Der virtuelle Azure Linux-Computer kann nach dem Anwenden von Kerneländerungen nicht gestartet werden
Gilt für: ✔️ Linux-VMs
Notiz
CentOS, auf das in diesem Artikel verwiesen wird, ist eine Linux-Verteilung und wird End Of Life (EOL) erreichen. Sie sollten sich Ihre Nutzung dieser Distribution ansehen und entsprechend planen. Weitere Informationen finden Sie unter CentOS End Of Life Guidance.
Dieser Artikel enthält Lösungen für ein Problem, bei dem ein virtueller Linux-Computer (VM) nach der Anwendung von Kerneländerungen nicht starten kann.
Voraussetzungen
Stellen Sie sicher, dass die serielle Konsole in der Linux-VM aktiviert und funktionsfähig ist.
Identifizieren des Kernel-bezogenen Startproblems
Um ein Kernel-bezogenes Startproblem zu identifizieren, überprüfen Sie die spezifische Kernel-Panikzeichenfolge. Verwenden Sie dazu die Azure CLI oder die Azure-Portal, um die Ausgabe des seriellen Konsolenprotokolls der VM im Startdiagnosebereich oder im seriellen Konsolenbereich anzuzeigen.
Eine Kernel-Panik sieht wie die folgende Ausgabe aus und wird am Ende des seriellen Konsolenprotokolls angezeigt:
Probing EDD (edd=off to disable)... ok
Memory KASLR using RDRAND RDTSC...
[ 300.206297] Kernel panic - xxxxxxxx
[ 300.207216] CPU: 1 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.xxx.x86_64 #1
Onlineproblembehandlung
Tipp
Wenn Sie über eine kürzliche Sicherung der VM verfügen, stellen Sie den virtuellen Computer aus der Sicherung wieder her, um das Startproblem zu beheben.
Die serielle Konsole ist die schnellste Methode zum Beheben des Startproblems. Es ermöglicht Ihnen, das Problem direkt zu beheben, ohne den Systemdatenträger auf einer Wiederherstellungs-VM präsentieren zu müssen. Stellen Sie sicher, dass Sie die erforderlichen Voraussetzungen für Ihre Verteilung erfüllen. Weitere Informationen finden Sie in der seriellen Konsole für virtuelle Computer für Linux.
Identifizieren Sie das spezifische Kernel-bezogene Startproblem.
Verwenden Sie die serielle Azure-Konsole , um Ihren virtuellen Computer im GRUB-Menü zu unterbrechen, und wählen Sie einen vorherigen Kernel aus, um ihn zu starten. Weitere Informationen finden Sie unter boot system on older kernel version.
Wechseln Sie zum entsprechenden Abschnitt, um das spezifische Kernel-bezogene Startproblem zu beheben:
Nachdem das Kernel-bezogene Startproblem behoben wurde, starten Sie den virtuellen Computer neu, damit er über die neueste Kernelversion starten kann.
Offlineproblembehandlung
Tipp
Wenn Sie über eine kürzliche Sicherung der VM verfügen, stellen Sie den virtuellen Computer aus der Sicherung wieder her, um das Startproblem zu beheben.
Wenn die serielle Azure-Konsole nicht in der jeweiligen VM funktioniert oder keine Option in Ihrem Abonnement ist, beheben Sie das Startproblem mithilfe einer Rettungs-/Reparatur-VM. Gehen Sie dazu wie folgt vor:
Verwenden Sie VM-Reparaturbefehle, um eine Reparatur-VM zu erstellen, an die eine Kopie des Betriebssystemdatenträgers der betroffenen VM angehängt ist. Mounten Sie die Kopie der OS-Dateisysteme in der Reparatur-VM mithilfe von chroot.
Notiz
Alternativ können Sie mithilfe des Azure-Portals manuell eine Rettungs-VM erstellen. Weitere Informationen finden Sie unter Beheben von Problemen mit einer Linux-VM durch Hinzufügen des Betriebssystemdatenträgers zu einer Wiederherstellungs-VM im Azure-Portal.
Identifizieren Sie das spezifische Kernel-bezogene Startproblem.
Wechseln Sie zum entsprechenden Abschnitt, um das spezifische Kernel-bezogene Startproblem zu beheben:
Führen Sie nach der Behebung des Kernel-bezogenen Startproblems die folgenden Aktionen aus:
- Beenden Sie chroot.
- Entfernen Sie die Kopie der Dateisysteme von der Rettungs-/Reparatur-VM.
- Führen Sie den Befehl
az vm repair restoreaus, um den reparierten Betriebssystemdatenträger durch den ursprünglichen Betriebssystemdatenträger der VM auszutauschen. Weitere Informationen finden Sie unter Schritt 5 in Reparieren eines virtuellen Linux-Computers mit dem Reparaturbefehlen virtueller Azure-Computer. - Überprüfen Sie, ob die VM gestartet werden kann, indem Sie einen Blick auf die serielle Azure-Konsole werfen oder versuchen, eine Verbindung zur VM herzustellen.
Wenn wichtige kernelbezogene Inhalte vorhanden sind, fehlen die gesamte
/bootPartition oder andere wichtige Inhalte, und sie können nicht wiederhergestellt werden, wir empfehlen, den virtuellen Computer aus einer Sicherung wiederherzustellen. Weitere Informationen finden Sie unter Wiederherstellen von Azure-VM-Daten im Azure-Portal.
Startsystem auf einer älteren Kernelversion
Verwenden der seriellen Azure-Konsole
Starten Sie den virtuellen Computer mithilfe der seriellen Azure-Konsole neu.
- Wählen Sie oben im seriellen Konsolenfenster die Schaltfläche zum Herunterfahren aus.
- Wählen Sie die Option "VM neu starten" (Hard) aus.
Sobald die serielle Konsolenverbindung fortgesetzt wird, wird in der linken oberen Ecke des seriellen Konsolenfensters ein Countdownzähler angezeigt. Drücken Sie die ESCAPE-TASTE , um Ihren virtuellen Computer im GRUB-Menü zu unterbrechen.
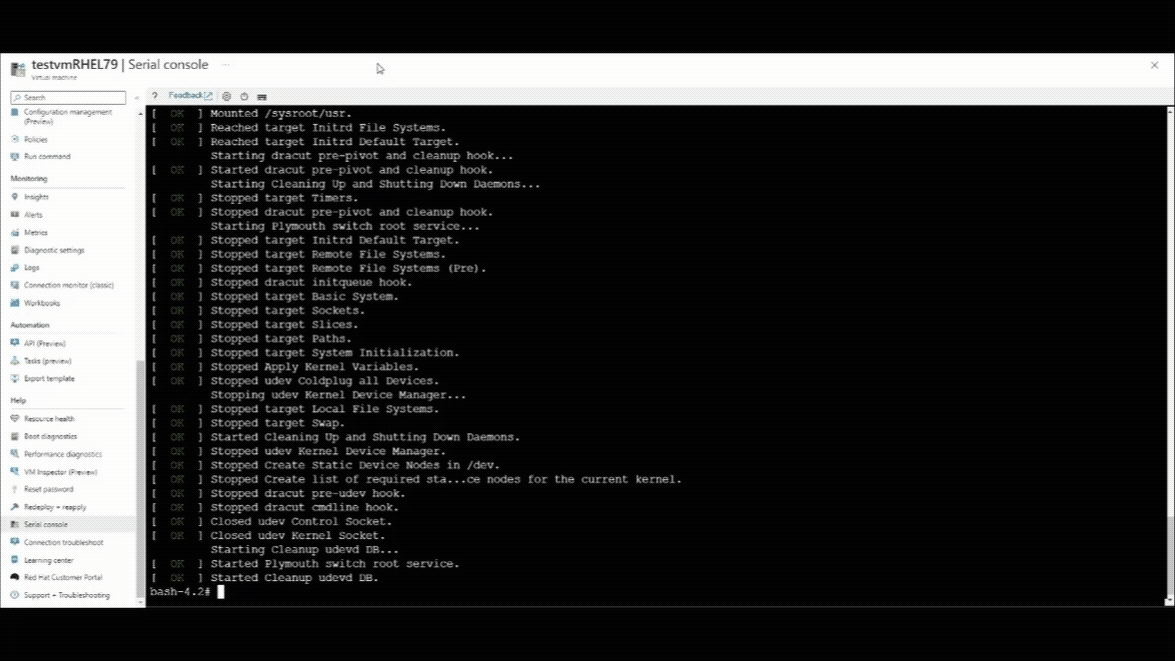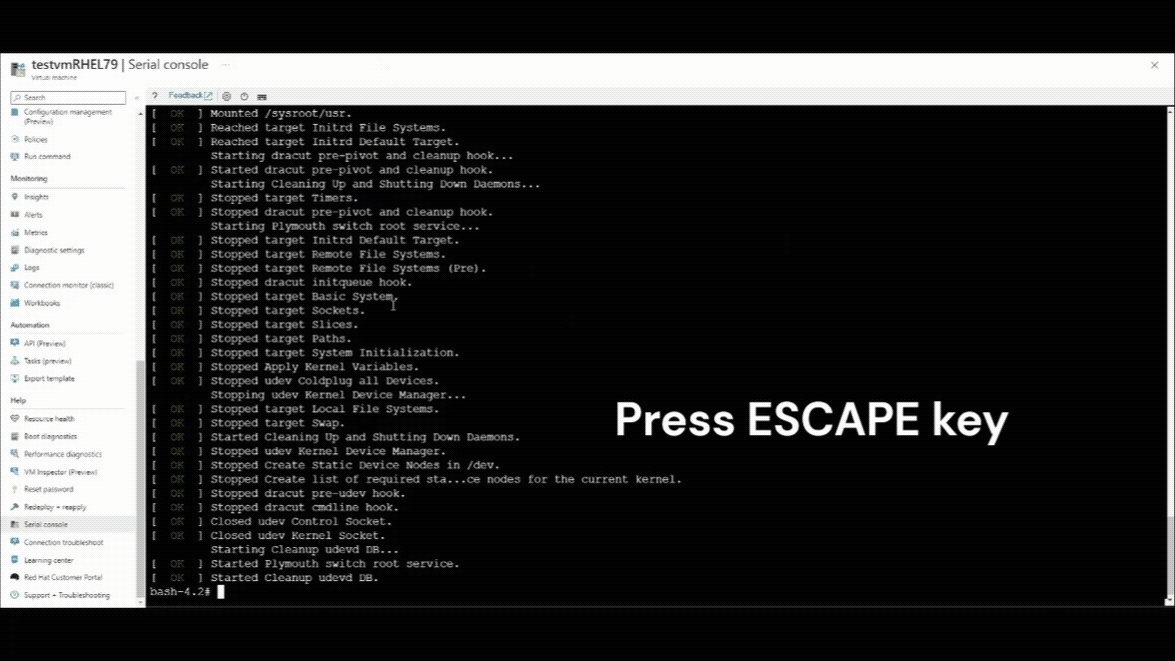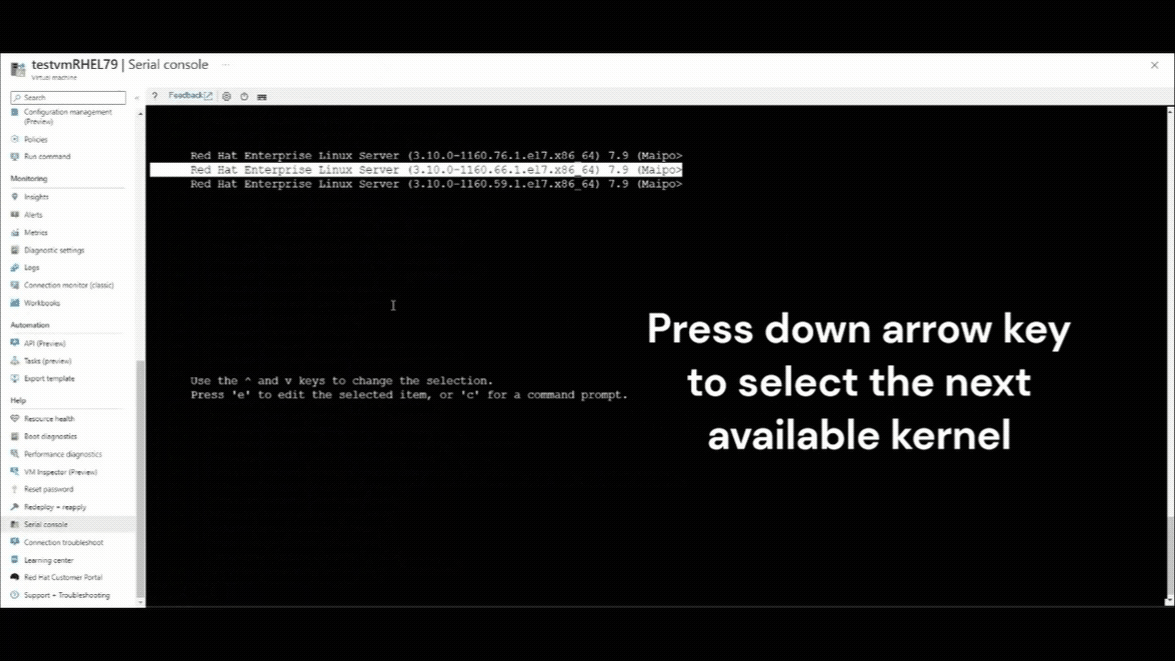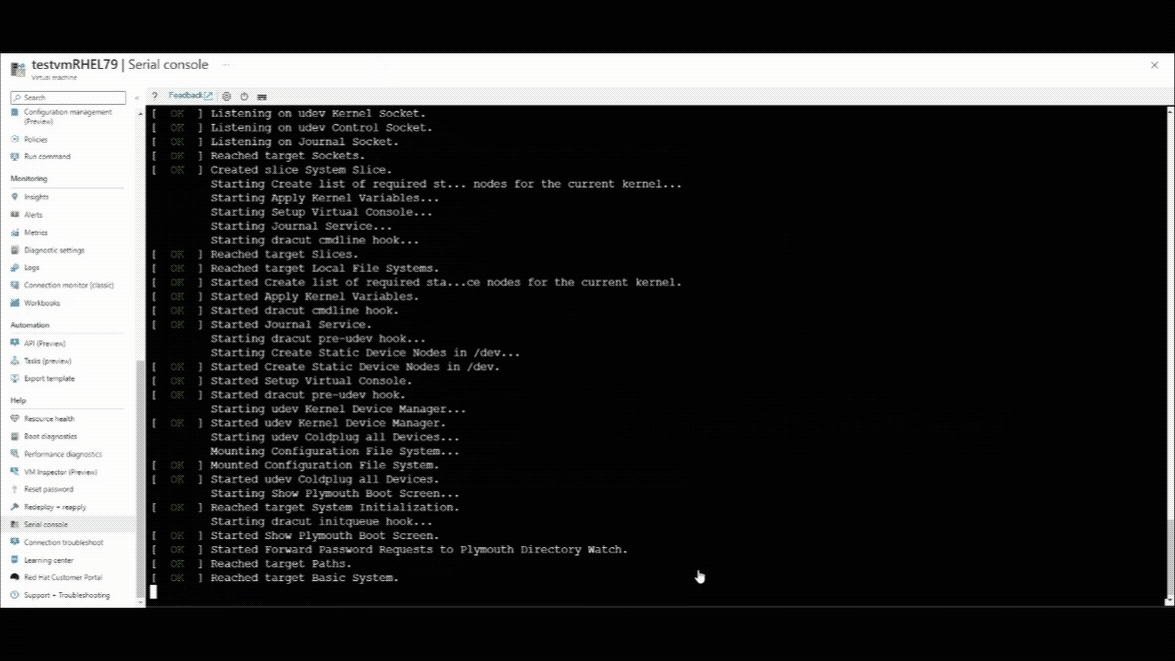
Drücken Sie die NACH-UNTEN-TASTE, um eine beliebige frühere Kernelversion auszuwählen.
Ändern Sie die Variable in der
GRUB_DEFAULTDatei "/etc/default/grub", wie in der Standard kernelversion manuell dargestellt. Dies ist eine dauerhafte Änderung.

Notiz
Wenn nur eine Kernelversion im GRUB-Menü aufgeführt ist, befolgen Sie den Ansatz zur Offline-Problembehandlung , um dieses Problem von einer Reparatur-VM zu beheben.
Verwenden der Reparatur-VM (ALAR-Skripts)
Führen Sie den folgenden Bash-Befehl in Azure Cloud Shell aus, um eine Reparatur-VM zu erstellen. Weitere Informationen finden Sie unter Verwenden der Azure Linux Auto Repair (ALAR) zum Beheben einer Linux-VM - Kerneloption.
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopyFühren Sie den folgenden Befehl aus, um den fehlerhaften Kernel durch die zuvor installierte Version zu ersetzen:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters kernel --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAME
Notiz
Wenn nur eine Kernelversion im System installiert ist, befolgen Sie den Ansatz zur Offline-Problembehandlung , um dieses Problem von einer Reparatur-VM zu beheben.
Manuelles Ändern der Standard-Kernelversion
Führen Sie die folgenden Schritte aus, um die Standard-Kernelversion von einer Reparatur-VM (innerhalb von chroot) oder auf einer ausgeführten VM zu ändern:
Notiz
Wenn ein Kernel-Downgrade-Rollback abgeschlossen ist, wählen Sie die neueste Kernelversion anstelle der älteren Version aus.
RHEL 7, Oracle Linux 7 und CentOS 7
Überprüfen Sie die Liste der verfügbaren Kernels in der GRUB-Konfigurationsdatei, indem Sie einen der folgenden Befehle ausführen:
Gen1 VMs:
cat /boot/grub2/grub.cfg | grep menuentryGen2-VMs:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
Legen Sie den neuen Standardkernkern fest, und geben Sie den entsprechenden Kerneltitel an, indem Sie den folgenden Befehl ausführen:
# grub2-set-default 'Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64'Notiz
Ersetzen Sie den
Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64entsprechenden Menüeintragstitel.Überprüfen Sie, ob der neue Standard kernel der gewünschte ist, indem Sie den folgenden Befehl ausführen:
grub2-editenv listStellen Sie sicher, dass der Wert der
GRUB_DEFAULTVariablen in der Datei "/etc/default/grub " auf "saved. Um sie zu ändern, stellen Sie sicher, dass Sie die GRUB-Konfigurationsdatei neu erstellen, um die Änderungen anzuwenden.
RHEL 8/9 und CentOS 8
Listen Sie die verfügbaren Kernel auf, indem Sie den folgenden Befehl ausführen:
ls -l /boot/vmlinuz-*Legen Sie den neuen Standardkernkern fest, indem Sie den folgenden Befehl ausführen:
grubby --set-default /boot/vmlinuz-4.18.0-372.19.1.el8_6.x86_64Notiz
Ersetzen Sie diese
4.18.0-372.19.1.el8_6.x86_64durch die entsprechende Kernelversion.Überprüfen Sie, ob der neue Standard kernel der gewünschte ist, indem Sie den folgenden Befehl ausführen:
grubby --default-kernel
SLES 12/15, Ubuntu 18.04/20.04
Listen Sie die verfügbaren Kernel in der GRUB-Konfigurationsdatei auf, indem Sie den folgenden Befehl ausführen:
Gen1 VMs:
SLES 12/15:
cat /boot/grub2/grub.cfg | grep menuentryUbuntu 18.04/20.04:
cat /boot/grub/grub.cfg | grep menuentry
Gen2-VMs:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
Legen Sie den neuen Standardkernkern fest, indem Sie den Wert der Variablen in der
GRUB_DEFAULTDatei "/etc/default/grub" ändern. Für die neueste Kernelversion, die im System installiert ist, lautet der Standardwert 0. Der nächste verfügbare Kernel ist auf "1>2" festgelegt.vi /etc/default/grub GRUB_DEFAULT="1>2"Notiz
Weitere Informationen zum Konfigurieren der
GRUB_DEFAULTVariablen finden Sie unter SUSE Boot Loader GRUB2 und Ubuntu Grub2/Setup. Als Referenz: Der Wert des Menüs der obersten Ebene ist 0, der erste Untermenüwert der obersten Ebene ist 1, und jeder geschachtelte Menuentrywert beginnt mit 0. Beispielsweise ist "1>2" der dritte Menuentry aus dem ersten Untermenü.Generieren Sie die GRUB-Konfigurationsdatei neu, um die Änderungen anzuwenden. Befolgen Sie die Anweisungen in "GRUB neu installieren" und generieren Sie die GRUB-Konfigurationsdatei für die entsprechende Linux-Verteilung und VM-Generation.
Kernel-Panik - nicht synchronisiert: VFS: Root fs kann nicht auf unbekannten Block (0,0) bereitgestellt werden.
Dieser Fehler tritt aufgrund eines aktuellen Systemupdates (Kernel) auf. Es ist am häufigsten in RHEL-basierten Verteilungen zu sehen. Sie können dieses Problem über die serielle Azure-Konsole identifizieren. Es wird eine der folgenden Fehlermeldungen angezeigt:
"Kernel-Panik - nicht synchronisiert: VFS: Root fs kann nicht auf unbekannten Block (0,0)" bereitgestellt werden.
[ 301.026129] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) [ 301.027122] CPU: 0 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.10.0-1160.36.2.el7.x86_64 #1 [ 301.027122] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090008 12/07/2018 [ 301.027122] Call Trace: [ 301.027122] [<ffffffff82383559>] dump_stack+0x19/0x1b [ 301.027122] [<ffffffff8237d261>] panic+0xe8/0x21f [ 301.027122] [<ffffffff8298b794>] mount_block_root+0x291/0x2a0 [ 301.027122] [<ffffffff8298b7f6>] mount_root+0x53/0x56 [ 301.027122] [<ffffffff8298b935>] prepare_namespace+0x13c/0x174 [ 301.027122] [<ffffffff8298b412>] kernel_init_freeable+0x222/0x249 [ 301.027122] [<ffffffff8298ab28>] ? initcall_blcklist+0xb0/0xb0 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] [<ffffffff8237235e>] kernel_init+0xe/0x100 [ 301.027122] [<ffffffff82395df7>] ret_from_fork_nospec_begin+0x21/0x21 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] Kernel Offset: 0xc00000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)"fehler: Datei '/initramfs-*.img' nicht gefunden"
fehler: Datei '/initramfs-3.10.0-1160.36.2.el7.x86_64.img' nicht gefunden.
Diese Art von Fehler gibt an, dass die Initramfs-Datei nicht generiert wird, die GRUB-Konfigurationsdatei den initrd-Eintrag nach einem Patchvorgang fehlt, oder eine manuelle GRUB-Konfiguration.
Vor dem Neustart eines Servers wird empfohlen, die GRUB-Konfiguration und /boot den Inhalt zu überprüfen, wenn ein Kernelupdate vorhanden ist, indem sie einen der folgenden Befehle ausführen. Es ist wichtig, sicherzustellen, dass das Update abgeschlossen ist und es keine fehlenden Initramfs-Dateien gibt.
BIOS-basiert - Gen1-Systeme
# ls -l /boot # cat /boot/grub2/grub.cfgUEFI-basiert - Gen2-Systeme
# ls -l /boot # cat /boot/efi/EFI/*/grub.cfg
Generieren fehlender Initramfs mithilfe von Azure Repair VM ALAR-Skripts
Erstellen Sie eine Reparatur-VM, indem Sie die folgende Bash-Befehlszeile mit Azure Cloud Shell ausführen. Weitere Informationen finden Sie unter Verwenden der Automatischen Reparatur von Azure Linux (ALAR), um eine Linux-VM zu reparieren .
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopyRegenerieren Sie das Initrd/Initramfs-Image, und generieren Sie die GRUB-Konfigurationsdatei neu, wenn der initrd-Eintrag fehlt. Führen Sie zu diesem Zweck den folgenden Befehl aus:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters initrd --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAMENachdem der Wiederherstellungsbefehl ausgeführt wurde, starten Sie den ursprünglichen virtuellen Computer neu, und überprüfen Sie, ob er gestartet werden kann.
Manuelles Generieren fehlender Initramfs
Wichtig
- Wenn Sie die VM mithilfe einer früheren Kernelversion oder innerhalb von chroot aus der Reparatur-/Rettungs-VM starten können, generieren Sie fehlende Initramfs manuell neu.
- Um fehlende Initramfs manuell von einer Reparatur-VM neu zu generieren, stellen Sie sicher, dass Schritt 1 in der Offline-Problembehandlung bereits befolgt wurde und diese Befehle in chroot ausgeführt werden.
Identifizieren Sie die spezifische Kernelversion, die Probleme beim Starten hat. Sie können die Versionsinformationen aus dem entsprechenden Kernel-Panikfehler extrahieren.
Sehen Sie sich den folgenden Screenshot als Beispiel an. Der Kernel-Panikfehler zeigt, dass die Kernelversion "3.10.0-1160.59.1.el7.x86_64" lautet:
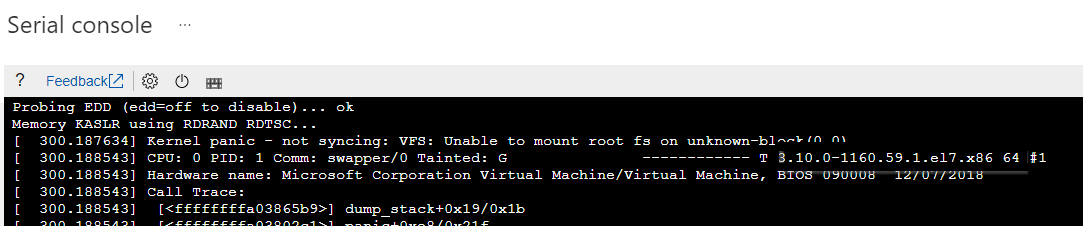
Generieren Sie die fehlende Initramfs-Datei neu, indem Sie einen der folgenden Befehle ausführen:
RHEL/CentOS/Oracle Linux 7/8
sudo depmod -a 3.10.0-1160.59.1.el7.x86_64 sudo dracut -f /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img 3.10.0-1160.59.1.el7.x86_64Wichtig
Ersetzen Sie diese
3.10.0-1160.59.1.el7.x86_64durch die entsprechende Kernelversion.SLES 12/15
sudo depmod -a 5.3.18-150300.38.53-azure sudo dracut -f /boot/initrd-5.3.18-150300.38.53-azure 5.3.18-150300.38.53-azureWichtig
Ersetzen Sie diese
5.3.18-150300.38.53-azuredurch die entsprechende Kernelversion.Ubuntu 18.04
sudo depmod -a 5.4.0-1077-azure sudo mkinitramfs -k -o /boot/initrd.img-5.4.0-1077-azureWichtig
Ersetzen Sie diese
5.4.0-1077-azuredurch die entsprechende Kernelversion.
Generieren Sie die GRUB-Konfigurationsdatei neu. Befolgen Sie die Anweisungen in der Neuinstallation von GRUB und generieren Sie die GRUB-Konfigurationsdatei für die entsprechende Linux-Verteilung und VM-Generation.
Wenn die obigen Schritte von einer Reparatur-VM ausgeführt werden, führen Sie Schritt 3 in der Offline-Problembehandlung aus. Wenn die obigen Schritte über die serielle Azure-Konsole ausgeführt werden, führen Sie die Online-Problembehandlungsmethode aus .
Starten Sie Ihren virtuellen Computer über die neueste Kernelversion neu.
Kernel-Panik - nicht synchronisiert: Versucht, init zu töten
Identifizieren Sie dieses Problem über die serielle Azure-Konsole. Die Ausgabe wird wie folgt angezeigt:
dracut Warning: Boot has failed. To debug this issue add "rdshell" to the kernel command line.
Kernel panic - not syncing: Attempted to kill init!
Pid: 1, comm: init Not tainted 2.6.32-754.17.1.el6.x86_64 #1
Call Trace:
[<ffffffff81558bfa>] ? panic+0xa7/0x18b
[<ffffffff81130370>] ? perf_event_exit_task+0xc0/0x340
[<ffffffff81086433>] ? do_exit+0x853/0x860
[<ffffffff811a33b5>] ? fput+0x25/0x30
[<ffffffff81564272>] ? system_call_after_swapgs+0xa2/0x152
[<ffffffff81086498>] ? do_group_exit+0x58/0xd0
[<ffffffff81086527>] ? sys_exit_group+0x17/0x20
[<ffffffff81564357>] ? system_call_fastpath+0x35/0x3a
[<ffffffff8156427e>] ? system_call_after_swapgs+0xae/0x152
Diese Art von Kernel-Panik tritt aufgrund der folgenden möglichen Ursachen auf:
Weitere Informationen und Lösungen finden Sie in den folgenden Abschnitten. Stellen Sie sicher, dass die Befehle von einer Reparatur-/Rettungs-VM in einer chroot-Umgebung ausgeführt werden, wie in der Offline-Problembehandlung angegeben.
Fehlende wichtige Dateien und Verzeichnisse
Wichtige Linux-Dateien und Verzeichnisse fehlen aufgrund eines menschlichen Fehlers. Beispielsweise werden Dateien versehentlich gelöscht oder Dateisystembeschädigungen.
Überprüfen Sie den Inhalt des Betriebssystemdatenträgers nach dem Anfügen der Kopie des Betriebssystemdatenträgers an eine Reparatur-VM, und fügen Sie die entsprechenden Dateisysteme mithilfe von chroot an. Sie können die Ausgaben mit den Ausgaben einer funktionierenden VM vergleichen, auf der dieselbe Betriebssystemversion ausgeführt wird.
ls -l / ls -l /usr/lib ls -l /usr/lib64 ls -lR / | moreStellen Sie die fehlenden Dateien aus einer Sicherung wieder her. Weitere Informationen finden Sie unter "Wiederherstellen von Dateien aus der Sicherung des virtuellen Azure-Computers". Je nach Anzahl fehlender Dateien ist es möglicherweise besser, eine vollständige VM-Wiederherstellung auszuführen. Weitere Informationen finden Sie unter Wiederherstellen von Azure-VM-Daten im Azure-Portal.
Fehlende wichtige Systemkernbibliotheken und -pakete
Wichtige Systemkernbibliotheken, Dateien oder Pakete werden aus dem System gelöscht oder beschädigt. Um dieses Problem zu beheben, installieren Sie die betroffenen Bibliotheken, Dateien oder Pakete erneut. Diese Lösung funktioniert auf RPM-basierten Verteilungen wie Red Hat/CentOS/SUSE VMs. Für andere Linux-Distributionen empfehlen wir, den virtuellen Computer aus der Sicherung wiederherzustellen.
Führen Sie die folgenden Schritte aus, um die Neuinstallation auszuführen:
Erstellen Sie einen virtuellen Rettungscomputer mithilfe eines unformatierten Images mit derselben Betriebssystemversion und Generierung wie die betroffene VM.
Greifen Sie auf die Chroot-Umgebung in der Rettungs-VM zu, um das Problem zu beheben.
sudo chroot /rescueDie Befehlsausgabe gibt an, welche Bibliothek fehlt oder beschädigt ist, wie unten dargestellt:
/bin/bash: error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directoryÜberprüfen Sie alle Systempakete und ihren entsprechenden Status auf dem virtuellen Rettungscomputer. Vergleichen Sie die Ausgabe mit einer fehlerfreien VM, auf der dieselbe Betriebssystemversion ausgeführt wird.
sudo rpm --verify --all --root=/rescueDies ist ein Beispiel für die Befehlsausgabe:
error: Failed to dlopen /usr/lib64/rpm-plugins/systemd_inhibit.so /lib64/librt.so.1: undefined symbol: __pthread_attr_copy, version GLIBC_PRIVATE S.5....T. c /etc/dnf/dnf.conf S.5....T. c /etc/ssh/sshd_config .M....... /boot/efi/EFI/BOOT/BOOTX64.EFI .M....... /boot/efi/EFI/BOOT/fbx64.efi .M....... /boot/efi/EFI/redhat/BOOTX64.CSV .M....... /boot/efi/EFI/redhat/mmx64.efi .M....... /boot/efi/EFI/redhat/shimx64-redhat.efi .M....... /boot/efi/EFI/redhat/shimx64.efi missing /run/motd.d .M....... g /var/spool/anacron/cron.daily .M....... g /var/spool/anacron/cron.monthly .M....... g /var/spool/anacron/cron.weekly missing /lib64/libc-2.28.so <------- .M....... /boot/efi/EFI/redhat S.5....T. c /etc/security/pwquality.confDie Ausgabezeile
missing /lib64/libc-2.28.sobezieht sich auf den vorherigen Fehler in Schritt 2 und gibt an, dass das libc-2.28.so Paket fehlt. Das libc-2.28.so-Paket kann jedoch geändert werden. In diesem Fall wird.M.....die Ausgabe anstelle vonmissing. Das libc-2.28.so-Paket wird als Beispiel in den folgenden Schritten referenziert.Überprüfen Sie im virtuellen Rettungscomputer, welches Paket die Bibliothek /lib64/libc-2.28.so enthält.
sudo rpm -qf /lib64/libc-2.28.soglibc-2.28-127.0.1.el8.x86_64Notiz
Die Ausgabe zeigt das Paket an, das neu installiert werden muss, einschließlich des Paketnamens und der Version. Die Paketversion unterscheidet sich möglicherweise von der version, die auf dem betroffenen virtuellen Computer installiert ist.
Überprüfen Sie auf der betroffenen VM, welche Version des glibc-Pakets installiert ist.
sudo rpm -qa --all --root=/rescue | grep -i glibcglibc-common-2.28-211.0.1.el8.x86_64 glibc-gconv-extra-2.28-211.0.1.el8.x86_64 glibc-2.28-211.0.1.el8.x86_64 <---- glibc-langpack-en-2.28-211.0.1.el8.x86_64Laden Sie das Paket glibc-2.28-211.0.1.el8.x86_64 herunter. Sie können es von der offiziellen Website des Betriebssystemanbieters oder von der Rettungs-VM herunterladen, indem Sie ein Paketverwaltungstool wie
yumdownloaderoderzypper install --download-only <packagename>je nach ausgeführtem Betriebssystem verwenden.Hier ist ein Beispiel für die Verwendung des
yumdownloaderTools:cd /tmp sudo yumdownloader glibc-2.28-211.0.1.el8.x86_64Last metadata expiration check: 0:03:24 ago on Thu 25 May 2023 02:36:25 PM UTC. glibc-2.28-211.0.1.el8.x86_64.rpm 8.7 MB/s | 2.2 MB 00:00Installieren Sie das betroffene Paket im virtuellen Rettungscomputer erneut.
sudo rpm -ivh --root=/rescue /tmp/glibc-*.rpm --replacepkgs --replacefileswarning: /tmp/glibc-2.28-211.0.1.el8.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID ad986da3: NOKEY Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing... 1:glibc-2.28-211.0.1.el8 ################################# [100%]Greifen Sie auf die chroot-Umgebung in der Rettungs-VM zu, um die Neuinstallation zu überprüfen.
sudo chroot /rescueDeaktivieren Sie den virtuellen Rettungscomputer, und tauschen Sie den Betriebssystemdatenträger auf den betroffenen virtuellen Computer aus.
Falsche Dateiberechtigungen
Falsche systemweite Dateiberechtigungen werden aufgrund eines menschlichen Fehlers geändert (z. B. wird jemand auf / oder anderen wichtigen Betriebssystemdateisystemen ausgeführtchmod 777). Um dieses Problem zu beheben, stellen Sie die Dateiberechtigungen wieder her. Diese Lösung funktioniert auf RPM-basierten Verteilungen wie Red Hat/CentOS/SUSE VMs. Für andere Linux-Distributionen empfehlen wir, den virtuellen Computer aus der Sicherung wiederherzustellen.
Führen Sie zum Wiederherstellen der Dateiberechtigungen den folgenden Befehl aus, nachdem Sie die Kopie des Betriebssystemdatenträgers an eine Reparatur-VM angefügt und die entsprechenden Dateisysteme mithilfe von chroot bereitgestellt haben:
rpm -a --setperms
rpm --setugids --all
chmod u+s /bin/sudo
chmod 660 /etc/sudoers.d/*
chmod 644 /etc/ssh/*.pub
chmod 640 /etc/ssh/*.key
Notiz
Führen Sie diesen Befehl nicht für die Ausführung von Produktionssystemen aus.
Wenn das Problem nach der manuellen Wiederherstellung der entsprechenden Dateiberechtigungen noch vorhanden ist, führen Sie eine Wiederherstellung aus der Sicherung aus.
Fehlende Partitionen
In Fällen, in denen /usr, /opt, /var, /home, /tmpund / Dateisysteme auf verschiedene Partitionen verteilt sind, können die Daten aufgrund von Problemen auf partitionsebene nicht zugänglich sein, was möglicherweise durch Fehler bei Partitionsänderungsvorgängen oder anderen verursacht wird.
Wenn Sie in diesem Szenario das ursprüngliche Partitionstabellenlayout dokumentieren, mit den genauen Anfangs- und Endbereichen für jede der ursprünglichen Partitionen, und keine weiteren Änderungen am System vorgenommen werden, z. B. die Erstellung neuer Dateisysteme, erstellen Sie die Partitionen neu, indem Sie dasselbe ursprüngliche Layout mit Tools wie fdisk (für MBR-Partitionstabellen) oder gdisk (für GPT-Partitionstabellen) verwenden, um Zugriff auf das fehlende Dateisystem zu erhalten.
Wenn dieser Ansatz nicht funktioniert, führen Sie eine Wiederherstellung aus der Sicherung aus.
SELinux-Probleme
Falsche SELinux-Berechtigungen verhindern möglicherweise, dass das System auf wichtige Dateien zugreift. Gehen Sie folgendermaßen vor, um das Problem zu beheben:
Um zu überprüfen, ob das System Aufgrund falscher SELinux-Berechtigungen Probleme hat, starten Sie das System mit deaktivierter SELinux, indem Sie die Selinux=0-Kerneloption zur GRUB linux16-Zeile hinzufügen.
Wenn das System gestartet werden kann, führen Sie den folgenden Befehl aus, um eine SELinux-Neubezeichnung zur Startzeit auszulösen und das System neu zu starten:
touch /.autorelabelWenn der virtuelle Computer immer noch nicht gestartet werden kann, führen Sie eine vollständige VM-Wiederherstellung aus der Sicherung aus. Weitere Informationen finden Sie unter Wiederherstellen von Azure-VM-Daten im Azure-Portal.
Andere kernelbezogene Startprobleme
In diesem Artikel werden die am häufigsten in Azure identifizierten Linux-Kernel-Paniken behandelt. Weitere Informationen zu allgemeinen Kernel-Panikszenarien finden Sie unter Kernel-Panik in Azure Linux-VMs – Allgemeine Kernel-Panikereignisse.
Es gibt einige andere wichtige mögliche Kernel-Panik, die möglicherweise keinen Start oder keine Secure Shell (SSH)-Szenarien verursachen.
Stellen Sie sicher, dass Sie alle Befehle von einer Reparatur-VM in einer Chroot-Umgebung ausführen, wie in der Offline-Problembehandlung angegeben. Wenn das System bereits über eine frühere Kernelversion gestartet wurde, können diese Befehle auch über die ursprüngliche VM mithilfe von Stammrechten oder sudo, wie in der Online-Problembehandlung beschrieben, ausgeführt werden.
Aktuelles Kernelupgrade
Wenn der Kernel nach einem letzten Kernelupgrade gestartet wird, starten Sie die VM über die vorherige Kernelversion. Weitere Informationen finden Sie unter boot system on older kernel version.
Sie können auch überprüfen, ob bereits eine neuere Kernelversion vom Linux-Distributionsanbieter veröffentlicht und installiert wird. Weitere Informationen zum Installieren der neuesten Kernelversion finden Sie im Kernelupdateprozess.
Aktuelles Kernel-Downgrade
Wenn der Kernel nach einem aktuellen Kernel-Downgrade beginnt, kehren Sie zum neuesten installierten Kernel zurück. Sie können auch überprüfen, ob bereits eine neuere Kernelversion vom Linux-Distributionsanbieter veröffentlicht und installiert wird. Weitere Informationen zum Installieren der neuesten Kernelversion finden Sie im Kernelupdateprozess.
Um das System über die neueste Kernelversion zu starten, befolgen Sie die Anweisungen unter "Manuelles Ändern der Standard kernelversion", wählen Sie jedoch den ersten Kernel aus, der im GRUB-Menü aufgeführt ist. In einer manuellen Änderung können Sie den GRUB_DEFAULT Wert auf 0 festlegen und die entsprechende GRUB-Konfigurationsdatei neu generieren.
Kernelmoduländerungen
Möglicherweise erleben Sie eine Kernel-Panik, die sich auf ein neues Kernelmodul oder ein fehlendes Kernelmodul bezieht. Um Details zu dem spezifischen Kernelmodul zu erhalten, das Probleme verursacht (falls vorhanden), überprüfen Sie die entsprechende Kernel-Panikablaufverfolgung.
Führen Sie einen der folgenden Befehle aus, um die geladenen Kernelmodule und die deaktivierten Module in /etc/modprobe.d/*.conf-Dateien zu überprüfen:
RHEL/CentOS/Oracle Linux 7/8
lsinitrd /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img lsmod cat /etc/modprobe.d/*.confWichtig
Ersetzen Sie diese
3.10.0-1160.59.1.el7.x86_64durch die entsprechende Kernelversion.SLES 12/15
lsinitrd /boot/initrd-5.3.18-150300.38.53-azure lsmod cat /etc/modprobe.d/*.confWichtig
Ersetzen Sie diese
5.3.18-150300.38.53-azuredurch die entsprechende Kernelversion.Ubuntu 18.04
lsinitramfs /boot/initrd.img-5.4.0-1077-azure lsmod cat /etc/modprobe.d/*.confWichtig
Ersetzen Sie diese
5.4.0-1077-azuredurch die entsprechende Kernelversion.
Um ein bestimmtes Kernelmodul zu entfernen, führen Sie den folgenden Befehl aus, und generieren Sie die Initramfs bei Bedarf neu.
rmmod <kernel_module_name>
Wenn ein Systemdienst das spezifische Kernelmodul verwendet, deaktivieren Sie es, indem Sie den systemctl disable <serviceName> Befehl ausführen systemctl stop <serviceName> .
Aktuelle Konfigurationsänderungen des Betriebssystems
Identifizieren Sie alle kürzlich vorgenommenen Kernelkonfigurationsänderungen, die zu Problemen führen können. Um die Probleme zu beheben, passen Sie diese Einstellungen an, oder führen Sie ein Rollback der Konfigurationsänderungen durch.
Führen Sie den folgenden Befehl aus, um persistente Kernelparameter zu finden, die in einer der folgenden Dateien konfiguriert sind:
cat /etc/systctl.conf
cat /etc/sysctl.d/*
Führen Sie den folgenden Befehl aus, um die aktuellen Kernelparameter und deren aktuelle Werte zu analysieren:
sysctl -a
Notiz
Führen Sie diesen Befehl auf einem ausgeführten System und nicht aus einer chroot-Umgebung aus.
Mögliche fehlende Dateien
Weitere Informationen zu dieser Art von Problem finden Sie unter Fehlende wichtige Dateien und Verzeichnisse.
Falsche Berechtigungen für Dateien
Weitere Informationen zu dieser Art von Problem finden Sie unter "Falsche Dateiberechtigungen".
Fehlende Partitionen
Weitere Informationen zu dieser Art von Problem finden Sie unter Fehlende Partitionen.
Kernel-Fehler
Identifizieren Sie dieses Problem über die serielle Azure-Konsole. Diese Art von Problem sieht wie die folgende Ausgabe aus:
[5275698.017004] kernel BUG at XXX/YYY.c:72!
[5275698.017004] invalid opcode: 0000 [#1] SMP
Diese Art von Kernel-Panik ist mit Kernelfehlern oder Kernelfehlern von Drittanbietern verbunden.
Um Kernelfehler zu beheben, durchsuchen Sie die Knowledge Base des Anbieters mithilfe der Kernel-BUG-Zeichenfolge, und suchen Sie nach bekannten Problemen in der entsprechenden Kernelversion, die Ihr System ausführt. Hier sind einige wichtige Lieferantenressourcen:
-
Dieses Tool ist darauf ausgelegt, Sie bei der Diagnose eines Kernelabsturzes zu unterstützen. Wenn Sie einen Text, eine vmcore-dmesg.txt oder eine Datei mit einer oder mehreren Kernel-Oops-Nachrichten eingeben, werden Sie durch die Diagnose des Kernelabsturzproblems geführt.
-
Um Zugriff auf die Red Hat-Ressourcen zu erhalten, verknüpfen Sie Ihre Microsoft Azure- und Red Hat-Konten miteinander. Weitere Informationen finden Sie unter How Microsoft Azure Customers Can Access the Red Hat Customer Portal.
Es wird empfohlen, alle Ihre Systeme auf dem neuesten Stand zu halten, um mögliche Fehler auszuschließen, die bereits in den neuesten Kernelversionen behoben wurden. Weitere Informationen finden Sie unter Kernel-Updateprozess.
Wenn weitere Analysen vom Anbieter erforderlich sind, konfigurieren und aktivieren Sie kdump, um ein Kernspeicherabbild zu generieren:
- Kdump-Konfiguration auf Red Hat-basierten VMs.
- Kernelabsturz-Speicherabbildkonfiguration auf Ubuntu-VMs.
- Kernel-Kernabbildkonfiguration auf SLES-VMs.
Kernelaktualisierungsprozess
Führen Sie einen der folgenden Befehle aus, um die neueste verfügbare Kernelversion zu installieren:
RHEL/CentOS/Oracle Linux
yum update kernelSLES 12/15
zypper refresh zypper update kernel*Ubuntu 18.04/20.04
apt update apt install linux-azure
Führen Sie einen der folgenden Befehle aus, um eine bestimmte Kernelversion neu zu installieren. Stellen Sie sicher, dass Sie nicht über dieselbe Kernelversion gestartet werden, die Sie erneut installieren möchten. Weitere Informationen finden Sie unter boot system on older kernel version.
RHEL/CentOS/Oracle Linux
yum reinstall kernel-3.10.0-1160.59.1.el7.x86_64Wichtig
Ersetzen Sie diese
3.10.0-1160.59.1.el7.x86_64durch die entsprechende Kernelversion.SLES 12/15
zypper refresh zypper install -f kernel-azure-5.3.18-150300.38.75.1.x86_64Wichtig
Ersetzen Sie diese
kernel-azure-5.3.18-150300.38.75.1.x86_64durch die entsprechende Kernelversion.Ubuntu 18.04/20.04
apt update apt install --reinstall linux-azure=5.4.0.1091.68Wichtig
Ersetzen Sie diese
5.4.0.1091.68durch die entsprechende Kernelversion.
Führen Sie einen der folgenden Befehle aus, um das System zu aktualisieren und die neuesten verfügbaren Änderungen anzuwenden:
RHEL/CentOS/Oracle Linux
yum updateSLES 12/15
zypper refresh zypper updateUbuntu 18.04/20.04
apt update apt upgrade
Kernel-Panik kann mit einem der folgenden Elemente zusammenhängen. Weitere Informationen finden Sie unter Kernel-Panik zur Laufzeit.
- Änderungen der Anwendungsarbeitsauslastung.
- Anwendungsentwicklung oder Anwendungsfehler.
- Leistungsbezogene Probleme usw.
Nächste Schritte
Wenn der spezifische Startfehler kein Kernel-bezogenes Startproblem ist, lesen Sie die Problembehandlung bei Startfehlern bei virtuellen Azure Linux-Computern für weitere Problembehandlungsoptionen.
Kontaktieren Sie uns für Hilfe
Wenn Sie Fragen haben oder Hilfe mit Ihren Azure-Gutschriften benötigen, dann erstellen Sie beim Azure-Support eine Support-Anforderung oder fragen Sie den Azure Community-Support. Sie können auch Produktfeedback an die Azure Feedback Community senden.