Erkunden von Continuous Operations
Continuous Operations ist eine der acht Funktionen in der DevOps-Taxonomie.
Gründe, weshalb Continuous Operations erforderlich ist
Bei komplexen Systemen können Fehler auftreten, die kostspielige Ausfälle und Unterbrechungen verursachen. Wir sehen uns nun einige Beispiele an.
| Companies | Ereignis |
|---|---|
Delta Air Lines |
Im August 2016 musste Delta 2.300 Flüge stornieren, als eine einzelne fehlerhafte Komponente einen Stromausfall in der Betriebszentrale des Unternehmens in Atlanta, USA, verursachte. Dieser Vorfall kostete das Unternehmen nach eigenen Angaben 150 Millionen US-Dollar. |
FedEx und UK National Health Service |
Im Mai 2017 verursachte WannaCry-Ransomware betriebliche Störungen bei FedEx. Nach eigenen Angaben lag der durch diese Unterbrechungen verursachte Verlust bei einem FedEx-Tochterunternehmen bei 300 Millionen US-Dollar. Auch der National Health Service des Vereinigten Königreichs wurde Opfer der Ransomware, durch die in diesem Fall der Zugriff auf Computer gesperrt und der Zugang zu wichtigen medizinischen Geräten verhindert wurde. Als Folge waren einige Krankenhäuser gezwungen, Krankenwagen an andere Kliniken zu verweisen. |
Amazon S3 |
Im Februar 2017 verursachte ein Bedienfehler eine vierstündige Unterbrechung der wichtigsten Amazon-Speicherdienste. Diese Unterbrechung hatte erhebliche Auswirkungen auf wichtige Webangebote wie Alexa, IFTTT, Quora und Trello. |
| Bei LinkedIn ist ein Problem aufgetreten, aufgrund dessen für zwei Monate keine Entwicklungsarbeiten ausgeführt werden konnten. | |
Equifax |
Bei Equifax ist 2017 eine Sicherheitsverletzung aufgetreten, durch die die persönlichen Informationen von über 160 Millionen Kunden offengelegt wurden. Auf dieses Problem wurde im Abschnitt zu Continuous Security bereits näher eingegangen. |
Geschäftliche Auswirkungen und Kosten einer Sicherheitsverletzung
Die Kosten einer Sicherheitsverletzung gehen häufig weit über die verlorenen Umsätze und das verlorene Vertrauen in ein Unternehmen hinaus. Diese Kosten können Folgendes umfassen:
- Reaktion und Benachrichtigungen
- Das Benachrichtigen der betroffenen Parteien gemäß geltendem Recht geht mit betrieblichen Kosten und Dienstleistungskosten einher. Diese Kosten umfassen zudem häufig weitere Kosten für Callcenter, Pressearbeit und Kreditüberwachungsdienstleistungen.
- Einbußen bei Mitarbeiterproduktivität und Umsätzen
- Der Leiter der Rechtsabteilung von Yahoo gab seinen Posten auf, und die CEO erhielt für 2016 keinen Jahresbonus.
- Gerichtsverfahren und Vergleiche
- Target bezahlte 18,5 Millionen US-Dollar an 47 US-Bundesstaaten.
- Behördliche Geldbußen und regulatorische Antworten
- Nach den neuen Datenschutzrichtlinien der EU, die seit 2018 wirksam sind, beträgt die Geldstrafe 4 % des Jahresumsatzes oder 20 Millionen Euro (je nachdem, welcher Wert höher ist).
- Kosten für die Wiederherstellung des Markenimage
- Das im Bereich der Bergbautechnik tätige Unternehmen Codan verzeichnete einen Umsatzrückgang von 45 Millionen auf 9,2 Millionen Dollar innerhalb eines Jahres.
- Weitere Kosten
- Verizon zahlte nach zwei großen Hackerangriffen 350 Millionen US-Dollar weniger für Yahoo.
Außerdem können zusätzliche Sicherheits- und Überwachungsanforderungen erforderlich sein.
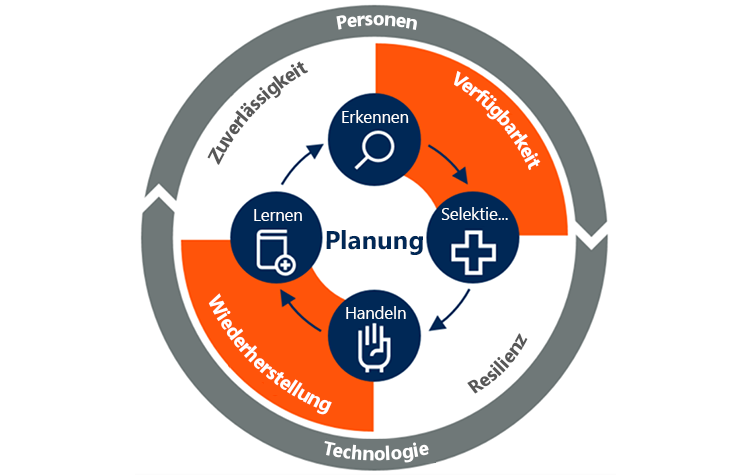
Verfügbarkeit und Wiederherstellung bei Continuous Operations
Laut einer Gartner-Umfrage gehen Führungskräfte aus Wirtschaft und IT davon aus, dass ca. 47 % der Produktionsanwendungen bis 2020 in der öffentlichen Cloud ausgeführt werden.
Wenn sich Rechenzentren mit nur einer einzigen Codezeile vollständig zerstören lassen, darf der Schwerpunkt nicht länger auf der Verfügbarkeit und Wiederherstellung von Produktionsumgebungen liegen. Durch neue Bereitstellungsmuster ändert sich die Art und Weise, wie die Verfügbarkeit von Anwendungen, Infrastrukturen und Wiederherstellungsfunktionen sichergestellt wird.
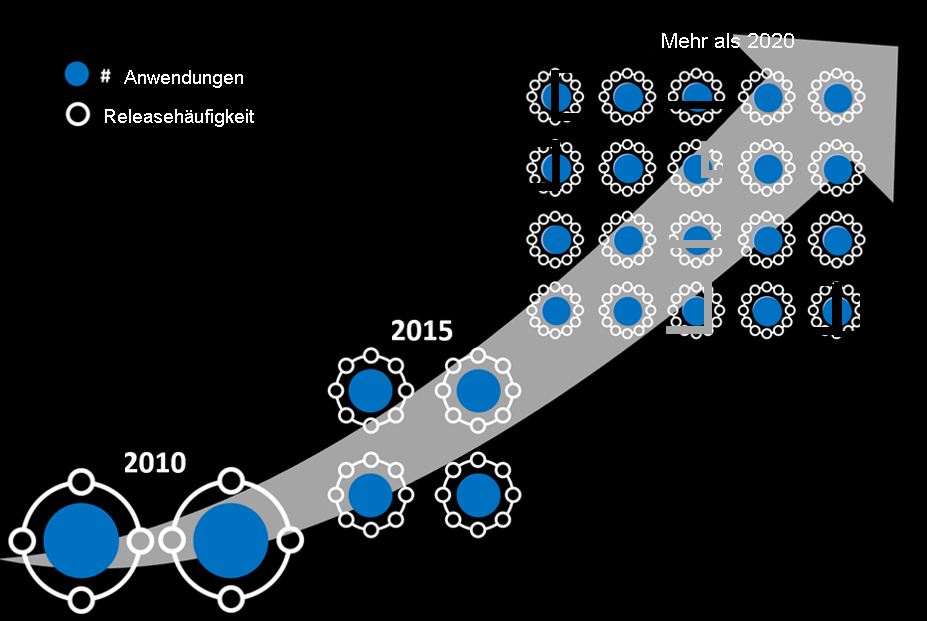
Steigende Anzahl von Apps und Releases in Produktionsumgebungen
Nachfolgend sind Key Performance Indicators für die Leistung bei der Softwarebereitstellung aufgeführt:
- Vorlaufzeit für Änderungen
- Bereitstellungshäufigkeit
- Mittlere Zeit zur Wiederherstellung
- Änderungsfehlerrate
Teams, die sich lediglich auf eine gesteigerte Geschwindigkeit konzentrieren, jedoch nicht ausreichend in die Qualität des Prozesses investieren, müssen mit größeren Ausfällen und einem höheren Zeitaufwand für die Wiederherstellung eines Diensts rechnen. Wenn der Schwerpunkt jedoch auch auf der Qualität des Prozesses liegt, profitieren Teams sowohl von einer hohen Geschwindigkeit als auch von Stabilität.
Auch die Anzahl von Web- und mobilen Anwendungen sowie die Häufigkeit von Anwendungsreleases sind erheblich gestiegen. Zudem wird Code immer komplexer.
Hinweis
Der große Nutzen von DevOps wird insbesondere durch das Bestimmen des idealen Verhältnisses zwischen Innovation (Geschwindigkeit) und Geschäftskontinuität (Kontrolle) erzielt.
Was ist Continuous Operations?
Wichtig
Durch Continuous Operations wird die Notwendigkeit geplanter Downtimes oder Unterbrechungen (z. B. geplante Wartungen) minimiert oder völlig eliminiert. Die kontinuierliche Überwachung von Infrastruktur, Anwendungen und Diensten sollte nach Möglichkeit mit einer automatisierten Wartung kombiniert werden. Benutzer sollten von Updates oder inkrementellen Releases nichts mitbekommen.
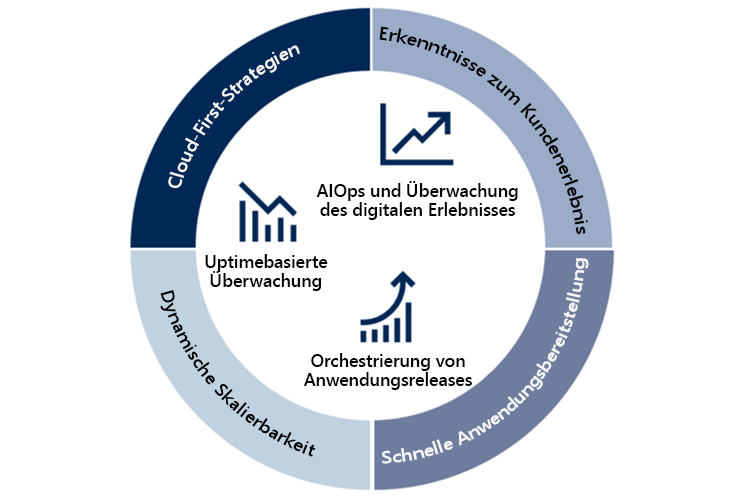
Traditionelle Verfahren und Continuous Operations-Vorgänge im Vergleich
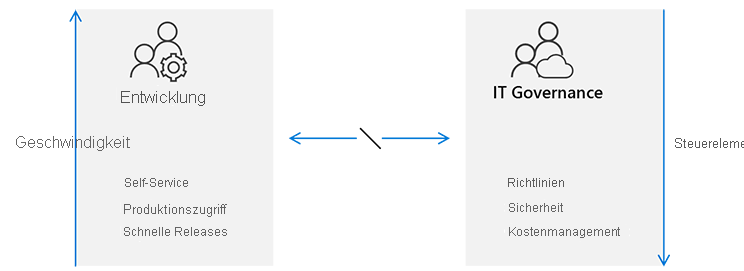
In einem traditionellen Unternehmensmodell setzt die IT durch, welche Releases verwendet werden. Für sämtliche Benutzer gelten starre Prozesse und Verfahren.
Bei diesem Ansatz kommt es zu Unstimmigkeiten zwischen den Entwicklungsteams und der IT-Governance. Entwicklungsteams arbeiten überwiegend agil und konzentrieren sich auf die Geschwindigkeit. Sie gehen davon aus, dass sie Releases so häufig veröffentlichen können, wie sie möchten. Für diese Teams ist die IT-Governance ein Engpass, der nicht mit den erwarteten Markteinführungszielen heutiger Geschäftsanforderungen in Einklang zu bringen ist.
Wichtig
Bei ordnungsgemäßer Implementierung kann DevOps sowohl Innovation (Geschwindigkeit) als auch Geschäftskontinuität (Kontrolle) bieten.
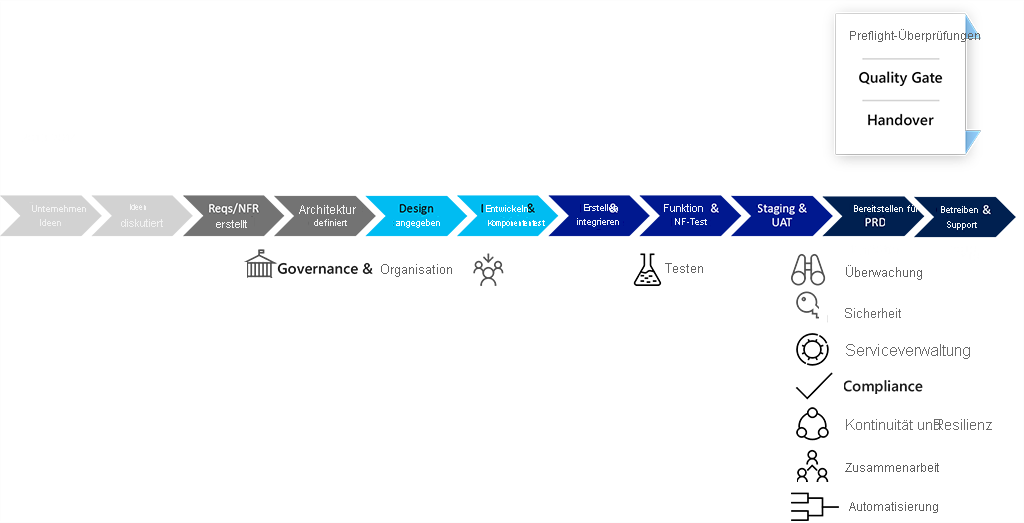
Traditioneller Entwicklungslebenszyklus:
- Das Testen erfolgt unmittelbar vor dem Go-Live.
- Die Überwachung wird häufig an andere Teams übergeben.
- Sicherheitsteams werden oft in den Testphasen kontaktiert.
- Bei der Übergabe müssen Sicherheitsüberprüfungen für den Code und alle Steuerelemente für die Dienstverwaltung abgeschlossen bzw. vorhanden sein.
- Die Compliance ist häufig nicht Teil der Übergabe, sondern ein Aspekt, der erst in der Betriebsphase eines Diensts auftaucht und eine Rolle spielt.
- Die Planung von Resilienz und Kontinuität ist zwar Teil der Entwurfsphase, das eigentliche Testen passender Szenarien erfolgt jedoch häufig erst in der Betriebs- oder Testphase. Diese Vorgehensweise kann zu Konfigurationsänderungen, Nacharbeit und unnötigem Arbeitsaufwand führen.
- Die Zusammenarbeit zwischen den für Betrieb, Sicherheit und Compliance sowie Entwicklung verantwortlichen Teams erfolgt häufig reaktiv über Prozesse für Incident- und Problemverwaltung.
- Wenn die Automatisierung erst in den finalen Phasen erfolgt, sind nicht selten nur wenige Ressourcen für diese Aufgaben verfügbar.
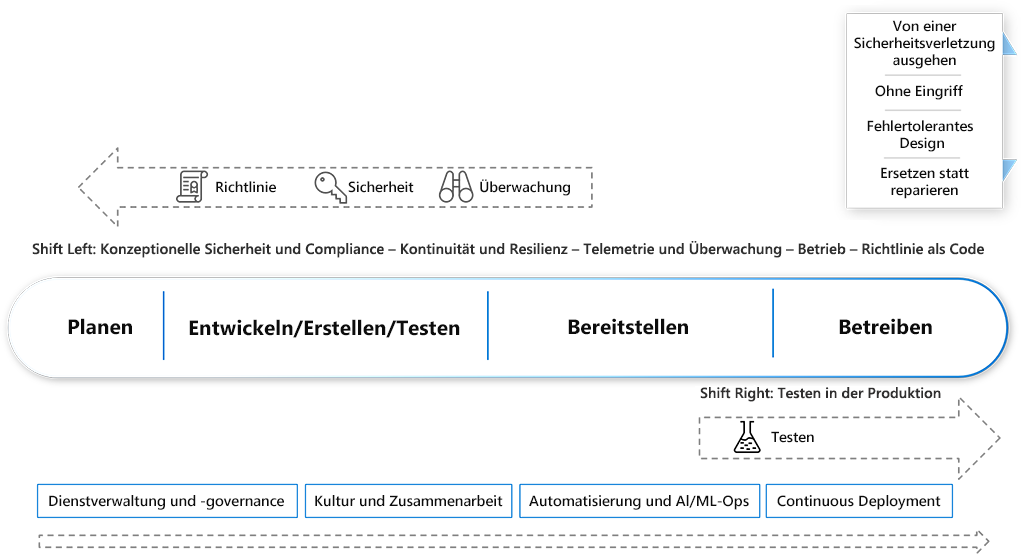
Neue Methoden, Technologien und Arbeitsweisen machen einen neuen Continuous Operations-Ansatz erforderlich. Nachfolgend sind die acht wichtigsten Continuous Operations-Verfahren aufgeführt, die zum Erfüllen der neuen Anforderungen entstanden sind und weiterentwickelt werden:
- Indem Sicherheit & Compliance bereits beim Entwurf berücksichtigt werden, wird sichergestellt, dass bestimmte Standards, Gesetze, aber auch Geschäftsanforderungen (z. B. Nachverfolgbarkeit und Überprüfbarkeit) schon zur Entwurfszeit berücksichtigt werden müssen, wenn Lösungen für hochgradig automatisierte Cloudumgebungen entworfen werden.
- Für Kontinuität & Resilienz ist eine enge Zusammenarbeit mit der Organisation erforderlich, damit den Geschäftsanforderungen beim Entwurf und bei der Implementierung Rechnung getragen wird.
- Mithilfe von Telemetrie & Überwachung lassen sich Nutzungsmuster von Kunden, potenzielle neue Anforderungen und Details dazu ermitteln, wo Fehler für Benutzer auftreten. Mithilfe dieser Tools lässt sich zudem sicherstellen, dass der gewünschte Nutzen erzielt wird.
- Die Dienstverwaltung wird in einer DevOps-Kultur neu betrachtet:
- Bei DevOps sind Sie für die Dienstverwaltung verantwortlich. Sie erstellen die Prozesse, Sie führen sie aus, und wenn Probleme auftreten, behandeln Sie diese.
- Sie konzentrieren sich auf das, was erforderlich ist.
- Sie ermöglichen Governanceprozesse.
- Sie sorgen für Transparenz.
- Kultur und Zusammenarbeit sind zwei entscheidende Aspekte für Continuous Operations. Für die Transformation in DevOps-Teams müssen Organisationen häufig ihre Arbeitsweise ändern. Auch beim Entwurf von Prozessen für Sicherheit und Resilienz spielt die Zusammenarbeit eine entscheidende Rolle.
- Automatisierung & AI/ML Ops sind wichtige Aspekte, durch die sich DevOps-Teams (und Cloudteams) von traditionellen Betriebsteams unterscheiden. Der Schwerpunkt darf nicht auf einem einzelnen Bereich, sondern muss auf der Automatisierung des gesamten Systems (systemische Automatisierung) liegen.
- Bei Continuous Deployment kommen moderne Releasepipelines zum Einsatz, mit denen Entwicklungsteams neue Features schnell und sicher bereitstellen können. Das Ergebnis ist ein kontinuierlicher Mehrwert für den Kunden und ein verringerter Zeitaufwand für die Problembehandlung.
- Bei Shift-Right-Tests werden Verfahren wie Dark-Launching, Featureflags, Überwachung und A/B-Tests verwendet. Teams können anschließend weitere Tests durchführen, um sicherzustellen, dass eine Anwendung bei der Live-Nutzung das erwartete Verhalten, die erwartete Leistung und die erwartete Verfügbarkeit bietet.
Für den Übergang zu einem DevOps-Ansatz ist ein erheblicher Paradigmenwechsel in der Kultur erforderlich, um mit einem modernen IT-Ansatz für einen geschäftlichen Mehrwert zu sorgen.
| Traditionelle IT | Moderne IT | |
|---|---|---|
| DNA | Vermittlung | Keine Vermittlung |
| Dienstbereitstellung | Wave-basiert | Continuous Iteration-basiert |
| Dienststabilität | Entwurf mit Fokus auf erfolgreiche Abläufe (Hochverfügbarkeit/Redundanz) | Entwurf mit Fokus auf Ausfälle (Resilienz) |
| Delegierungsebenen | IT-Silos | End-to-End-Dienste |
| Prozesse | In Dokumenten, optimiert, überarbeitet | Self-Service, Wissen, reibungsarm, automatisiert |
| Automation | Isoliert, manuell initiiert | Systemisch, ausgelöst, automatisch |
| Überwachung | Element, Fokus auf Fehlern | Dienst, Fokus auf End-to-End-Funktionen |
| Unterstützung | Service Desk/Kontaktcenter | Kundenservice/Self-Service |
| Lebenszyklus | N-1 oder älter | N, N+1 |
| Konfiguration/Asset Management | Entdeckt/manuelle Konfiguration | Vorgegeben, deklarativ, automatisiert |
Diese Änderungen haben vereinfachte und automatisierte Prozesse, angepasste Ergebnisanreize, ein geringeres Risiko und einen kundenorientierten Ansatz zur Folge.