Behandeln von Leistungsproblemen von virtuellen Azure-Computern unter Linux oder Windows
Gilt für: ✔️ Linux-VMs ✔️ Windows-VMs
Dieser Artikel beschreibt die allgemeine Behandlung von Leistungsproblemen bei virtuellen Computern (VMs) durch Überwachen und Beobachten von Leistungsengpässen und bietet mögliche Korrekturen für Probleme, die auftreten können. Neben Überwachung können Sie auch Perfinsights verwenden, um einen Bericht mit Best Practice-Empfehlungen und wichtigen Engpässen rund um E/A, CPU und Arbeitsspeicher bereitzustellen. Perfinsights ist für Windows- und Linux-VMs in Azure verfügbar.
In diesem Artikel wird die Verwendung von Überwachung zur Diagnose von Leistungsengpässen erläutert.
Aktivieren der VM-Diagnose über Azure-Portal
So aktivieren Sie die VM-Diagnose:
Wechseln Sie zum virtuellen Computer.
Wählen Sie im Abschnitt "Überwachung " die Option "Diagnoseeinstellungen" aus.
Wählen Sie ein Speicherkonto und dann " Überwachung auf Gastebene aktivieren" aus.


Anzeigen von Speicherkontometriken über Azure-Portal (für nicht verwaltete Datenträger)
Für die virtuellen Computer, die nicht verwaltete Datenträger verwenden, ist der Speicher eine sehr wichtige Stufe, wenn wir die E/A-Leistung analysieren möchten. Für speicherbezogene Metriken müssen wir die Diagnose als zusätzlichen Schritt aktivieren:
Identifizieren Sie, welches Speicherkonto (oder welche Konten) Ihre VM verwendet, indem Sie den virtuellen Computer auswählen:
- Wählen Sie im Azure-Portal Ihren virtuellen Computer aus.
- Wählen Sie unter "Einstellungen" die Option "Datenträger" aus, und suchen Sie dann das Speicherkonto, auf dem der Datenträger gespeichert ist.
- Navigieren Sie zum Speicherkonto, und wählen Sie "Metriken" aus.
Erkennen von Leistungsengpässen
Nachdem wir den anfänglichen Einrichtungsvorgang für die erforderlichen Metriken abgeschlossen und die Diagnose für die VM und das zugehörige Speicherkonto aktiviert haben, können wir in die Analysephase wechseln.
Zugreifen auf die Überwachung
Wählen Sie im Azure-Portal die azure-VM aus, die Sie untersuchen möchten, wählen Sie "Metriken" im Abschnitt "Überwachung" und dann eine Metrik aus.

Beobachtungszeitskalen
Um zu bestimmen, ob Ressourcenengpässe vorliegen, überprüfen Sie Ihre Daten. Wenn Sie herausfinden, dass Ihr Computer einwandfrei gelaufen ist, in jüngster Zeit aber nachlassende Leistung gemeldet wurde, überprüfen Sie einen Zeitbereich der Daten, der Leistungsmetriken vor der gemeldeten Änderung sowie während und nach dem Problem umfasst.
Überprüfen der CPU auf Engpässe
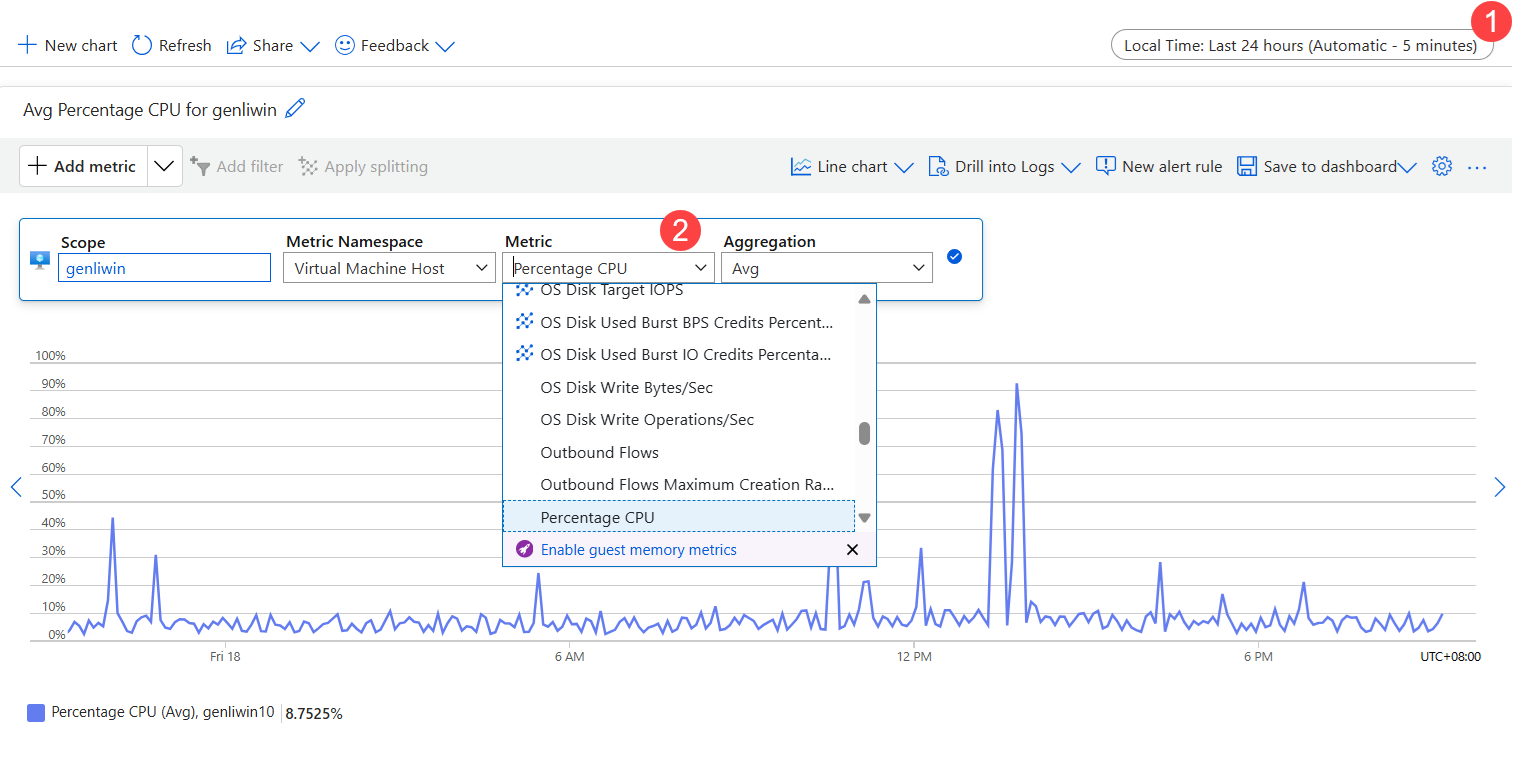
- Legen Sie den Zeitraum fest.
- Wählen Sie in "Metrik" den CPU-Prozentsatz aus.
Überwachen der CPU-Leistungstrends
Seien Sie sich bei der Untersuchung von Leistungsproblemen der Trends bewusst, und bemühen Sie sich darum, sie zu verstehen, wenn sie Sie betreffen. In den nächsten Abschnitten verwenden wir die Überwachungsdiagramme aus dem Portal, um Trends zu veranschaulichen. Sie können außerdem für Querverweise auf abweichendes Ressourcenverhalten innerhalb des gleichen Zeitraums nützlich sein. Klicken Sie zum Anpassen der Diagramme auf Azure Monitor-Datenplattform.
Spitzen: Spitzen können mit einer geplanten Aufgabe/einem bekannten Ereignis zusammenhängen. Wenn Sie die Aufgabe identifizieren können, bestimmen Sie, ob die Aufgabe auf der erforderlichen Leistungsstufe ausgeführt wird. Wenn die Leistung akzeptabel ist, müssen Sie möglicherweise keine weiteren Ressourcen zuweisen.
Steiler Anstieg und Plateau: Zeigt oftmals eine neue Workload an. Wenn die Workload nicht bekannt ist, aktivieren Sie Überwachung in der VM, um herauszufinden, welcher Prozess (oder Prozesse) dieses Verhalten verursacht. Sobald der Prozess bekannt ist, bestimmen Sie, ob sein höherer Ressourcenverbrauch durch ineffizienten Code oder normalen Verbrauch verursacht wird. Wenn es sich um normalen Verbrauch handelt, bestimmen Sie, ob der Prozess auf der normalen Leistungsstufe ausgeführt wird.
Plateau: Bestimmen Sie, ob Ihre VM im Betrieb schon immer dieses Niveau erreichte oder sie erst nach dem Aktivieren der Diagnose auf diesem Niveau ausgeführt wurde. Wenn dies der Fall ist, identifizieren Sie die Prozesse, die das Problem verursachen, und erwägen Sie, mehr von der betroffenen Ressourcen hinzuzufügen.
Stetige Zunahme: Ein ständiger Anstieg im Ressourcenverbrauch ist oftmals entweder auf ineffizienten Code oder auf einen Prozess zurückzuführen, der mehr Benutzerworkload übernimmt.
Wartungsmaßnahmen bei hoher CPU-Auslastung
Wenn Ihre Anwendung oder Ihr Prozess nicht optimal ausgeführt wird und die CPU-Auslastung über 95 % liegt, können Sie eine der folgenden Aufgaben ausführen:
- Zur sofortigen Abhilfe: Erhöhen Sie die Größe der VM auf eine Größe, die mehr Kerne aufweist
- Verstehen des Problems: Bestimmen Sie die Anwendung/den Prozess, und führen Sie eine entsprechende Problembehandlung durch.
Wenn Sie die VM vergrößert haben und die CPU immer noch zu 95 % ausgelastet ist, bestimmen Sie, ob diese Einstellung bessere Leistung oder einen höheren Anwendungsdurchsatz auf einer akzeptablen Stufe bietet. Führen Sie andernfalls eine Problembehandlung der einzelnen Anwendung/des einzelnen Prozesses durch.
Sie können Perfinsights für Windows oder Linux verwenden, um zu analysieren, welcher Prozess für den CPU-Verbrauch verantwortlich ist.
Prüfen auf Speicherengpass
So zeigen Sie die Metriken an:
- Fügen Sie einen Abschnitt hinzu.
- Fügen Sie eine Kachel hinzu.
- Öffnen Sie den Katalog.
- Wählen Sie „Speicherauslastung“ aus, und ziehen Sie das Objekt auf die Kachel. Wenn die Kachel angedockt ist, klicken Sie mit der rechten Maustaste, und wählen Sie 6x4 aus.
Überwachen der Speicherleistungstrends
Die Speicherauslastung zeigt Ihnen, wie viel Arbeitsspeicher von der VM verbraucht wird. Verstehen Sie den Trend, und überprüfen Sie, ob er sich den Zeiten zuordnen lässt, zu denen Sie Probleme beobachten. Sie sollten zu jeder Zeit mehr als 100 MB verfügbaren Arbeitsspeicher haben.
Steiler Anstieg und Plateau/Gleichbleibend hohe Auslastung: Hohe Speicherauslastung ist möglicherweise nicht die Ursache schlechter Leistung, da einige Anwendungen, wie etwa relationale Datenbank-Engines, eine große Menge Arbeitsspeicher zuordnen, und diese Auslastung ist möglicherweise nicht ausreichend. Wenn mehrere speicherhungrige Anwendungen ausgeführt werden, kann jedoch schlechte Leistung aufgrund der Konkurrenz um Arbeitsspeicher auftreten, was zu Zuschneiden und Auslagern auf Datenträger führen kann. Diese schlechte Leistung ist oftmals in erheblichem Maß ursächlich für die Leistung von Anwendungen.
Langsam ansteigender Verbrauch – Dieser Verbrauch deutet auf ein mögliches „Aufwärmen“ der Anwendung hin und tritt häufig bei der Inbetriebnahme von Datenbank-Engines auf. Es könnte jedoch ebenso ein Hinweis auf ein Speicherleck in einer Anwendung sein. Identifizieren Sie die Anwendung, und verstehen Sie, ob es sich um ein erwartetes Verhalten handelt.
Nutzung der Auslagerungsdatei: Überprüfen Sie, ob Sie die Windows-Auslagerungsdatei (die sich unter D: befindet) verwenden oder die Linux-Auslagerungsdatei (auf /dev/sdb) in hohem Maß gebraucht werden. Wenn auf diesen Volumes nichts außer diesen Dateien vorhanden ist, prüfen Sie diese Datenträger auf hohe Vorkommen von Lese-/Schreibvorgängen. Dieses Problem weist auf einen Zustand mit wenig Arbeitsspeicher hin.
Wartungsmaßnahme bei hoher Speicherauslastung
Um hohe Speicherauslastung zu beheben, führen Sie eine der folgenden Aufgaben aus:
- Sofortige Abhilfe bei Nutzung der Auslagerungsdatei: Erhöhen Sie die Größe der VM-Datei auf eine mit mehr Arbeitsspeicher, und führen Sie dann eine Überwachung durch.
- Verstehen des Problems: Spüren Sie Anwendungen/Prozesse auf, und führen Sie dann eine Problembehandlung aus, um Anwendungen mit hohem Speicherverbrauch zu ermitteln.
- Wenn Sie die Anwendung kennen, prüfen Sie, ob die Speicherzuweisung gedeckelt werden kann.
Wenn Sie nach dem Upgrade auf eine größere VM feststellen, dass Sie immer noch eine konstante ständige Zunahme bis 100 % verzeichnen, identifizieren Sie die Anwendung/den Prozess, und führen Sie eine Problembehandlung durch.
Sie können Perfinsights für Windows oder Linux verwenden, um zu analysieren, welcher Prozess für den Arbeitsspeicherverbrauch verantwortlich ist.
Überprüfen auf Datenträgerengpässe (bei nicht verwalteten Datenträgern)
Um das Speichersubsystem der VM zu überprüfen, überprüfen Sie die Diagnoseprotokolle auf der Azure VM-Ebene mithilfe der Leistungsindikatoren in der VM-Diagnose und ebenfalls der Speicherkontodiagnose.
Für die VM-spezifische Problembehandlung können Sie Perfinsights für Windows oder Linux verwenden, um zu analysieren, welcher Prozess die Eingaben/Ausgaben steuert.
Beachten Sie, dass keine Leistungsindikatoren für Zonenredundanz und Premium-Speicherkonten vorhanden sind. Bei Problemen im Zusammenhang mit diesen Leistungsindikatoren öffnen Sie eine Supportanfrage.
Anzeigen der Speicherkontodiagnose in der Überwachung
Um an den Elementen unten zu arbeiten, wechseln Sie zum Speicherkonto für die VM im Portal:
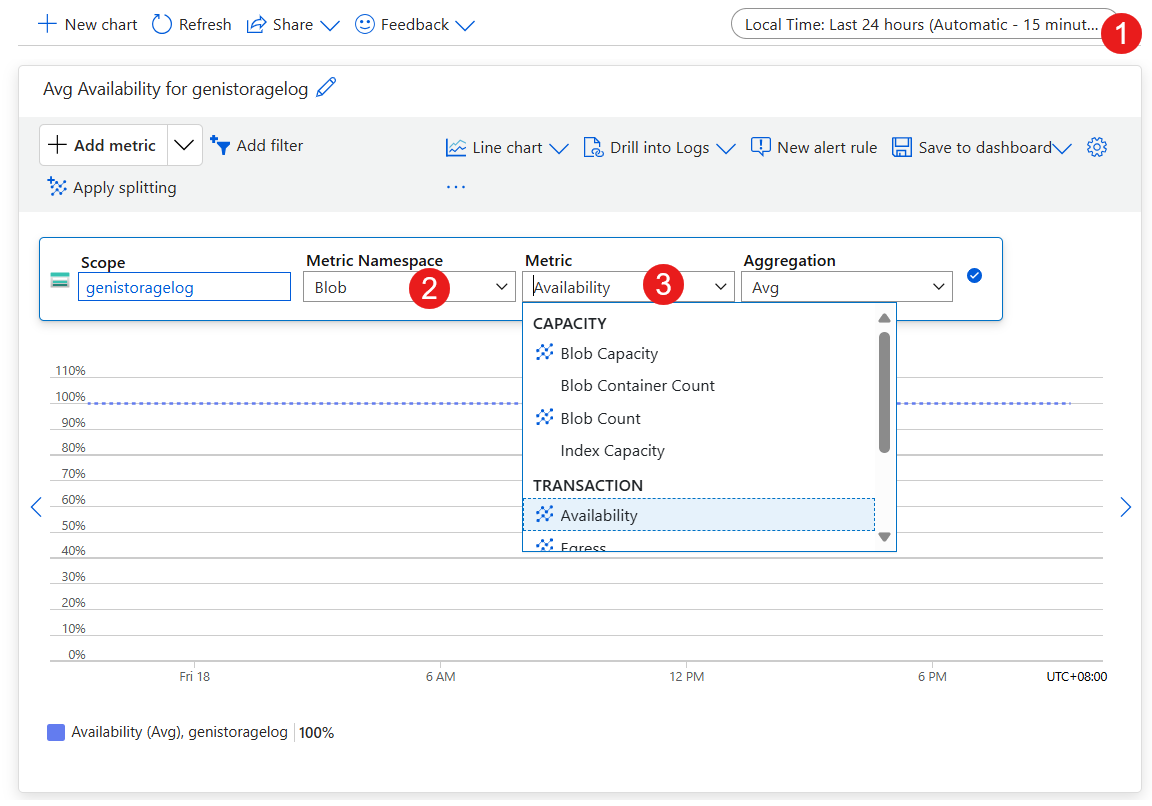
- Legen Sie den Zeitraum fest.
- Legen Sie den metrischen Namespace auf Blob fest.
- Legen Sie die Metrik auf Verfügbarkeit fest.
Überwachen der Datenträgerleistungstrends (nur Standardspeicher)
Um Probleme mit dem Speicher zu erkennen, sehen Sie sich die Leistungsmetriken der Speicherkontodiagnose und der VM-Diagnose an.
Suchen Sie für jede Überprüfung unten nach Schlüsseltrends, wenn die Probleme innerhalb des Zeitraums dieses Problems auftreten.
Überprüfen der Verfügbarkeit von Azure Storage – Hinzufügen der Speicherkontometrik: Verfügbarkeit
Wenn Sie ein Nachlassen der Verfügbarkeit finden, liegt möglicherweise ein Problem mit der Plattform vor, überprüfen Sie den Azure-Status. Wenn hier kein Problem angezeigt wird, öffnen Sie eine neue Supportanfrage.
Prüfen auf Timeouts bei Azure Storage: Fügen Sie die Speicherkontometriken hinzu
- ClientTimeOutError
- ServerTimeOutError
- AverageE2ELatency
- AverageServerLatency
- TotalRequests
Werte in den *TimeOutError-Metriken geben an, dass eine I/O-Operation zu lange gedauert hat und eine Zeitüberschreitung aufgetreten ist. Mit der Durchführung der nächsten Schritte können mögliche Ursachen identifiziert werden.
AverageServerLatency steigt gleichzeitig an – die TimeOutErrors stellen möglicherweise ein Plattformproblem dar. Öffnen Sie in dieser Situation eine neue Supportanfrage.
AverageE2ELatency stellt die Clientlatenz dar. Überprüfen Sie, wie die IOPS von der Anwendung ausgeführt wird. Suchen Sie nach einem Anstieg oder konstant hohen Metriken für TotalRequests. Diese Metrik stellt IOPS dar. Wenn Sie sich den Grenzen des Speicherkontos oder der einzelnen virtuellen Festplatte annähern, ist die Latenz möglicherweise auf Drosselung zurückzuführen.
Prüfen auf Drosselung des Azure Storage – Hinzufügen der Speicherkontometriken: ThrottlingError
Die Werte für die Einschränkung deuten darauf hin, dass Sie auf Speicherkontoebene gedrosselt werden, was bedeutet, dass Ihr IOPS-Limit des Kontos erreicht. Sie können bestimmen, ob Sie sich dem IOPs-Schwellenwert annähern, indem Sie die Metrik TotalRequests überprüfen.
Beachten Sie, dass jede virtuelle Festplatte einen Grenzwert von 500 IOPS oder 60 MBit aufweist, jedoch durch den kumulativen Grenzwert von 20.000 IOPS pro Speicherkonto gebunden ist.
Auf der Grundlage dieser Metrik können Sie nicht bestimmen, welcher Blob die Drosselung bewirkt und welche Blobs von ihr betroffen sind. Klar ist aber, dass Sie entweder den IOPS-Grenzwert oder den eingehenden/ausgehenden Grenzwert des Speicherkontos erreichen.
Um zu bestimmen, ob Sie den IOPS-Grenzwert erreichen, wechseln Sie zur Speicherkontodiagnose, und überprüfen Sie TotalRequests, um festzustellen, ob Sie sich an die 20 tausend TotalRequests annähern. Bestimmen Sie entweder eine Änderung im Muster, ob Sie diesen Grenzwert zum ersten Mal erreichen oder ob dieser Grenzwert zu bestimmten Zeiten erreicht wird.
Mit neuen Datenträgerangeboten unter Storage Standard können die IOPS- und Durchsatzlimits abweichen, aber das kumulative Limit für das Storage Standard-Speicherkonto beträgt 20.000 IOPS (Storage Premium hat unterschiedliche Grenzwerte auf Konto- oder Datenträgerebene). Weitere Informationen zu Storage Standard-Datenträgerangeboten und Grenzwerten pro Datenträger:
References
Die Bandbreite des Speicherkontos wird mithilfe folgender Speicherkontometriken gemessen: TotalIngress und TotalEgress. Je nach Art der Redundanz und Regionen gibt es unterschiedliche Schwellenwerte für Bandbreite:
- Skalierbarkeits- und Leistungsziele für Storage Standard-Konten
- Skalierungs- und Leistungsziele für Seitenblob-Speicherkonten mit Premium-Leistung
Vergleichen Sie TotalIngress und TotalEgress mit den Grenzwerten für Ingress und Egress für den Redundanztyp und die Region des Speicherkontos.
Überprüfen Sie die Grenzwerte für den Durchsatz der mit der VM verbundenen VHDs. Fügen Sie die VM-Metriken „Datenträgerlesevorgänge“ und „Datenträgerschreibvorgänge“ hinzu.
Neue Datenträgerangebote in Storage Standard weisen unterschiedliche IOPS- und Durchsatzlimits auf (IOPS werden nicht pro VHD verfügbar gemacht). Sehen Sie sich die Daten an, um festzustellen, ob Sie auf der Grundlage der Datenlese- und -schreibvorgänge die Grenzwerte des kombinierten Durchsatzes in MB der VHD(s) erreichen, und optimieren Sie dann Ihre VM-Speicherkonfiguration, um eine Skalierung jenseits der Grenzwerte einzelner VHDs zu erreichen. Weitere Informationen zu Storage Standard-Datenträgerangeboten und Grenzwerten pro Datenträger:
Wartung bei hoher Datenträgerverwendung/Latenz
Verringern der Clientlatenz und Optimieren der VM-E/A, um eine Skalierung jenseits der VHD-Grenzwerte zu erreichen
Verringern der Drosselung
Wenn die oberen Grenzwerte von Speicherkonten erreicht werden, gleichen Sie die VHDs zwischen den einzelnen Speicherkonten neu aus. Informationen hierzu finden Sie unter Skalierbarkeits- und Leistungsziele für Azure Storage.
Vergrößern des Durchsatzes und Verringern der Latenz
Wenn Sie eine für Latenz anfällige Anwendung ausführen und hohen Durchsatz benötigen, migrieren Sie Ihre VHDs zu Azure Premium Storage, indem Sie VMs der DS- und GS-Reihe verwenden.
Die spezifischen Szenarien werden in diesen Artikeln besprochen:
Kontaktieren Sie uns für Hilfe
Wenn Sie Fragen haben oder Hilfe mit Ihren Azure-Gutschriften benötigen, dann erstellen Sie beim Azure-Support eine Support-Anforderung oder fragen Sie den Azure Community-Support. Sie können auch Produktfeedback an die Azure Feedback Community senden.