Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: ![]() SQL Server
SQL Server ![]() Azure SQL-Datenbank
Azure SQL-Datenbank ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() SQL-Datenbank in Microsoft Fabric
SQL-Datenbank in Microsoft Fabric
Mit SQL Server 2016 (13.x) wird die operative Echtzeitanalyse eingeführt, die Möglichkeit, Analyse- und OLTP-Arbeitsauslastungen zugleich auf den gleichen Datenbanktabellen auszuführen. Damit können Sie nicht nur Analysen in Echtzeit ausführen, sondern benötigen auch keine ETL-Aufträge und kein Data Warehouse mehr.
Erläuterung der Betriebsanalysen in Echtzeit
Bisher verwendeten Unternehmen separate Systeme für operative (d. h. OLTP) und Analysearbeitsauslastungen. Bei derartigen Systemen verschieben ETL-Aufträge (Extrahieren, Transformieren, Laden) die Daten aus dem Betriebs- in den Analysespeicher. Die Analysedaten sind normalerweise in einem Data Warehouse oder Data Mart gespeichert, die dediziert für die Ausführung von Analyseabfragen verwendet werden. Diese Lösung hat sich zwar als Standard etabliert, sie sieht sich jedoch diesen drei Herausforderungen gegenüber:
Komplexität. Für das Implementieren von ETL kann Codeerstellung in erheblichem Umfang erforderlich werden, insbesondere, um nur geänderte Zeilen zu laden. Es kann schwierig sein, die geänderten Zeilen zu bestimmen.
Kosten: Die Implementierung von ETL verursacht Kosten durch den Erwerb von Hardware und zusätzlicher Softwarelizenzen.
Datenlatenz. Die Implementierung von ETL bringt eine zeitliche Verzögerung mit sich, die durch die Ausführung der Analyse bedingt ist. Wenn der ETL-Auftrag beispielsweise am Ende jedes Geschäftstags ausgeführt wird, werden die Analyseabfragen auf Daten ausgeführt, die mindestens einen Tag alt sind. Für viele Unternehmen ist diese Verzögerung nicht akzeptabel, da das Unternehmen von einer Analyse der Daten in Echtzeit abhängig ist. Beispielsweise ist für die Erkennung von Betrugsversuchen eine Echtzeitanalyse der Betriebsdaten erforderlich.
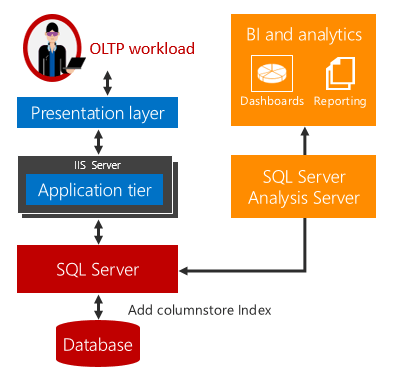
Die operative Echtzeitanalyse stellt eine Lösung für diese Herausforderungen bereit.
Wenn Analyse- und OLTP-Arbeitsauslastungen auf der gleichen zugrundeliegenden Tabelle ausgeführt werden, tritt keine Zeitverzögerung ein. In Szenarien, die Echtzeitanalyse verwenden können, lassen sich Kosten und Komplexität stark verringern, da die Notwendigkeit von ETL sowie von Erwerb und Wartung eines separaten Data Warehouses entfallen.
Hinweis
Die operative Echtzeitanalyse zielt auf das Szenario einer einzelnen Datenquelle ab, etwa einer ERP-Anwendung (Enterprise Resource Planning), auf der sowohl die betriebs- als auch die analysebedingte Arbeitsauslastung ausgeführt werden kann. Die Notwendigkeit eines separaten Data Warehouses entfällt dadurch nicht, wenn vor der Ausführung der Analysearbeitsauslastung Daten aus mehreren Quellen integriert werden müssen, oder für die Analyse extreme Leistungsfähigkeit mithilfe zuvor aggregierter Daten, wie etwa Cubes, erforderlich ist.
Echtzeitanalysen verwenden einen aktualisierbaren Columnstore-Index in einer Rowstore-Tabelle. Der Columnstore-Index unterhält eine Kopie der Daten, sodass die OLTP- und Analysearbeitsauslastungen auf separaten Kopien der Daten ausgeführt werden. Dadurch wird die Leistungseinbuße durch die gleichzeitige Ausführung beider Arbeitsauslastungen minimiert. SQL Server verwaltet Indexänderungen automatisch, sodass OLTP-Änderungen jederzeit für die Analyse auf dem aktuellen Stand verfügbar sind. Mit diesem Entwurf ist es möglich und praktikabel, die Analyse in Echtzeit auf aktuellen Daten auszuführen. Dies funktioniert sowohl für datenträgerbasierte als auch für speicheroptimierte Tabellen.
Beispiel für den Einstieg
So steigen Sie in die Echtzeitanalyse ein:
Bestimmen Sie die Tabellen in Ihrem operationalen Schema, die Daten enthalten, die für die Analyse benötigt werden.
Löschen Sie für jede Tabelle alle B-Strukturindizes, deren Hauptzweck im Beschleunigen der vorhandenen Analyse für Ihre OLTP-Arbeitsauslastung besteht. Ersetzen Sie sie durch einen einzelnen Columnstore-Index. Dadurch wird möglicherweise die Gesamtleistung Ihrer OLTP-Arbeitsauslastung verbessert, da weniger Indizes gewartet werden müssen.
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;Der Columnstore-Index für eine Tabelle im Arbeitsspeicher ermöglicht die operative Echtzeitanalyse durch die Integration von In-Memory-OLTP- und In-Memory-Columnstore-Technologien, durch die hohe Leistung sowohl für die OLTP- als auch für die analysebedingten Workloads möglich werden. Der Columnstore-Index für eine Tabelle im Arbeitsspeicher muss alle Spalten beinhalten.
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON ); GO
Sie können jetzt operative Echtzeitanalyse ausführen, ohne Änderungen an Ihrer Anwendung vornehmen zu müssen. Die Analyseabfragen werden auf dem Columnstore-Index ausgeführt, während die OLTP-Operationen auch weiterhin auf den OLTP-B-Strukturindizes ausgeführt werden. Die OLTP-Arbeitsauslastungen werden auch weiterhin mit hoher Leistung ausgeführt, bringen jedoch einen gewissen Mehraufwand für die Wartung des Columnstore-Index mit sich. Informationen über Leistungsoptimierungen finden Sie im nächsten Abschnitt.
Hinweis
In der Dokumentation wird der Begriff „B-Struktur“ im Allgemeinen in Bezug auf Indizes verwendet. In Zeilenspeicherindizes implementiert die Datenbank-Engine eine B+-Struktur. Dies gilt nicht für Columnstore-Indizes oder In-Memory-Datenspeicher. Weitere Informationen finden Sie im Leitfaden zur Architektur und zum Entwerfen von SQL Server- und Azure SQL-Indizes.
Blogbeiträge
In den folgenden Blogbeiträgen erfahren Sie mehr über die operative Echtzeitanalyse. Möglicherweise sind die Abschnitte zu Leistungstipps leichter zu verstehen, wenn Sie sich zuerst die Blogbeiträge ansehen.
Videos
Die Videoreihe "Data Exposed" enthält ausführlichere Informationen zu einigen der Funktionen und Überlegungen.
- Teil 1: So ermöglicht Azure SQL Die Betriebsanalyse in Echtzeit (HTAP)
- Teil 2: Optimieren vorhandener Datenbanken und Anwendungen mit Betriebsanalysen
- Teil 3: Erstellen von Betriebsanalysen mit Fensterfunktionen.
Leistungstipp Nr. 1: Verwenden von gefilterten Indizes zum Verbessern der Abfrageleistung
Das Ausführen der operativen Echtzeitanalyse kann die Leistung der OLTP-Arbeitsauslastung beeinträchtigen. Dieser Einfluss sollte so klein wie möglich sein. Beispiel A zeigt, wie gefilterte Indizes verwendet werden, um die Auswirkungen des nicht gruppierten Columnstore-Index auf transaktionsrelevante Arbeitsauslastungen zu minimieren und gleichzeitig Analysen in Echtzeit zu liefern.
Um den Mehraufwand für die Wartung eines nicht gruppierten Columnstore-Index für eine Betriebsarbeitsauslastung zu minimieren, können Sie eine gefilterte Bedingung verwenden, um einen nicht gruppierten Columnstore-Index nur für die warmen oder sich langsam ändernden Daten zu erstellen. Beispielsweise können Sie in einer Anwendung zur Bestellungsverwaltung einen nicht gruppierten Columnstore-Index für die bereits versendeten Bestellungen erstellen. Nach dem Versand ändert sich eine Bestellung in der Regel nicht mehr, daher können diese Daten als „warm“ angesehen werden. Bei einem gefilterten Index erfordern die Daten im nicht gruppierten Columnstore-Index weniger Aktualisierungen, wodurch sich der Einfluss auf die Transaktionsarbeitsauslastung verringert.
Analyseabfragen greifen bei Bedarf transparent sowohl auf „warme“ als auch auf „heiße“ Daten zu, um Echtzeitanalyse bereitzustellen. Wenn ein erheblicher Anteil der Betriebsworkload die „heißen“ Daten betrifft, ist für diese Vorgänge keine zusätzliche Wartung des Columnstore-Index erforderlich. Eine bewährte Methode ist die Erstellung eines gruppierten Rowstore-Index für die in der gefilterten Indexdefinition verwendeten Spalten. SQL Server verwendet den gruppierten Index, um schnell die Zeilen zu durchsuchen, die der Filterbedingung nicht entsprochen haben. Ohne diesen gruppierten Index ist ein vollständiger Scan der Rowstore-Tabelle erforderlich, um diese Zeilen zu finden, was sich deutlich negativ auf die Leistung der Analyseabfrage auswirken kann. Ohne Einsatz eines gruppierten Index lässt sich auch ein komplementär gefilterter, nicht gruppierter B-Strukturindex zur Bestimmung dieser Zeilen verwenden, jedoch ist das nicht zu empfehlen, da der Zugriff auf einen großen Zeilenbereich über nicht gruppierte B-Strukturindizes aufwändig ist.
Hinweis
Ein gefilterter nicht gruppierter Columnstore-Index wird nur für datenträgerbasierte Tabellen unterstützt. Für speicheroptimierte Tabellen wird er nicht unterstützt
Beispiel A: Zugriff auf „heiße“ Daten über einen B-Strukturindex, auf „warme“ Daten über einen Columnstore-Index
In diesem Beispiel wird eine gefilterte Bedingung (accountkey > 0) verwendet, um festzulegen, welche Zeilen sich im Spaltenspeicherindex befinden. Dies hat den Zweck, die Filterbedingung und die nachfolgenden Abfragen so zu gestalten, dass auf sich häufig ändernde „heiße“ Daten über den B+-Strukturindex, auf die stabileren „warmen“ Daten über den Columnstore-Index zugegriffen wird.

Hinweis
Der Abfrageoptimierer zieht den Columnstore-Index für den Abfrageplan in Betracht, wählt ihn aber nicht in jedem Fall aus. Wenn der Abfrageoptimierer den gefilterten Columnstore-Index wählt, kombiniert er transparent die Zeilen aus dem Columnstore-Index mit den Zeilen, die der Filterbedingung nicht entsprechen, um Echtzeitanalyse zu ermöglichen. Dies unterscheidet sich von einem gewöhnlichen nicht gruppierten gefilterten Index, der nur in Abfragen verwendet werden kann, die sich auf die im Index vorhandenen Zeilen beschränken.
--Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
Customername nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50));
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fulfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
where orderstatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT top 5 customername, sum (PurchasePrice)
FROM orders
WHERE purchaseprice > 100.0
Group By customername;
Die Analyseabfrage wird mit dem folgenden Abfrageplan ausgeführt. Es ist zu sehen, dass der Zugriff auf die Zeilen, die der Filterbedingung nicht entsprechen, über den gruppierten B-Strukturindex erfolgt.

Weitere Informationen finden Sie im Blog: Gefilterter nicht gruppierter Spaltenspeicherindex.
Leistungstipp Nr. 2: Auslagern der Analyse auf eine schreibgeschützte sekundäre Always On-Datenbank
Zwar kann der Wartungsaufwand für den Columnstore-Index durch Verwendung eines gefilterten Columnstore-Index minimiert werden, die Analyseabfragen können jedoch trotzdem erhebliche Computerressoucen (CPU, E/A, Arbeitsspeicher) in Anspruch nehmen, was sich negativ auf die für die Betriebsworkload verfügbare Leistung auswirkt. Für die meisten unternehmenswichtigen Arbeitsauslastungen ergibt sich als unsere Empfehlung die Always On-Konfiguration. In dieser Konfiguration kann der Einfluss der Ausführung der Analyse beseitigt werden, indem sie in eine schreibgeschützte sekundäre Datenbank ausgelagert wird.
Leistungstipp Nr. 3: Reduzierung der Indexfragmentierung durch Speicherung der „heißen“ Daten in Deltazeilengruppen
Tabellen mit Spaltenspeicherindex werden möglicherweise erheblich fragmentiert (d. h. gelöschte Zeilen), wenn die Workload Zeilen aktualisiert/löscht, die komprimiert wurden. Ein fragmentierter Columnstore-Index führt zu einer ineffizienten Auslastung von Arbeitsspeicher/Speicherplatz. Neben dem ineffizienten Ressourceneinsatz wirkt er sich auch negativ auf die Analyseabfrageleistung aus, da zusätzliche E/A-Vorgänge anfallen und es erforderlich ist, die gelöschten Zeilen aus dem Resultset zu filtern.
Die gelöschten Zeilen werden physisch erst beim Ausführen der Indexdefragmentierung mit dem Befehl REORGANIZE oder durch Neuerstellung des Columnstore-Index für die gesamte Tabelle oder die betroffene(n) Partition(en) entfernt. Sowohl REORGANIZE als auch REBUILD sind aufwändige Indexvorgänge, die Ressourcen beanspruchen, die andernfalls für die Workload zur Verfügung stünden. Wenn Zeilen zu früh komprimiert wurden, muss sie möglicherweise aufgrund von Updates, die zu einem verschwendeten Komprimierungsaufwand führen, mehrmals komprimiert werden.
Die Indexfragmentierung kann mithilfe der Option COMPRESSION_DELAY minimiert werden.
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY. The columnstore index will keep the rows in closed delta rowgroup for 100 minutes
-- after it has been marked closed
CREATE NONCLUSTERED COLUMNSTORE index t_colstor_cci on t_colstor (accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION= COLUMNSTORE, COMPRESSION_DELAY = 100);
Weitere Informationen finden Sie im Blog: Komprimierungsverzögerung.
Im Folgenden werden die empfohlenen bewährten Methoden aufgeführt:
Einfüge-/Abfragearbeitsauslastung: Wenn Ihre Arbeitsauslastung in erster Linie Daten einfügt und sie abfragt, stellt der Standardwert 0 für COMPRESSION_DELAY die empfohlene Option dar. Die neu eingefügten Zeilen werden komprimiert, sobald eine Million Zeilen in eine einzelne Deltazeilengruppe eingefügt wurden.
Einige Beispiele für diese Workload sind (a) herkömmliche DW-Workload (b) Select-Stream-Analyse, wenn Sie das Auswahlmuster in einer Webanwendung analysieren müssen.OLTP-Workload: Wenn die Workload DML schwer ist (d. h. eine schwere Mischung aus Update, Löschen und Einfügen), wird möglicherweise die Fragmentierung des Spaltenspeicherindex durch Untersuchen der DMV
sys. dm_db_column_store_row_group_physical_statsangezeigt. Wenn Sie dabei sehen, dass > 10 % der Zeilen in kürzlich komprimierten Zeilengruppen als gelöscht markiert wurden, können Sie die Option COMPRESSION_DELAY verwenden, um eine Zeitverzögerung bis zur Qualifikation der Zeilen zur Komprimierung hinzuzufügen. Wenn bei Ihrer Arbeitsauslastung neu eingefügte Datensätze normalerweise für etwa 60 Minuten „heiß“ bleiben (d. h. in dieser Zeit mehrfach aktualisiert werden), sollten Sie COMPRESSION_DELAY auf 60 festlegen.
Wir gehen davon aus, dass die meisten Kunden keine Anpassungen vornehmen müssen. Der Standardwert der COMPRESSION_DELAY Option sollte für sie funktionieren.
Für vorausgestellte Benutzer wird empfohlen, die folgende Abfrage auszuführen und % der gelöschten Zeilen in den letzten sieben Tagen zu erfassen.
SELECT row_group_id,cast(deleted_rows as float)/cast(total_rows as float)*100 as [% fragmented], created_time
FROM sys. dm_db_column_store_row_group_physical_stats
WHERE object_id = object_id('FactOnlineSales2')
AND state_desc='COMPRESSED'
AND deleted_rows>0
AND created_time > GETDATE() - 7
ORDER BY created_time DESC;
Wenn die Anzahl der gelöschten Zeilen in komprimierten Zeilengruppen > 20 % beträgt, wird das Plateauing in älteren Zeilengruppen mit < einer Variation von 5 % (als kalte Zeilengruppen bezeichnet) = (youngest_rowgroup_created_time - current_time) festgelegt COMPRESSION_DELAY . Dieser Ansatz funktioniert am besten mit einer stabilen und relativ homogenen Arbeitsauslastung.