Benutzerhandbuch für Datenherkunft
Dieser Artikel bietet eine Übersicht über die Datenherkunftsfeatures im klassischen Microsoft Purview Data Catalog.
Um die Datenherkunft im Unified Catalog anzuzeigen, müssen Sie zuerst nach einem Datenprodukt suchen und dann Details zur Datenressource anzeigen.
Hintergrund
Eines der Plattformfeatures von Microsoft Purview ist die Möglichkeit, die Herkunft zwischen Datasets anzuzeigen, die von Datenprozessen erstellt wurden. Systeme wie Data Factory, Data Share und Power BI erfassen die Datenherkunft beim Verschieben. Benutzerdefinierte Herkunftsberichte werden auch über Atlas-Hooks und die REST-API unterstützt.
Herkunftsauflistung
Metadaten, die in Microsoft Purview von Unternehmensdatensystemen gesammelt werden, werden zusammengefügt, um eine End-to-End-Datenherkunft anzuzeigen. Datensysteme, die Datenherkunft in Microsoft Purview erfassen, sind allgemein in die folgenden drei Typen unterteilt:
Jedes System unterstützt eine andere Ebene des Herkunftsbereichs. Überprüfen Sie die folgenden Abschnitte oder den artikel über die individuelle Herkunft Ihres Systems, um den derzeit verfügbaren Herkunftsbereich zu überprüfen.
Bekannte Einschränkungen
- Datenbanksichten, die als Quelle der Prozessaktivität (Azure Data Factory, Synapse-Pipelines, Azure SQL-Datenbank, Azure Data Share) verwendet werden, werden derzeit als Datenbanktabellenobjekte in Microsoft Purview erfasst. Wenn die Datenbank ebenfalls gescannt wird, werden die Objekte anzeigen separat in Microsoft Purview ermittelt. In diesem Szenario werden zwei Objekte mit demselben Namen in Microsoft Purview erfasst, eines als Tabelle mit Datenherkunft und ein anderes als Ansicht.
- Wenn eine gespeicherte Prozedur Drop- oder Create-Anweisungen enthält, werden sie derzeit nicht in der Herkunft erfasst.
Datenverarbeitungssysteme
Datenintegrations- und ETL-Tools können die Datenherkunft zur Ausführungszeit in Microsoft Purview pushen. Tools wie Data Factory, Data Share, Synapse, Azure Databricks usw. gehören zu dieser Kategorie von Datenverarbeitungssystemen. Die Datenverarbeitungssysteme verweisen auf Datasets als Quelle aus verschiedenen Datenbanken und Speicherlösungen, um Zieldatasets zu erstellen. Die Liste der Datenverarbeitungssysteme, die derzeit in Microsoft Purview für die Herkunft integriert sind, ist in der folgenden Tabelle aufgeführt.
| Datenverarbeitungssystem | Unterstützter Bereich |
|---|---|
| Luftstrom | Airflow-Herkunft |
| Azure Data Share | Momentaufnahme freigeben |
| Azure Data Factory |
Copy-Aktivität Datenflussaktivität Aktivität "SSIS-Paket ausführen" |
| Azure SQL-Datenbank (Vorschau) | Herkunftsextraktion für Ausführungen gespeicherter Prozeduren |
| Azure Synapse Analytics |
Copy-Aktivität Datenflussaktivität |
Datenspeichersysteme
Datenbanken & Speicherlösungen wie Oracle, Teradata und SAP verfügen über Abfrage-Engines zum Transformieren von Daten mithilfe der Skriptsprache. Datenherkunftsinformationen aus Ansichten/gespeicherten Prozeduren/etc werden in Microsoft Purview gesammelt und mit der Herkunft aus anderen Systemen zusammengefügt. Die Herkunft wird für die folgenden Datenquellen über die Microsoft Purview-Datenüberprüfung unterstützt. Weitere Informationen zu den unterstützten Herkunftsszenarien finden Sie im entsprechenden Artikel.
| Kategorie | Datenquelle |
|---|---|
| Azure | Azure Databricks |
| Datenbank | Cassandra |
| Db2 | |
| Google BigQuery | |
| Hive-Metastore-Datenbank | |
| MySQL | |
| Oracle | |
| PostgreSQL | |
| Schneeflocke | |
| Teradata | |
| Dienste und Apps | Erwin |
| Looker | |
| SAP ECC | |
| SAP S/4HANA |
Datenanalyse- und Berichterstellungssysteme
Datenanalyse- und Berichterstellungssysteme wie Azure Machine Learning und Power BI melden die Herkunft in Microsoft Purview. Diese Systeme verwenden die Datasets aus Speichersystemen und verarbeiten über ihr Metamodell, um BI-Dashboards, ML-Experimente usw. zu erstellen.
| Berichterstellungssystem für Datenanalysen & | Unterstützter Bereich |
|---|---|
| Power BI | Datasets, Dataflows, Berichte & Dashboards |
Erste Schritte mit der Herkunft
Die Herkunft in Microsoft Purview umfasst Datasets und Prozesse. Datasets werden auch als Knoten bezeichnet, während Prozesse auch als Edges bezeichnet werden können:
Dataset (Knoten): Ein Dataset (strukturiert oder unstrukturiert), das als Eingabe für einen Prozess bereitgestellt wird. Beispielsweise werden eine SQL-Tabelle, ein Azure-Blob und Dateien (z. B. .csv und .xml) als Datasets betrachtet. Im Abschnitt "Herkunft" von Microsoft Purview werden Datasets durch rechteckige Felder dargestellt.
Prozess (Edge): Eine Aktivität oder Transformation, die für ein Dataset ausgeführt wird, wird als Prozess bezeichnet. ADF-Copy-Aktivität, Data Share Momentaufnahme usw. Im Abschnitt "Herkunft" von Microsoft Purview werden Prozesse durch abgerundete Felder dargestellt.
Führen Sie die folgenden Schritte aus, um auf Herkunftsinformationen für ein Medienobjekt in Microsoft Purview zuzugreifen:
Öffnen Sie das klassische Microsoft Purview-Governanceportal wie folgt:
- Navigieren Sie direkt zu https://web.purview.azure.com Ihrem Microsoft Purview-Konto, und wählen Sie es aus.
- Öffnen Sie die Azure-Portal, suchen Sie nach dem Microsoft Purview-Konto, und wählen Sie es aus. Wählen Sie die Schaltfläche Microsoft Purview-Governanceportal aus.
Suchen Sie auf der Startseite des Microsoft Purview-Governanceportals nach einem Datasetnamen oder dem Prozessnamen, z. B. ADF-Kopie oder Datenfluss-Aktivität. Drücken Sie dann die EINGABETASTE.
Wählen Sie in den Suchergebnissen das Medienobjekt und dann die Registerkarte Herkunft aus.
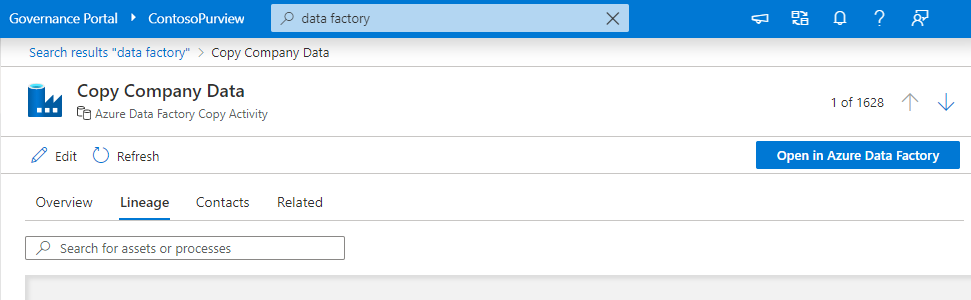
Herkunft auf Ressourcenebene
Microsoft Purview unterstützt die Herkunft auf Ressourcenebene für die Datasets und Prozesse. Um die Herkunft auf Ressourcenebene anzuzeigen, wechseln Sie zur Registerkarte Herkunft des aktuellen Medienobjekts im Katalog. Wählen Sie den aktuellen Ressourcenknoten des Datasets aus. Standardmäßig wird die Liste der Spalten, die zu den Daten gehören, im linken Bereich angezeigt.

Manuelle Herkunft
Die Datenherkunft in Microsoft Purview ist für viele Ressourcen in lokalen, Multicloud- und SaaS-Umgebungen automatisiert . Während wir weiterhin automatisierte Quellen hinzufügen, können Sie mit der manuellen Herkunft Herkunftsmetadaten für Quellen dokumentieren, bei denen die Automatisierung noch nicht unterstützt wird, ohne Code zu verwenden.
Führen Sie die folgenden Schritte aus, um eine manuelle Herkunft für Ihre Ressourcen hinzuzufügen:
Suchen Sie im klassischen Data Catalog nach Ihrer Ressource, und wählen Sie sie aus, um Details anzuzeigen.
Wählen Sie Bearbeiten aus, navigieren Sie zur Registerkarte Herkunft , und wählen Sie im unteren Bereich manuelle Herkunft hinzufügen aus.
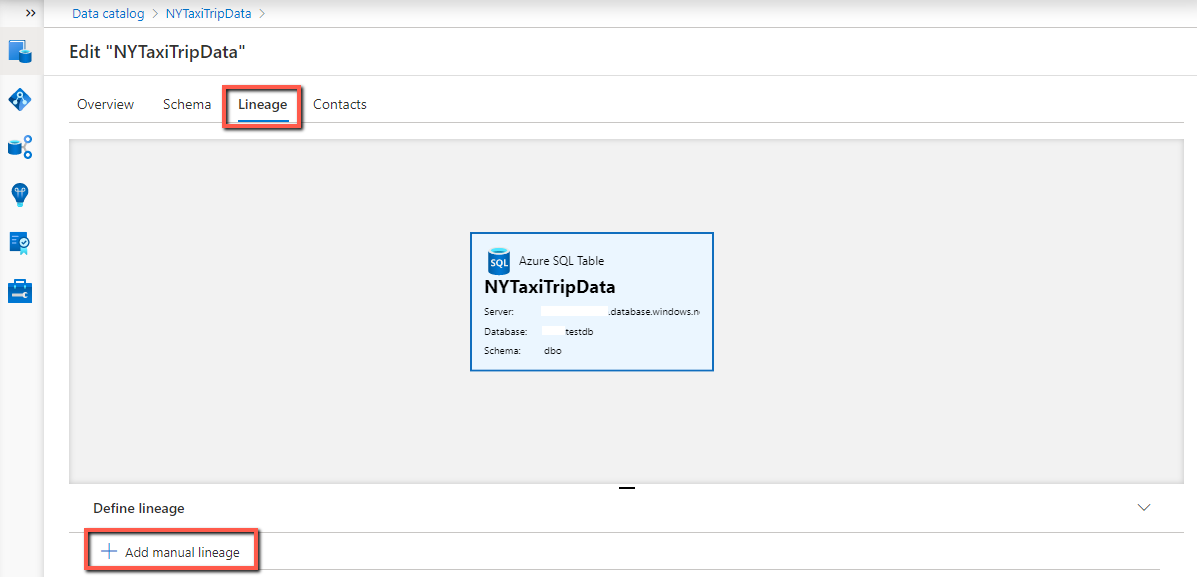
So konfigurieren Sie die Ressourcenherkunft:
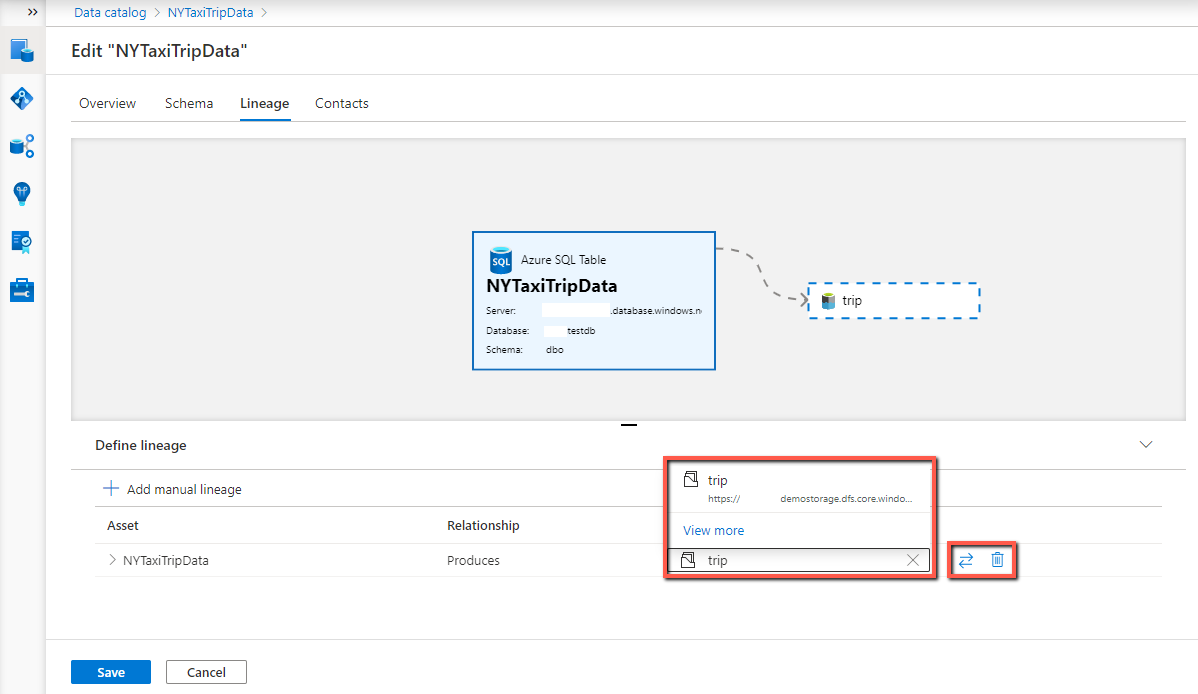
- Wählen Sie das Ressourcendropdown aus, um das Medienobjekt aus der Liste der vorgeschlagenen Ressourcen zu finden, oder Mehr anzeigen , um den vollständigen Katalog zu durchsuchen. Wählen Sie die Ressource aus, die Sie verknüpfen möchten.
- Wählen Sie das Tauschsymbol aus, um die Beziehungsrichtung als Erzeugt (für downstream-Herkunft) oder Verbraucht (für Upstream Herkunft) zu konfigurieren.
- Wenn Sie eine Herkunft löschen möchten, wählen Sie das Papierkorbsymbol aus.
Wenn Sie die Herkunft zwischen zwei Datenassets hinzufügen, können Sie zusätzlich die Herkunft auf Spaltenebene konfigurieren. Wählen Sie das Erweiterungssymbol am Anfang der Zeile aus, und wählen Sie die Upstream- und downstream-Spalten aus den entsprechenden Dropdownlisten aus, um die Spaltenzuordnung zu konfigurieren. Wählen Sie das Plussymbol aus, um weitere Spaltenherkunft hinzuzufügen. Wählen Sie das Papierkorbsymbol aus, um vorhandene zu löschen.
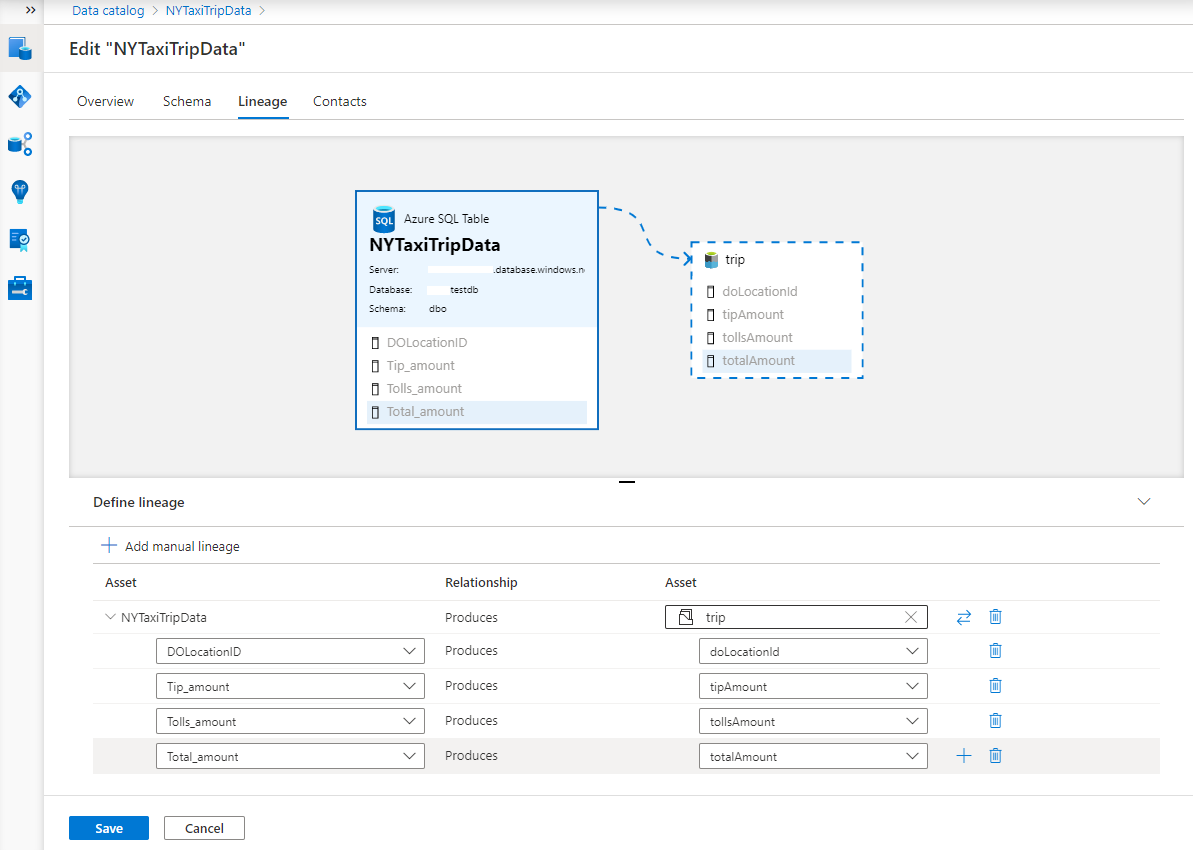
Sie können eine weitere Herkunft auf Ressourcenebene hinzufügen, indem Sie erneut die Schaltfläche Manuelle Herkunft hinzufügen auswählen. Wenn Sie fertig sind, wählen Sie die Schaltfläche Speichern aus, um Ihre Herkunft zu speichern und den Bearbeitungsmodus zu beenden.
Bekannte Einschränkungen der manuellen Herkunft
- Die aktuelle Benutzeroberfläche für die Ressourcenauswahl ermöglicht die Auswahl jeweils nur eines Medienobjekts.
- Die manuelle Herkunft auf Spaltenebene wird derzeit für die Herkunft zwischen zwei Datenassets unterstützt, während sie nicht unterstützt wird, wenn ein Prozessobjekt dazwischen beteiligt ist.
- Daten curation-Zugriff für Quell- und Zielressourcen erforderlich.
- Diese Ressourcentypen lassen derzeit keine manuelle Herkunft zu, da sie die automatisierte Herkunft unterstützen:
- Azure Data Factory
- Synapse-Pipelines
- Power BI-Datasets
- Gespeicherte Teradata-Prozedur
- Azure SQL gespeicherte Prozedur
Datasetspaltenherkunft
Um die Herkunft eines Datasets auf Spaltenebene anzuzeigen, wechseln Sie zur Registerkarte Herkunft des aktuellen Medienobjekts im Katalog, und führen Sie die folgenden Schritte aus:
Sobald Sie sich auf der Registerkarte Herkunft befinden, aktivieren Sie im linken Bereich das Kontrollkästchen neben jeder Spalte, die Sie in der Datenherkunft anzeigen möchten.
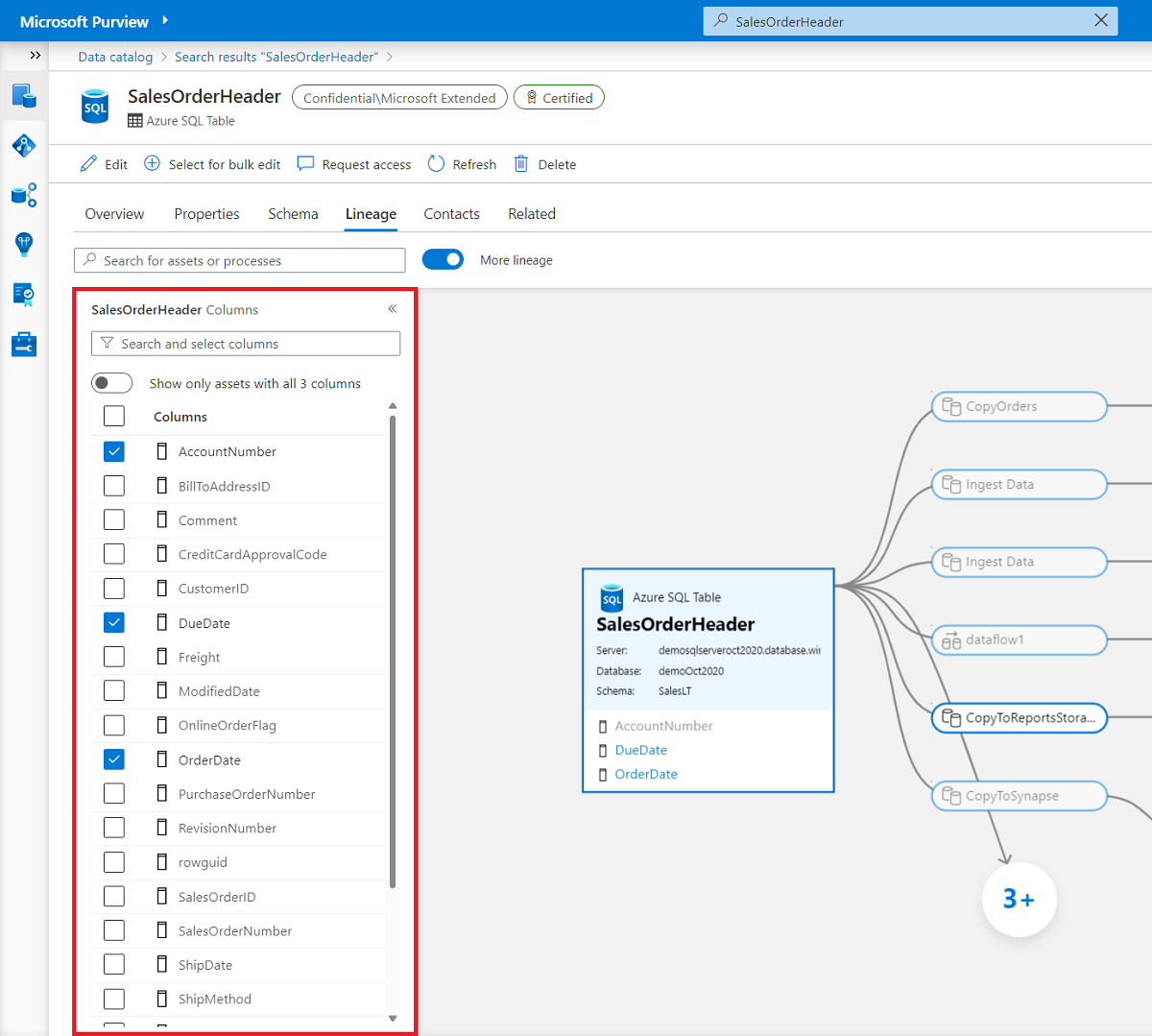
Zeigen Sie auf eine ausgewählte Spalte im linken Bereich oder in das Dataset des Herkunftsbereichs, um die Spaltenzuordnung anzuzeigen. Alle Spalteninstanzen sind hervorgehoben.
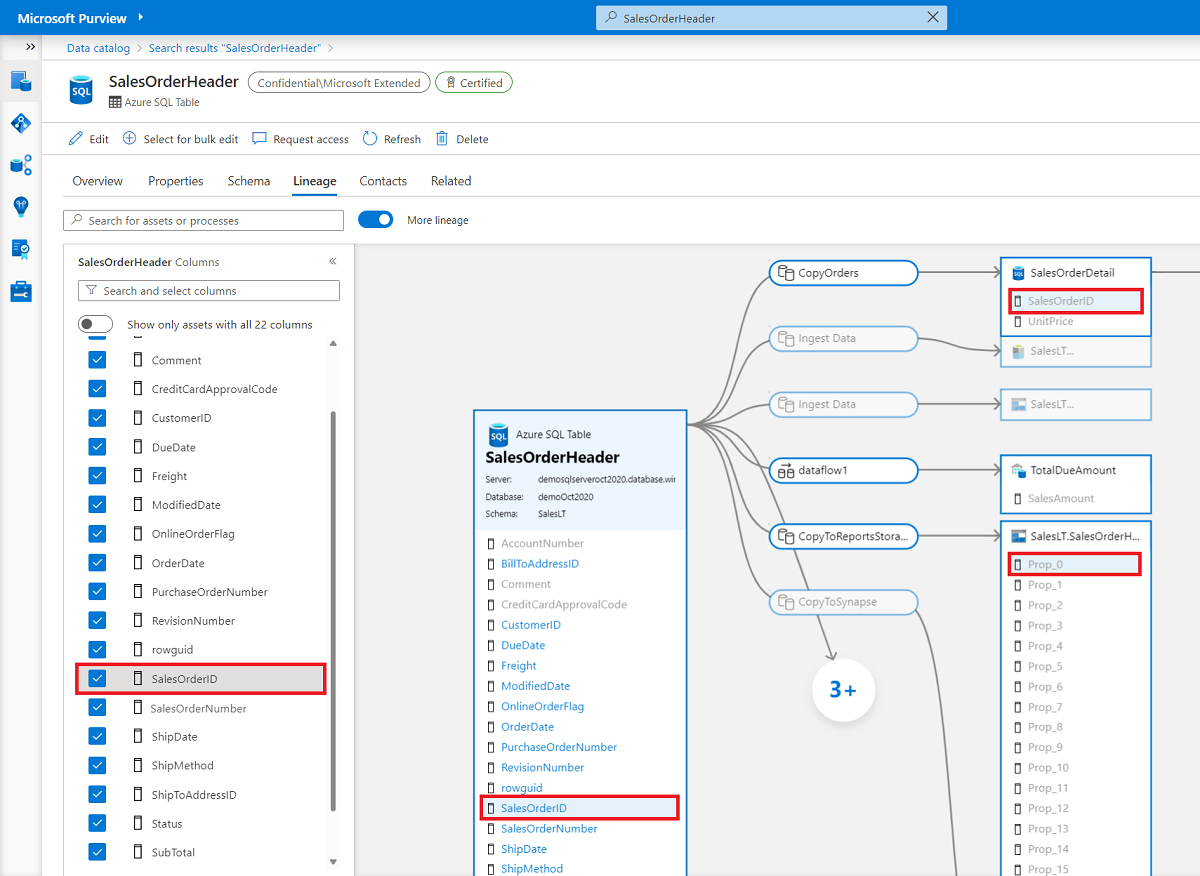
Wenn die Anzahl der Spalten größer ist als im linken Bereich angezeigt werden kann, verwenden Sie die Filteroption, um eine bestimmte Spalte anhand des Namens auszuwählen. Alternativ können Sie mit der Maus durch die Liste scrollen.

Wenn der Herkunftsbereich mehr Knoten und Kanten enthält, verwenden Sie den Filter, um Datenasset- oder Prozessknoten anhand des Namens auszuwählen. Alternativ können Sie die Maus verwenden, um das Herkunftsfenster zu schwenken.
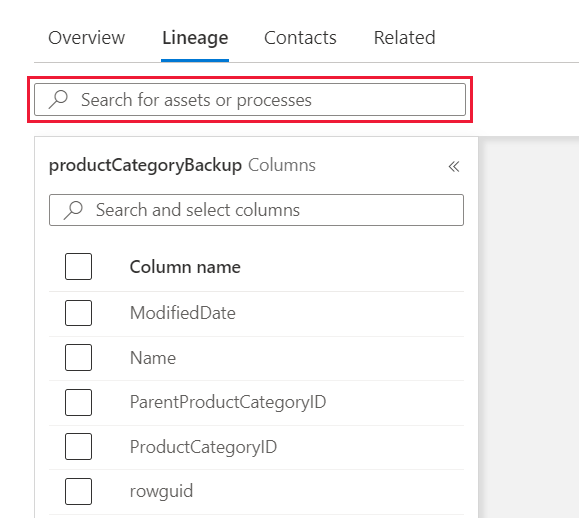
Verwenden Sie die Umschaltfläche im linken Bereich, um die Liste der Datasets im Herkunftsbereich hervorzuheben. Wenn Sie die Umschaltfläche deaktivieren, wird jedes Medienobjekt angezeigt, das mindestens eine der ausgewählten Spalten enthält. Wenn Sie die Umschaltfläche aktivieren, werden nur Datasets angezeigt, die alle Spalten enthalten.






Prozessspaltenherkunft
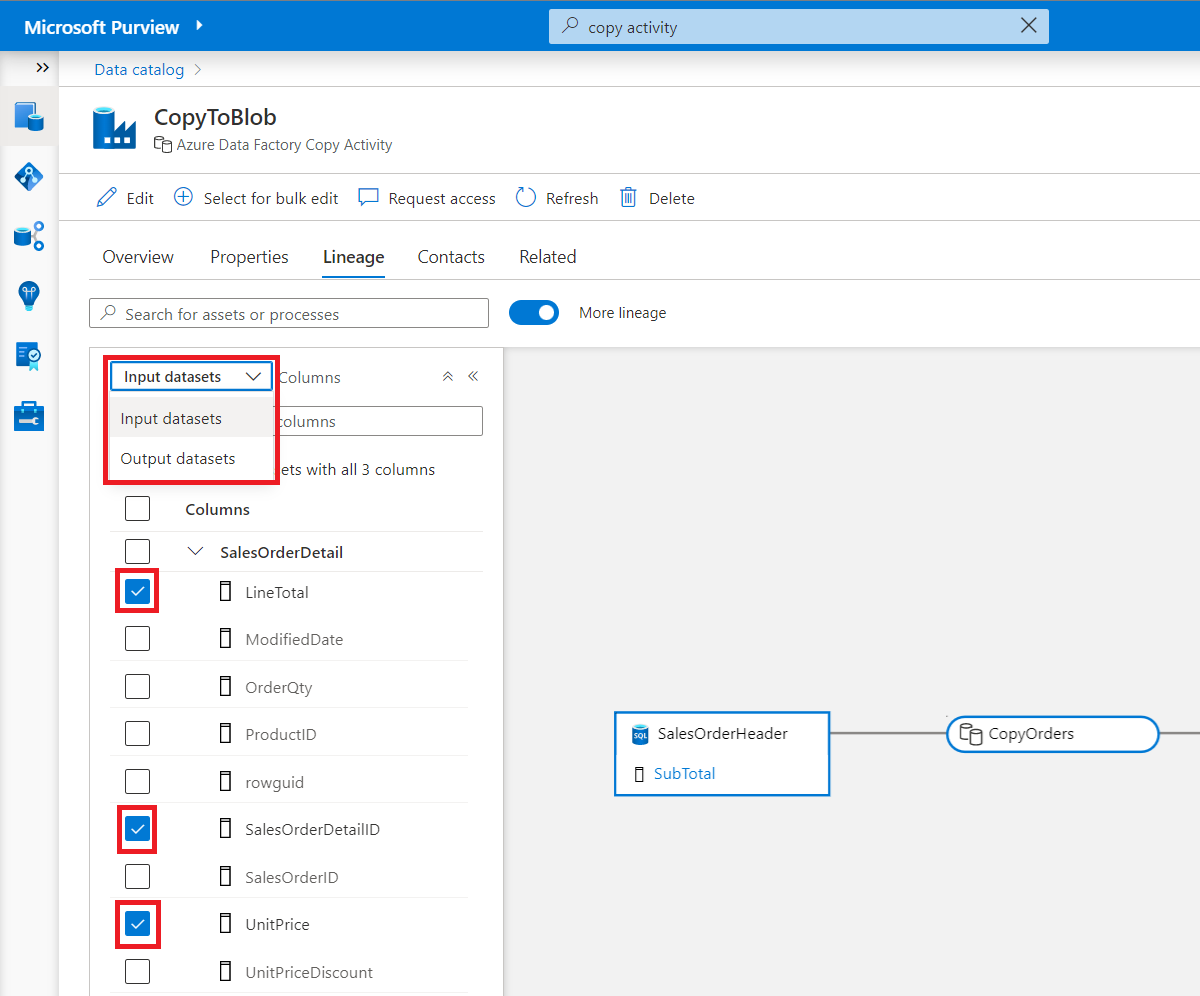
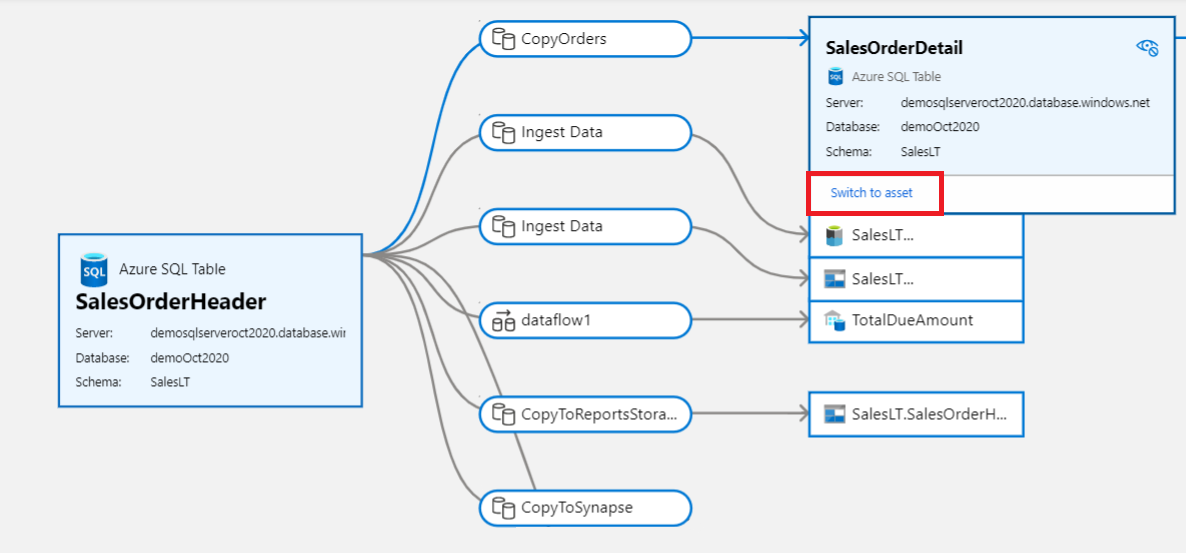
Sie können auch Datenprozesse wie Kopieraktivitäten im Katalog anzeigen. Wählen Sie beispielsweise in diesem Datenfluss die Kopieraktivität aus:

Die Kopieraktivität wird erweitert, und Sie können dann die Schaltfläche Zu Medienobjekt wechseln auswählen, die Ihnen weitere Details zum Prozess selbst enthält.

Der Datenprozess kann ein oder mehrere Eingabedatasets verwenden, um eine oder mehrere Ausgaben zu erzeugen. In Microsoft Purview ist die Herkunft auf Spaltenebene für Prozessknoten verfügbar.
Wechseln Zwischen Eingabe- und Ausgabedatasets aus einer Dropdownliste im Spaltenbereich.
Wählen Sie Spalten aus einer oder mehreren Tabellen aus, um zu sehen, wie die Herkunft vom Eingabedataset zum entsprechenden Ausgabedataset fließt.

Durchsuchen von Ressourcen in der Herkunft
Wählen Sie Zu Medienobjekt wechseln für ein beliebiges Medienobjekt aus, um die entsprechenden Metadaten in der Herkunftsansicht anzuzeigen. Dies ist eine effektive Möglichkeit, aus der Herkunftsansicht zu einer anderen Ressource im Katalog zu navigieren.
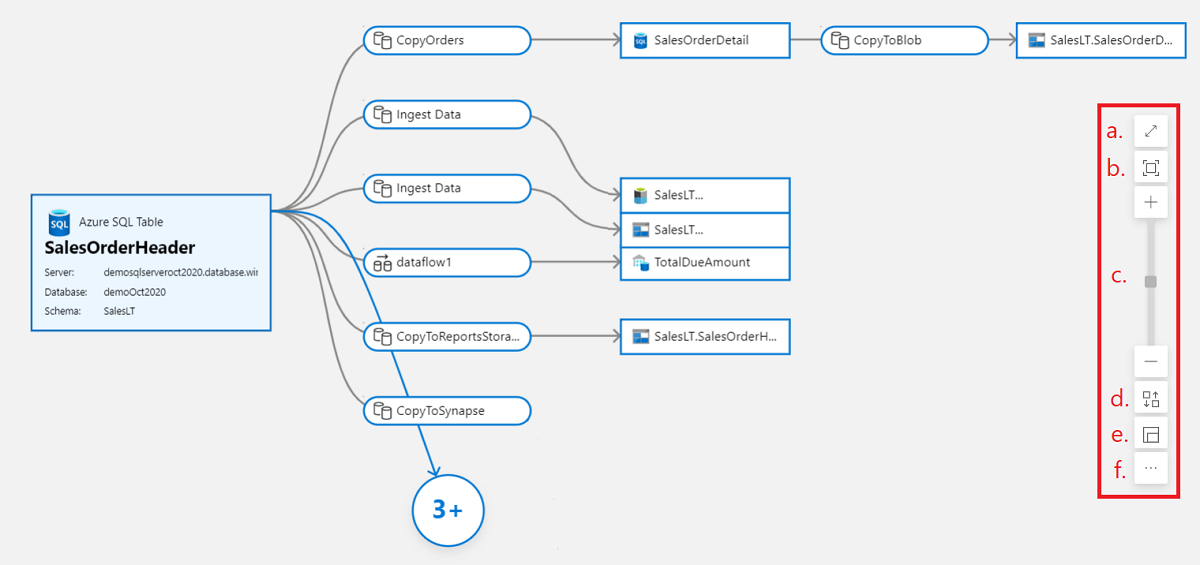
Der Herkunftsbereich könnte für beliebte Datasets komplex werden. Um Unübersichtlichkeit zu vermeiden, zeigt die Standardansicht nur fünf Herkunftsebenen für das Medienobjekt im Fokus an. Der Rest der Herkunft kann erweitert werden, indem die Blasen im Herkunftsbereich ausgewählt werden. Datenconsumer können auch die Ressourcen im Zeichenbereich ausblenden, die von keinem Interesse sind. Um die Unübersichtlichkeit weiter zu reduzieren, deaktivieren Sie die Umschaltfläche Weitere Herkunft oben im Herkunftsbereich. Diese Aktion blendet alle Blasen im Herkunftsbereich aus.
Verwenden Sie die smarten Schaltflächen im Herkunftsbereich, um eine optimale Ansicht der Herkunft zu erhalten:
- Vollbild
- Anpassen des Zooms
- Vergrößern/Verkleineren
- Automatische Ausrichtung
- Zoomvorschau
- Und weitere Optionen:
- Aktuelle Ressource zentren
- Auf Standardansicht zurücksetzen



Manuelles Erstellen einer benutzerdefinierten Herkunft oder mit REST-APIs
Eines der wichtigen Plattformfeatures von Microsoft Purview ist die Möglichkeit, die Herkunft zwischen Datasets anzuzeigen, die von Datenprozessen erstellt wurden. Systeme wie Data Factory, Data Share und Power BI erfassen die Datenherkunft beim Verschieben. In bestimmten Situationen ist die automatisch generierte Herkunft von Purview unvollständig oder fehlt für praktische Visualisierungs- und/oder Unternehmensberichte. In diesen Szenarien können Sie benutzerdefinierte Herkunftseinträge manuell im Microsoft Purview-Portal oder über Apache Atlas-Hooks und die REST-API erstellen. Ein weiterer großer Vorteil der Verwendung von REST-APIs zum Melden oder Erstellen benutzerdefinierter Herkunft ist die Überwindung oder Entschärfung der Einschränkungen der Funktionalität, die durch manuelle Herkunft verfügbar gemacht wird.
Um eine benutzerdefinierte Herkunft manuell zu erstellen, können Sie dieses Benutzerhandbuch befolgen: Manuelle Herkunftseinträge in Microsoft Purview.
Befolgen Sie zum Erstellen einer benutzerdefinierten Herkunft in Microsoft Purview mithilfe der REST-APIs dieses Benutzerhandbuchs: Microsoft Purview – Erstellen einer benutzerdefinierten Herkunft mithilfe von REST-APIs.
Tipp
In einigen Fällen bieten die REST-APIs mehr Eingabe- und Anpassungsoptionen als das manuelle Erstellen der Herkunftseinträge über das Portal.