Bewährte Methoden für die Überwachung von Workloads mit Abfragespeicher
Gilt für: ![]() SQL Server 2016 (13.x) und höhere Versionen
SQL Server 2016 (13.x) und höhere Versionen![]() Azure SQL-Datenbank
Azure SQL-Datenbank ![]() Azure SQL verwaltete Instanz
Azure SQL verwaltete Instanz ![]() Azure Synapse Analytics (nur dedizierte SQL-Pool)
Azure Synapse Analytics (nur dedizierte SQL-Pool)![]() -SQL-Datenbank in Microsoft Fabric
-SQL-Datenbank in Microsoft Fabric
In diesem Artikel werden die bewährten Methoden für den Einsatz des SQL Server-Abfragespeichers mit Ihrer Arbeitsauslastung vorgestellt.
- Weitere Informationen zum Konfigurieren und Verwalten mit dem Abfragespeicher finden Sie unter Überwachen der Leistung mit dem Abfragespeicher.
- Informationen zur Ermittelung handlungsrelevanter Informationen und zur Leistungsoptimierung mit dem Abfragespeicher finden Sie unter Optimieren der Leistung mit dem Abfragespeicher.
- Informationen zum Betrieb des Abfragespeichers in Azure SQL-Datenbank finden Sie unter Betrieb des Abfragespeichers in Azure SQL-Datenbank.
- In Azure Synapse Analytics ist Abfragespeicher nicht standardmäßig für dedizierte SQL-Pools aktiviert, die Aktivierung ist jedoch möglich. Weitere Konfigurationsoptionen für den Abfragespeicher werden nicht unterstützt. Weitere Informationen finden Sie unter Speicherung und Analyse von Verlaufsabfragen in Azure Synapse Analytics.
Verwenden Sie die aktuelle Version von SQL Server Management Studio
SQL Server Management Studio verfügt über mehrere Benutzeroberflächen, die zum Konfigurieren des Abfragespeichers und zur Nutzung der gesammelten Daten über Ihre Arbeitsauslastung konzipiert wurden. Laden Sie die aktuelle Version von SQL Server Management Studio herunter.
Eine kurze Beschreibung der Verwendung des Abfragespeichers in Fehlerbehandlungsszenarien finden Sie unter Query Store Azure blogs.
Verwenden von Query Performance Insight in Azure SQL-Datenbank
Wenn Sie den Abfragespeicher in der Azure SQL-Datenbank ausführen, können Sie mit Query Performance Insight die Ressourcennutzung im Verlauf der Zeit analysieren. Sie können zwar Management Studio und Azure Data Studio verwenden, um detaillierte Ressourcennutzungswerte für alle Ihre Abfragen wie CPU, Arbeitsspeicher und E/A abzurufen, Query Performance Insight bietet Ihnen jedoch eine schnelle und effiziente Möglichkeit, um deren Effekt auf den DTU-Verbrauch Ihrer Datenbank insgesamt zu ermitteln. Weitere Informationen finden Sie unter Query Performance Insight für Azure SQL-Datenbank.
Verwenden Sie das Performance-Dashboard, um die Leistung in der Fabric SQL-Datenbank zu überwachen.
Verwenden des Abfragespeichers mit Pools für elastische Datenbanken
Sie können den Abfragespeicher bedenkenlos in allen Datenbanken verwenden, selbst in dicht gepackten elastischen Pools der Azure SQL-Datenbank. Alle vorherigen mit übermäßiger Ressourcennutzung zusammenhängenden Probleme, die bei der Aktivierung des Abfragespeichers für die große Anzahl Datenbanken in Pools für elastische Datenbanken auftreten konnten, wurden behoben.
Erste Schritte bei der Behandlung von Leistungsproblemen
Der Workflow zur Behandlung von Problemen mit dem Abfragespeicher ist einfach, wie im folgenden Diagramm dargestellt:

Aktivieren Sie den Abfragespeicher mit Management Studio, wie im vorherigen Abschnitt beschrieben, oder führen Sie die folgende Transact-SQL-Anweisung aus:
ALTER DATABASE [DatabaseOne] SET QUERY_STORE = ON;
Es dauert einige Zeit, bis der Abfragespeicher das Dataset erfasst, das Ihre Arbeitsauslastung präzise darstellt. In der Regel reicht ein Tag, selbst bei sehr komplexen Arbeitsauslastungen. Sie können jedoch unmittelbar nach Aktivierung der Funktion damit beginnen, die Daten zu untersuchen und Abfragen zu identifizieren, die Ihre Aufmerksamkeit erfordern. Navigieren Sie zu dem Abfragespeicher-Unterordner unter dem Datenbankknoten im Objekt-Explorer von Management Studio, um Problembehandlungsansichten für bestimmte Szenarios zu öffnen.
Management Studio-Abfragespeicheransichten arbeiten mit dem Satz von Ausführungsmetriken, die alle als eine der folgenden Statistikfunktionen ausgedrückt werden:
| SQL Server-Version | Ausführungsmetrik | Statistikfunktion |
|---|---|---|
| SQL Server 2016 (13.x) | CPU-Zeit, Dauer, Ausführungsanzahl, logische Lesevorgänge, logische Schreibvorgänge, Speicherverbrauch, physische Lesevorgänge, CLR-Zeit, Parallelitätsgrad (Degree of Parallelism, DOP) und Zeilenanzahl | Durchschnitt, Maximum, Minimum, Standardabweichung, Gesamt |
| SQL Server 2017 (14.x) | CPU-Zeit, Dauer, Ausführungsanzahl, logische Lesevorgänge, logische Schreibvorgänge, Speicherverbrauch, physische Lesevorgänge, CLR-Zeit, Parallelitätsgrad, Zeilenanzahl, Protokollspeicher, TempDB-Speicher und Wartezeiten | Durchschnitt, Maximum, Minimum, Standardabweichung, Gesamt |
Die folgende Grafik veranschaulicht, wie Sie die Abfragespeicheransichten suchen:
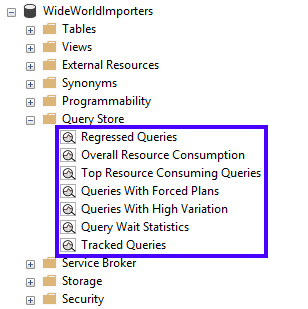
In der folgenden Tabelle wird erläutert, wann Sie die einzelnen Abfragespeicheransichten verwenden sollten:
| SQL Server Management Studio-Ansicht | Szenario |
|---|---|
| Rückläufige Abfragen | Identifizieren von Abfragen, bei denen die Ausführungsmetriken vor kurzem rückläufig waren (z.B. sich verschlechtert haben). Verwenden Sie diese Ansicht, um beobachtete Leistungsprobleme in Ihrer Anwendung mit den tatsächlichen Abfragen zu korrelieren, die korrigiert oder verbessert werden müssen. |
| Gesamter Ressourcenverbrauch | Analysieren Sie den Gesamtressourcenverbrauch für die Datenbank für eine der Ausführungsmetriken. Verwenden Sie diese Ansicht, um Ressourcenmuster zu identifizieren (tägliche im Vergleich zu nächtlichen Arbeitsauslastungen), und optimieren Sie den Gesamtverbrauch für Ihre Datenbank. |
| Abfragen mit höchstem Ressourcenverbrauch | Wählen Sie die gewünschte Ausführungsmetrik, und identifizieren Sie Abfragen mit den extremsten Werten für ein angegebenes Zeitintervall. Verwenden Sie diese Ansicht, um sich auf die relevantesten Abfragen zu konzentrieren, die den größten Effekt auf den Ressourcenverbrauch der Datenbank haben. |
| Abfragen mit erzwungenen Plänen | Zeigt vorherige erzwungene Pläne durch Verwendung des Abfragespeichers an. Verwenden Sie diese Ansicht, um schnell auf alle aktuell erzwungenen Pläne zuzugreifen. |
| Abfragen mit hoher Variation | Analysieren Sie Abfragen mit hoher Ausführungsvariation in Verbindung mit allen verfügbaren Dimensionen wie Dauer, CPU-Zeit, E/A und Speicherauslastung im gewünschten Zeitintervall. Verwenden Sie diese Ansicht, um Abfragen mit stark abweichender Leistung zu identifizieren, die die Benutzerfreundlichkeit in Ihren Anwendungen beeinträchtigen können. |
| Statistik der Abfragewartezeit | Analysieren Sie Wartekategorien, die in einer Datenbank am aktivsten sind, sowie welche Abfragen am meisten zur ausgewählten Wartekategorie beitragen. Verwenden Sie diese Ansicht, um Wartezeitstatistiken zu analysieren und Abfragen zu identifizieren, die sich auf die Benutzerfreundlichkeit in Ihren Anwendungen auswirken können. Gilt für: ab SQL Server Management Studio v18.0 und SQL Server 2017 (14.x). |
| Nachverfolgte Abfragen | Verfolgen Sie die Ausführung der wichtigsten Abfragen in Echtzeit. In der Regel verwenden Sie diese Ansicht, wenn Sie über Abfragen mit erzwungenen Plänen verfügen und Sie sicherstellen möchten, dass die Abfrageleistung stabil ist. |
Tipp
Eine ausführliche Beschreibung dazu, wie Sie mit Management Studio die Abfragen mit dem größten Ressourcenverbrauch identifizieren und die Abfragen korrigieren können, die aufgrund der Änderung der Planauswahl zurückgestellt wurden, finden Sie unter Query Store Azure Blogs.
Wenn Sie eine Abfrage mit nicht optimaler Leistung identifiziert haben, richtet sich das weitere Vorgehen nach der Art des Problems.
- Wenn die Abfrage mit mehreren Plänen ausgeführt wurde und der letzte Plan signifikant schlechter als der vorherige ist, können Sie den Planerzwingungsmechanismus verwenden, um diesen zu erzwingen. SQL Server versucht, den Plan im Optimierer zu erzwingen. Wenn das Erzwingen des Plans fehlschlägt, wird ein XEvent ausgelöst, und der Optimierer wird angewiesen, die Optimierung auf die übliche Weise durchzuführen.
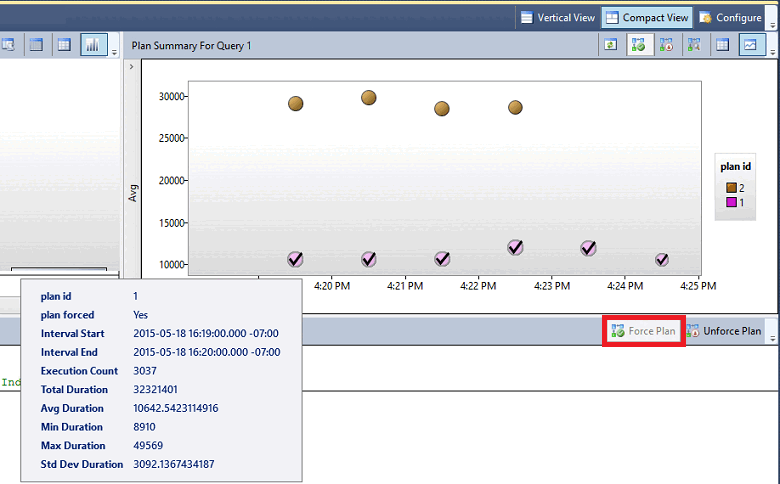
Hinweis
Die vorherige Abbildung kann verschiedene Formen für bestimmte Abfragepläne aufweisen, wobei die möglichen Status folgende Bedeutungen haben:
| Form | Bedeutung |
|---|---|
| Kreis | Abfrage abgeschlossen, d.h., dass eine reguläre Ausführung erfolgreich abgeschlossen wurde. |
| Quadrat | Abgebrochen, d.h., dass ein vom Client initiierter Abbruch der Ausführung erfolgte. |
| Dreieck | Fehlerhaft, d.h., dass die Ausführung durch eine Ausnahme abgebrochen wurde. |
Darüber hinaus gibt die Größe der Form Aufschluss über die Anzahl von Abfrageausführungen innerhalb des angegebenen Zeitintervalls. Die Größe der Form nimmt mit zunehmender Anzahl von Ausführungen zu.
- Sie können daraus schließen, dass der Abfrage ein Index für eine optimale Ausführung fehlt. Diese Informationen werden innerhalb des Abfrageausführungsplans eingeblendet. Erstellen Sie den fehlenden Index, und überprüfen Sie die Abfrageleistung mit dem Abfragespeicher.

Wenn Sie Ihre Arbeitsauslastung auf der SQL-Datenbank ausführen, registrieren Sie sich für den SQL-Datenbank-Indexratgeber, um automatisch Indexempfehlungen zu erhalten.
- In einigen Fällen können Sie eine statistische Neukompilierung erzwingen, wenn Sie feststellen, dass der Unterschied zwischen der geschätzten und der tatsächlichen Anzahl der Zeilen im Ausführungsplan maßgeblich ist.
- Schreiben Sie problematische Abfragen neu, beispielsweise, um die Vorteile der Abfrageparametrisierung nutzen zu können oder um eine bessere Logik zu implementieren.
Tipp
Ziehen Sie in der Azure SQL-Datenbank das Feature Abfragespeicherhinweise zum Erzwingen von Abfragehinweisen für Abfragen ohne Codeänderungen in Betracht. Weitere Informationen und Beispiele finden Sie unter Abfragespeicherhinweise.
Überprüfen, ob der Abfragespeicher kontinuierlich Abfragedaten erfasst
Der Abfragespeicher kann den Betriebsmodus automatisch ändern. Überwachen Sie regelmäßig den Status des Abfragespeichers, um sicherzustellen, dass der Abfragespeicher funktioniert, und um Maßnahmen zu ergreifen, damit so Ausfälle aufgrund von vermeidbaren Ursachen verhindert werden. Führen Sie die folgende Abfrage aus, um den Betriebsmodus zu ermitteln und die wichtigsten Parameter anzuzeigen:
USE [QueryStoreDB];
GO
SELECT actual_state_desc, desired_state_desc, current_storage_size_mb,
max_storage_size_mb, readonly_reason, interval_length_minutes,
stale_query_threshold_days, size_based_cleanup_mode_desc,
query_capture_mode_desc
FROM sys.database_query_store_options;
Der Unterschied zwischen actual_state_desc und desired_state_desc weist darauf hin, dass automatisch eine Änderung des Betriebsmodus aufgetreten ist. Die häufigste Änderung besteht darin, dass der Abfragespeicher im Hintergrund in den schreibgeschützten Modus wechselt. In sehr seltenen Fällen können interne Fehler dazu führen, dass sich der Abfragespeicher in einem fehlerhaften Zustand (ERROR) befindet.
Wenn der tatsächliche Status schreibgeschützt ist, verwenden Sie die readonly_reason-Spalte, um die Grundursache zu ermitteln. In der Regel werden Sie feststellen, dass der Abfragespeicher in den schreibgeschützten Modus gewechselt hat, da das Kontingent überschritten wurde. In diesem Fall wird readonly_reason auf 65536 festgelegt. Andere Gründe finden Sie unter sys.database_query_store_options (Transact-SQL).
Ziehen Sie die folgenden Schritte in Betracht, um den Abfragespeicher in den schreibgeschützten Modus zu schalten und die Datensammlung zu aktivieren:
Erhöhen Sie die maximale Speichergröße mithilfe der
MAX_STORAGE_SIZE_MB-Option vonALTER DATABASE.Bereinigen Sie die Abfragespeicherdaten mithilfe der folgenden Anweisung:
ALTER DATABASE [QueryStoreDB] SET QUERY_STORE CLEAR;
Wenden Sie einen oder beide der folgenden Schritte an, indem Sie die folgende Anweisung ausführen, die den Betriebsmodus explizit wieder in den Lese-/ Schreibzugriff zurücksetzt:
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE);
Gehen Sie proaktiv folgendermaßen vor:
- Sie können die automatischen Änderungen des Betriebsmodus durch Anwenden bewährter Methoden verhindern. Stellen Sie sicher, dass die Abfragespeichergröße immer unterhalb des maximal zulässigen Werts liegt, um so die Wahrscheinlichkeit des Übergangs in den schreibgeschützten Modus maßgeblich zu verringern. Aktivieren Sie die größenbasierte Richtlinie, wie im Abschnitt zum Konfigurieren des Abfragespeichers beschrieben, sodass der Abfragespeicher die Daten automatisch bereinigt, wenn sich die Größe dem Grenzwert nähert.
- Um sicherzustellen, dass die neuesten Daten beibehalten werden, konfigurieren Sie die zeitbasierte Richtlinie, um regelmäßig veraltete Informationen zu entfernen.
- Nicht zuletzt sollten Sie es in Betracht ziehen, den Erfassungsmodus für den Abfragespeicher auf Automatisch einzustellen, da dadurch Abfragen herausgefiltert werden, die in der Regel weniger relevant für Ihre Arbeitsauslastung sind.
Fehlerzustand
Zum Wiederherstellen des Abfragespeichers versuchen Sie explizit den Lese-/Schreibmodus einzustellen, und prüfen Sie den tatsächlichen Status noch mal.
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE);
GO
SELECT actual_state_desc, desired_state_desc, current_storage_size_mb,
max_storage_size_mb, readonly_reason, interval_length_minutes,
stale_query_threshold_days, size_based_cleanup_mode_desc,
query_capture_mode_desc
FROM sys.database_query_store_options;
Wenn das Problem weiterhin besteht, bedeutet dies, dass die beschädigten Abfragespeicherdaten auf dem Datenträger beibehalten werden.
Der Abfragespeicher kann ab SQL Server 2017 (14.x) wiederhergestellt werden, indem innerhalb der betroffenen Datenbank die gespeicherte Prozedur sys.sp_query_store_consistency_check ausgeführt wird. Der Abfragespeicher muss vor dem Wiederherstellungsvorgang deaktiviert werden. Hier sehen Sie eine Beispielabfrage, die Sie verwenden oder anpassen können, um die Konsistenzprüfung und die QDS-Wiederherstellung durchzuführen:
IF EXISTS (SELECT * FROM sys.database_query_store_options WHERE actual_state=3)
BEGIN
BEGIN TRY
ALTER DATABASE [QDS] SET QUERY_STORE = OFF
Exec [QDS].dbo.sp_query_store_consistency_check
ALTER DATABASE [QDS] SET QUERY_STORE = ON
ALTER DATABASE [QDS] SET QUERY_STORE (OPERATION_MODE = READ_WRITE)
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber
,ERROR_SEVERITY() AS ErrorSeverity
,ERROR_STATE() AS ErrorState
,ERROR_PROCEDURE() AS ErrorProcedure
,ERROR_LINE() AS ErrorLine
,ERROR_MESSAGE() AS ErrorMessage;
END CATCH;
END
Für SQL Server 2016 (13.x) müssen Sie die Daten aus dem Abfragespeicher, wie gezeigt, löschen.
Wenn die Wiederherstellung nicht erfolgreich war, können Sie versuchen, den Abfragespeicher vor dem Aktivieren des Lese-/Schreibmodus zu löschen.
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE CLEAR;
GO
ALTER DATABASE [QueryStoreDB]
SET QUERY_STORE (OPERATION_MODE = READ_WRITE);
GO
SELECT actual_state_desc, desired_state_desc, current_storage_size_mb,
max_storage_size_mb, readonly_reason, interval_length_minutes,
stale_query_threshold_days, size_based_cleanup_mode_desc,
query_capture_mode_desc
FROM sys.database_query_store_options;
Vermeiden des Einsatzes von nicht parametrisierten Abfragen
Es wird nicht empfohlen, parametrisierte Abfragen zu verwenden, wenn dies nicht erforderlich ist. Ein Beispiel hierfür ist die Ad-hoc-Analyse. Zwischengespeicherte Pläne können nicht wiederverwendet werden, sodass der Abfrageoptimierer gezwungen ist, Abfragen für jeden eindeutigen Abfragetext zu kompilieren. Weitere Informationen finden Sie unter Richtlinien für die Verwendung der erzwungenen Parametrisierung.
Der Abfragespeicher kann darüber hinaus schnell die Kontingentgröße aufgrund einer potenziell großen Anzahl von verschiedenen Abfragetexten und somit einer großen Anzahl von verschiedenen Ausführungsplänen mit ähnlicher Form überschreiten. Daher wird die Leistung Ihrer Arbeitsauslastung suboptimal sein, und der Abfragespeicher wechselt möglicherweise in den schreibgeschützten Modus oder löscht kontinuierlich die Daten, um mit den eingehenden Abfragen Schritt zu halten.
Ziehen Sie folgende Möglichkeiten in Betracht:
- Parametrisieren Sie Abfragen, sofern möglich. Umschließen Sie Abfragen beispielsweise in einer gespeicherten Prozedur oder
sp_executesql. Weitere Informationen finden Sie unter Parameter und Wiederverwendung von Ausführungsplänen. - Verwenden Sie die Option Für Ad-hoc-Arbeitsauslastungen optimieren, wenn Ihre Arbeitsauslastung viele einmalige Ad-hoc-Batches mit anderen Abfrageplänen enthält.
- Vergleichen Sie die Anzahl der unterschiedlichen query_hash-Werte mit der Gesamtanzahl der Einträge in
sys.query_store_query. Ist das Verhältnis nahe 1, generiert Ihre Ad-hoc-Arbeitsauslastung verschiedene Abfragen.
- Vergleichen Sie die Anzahl der unterschiedlichen query_hash-Werte mit der Gesamtanzahl der Einträge in
- Wenden Sie die erzwungene Parametrisierung auf die Datenbank oder auf eine Teilmenge der Abfragen an, wenn die Anzahl der unterschiedlichen Abfragepläne nicht groß ist.
- Verwenden Sie die Planhinweisliste, um die Parametrisierung nur für die ausgewählte Abfrage zu erzwingen.
- Konfigurieren Sie die erzwungene Parametrisierung über den Befehl für die Option zur Parametrisierung der Datenbank, wenn Ihre Arbeitsauslastung eine kleine Anzahl von unterschiedlichen Abfragepläne umfasst. Ein Beispiel hierfür besteht, wenn das Verhältnis zwischen der Anzahl unterschiedlicher query_hash-Werte und der Gesamtanzahl der Einträge in
sys.query_store_querywesentlich kleiner als 1 ist.
- Legen Sie
QUERY_CAPTURE_MODEaufAUTOfest, um Ad-hoc-Abfragen mit geringem Ressourcenverbrauch automatisch herauszufiltern.
Tipp
Wenn Sie eine ORM-Lösung (Object-Relational Mapping, objektrelationale Zuordnung) wie Entity Framework (EF) verwenden, werden Anwendungsabfragen wie manuelle LINQ-Abfragestrukturen oder bestimmte unformatierte SQL-Abfragen unter Umständen nicht parametrisiert. Dies wirkt sich auf die Wiederverwendung von Plänen und die Möglichkeit zum Nachverfolgen von Abfragen im Abfragespeicher aus. Weitere Informationen finden Sie unter Zwischenspeichern und Parametrisieren von Abfragen und Unformatierte SQL-Abfragen.
Suchen nach nicht parametrisierten Abfragen im Abfragespeicher
Die Anzahl der pläne, die in Abfragespeicher gespeichert sind, finden Sie mithilfe der folgenden Abfrage unter Verwendung Abfragespeicher DMVs, in SQL Server, Azure SQL verwaltete Instanz oder Azure SQL-Datenbank:
SELECT count(Pl.plan_id) AS plan_count, Qry.query_hash, Txt.query_text_id, Txt.query_sql_text
FROM sys.query_store_plan AS Pl
INNER JOIN sys.query_store_query AS Qry
ON Pl.query_id = Qry.query_id
INNER JOIN sys.query_store_query_text AS Txt
ON Qry.query_text_id = Txt.query_text_id
GROUP BY Qry.query_hash, Txt.query_text_id, Txt.query_sql_text
ORDER BY plan_count desc;
Im folgenden Beispiel wird eine Sitzung für erweiterte Ereignisse erstellt, um das Ereignis query_store_db_diagnostics zu erfassen, was bei der Diagnose des Ressourcenverbrauchs von Abfragen nützlich sein kann. In SQL Server wird von dieser Sitzung für erweiterte Ereignisse standardmäßig eine Ereignisdatei im SQL Server-Protokollordner erstellt. Bei einer Standardinstallation von SQL Server 2019 (15.x) unter Windows sollte die Ereignisdatei (XEL-Datei) beispielsweise im Ordner C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\Log erstellt werden. Geben Sie bei Azure SQL Managed Instance stattdessen einen Azure Blob Storage-Speicherort an. Weitere Informationen finden Sie unter Phase 2: Transact-SQL-Code zum Verwenden des Azure-Speichercontainers. Das Ereignis „qds.query_store_db_diagnostics“ ist für Azure SQL-Datenbank nicht verfügbar.
CREATE EVENT SESSION [QueryStore_Troubleshoot] ON SERVER
ADD EVENT qds.query_store_db_diagnostics(
ACTION(sqlos.system_thread_id,sqlos.task_address,sqlos.task_time,sqlserver.database_id,sqlserver.database_name))
ADD TARGET package0.event_file(SET filename=N'QueryStore',max_file_size=(100))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF);
Mit diesen Daten können Sie die Plananzahl im Abfragespeicher und viele weitere Statistikinformationen ermitteln. Suchen Sie in den Ereignisdaten nach den Spalten plan_count, query_count, max_stmt_hash_map_size_kb und max_size_mb, um die Menge des verwendeten Arbeitsspeichers und die Anzahl von Plänen nachzuvollziehen, die vom Abfragespeicher nachverfolgt werden. Wenn die Plananzahl höher als normal ist, deutet das möglicherweise auf eine Zunahme bei nicht parametrisierten Abfragen hin. Verwenden Sie die folgende Abfrage für dynamische Verwaltungssichten des Abfragespeichers, um die parametrisierten und nicht parametrisierte Abfragen im Abfragespeicher zu überprüfen.
Parametrisierte Abfragen:
SELECT qsq.query_id, qsqt.query_sql_text
FROM sys.query_store_query AS qsq
INNER JOIN sys.query_store_query_text AS qsqt
ON qsq.query_text_id= qsqt.query_text_id
WHERE qsq.query_parameterization_type<>0 or qsqt.query_sql_text like '%@%';
Nicht parametrisierte Abfragen:
SELECT qsq.query_id, qsqt.query_sql_text
FROM sys.query_store_query AS qsq
INNER JOIN sys.query_store_query_text AS qsqt
ON qsq.query_text_id= qsqt.query_text_id
WHERE query_parameterization_type=0;
Vermeiden eines DROP- und CREATE-Musters für enthaltende Objekte
Der Abfragespeicher ordnet einen Abfrageeintrag einem enthaltenen Objekt zu (gespeicherte Prozedur, Funktion und Trigger). Wenn Sie ein enthaltenes Objekt neu erstellen, wird ein neuer Abfrageeintrag für den gleichen Abfragetext generiert. Dies verhindert die Nachverfolgung der Leistungsstatistiken für diese Abfrage im Verlauf der Zeit und die Anwendung eines Mechanismus zur Nutzungsplanerzwingung. Damit dies vermieden wird, verwenden Sie den ALTER <object>-Prozess, um die Definition des enthaltenen Objekts nach Möglichkeit zu ändern.
Regelmäßiges Überprüfen des Status der erzwungenen Pläne
Die Planerzwingung ist ein nützlicher Mechanismus zur Behandlung von Leistungsproblemen für kritische Abfragen, um sie besser vorhersagbar zu machen. Wie bei Planhinweisen und Planhinweislisten ist das Erzwingen eines Plans keine Garantie dafür, dass er in späteren Ausführungen verwendet wird. Wenn das Datenbankschema sich derart ändert, dass Objekte, auf die der Ausführungsplan verweist, geändert oder gelöscht werden, wird das Erzwingen eines Plans in der Regel scheitern. In diesem Fall greift SQL Server auf eine Neukompilierung der Abfrage zurück, während die tatsächliche Ursache für den Fehler beim Erzwingen in sys.query_store_plan ersichtlich ist. Die folgende Abfrage gibt Informationen zu erzwungenen Plänen zurück:
USE [QueryStoreDB];
GO
SELECT p.plan_id, p.query_id, q.object_id as containing_object_id,
force_failure_count, last_force_failure_reason_desc
FROM sys.query_store_plan AS p
JOIN sys.query_store_query AS q on p.query_id = q.query_id
WHERE is_forced_plan = 1;
Eine vollständige Liste der Gründe finden Sie unter sys.query_store_plan. Sie können auch das XEvent query_store_plan_forcing_failed verwenden, um Fehler bei der Planerzwingung nachzuverfolgen und zu beheben.
Tipp
Ziehen Sie in der Azure SQL-Datenbank das Feature Abfragespeicherhinweise zum Erzwingen von Abfragehinweisen für Abfragen ohne Codeänderungen in Betracht. Weitere Informationen und Beispiele finden Sie unter Abfragespeicherhinweise.
Vermeiden der Umbenennung von Datenbanken bei Abfragen mit erzwungenen Plänen
Ausführungspläne verweisen auf Objekte mithilfe von dreiteiligen Namen wie database.schema.object.
Wenn Sie eine Datenbank umbenennen, wird das Erzwingen eines Plans fehlschlagen, wodurch bei allen nachfolgenden Abfrageausführungen eine Neukompilierung durchgeführt wird.
Verwenden von Abfragespeicher in unternehmenskritischen Servern
Die globalen Ablaufverfolgungsflags 7745 und 7752 können verwendet werden, um die Verfügbarkeit von Datenbanken mithilfe des Abfragespeichers zu verbessern. Weitere Informationen finden Sie unter Ablaufverfolgungsflags.
- Das Ablaufverfolgungsflag 7745 verhindert, dass der Abfragespeicher standardmäßig Daten auf den Datenträger schreibt, bevor SQL Server beendet werden kann. Dies bedeutet, dass Abfragespeicherdaten, die erfasst, aber noch nicht dauerhaft auf einem Datenträger gespeichert wurden, bis zu dem mit
DATA_FLUSH_INTERVAL_SECONDSdefinierten Zeitfenster verloren gehen. - Ablaufverfolgungsflag 7752 aktiviert asynchrones Laden von Abfragespeicher. Dadurch kann eine Datenbank online geschaltet und können Abfragen ausgeführt werden, bevor der Abfragespeicher vollständig wiederhergestellt wurde. Beim Standardverhalten erfolgt ein synchrones Laden des Abfragespeichers. Das Standardverhalten verhindert, dass Abfragen ausgeführt werden, bevor der Abfragespeicher wiederhergestellt wurde, verhindert aber auch, dass irgendwelche Abfragen in der Datensammlung ignoriert werden.
Hinweis
Ab SQL Server 2019 (15.x) wird dieses Verhalten durch die Engine gesteuert, und das Ablaufverfolgungsflag 7752 hat keine Auswirkungen.
Wichtig
Wenn Sie den Abfragespeicher für Erkenntnisse zu Just-In-Time-Arbeitsauslastungen in SQL Server 2016 (13.x) verwenden, planen Sie baldmöglichst die Installation der Verbesserungen zur Leistungsskalierbarkeit in SQL Server 2016 (13.x) SP2 CU2 (KB 4340759) ein. Ohne diese Verbesserungen kann es bei hohen Workloads der Datenbank zu Spinlock-Konflikten kommen und die Serverleistung beeinträchtigt werden. Insbesondere beim QUERY_STORE_ASYNC_PERSIST- oder SPL_QUERY_STORE_STATS_COOKIE_CACHE-Spinlock kann es zu heftigen Konflikten kommen. Nachdem diese Verbesserungen angewendet wurden, führt der Abfragespeicher nicht mehr zu Spinlock-Konflikten.
Wichtig
Wenn Sie Abfragespeicher für Just-in-Time-Workload-Einblicke in SQL Server (SQL Server 2016 (13.x) bis SQL Server 2017 (14.x)) verwenden, planen Sie die Installation der Funktion zur verbesserten Leistungsskalierbarkeit in SQL Server 2016 (13.x) SP2 CU15, SQL Server 2017 (14.x) CU23 und SQL Server 2019 (15.x) CU9 so schnell wie möglich ein. Ohne diese Verbesserung kann bei hoher Ad-hoc-Workload der Datenbank der Abfragespeicher einen großen Teil des Speichers in Anspruch nehmen und die Serverleistung kann beeinträchtigt werden. Nachdem diese Verbesserung angewendet wurde, legt der Abfragespeicher interne Grenzwerte für die Menge an Arbeitsspeicher fest, die von seinen verschiedenen Komponenten verwendet werden kann. Zudem kann der Betriebsmodus automatisch in „schreibgeschützt“ geändert werden, bis genügend Arbeitsspeicher an die Datenbank-Engine zurückgegeben wurde. Die internen Grenzwerte für den Arbeitsspeicher des Abfragespeichers sind nicht dokumentiert, da sie sich ändern können.
Verwenden des Abfragespeichers bei der aktiven Georeplikation in Azure SQL-Datenbank
Beim Abfragespeicher für ein sekundäres aktives Georeplikat von Azure SQL-Datenbank handelt es sich um eine schreibgeschützte Kopie der Aktivität für das primäre Replikat.
Vermeiden Sie nicht übereinstimmende Ebenen mit Azure SQL-Datenbank-Georeplikation. Eine sekundäre Datenbank sollte dieselbe oder eine ähnliche Computegröße wie die primäre Datenbank aufweisen und dieselbe Dienstebene wie die primäre Datenbank verwenden. Suchen Sie nach dem Wartetyp HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO in sys.dm_db_wait_stats, der auf eine Drosselung der Transaktionsprotokollrate für das primäre Replikat aufgrund einer sekundären Verzögerung hinweist.
Weitere Informationen zum Abschätzen und Konfigurieren der Größe der sekundären Azure SQL-Datenbank-Instanz der aktiven Georeplikation finden Sie unter Konfigurieren einer sekundären Datenbank.
Dauerhafte Abfragespeicheranpassung an Ihre Workload
Bewährte Methoden und Empfehlungen zum Konfigurieren und Verwalten von Abfragespeicher wurden in diesem Artikel erweitert: Bewährte Methoden für die Verwaltung der Abfragespeicher.
Zugehöriger Inhalt
- ALTER DATABASE SET-Optionen (Transact-SQL)
- Katalogsichten des Abfragespeichers (Transact-SQL)
- Gespeicherte Prozeduren für den Abfragespeicher (Transact-SQL)
- Verwenden des Abfragespeichers mit In-Memory-OLTP
- Leitfaden zur Architektur der Abfrageverarbeitung
- Abfragespeicherhinweise
- Überwachen der Leistung mit dem Abfragespeicher
- Optimieren der Leistung mit dem Abfragespeicher
- Speicherung und Analyse von Verlaufsabfragen in Azure Synapse Analytics