. Daher müssen Sie sich auf der Website des Herstellers informieren, wie Sie diese Werte erhöhen können und welche Werte Sie verwenden sollten. Wenn Sie auf VMware arbeiten, spricht der folgende Blog etwas ausführlicher darüber, einschließlich der Frage, ob dies das Problem ist, sowie verweist Sie auf den VMware-Artikel zu den zu ändernden Einstellungen.
Knoten werden unter VMware ESX aus der Failoverclustermitgliedschaft entfernt
Dies sind die häufigsten Gründe, warum diese Ereignisse protokolliert werden, aber es kann auch andere Gründe geben. Mit diesem Blog möchten wir Ihnen einen Einblick in den Prozess sowie Anregungen geben, worauf Sie achten sollten. Einige werden die folgenden Werte auf ihre Maximalwerte erhöhen, um zu versuchen, dieses Problem zu beheben.
| Parameter | Standard | Bereich |
|---|---|---|
| SameSubnetDelay | 1000 Millisekunden | 250-2000 Millisekunden |
| CrossSubnetDelay | 1000 Millisekunden | 250-4000 Millisekunden |
| SameSubnetThreshold | 5 | 3–10 |
| CrossSubnetThreshold | 5 | 3–10 |
Wenn Sie diese Werte auf ihr Maximum erhöhen, kann das Entfernen des Ereignisses und Knotens wegfallen, es maskiert einfach das Problem. Es wird nichts behoben. Das Beste ist, die Ursache der Taktfehler herauszufinden und es zu beheben. Die einzige wirkliche Notwendigkeit, diese Werte zu erhöhen, liegt in einem Szenario mit mehreren Standorten, in dem Sich Knoten an verschiedenen Standorten befinden und die Netzwerklatenz nicht überwunden werden kann.