Beheben von Datenschiefeproblemen in Azure Data Lake Analytics mithilfe von Azure Data Lake Tools für Visual Studio
Wichtig
Azure Data Lake Analytics am 29. Februar 2024 eingestellt. In dieser Ankündigung erhalten Sie weitere Informationen.
Für Datenanalysen kann Ihr organization Azure Synapse Analytics oder Microsoft Fabric verwenden.
Was ist Datenschiefe?
Kurz gesagt: Datenschiefe ist ein überrepräsentierter Wert. Stellen Sie sich vor, Sie haben 50 Steuerprüfer mit der Prüfung von Steuererklärungen beauftragt, einen Prüfer für jeden US-Bundesstaat. Der Wyoming-Prüfer, weil die Population dort klein ist, hat wenig zu tun. Der Prüfer in Kalifornien dagegen muss lange arbeiten, weil dieser Staat viele Einwohner hat.

In unserem Szenario bedeutet dies, dass die Daten nicht gleichmäßig auf alle Steuerprüfer verteilt sind, sodass einige Prüfer länger arbeiten müssen als andere. In Ihrem Arbeitsumfeld treten sicherlich häufig Situationen auf, auf die sich das Beispiel mit den Steuerprüfern übertragen lässt. In technischen Begriffen ausgedrückt: Ein Vertex erhält wesentlich mehr Daten als die anderen – daher wird dieser Vertex länger ausgeführt und letztendlich der gesamte Auftrag verlangsamt. Schlimmer noch: Der Auftrag kann möglicherweise nicht erfolgreich ausgeführt werden, da bei den Vertices beispielsweise die Laufzeit auf 5 Stunden und die Arbeitsspeichernutzung auf 6 GB beschränkt sein kann.
Lösen von Datenschiefeproblemen
Azure Data Lake Tools für Visual Studio und Visual Studio Code können sie dabei unterstützen, zu erkennen, ob bei Ihrem Auftrag ein Datenschiefeproblem vorliegt.
- Installieren von Azure Data Lake Tools für Visual Studio
- Installieren von Azure Data Lake Tools für Visual Studio Code
Wenn ein Problem vorliegt, können Sie versuchen, es mit den in diesem Abschnitt vorgestellten Lösungen zu beheben.
Lösung 1: Verbessern der Tabellenpartitionierung
Option 1: Filtern der schiefen Schlüsselwerte im Voraus
Wenn sich dies nicht auf Ihre Geschäftslogik auswirkt, können Sie die Werte mit höherer Häufigkeit im Voraus filtern. Wenn beispielsweise viele 000-000-000-000 in der Spalten-GUID vorhanden sind, möchten Sie diesen Wert möglicherweise nicht aggregieren. Vor dem Aggregieren können Sie „WHERE GUID != "000-000-000"“ schreiben, um häufig verwendete Werte herauszufiltern.
Option 2: Auswahl eines anderen Partitions- oder Verteilungsschlüssels
Wenn Sie im oben genannten Beispiel nur die Workload für die Steuerprüfung im gesamten Land bzw. in der gesamten Region überprüfen möchten, können Sie die Datenverteilung verbessern, indem Sie ID als Schlüssel auswählen. Die Auswahl eines anderen Partitions- oder Verteilungsschlüssels kann manchmal für eine gleichmäßigere Verteilung der Daten sorgen, aber Sie müssen sicherstellen, dass dies Ihre Geschäftslogik nicht beeinträchtigt. Wenn Sie z.B. die Steuersumme für jeden Bundesstaat berechnen möchten, sollten Sie als Partitionsschlüssel State auswählen. Lässt sich das Problem dadurch nicht lösen, versuchen Sie Option 3.
Option 3: Hinzufügen weiterer Partitions- oder Verteilungsschlüssel
Anstatt nur State als Partitionsschlüssel zu verwenden, können Sie auch mehrere Schlüssel für die Partitionierung angeben. Erwägen Sie beispielsweise das Hinzufügen von POSTLEITZAHL als weiteren Partitionsschlüssel, um die Größe der Datenpartitionen zu reduzieren und die Daten gleichmäßiger zu verteilen.
Option 4: Roundrobinverteilung
Wenn Sie keinen geeigneten Schlüssel für die Partitionierung und Verteilung finden können, können Sie versuchen, die Roundrobinverteilung zu verwenden. Die Roundrobinverteilung behandelt alle Zeilen gleich und fügt sie nach dem Zufallsprinzip in die entsprechenden Buckets ein. Die Daten werden gleichmäßig verteilt, aber es gehen alle Ortsinformationen verloren, wodurch die Auftragsleistung bei einigen Vorgängen sinken kann. Wenn Sie die Aggregation für den schiefen Schlüssel sowieso durchführen, bleibt das Problem mit der Datenschiefe weiterhin bestehen. Weitere Informationen zur Roundrobinverteilung finden Sie im Abschnitt U-SQL-Tabellenverteilungen unter CREATE TABLE (U-SQL): Erstellen einer Tabelle mit Schema.
Lösung 2: Verbessern des Abfrageplans
Option 1: Verwenden der CREATE STATISTICS-Anweisung
U-SQL stellt eine CREATE STATISTICS-Anweisung für Tabellen bereit. Diese Anweisung gibt dem Abfrageoptimierer weitere Informationen zu den Datenmerkmalen (z. B. Wertverteilung), die in einer Tabelle gespeichert sind. Bei den meisten Abfragen generiert der Abfrageoptimierer bereits die notwendigen Statistiken für einen hochwertigen Abfrageplan. Gelegentlich müssen Sie möglicherweise die Abfrageleistung verbessern, indem Sie mehr Statistiken mit CREATE STATISTICS erstellen oder den Abfrageentwurf ändern. Weitere Informationen finden Sie auf der Seite CREATE STATISTICS (U-SQL).
Codebeispiel:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
Hinweis
Statistische Informationen werden nicht automatisch aktualisiert. Wenn Sie die Daten in einer Tabelle aktualisieren, ohne die Statistik neu zu erstellen, sinkt möglicherweise die Abfrageleistung.
Option 2: Verwenden von SKEWFACTOR
Wenn Sie die Steuer für jeden Bundesstaat summieren möchten, müssen Sie mit GROUP BY nach Bundesstaat gruppieren. Bei diesem Vorgehen lässt sich aber das Datenschiefeproblem nicht verhindern. Sie können jedoch in Ihrer Abfrage einen Datenhinweis bereitstellen, um Datenschiefe in Schlüsseln zu identifizieren, damit der Optimierer einen Ausführungsplan für Sie erstellen kann.
In der Regel können Sie den Parameter auf 0,5 und 1 festlegen, wobei 0,5 keine große Abweichung bedeutet und eine starke Abweichung bedeutet. Der Hinweis wirkt sich auf die Optimierung des Ausführungsplans für die aktuelle Anweisung und alle nachfolgenden Anweisungen aus. Stellen Sie daher sicher, dass Sie den Hinweis vor einer möglichen Aggregation schiefer Schlüssel hinzufügen.
SKEWFACTOR (columns) = x
Gibt einen Hinweis darauf an, dass die angegebenen Spalten einen Skewfaktor x von 0 (keine Abweichung) bis 1 (starke Abweichung) aufweisen.
Codebeispiel:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
Option 3: Verwenden von ROWCOUNT
Wenn Sie bei bestimmten Joins mit schiefen Schlüsseln wissen, dass das andere verknüpfte Rowset klein ist, können Sie vor JOIN einen ROWCOUNT-Hinweis in die U-SQL-Anweisung einfügen, um den Optimierer darüber zu informieren. So kann der Optimierer eine Broadcastjoinstrategie auswählen, um die Leistung zu verbessern. Beachten Sie, dass ROWCOUNT das Problem mit der Datenschiefe nicht löst, aber es kann zusätzliche Hilfe bieten.
OPTION(ROWCOUNT = n)
Identifizieren Sie vor JOIN ein Rowset mit geringem Umfang, indem Sie eine geschätzte ganzzahlige Zeilenanzahl angeben.
Codebeispiel:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
Lösung 3: Verbessern der benutzerdefinierten Reduzierungs- und Kombinierungsfunktion
In manchen Fällen können Sie einen benutzerdefinierten Operator zur Verarbeitung komplizierter Prozesslogik schreiben. Eine gut geschriebene Reduzierungs- und Kombinierungsfunktion kann das Datenschiefeproblem in einigen Fällen minimieren.
Option 1: Verwenden einer rekursiven Reduzierungsfunktion, sofern möglich
Standardmäßig wird ein benutzerdefinierter Reducer im nicht wiederkehrenden Modus ausgeführt. Dies bedeutet, dass die Reduzierung der Arbeit für einen Schlüssel auf einen einzelnen Scheitelpunkt verteilt wird. Wenn allerdings Datenschiefe vorliegt, werden sehr große Datasets möglicherweise in einem einzigen Vertex verarbeitet und sehr lange ausgeführt.
Zur Leistungsverbesserung können Sie ein Attribut in Ihren Code einfügen, um den rekursiven Modus für die Reduzierungsfunktion festzulegen. Dann können sehr große Datasets auf mehrere Vertices verteilt und parallel verarbeitet werden, was die Ausführung des Auftrags insgesamt beschleunigt.
Um einen nicht wiederkehrenden Reducer in rekursiv zu ändern, müssen Sie sicherstellen, dass Ihr Algorithmus assoziativ ist. Beispielsweise ist die Summe assoziativ, und der Median ist nicht. Sie müssen auch sicherstellen, dass die Eingabe und Ausgabe für die Reduzierungsfunktion dem gleichen Schema folgen.
Attribut einer rekursiven Reduzierungsfunktion:
[SqlUserDefinedReducer(IsRecursive = true)]
Codebeispiel:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
Option 2: Verwenden des Kombinierungsmodus auf Zeilenebene, sofern möglich
Ähnlich wie beim ROWCOUNT-Hinweis für bestimmte Joins mit schiefen Schlüsseln versucht der Kombinierungsmodus, große Wertsätze mit schiefen Schlüsseln auf mehrere Vertices zu verteilen, sodass die Arbeit parallel ausgeführt werden kann. Der Kombiniermodus kann Probleme mit Datenschiefe nicht beheben, aber er kann zusätzliche Hilfe für riesige Wertsätze mit schiefen Schlüsseln bieten.
Standardmäßig ist der Kombinationsmodus Vollständig. Dies bedeutet, dass der linke Zeilensatz und der rechte Zeilensatz nicht getrennt werden können. Das Festlegen des Modus auf „Left“, „Right“ oder „Inner“ ermöglicht ein Join auf Zeilenebene. Das System trennt die entsprechenden Rowsets und verteilt sie auf mehrere Vertices, die parallel ausgeführt werden. Vor dem Konfigurieren des Kombinierungsmodus müssen Sie jedoch sicherstellen, dass die entsprechenden Rowsets getrennt werden können.
Das folgende Beispiel zeigt ein getrenntes Rowset links. Für jede Ausgabezeile wird eine einzelne Eingabezeile von links und potenziell alle Zeilen von rechts mit dem gleichen Schlüsselwert verwendet. Wenn Sie den Kombinierungsmodus als „Left“ festlegen, teilt das System das sehr große linke Rowset in kleinere Rowsets auf und weist diese mehreren Vertices zu.
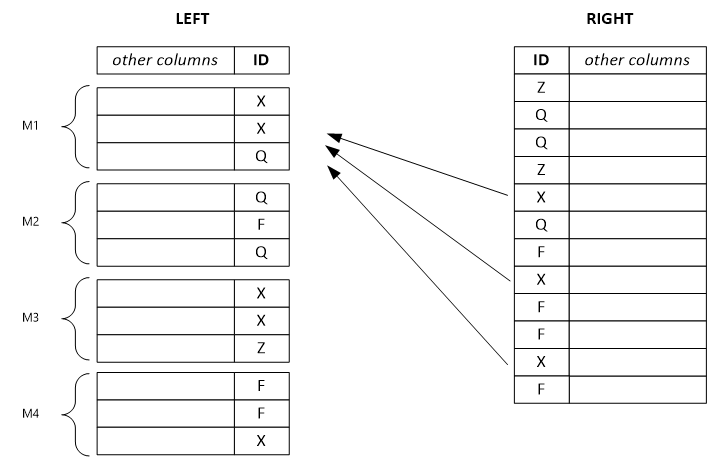
Hinweis
Wenn Sie den falschen Kombinierungsmodus festlegen, erfolgt das Kombinieren weniger effizient, und die Ergebnisse können falsch sein.
Attribute des Kombinierungsmodus:
SqlUserDefinedCombiner(Mode=CombinerMode.Full): Jede Ausgabezeile ist potenziell von allen Eingabezeilen von links und rechts mit dem gleichen Schlüsselwert abhängig.
SqlUserDefinedCombiner(Mode=CombinerMode.Left): Jede Ausgabezeile ist von einer einzelnen Eingabezeile von links (und potenziell von allen Zeilen von rechts mit dem gleichen Schlüsselwert) abhängig.
qlUserDefinedCombiner(Mode=CombinerMode.Right): Jede Ausgabezeile ist von einer einzelnen Eingabezeile von rechts (und potenziell von allen Zeilen von links mit dem gleichen Schlüsselwert) abhängig.
SqlUserDefinedCombiner(Mode=CombinerMode.Inner): Jede Ausgabezeile ist von einer einzelnen Eingabezeile von links und rechts mit dem gleichen Wert abhängig.
Codebeispiel:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}