Datenqualität für Microsoft Synapse serverlos und Data Warehouse
Azure Synapse Analytics ist ein Unternehmensanalysedienst, der die Zeit für Einblicke in Data Warehouses und Big Data-Systeme beschleunigt. Es vereint die besten SQL-Technologien, die im Data Warehousing für Unternehmen verwendet werden, Apache Spark-Technologien für Big Data und Azure Data Explorer für Protokoll- und Zeitreihenanalysen.
Azure Synapse ist ein unbegrenzter Analysedienst, der Data Warehousing und Big Data-Analysen für Unternehmen vereint. Es bietet Ihnen die Möglichkeit, Daten nach Ihren Bedingungen abzufragen, entweder mit serverlosen oder dedizierten Ressourcen – im großen Stil. Weitere Informationen zu Azure Synapse finden Sie in der Fabric-Dokumentation.
Beispiel für einen Synapse-Arbeitsbereich mit einer instance der Tabelle "Dedicated Synapse Data Warehouse (DWH)" (Employee) und einer serverlosen Datenbank (SQL_ON_DEMAND) mit synapseSalesDelta-Tabelle.
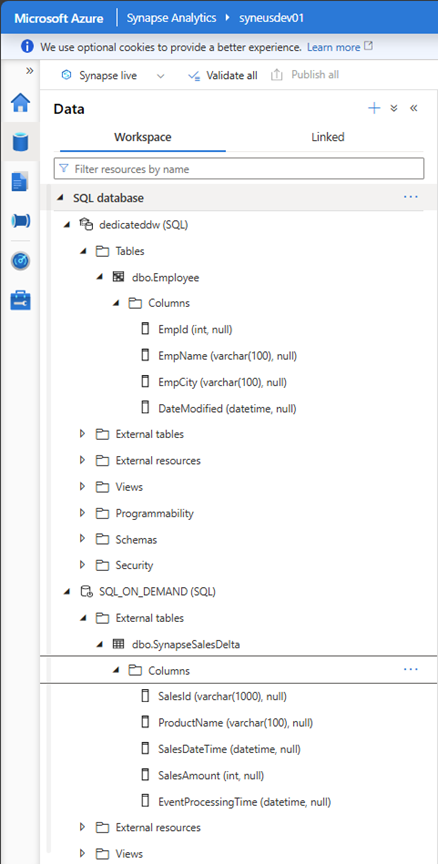
Nach der Überprüfung sind die Ressourcen in Microsoft Purview verfügbar. Es folgt ein Beispiel für eine Employee-Tabelle in Synapse Analytics Dedicated instance.
Azure Synapse Analytics Dedicated (Data Warehouse)
Einrichten der Data Map-Überprüfung
Um Azure Synapse Analytics Dedicated (Data Warehouse) zu überprüfen, befolgen Sie die Dokumentation. Um die erforderlichen MI-Berechtigungen für den dedizierten DWH-instance zu erteilen, folgen Sie der Dokumentation.
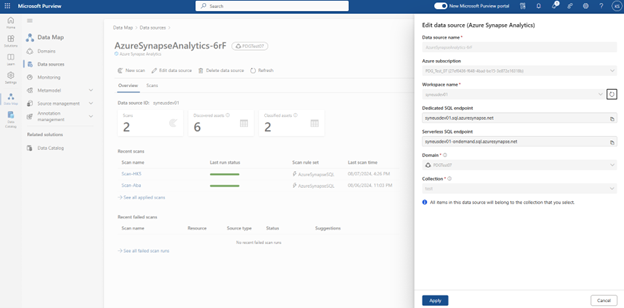
Nach dem Scannen sind die Ressourcen im Microsoft Purview-Katalog verfügbar. Es folgt ein Beispiel für eine Employee-Tabelle in Synapse Analytics Dedicated instance.
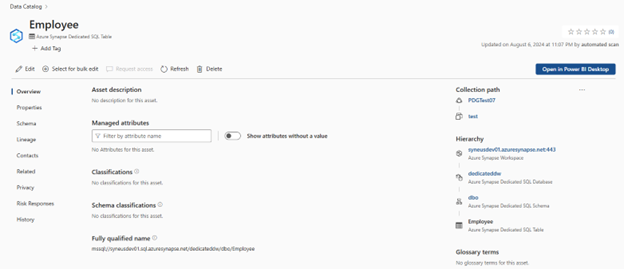
Einrichten der Verbindung mit Ihrem dedizierten Synapse Data Warehouse
An diesem Punkt haben wir die gescannte Ressource für die Katalogisierung und Governance bereit. Ordnen Sie das gescannte Medienobjekt dem Datenprodukt in einer Governancedomäne zu. Fügen Sie auf der Registerkarte Datenqualität eine neue Azure SQL Datenbankverbindung hinzu: Rufen Sie den manuell eingegebenen Datenbanknamen ab.
Wählen Sie die Registerkarte Datenqualitäts-Governancedomäne >> Verwalten aus, um eine Verbindung zu erstellen.
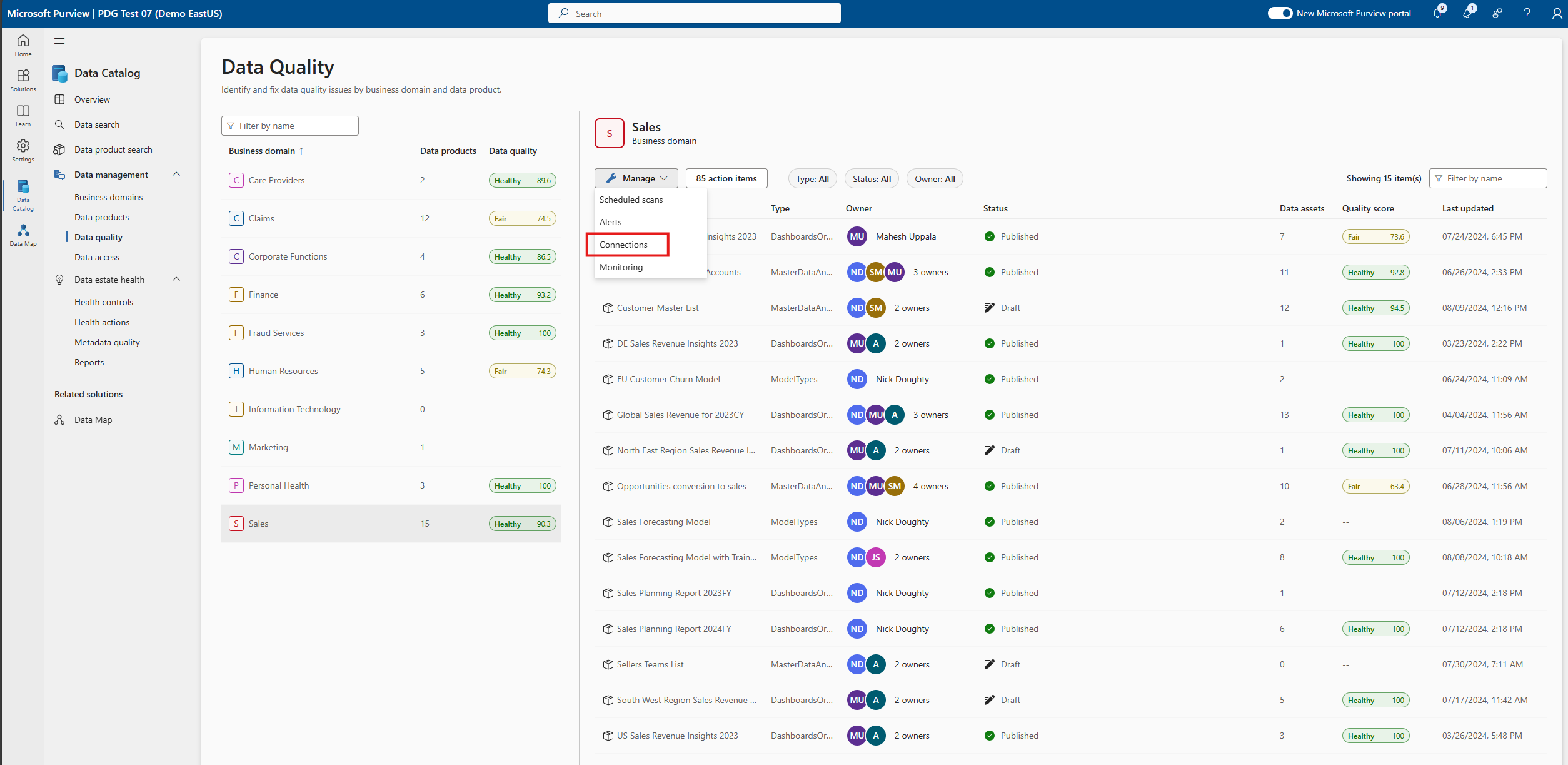
Konfigurieren Sie die Verbindung auf der Verbindungsseite.
- Fügen Sie den Verbindungsnamen und die Beschreibung hinzu.
- Wählen Sie quelltyp Azure Synapse Analytics aus.
- Wählen Sie Azure-Abonnement aus.
- Wählen Sie Arbeitsbereichsname aus.
- Wählen Sie Dedizierter SQL-Endpunkt aus.
- Wählen Sie serverloser SQL-Endpunkt aus.
- Wählen Sie Endpunkttyp aus.
- Wählen Sie Datenbank aus.
- Fügen Sie MSI als Anmeldeinformationen hinzu.
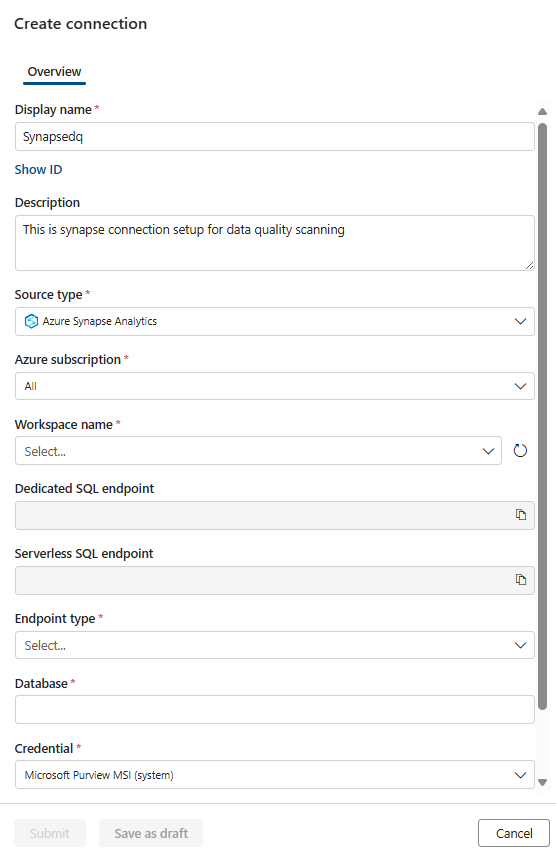
Testen Sie die Verbindung. Nachdem Sie die Datenquellenverbindung konfiguriert und erfolgreich getestet haben, können Sie mit dem Konfigurieren und Ausführen von Datenprofilerstellungs- und Data Quality-Überprüfungen fortfahren.
Wenn sich Ihre Synapse-Datenquelle hinter einem privaten Endpunkt befindet, müssen Sie das verwaltete VNET aktivieren. Befolgen Sie das Dokument zum Konfigurieren eines verwalteten VNET.


Wichtig
Data Quality-Stewards benötigen schreibgeschützten Zugriff auf das dedizierte Synapse Data Warehouse, um eine Data Quality-Verbindung einzurichten. Beim Setup eines verwalteten VNET können Sie die Verbindung nicht testen.
Profilerstellung und Datenqualitätsüberprüfung für Daten im dedizierten Synapse Data Warehouse
Nachdem die Verbindungseinrichtung erfolgreich abgeschlossen wurde, können Sie ein Profil erstellen, Regeln erstellen und anwenden und eine DQ-Überprüfung Ihrer Daten im Synapse-Warehouse ausführen. Befolgen Sie die schritt-für-Schritt-Anleitung, die in den folgenden Dokumenten beschrieben wird:
- Konfigurieren und Ausführen der Datenprofilerstellung für Ihre Daten
- Konfigurieren und Ausführen der Datenqualitätsüberprüfung
Wichtig
- Die Leistung der Abfragen und sogar die erfolgreichen Ausführungen hängen von der DW-Konfiguration ab, die die Kunden für ihre dedizierten Datenbankinstanzen haben.
- Entsprechende DQ-Bewertungsaufträge oder in diesem Fall ein anderer DQ-Auftrag führt zu einer Verbindung mit dem dedizierten Dw und kann fehlschlagen, wenn die instance bereitgestellt wird oder bei Parallelitätsgrenzwerten fehlschlägt. Kunden müssen die DW-Konfiguration kennen. Seine Parallelität hat sehr harte Grenzen für jede instance in der Zeit.
- Parallelitätsgrenzwerte können zur Beendigung des Auftrags führen. DW-Grenzwerte (z. B. 1000 DW) stellen die Leistung zum Ausführen der Abfragen bereit.
- Die vNET-Unterstützung befindet sich in der Vorschauphase mit Unterstützung für allgemein verfügbare Netzwerke.
serverlos Azure Synapse Analytics
Einrichten der Data Map-Überprüfung
Um Azure Synapse Analytics serverlos zu überprüfen, befolgen Sie die Dokumentation. Um die erforderlichen MI-Berechtigungen für den dedizierten DWH-instance zu erteilen, folgen Sie der Dokumentation. Nach der Überprüfung sind die serverlosen Ressourcen im Microsoft Purview-Katalog verfügbar.
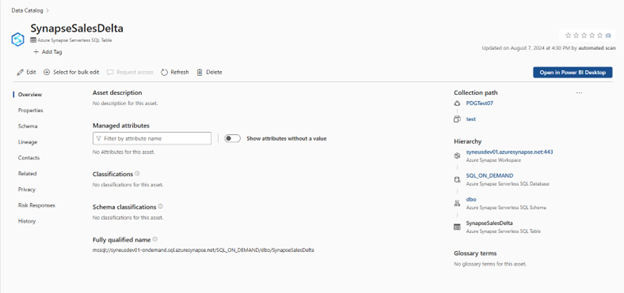
Einrichten einer Verbindung mit Synapse Serverless
An diesem Punkt haben wir die gescannte Ressource für die Katalogisierung und Governance bereit. Ordnen Sie das gescannte Medienobjekt dem Datenprodukt in einer Governancedomäne zu. Fügen Sie in Data Quality eine neue Azure SQL Datenbankverbindung hinzu: Rufen Sie den manuell eingegebenen Datenbanknamen ab.
Wählen Sie die RegisterkarteDatenqualitäts-Governancedomäne>> Verwalten aus, um eine Verbindung zu erstellen.
Konfigurieren Sie die Verbindung auf der Verbindungsseite.
- Fügen Sie den Verbindungsnamen und die Beschreibung hinzu.
- Wählen Sie quelltyp Azure Synapse Analytics aus.
- Wählen Sie Azure-Abonnement aus.
- Wählen Sie Arbeitsbereichsname aus.
- Wählen Sie Dedizierter SQL-Endpunkt aus.
- Wählen Sie serverloser SQL-Endpunkt aus.
- Wählen Sie Endpunkttyp aus.
- Wählen Sie Datenbank aus.
- Fügen Sie MSI als Anmeldeinformationen hinzu.
Testen Sie die Verbindung. Nachdem Sie die Datenquellenverbindung konfiguriert und erfolgreich getestet haben, können Sie mit dem Konfigurieren und Ausführen von Datenprofilerstellungs- und Data Quality-Überprüfungen fortfahren.
Wenn sich Ihre Synapse-Datenquelle hinter einem privaten Endpunkt befindet, müssen Sie das verwaltete VNET aktivieren. Befolgen Sie das Dokument zum Konfigurieren eines verwalteten VNET.
Wichtig
- Data Quality-Stewards benötigen schreibgeschützten Zugriff auf das dedizierte Synapse Data Warehouse, um eine Data Quality-Verbindung einzurichten.
- Beim serverlosen Synapse-Setup verweist die externe Tabelle auf Delta-formatierte Daten, die in ADLS Gen2 gespeichert sind.
- Die vNet-Unterstützung befindet sich in der gated-Vorschau. Wenden Sie sich an das Purview-Vertriebsteam, um Ihren Mandanten für gated preview in die Positivliste zu eintragen.
- Synapse Connector erkennt und unterstützt nur sql.azuresynapse.net. Wenn der von Ihrem Data Mmap-Scan generierte vollqualifizierte Name (Fully Qualified Name, FQN) database.windows.net enthält, schlägt die Synapse-Verbindung für die DQ-Überprüfung fehl.
Profilerstellung und Datenqualitätsüberprüfung (DQ) für Daten in synapse serverlos
Nachdem die Verbindungseinrichtung erfolgreich abgeschlossen wurde, können Sie ein Profil erstellen, Regeln erstellen und anwenden und eine Datenqualitätsüberprüfung (Data Quality, DQ) Ihrer Daten im Synapse-Warehouse ausführen. Befolgen Sie die schritt-für-Schritt-Anleitung, die in den folgenden Dokumenten beschrieben wird:
- Konfigurieren und Ausführen der Datenprofilerstellung für Ihre Daten
- Konfigurieren und Ausführen der Datenqualitätsüberprüfung
Wichtig
- Die DQ-Bewertungen, die Profilerstellung wird auf Spark im Hintergrund ausgeführt. Kunden verfügen über mehrere Verbindungen, bei denen jeder Spark-Knoten über eine Verbindungs-SPID verfügt, sodass DWH aktuelle Abfragegrenzwerte aufweisen kann, wenn sie verwendet/geplant über DW-Grenzwerte hinausgeht, was zu Fehlern führt. Für Azure Synapse Serverlose SQL-Tabelle gelten jedoch keine Parallelitätsgrenzwerte. Dies hängt vollständig von den Serverless Delta Parquet-Optimierungen ab, die kunden für ihre ADLS Gen2-instance haben. Die Engine kann eng betrachtet werden, da Databricks Serverless DW auf externen Lakehouse-Quellen wie DELTA-Formattabellen arbeitet.