Empfehlungen für die Reaktion auf Sicherheitsvorfälle
Gilt für die Power Platform Well-Architected Security-Checklisten-Empfehlung:
| SE:11 | Definieren und testen Sie wirksame Verfahren zur Reaktion auf Vorfälle, die ein Spektrum von Vorfällen abdecken, von lokalen Problemen bis hin zur Notfallwiederherstellung. Definieren Sie klar, welches Team oder welche Einzelperson einen Vorgang durchführt. |
|---|
In dieser Anleitung werden die Empfehlungen zur Implementierung einer Reaktion auf Sicherheitsvorfälle für eine Workload beschrieben. Wenn die Sicherheit eines Systems gefährdet ist, trägt ein systematischer Vorfallreaktionsansatz dazu bei, die Zeit zu verkürzen, die zur Identifizierung, Bewältigung und Eindämmung von Sicherheitsvorfällen erforderlich ist. Diese Vorfälle können die Vertraulichkeit, Integrität und Verfügbarkeit von Softwaresystemen und Daten gefährden.
Die meisten Unternehmen verfügen über ein zentrales Sicherheitsteam (auch als Security Operations Center [SOC] oder SecOps bezeichnet). Die Verantwortung des Sicherheitseinsatzteams besteht darin, potenzielle Angriffe schnell zu erkennen, zu priorisieren und zu selektieren. Das Team überwacht außerdem sicherheitsrelevante Telemetriedaten und untersucht Sicherheitsverletzungen.
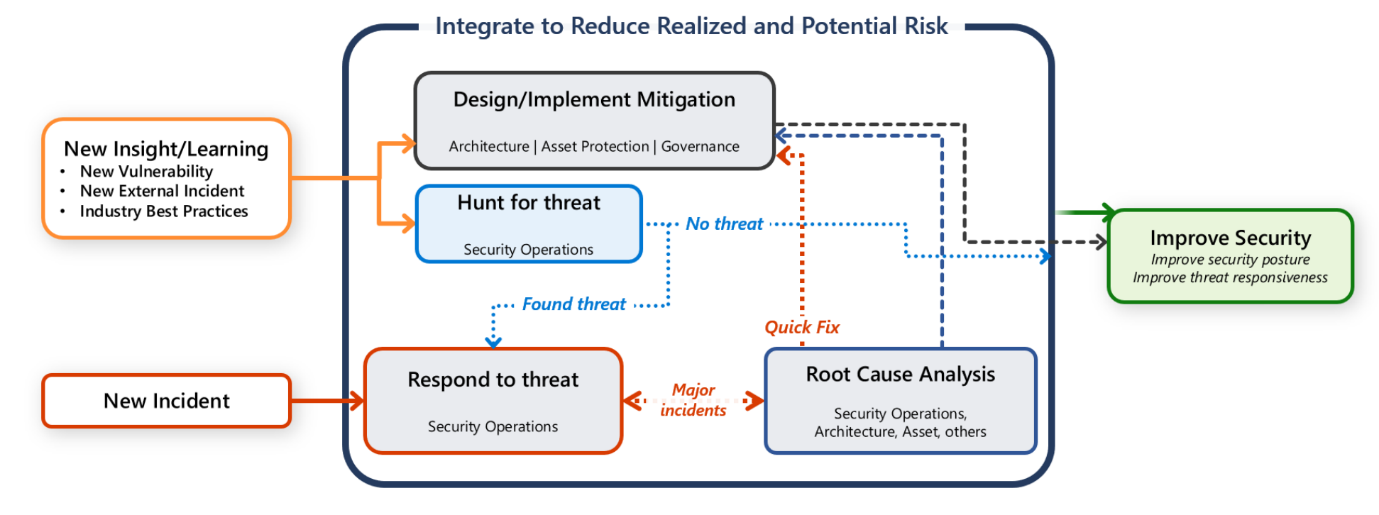
Sie tragen jedoch auch die Verantwortung, Ihre Workload zu schützen. Es ist wichtig, dass sämtliche Kommunikations-, Untersuchungs- und Suchaktivitäten eine Zusammenarbeit zwischen dem Workload-Team und dem SecOps-Team sind.
Diese Anleitung bietet Ihnen und Ihrem Workload-Team Empfehlungen, die Ihnen dabei helfen sollen, Angriffe schnell zu erkennen, einzustufen und zu untersuchen.
Definitionen
| Begriff | Definition |
|---|---|
| Alert | Eine Benachrichtigung, die Informationen zu einem Vorfall enthält. |
| Warnungsgenauigkeit | Die Genauigkeit der Daten, die eine Warnung bestimmen. Hochpräzise Warnungen enthalten den Sicherheitskontext, der zum Ergreifen sofortiger Maßnahmen erforderlich ist. Bei Warnungen mit geringer Genauigkeit fehlen Informationen oder sie enthalten Rauschen. |
| Falsch-positiv | Eine Warnung, die auf einen Vorfall hinweist, der nicht stattgefunden hat. |
| Vorfall | Ein Ereignis, das auf einen nicht autorisierten Zugriff auf ein System hinweist. |
| Reaktion auf Vorfälle | Ein Prozess, der die mit einem Vorfall verbundenen Risiken erkennt, auf sie reagiert und sie abmildert. |
| Selektierung | Ein Vorfallreaktionsvorgang, der Sicherheitsprobleme analysiert und deren Entschärfung priorisiert. |
Wichtige Designstrategien
Sie und Ihr Team führen Vorfallreaktionsvorgänge durch, wenn ein Signal oder eine Warnung auf einen potenziellen Sicherheitsvorfall hinweist. Hochpräzise Warnungen enthalten einen umfassenden Sicherheitskontext, der Analysten die Entscheidungsfindung erleichtert. Bei hochpräzisen Warnungen kommt es nur zu einer geringen Anzahl falscher Positivmeldungen. In diesem Leitfaden wird davon ausgegangen, dass ein Warnsystem Signale mit geringer Zuverlässigkeit filtert und sich auf Warnungen mit hoher Genauigkeit konzentriert, die auf einen tatsächlichen Vorfall hinweisen könnten.
Vorfallbenachrichtigung zuweisen
Sicherheitswarnungen müssen die entsprechenden Personen in Ihrem Team und Ihrer Organisation erreichen. Richten Sie in Ihrem Workload-Team einen festen Ansprechpartner für den Empfang von Vorfallbenachrichtigungen ein. Diese Benachrichtigungen sollten möglichst viele Informationen über die gefährdete Ressource und das System enthalten. Die Warnung muss die nächsten Schritte enthalten, damit Ihr Team die Maßnahmen beschleunigen kann.
Wir empfehlen Ihnen, Vorfallbenachrichtigungen und -aktionen mithilfe spezieller Tools zu protokollieren und zu verwalten, die ein Prüfprotokoll führen. Durch die Verwendung von Standardwerkzeugen können Sie Beweise sichern, die für mögliche rechtliche Ermittlungen benötigt werden könnten. Suchen Sie nach Möglichkeiten zur Implementierung einer Automatisierung, die Benachrichtigungen basierend auf den Verantwortlichkeiten der verantwortlichen Parteien senden kann. Halten Sie während eines Vorfalls eine klare Kommunikations- und Meldekette aufrecht.
Profitieren Sie von den SIEM-Lösungen (Security Information Ereignisverwaltung) und SOAR-Lösungen (Security Orchestration Automated Response), die Ihre Organisation bereitstellt. Alternativ können Sie Tools zum Vorfallmanagement beschaffen und Ihr Unternehmen dazu anregen, diese für alle Workload-Teams zu standardisieren.
Mit einem Triage-Team untersuchen
Das Teammitglied, das eine Vorfallbenachrichtigung erhält, ist dafür verantwortlich, einen Triage-Prozess einzurichten, der auf der Grundlage der verfügbaren Daten die entsprechenden Personen einbezieht. Das Triage-Team, oft auch als Brückenteam bezeichnet, muss sich auf die Art und Weise und das Verfahren der Kommunikation einigen. Erfordert dieser Vorfall asynchrone Diskussionen oder Brückenanrufe? Wie sollte das Team den Fortschritt der Untersuchungen verfolgen und kommunizieren? Wo kann das Team auf Vorfallressourcen zugreifen?
Die Reaktion auf Vorfälle ist ein entscheidender Grund dafür, die Dokumentation auf dem neuesten Stand zu halten, beispielsweise den architektonischen Aufbau des Systems, Informationen auf Komponentenebene, Datenschutz- oder Sicherheitsklassifizierung, Eigentümer und wichtige Kontaktpunkte. Wenn die Informationen ungenau oder veraltet sind, vergeudet das Brückenteam wertvolle Zeit mit dem Versuch, herauszufinden, wie das System funktioniert, wer für welchen Bereich verantwortlich ist und welche Auswirkungen das Ereignis haben könnte.
Für weitere Untersuchungen ziehen Sie die entsprechenden Personen hinzu. Sie können einen Vorfallmanager, einen Sicherheitsbeauftragten oder Workload-orientierte Leiter einbeziehen. Um die Triage fokussiert zu halten, schließen Sie Personen aus, die nicht zum Problembereich gehören. Manchmal untersuchen separate Teams den Vorfall. Es könnte ein Team geben, das das Problem zunächst untersucht und versucht, den Vorfall zu entschärfen, und ein anderes spezialisiertes Team, das eine eingehende Forensik-Untersuchung durchführt, um weitreichende Probleme zu ermitteln. Sie können die Workload-Umgebung unter Quarantäne stellen, um dem Forensikteam die Durchführung seiner Untersuchungen zu ermöglichen. In manchen Fällen kann es sein, dass dasselbe Team die gesamte Untersuchung durchführt.
In der Anfangsphase ist das Triage-Team dafür verantwortlich, den potenziellen Vektor und seine Auswirkungen auf die Vertraulichkeit, Integrität und Verfügbarkeit (auch als CIA bezeichnet) des Systems zu bestimmen.
Weisen Sie innerhalb der CIA-Kategorien einen anfänglichen Schweregrad zu, der das Ausmaß des Schadens und die Dringlichkeit der Sanierung angibt. Es ist zu erwarten, dass sich diese Ebene im Laufe der Zeit ändert, wenn in den Triage-Ebenen mehr Informationen entdeckt werden.
In der Entdeckungsphase ist es wichtig, einen sofortigen Aktionsverlauf und Kommunikationspläne festzulegen. Gibt es Änderungen am Betriebszustand des Systems? Wie kann der Angriff eingedämmt werden, um eine weitere Ausnutzung zu verhindern? Muss das Team interne oder externe Mitteilungen versenden, beispielsweise eine verantwortungsvolle Offenlegung? Berücksichtigen Sie die Erkennungs- und Reaktionszeit. Bestimmte Arten von Verstößen können gesetzlich dazu verpflichtet sein, diese innerhalb einer bestimmten Frist (oft Stunden oder Tage) einer Aufsichtsbehörde zu melden.
Wenn Sie sich zum Herunterfahren des Systems entschließen, führen die nächsten Schritte zum Disaster Recovery- (DR-)Prozess der Workload.
Wenn Sie das System nicht herunterfahren, ermitteln Sie, wie der Vorfall behoben werden kann, ohne die Funktionalität des Systems zu beeinträchtigen.
Wiederherstellen nach einem Vorfall
Behandeln Sie einen Sicherheitsvorfall wie eine Katastrophe. Wenn für die Behebung eine vollständige Wiederherstellung erforderlich ist, verwenden Sie aus Sicherheitsgründen geeignete DR-Mechanismen. Der Genesungsprozess muss die Möglichkeit einer Wiederholung verhindern. Andernfalls tritt das Problem bei der Wiederherstellung von einem beschädigten Backup erneut auf. Die erneute Bereitstellung eines Systems mit derselben Sicherheitslücke führt zum selben Vorfall. Validieren Sie Failover- und Failback-Schritte und -Prozesse.
Wenn das System weiterhin funktioniert, beurteilen Sie die Auswirkungen auf die laufenden Systemteile. Überwachen Sie das System weiterhin, um sicherzustellen, dass andere Zuverlässigkeits- und Leistungsziele erreicht oder durch die Implementierung geeigneter Degradationsprozesse angepasst werden. Gehen Sie aufgrund von Schadensbegrenzung keine Kompromisse bei der Privatsphäre ein.
Die Diagnose ist ein interaktiver Prozess, bis der Vektor und eine mögliche Lösung und Fallbackmöglichkeit identifiziert sind. Nach der Diagnose arbeitet das Team an der Behebung des Problems, wobei die erforderliche Lösung innerhalb eines akzeptablen Zeitraums ermittelt und implementiert wird.
Wiederherstellungsmetriken messen, wie lange es dauert, ein Problem zu beheben. Im Falle einer Betriebsunterbrechung kann es zu zeitlichen Engpässen bei der Sanierung kommen. Um das System zu stabilisieren, braucht es Zeit, um Fixes, Patches und Tests anzuwenden und Updates bereitzustellen. Bestimmen Sie Eindämmungsstrategien, um weiteren Schaden und die Ausbreitung des Vorfalls zu verhindern. Entwickeln Sie Beseitigungsverfahren, um die Bedrohung vollständig aus der Umgebung zu entfernen.
Kompromiss: Es gibt einen Kompromiss zwischen Zuverlässigkeitszielen und Sanierungszeiten. Während eines Vorfalls ist es wahrscheinlich, dass Sie andere nichtfunktionale oder funktionale Anforderungen nicht erfüllen. So kann es beispielsweise erforderlich sein, Teile Ihres Systems zu deaktivieren, während Sie den Vorfall untersuchen, oder sogar das gesamte System offline zu nehmen, bis Sie den Umfang des Vorfalls ermittelt haben. Die Entscheidungsträger in den Unternehmen müssen ausdrücklich festlegen, welche Ziele während des Vorfalls akzeptabel sind. Bestimmen Sie eindeutig die Person, die für diese Entscheidung verantwortlich ist.
Aus einem Vorfall lernen
Ein Vorfall deckt Lücken oder Schwachstellen in einem Entwurf oder einer Implementierung auf. Es handelt sich um eine Verbesserungsmöglichkeit, die sich aus den Erkenntnissen über technische Designaspekte, Automatisierung, Produktentwicklungsprozesse, die auch Tests umfassen, und die Effektivität des Vorfallreaktionsprozesses ergibt. Führen Sie detaillierte Vorfallprotokolle, einschließlich der ergriffenen Maßnahmen, Zeitpläne und Ergebnisse.
Wir empfehlen dringend die Durchführung strukturierter Überprüfungen nach Unfällen, z. B. Ursachenanalysen und Retrospektiven. Verfolgen und priorisieren Sie die Ergebnisse dieser Überprüfungen und berücksichtigen Sie die Verwendung Ihrer Erkenntnisse bei der Gestaltung zukünftiger Workloads.
Die Verbesserungspläne sollten auch Aktualisierungen der Sicherheitsübungen und -tests enthalten, z. B. Übungen zur Geschäftskontinuität und Notfallwiederherstellung (BCDR). Verwenden Sie eine Sicherheitsverletzung als Szenario für die Durchführung einer BCDR-Übung. Durch Übungen kann die Funktionsweise der dokumentierten Prozesse überprüft werden. Es sollte nicht mehrere Playbooks für die Reaktion auf Vorfälle geben. Verwenden Sie eine einzelne Quelle, die Sie je nach Größe des Vorfalls und je nachdem, wie weit verbreitet oder lokal die Auswirkungen sind, anpassen können. Die Übungen basieren auf hypothetischen Situationen. Führen Sie Übungen in einer Umgebung mit geringem Risiko durch und beziehen Sie die Lernphase in die Übungen ein.
Führen Sie nach dem Vorfall eine Überprüfung bzw. Post-Mortem-Analyse durch, um Schwächen im Reaktionsprozess und Bereiche mit Verbesserungsbedarf zu ermitteln. Aktualisieren Sie den Vorfallreaktionsplan (IRP) und die Sicherheitskontrollen auf der Grundlage der Lehren, die Sie aus dem Vorfall ziehen.
Die erforderliche Kommunikation senden
Implementieren Sie einen Kommunikationsplan, um Benutzer über eine Störung zu benachrichtigen und interne Stakeholder über die Behebung und Verbesserungen zu informieren. Andere Personen in Ihrer Organisation müssen über alle Änderungen an der Sicherheitsbasis der Workload benachrichtigt werden, um zukünftige Vorfälle zu verhindern.
Erstellen Sie Vorfallberichte für den internen Gebrauch und, falls erforderlich, zur Einhaltung gesetzlicher Vorschriften oder zu rechtlichen Zwecken. Nehmen Sie außerdem einen Bericht im Standardformat an (eine Dokumentvorlage mit definierten Abschnitten), den das SOC-Team für alle Vorfälle verwendet. Stellen Sie sicher, dass jedem Vorfall ein Bericht zugeordnet ist, bevor Sie die Untersuchung abschließen.
Power Platform: schnellere Durchführung
In den folgenden Abschnitten werden die Mechanismen beschrieben, die Sie im Rahmen Ihrer Reaktionsverfahren bei Sicherheitsvorfällen einsetzen können.
Microsoft Sentinel
Mit der Microsoft Sentinel-Lösung Microsoft Power Platform können Kunden verschiedene verdächtige Aktivitäten erkennen, darunter:
- Power Apps-Ausführung von nicht autorisierten geografischen Regionen
- Verdächtige Datenvernichtung durch Power Apps
- Massenlöschung von Power Apps
- Phishing-Angriffe durch Power Apps
- Power Automate-Flows-Aktivität durch ausscheidende Mitarbeiter
- Einer Umgebung hinzugefügte Microsoft Power Platform-Konnektoren
- Aktualisierung oder Entfernung von Microsoft Power Platform-Richtlinien zur Verhinderung von Datenverlust
Weitere Informationen finden Sie unter Übersicht über die Microsoft Sentinel-Lösung für Microsoft Power Platform.
Microsoft Purview-Aktivitätsprotokollierung
Power Apps, Power Automate, Konnektoren, Verhinderung von Datenverlust und administrative Power Platform-Aktivitätsprotokollierung werden über das Microsoft Purview-Compliance-Portal verfolgt und angezeigt.
Weitere Informationen finden Sie unter
- Power Apps Aktivitätsprotokollierung
- Power Automate Aktivitätsprotokollierung
- Copilot Studio Aktivitätsprotokollierung
- Power Pages Aktivitätsprotokollierung
- Power Platform Connector-Aktivitätsprotokollierung
- Daten Schadensverhütung Aktivitätsprotokollierung
- Power Platform Protokollierung der Aktivitäten von Verwaltungsaktionen
- Microsoft Dataverse und modellgesteuerte App-Aktivitätsprotokollierung
Kunden-Lockbox
Für die meisten Vorgänge, den Support und die Problembehandlung, die von Microsoft-Mitarbeitern (einschließlich Unterauftragnehmern) durchgeführt werden, ist kein Zugriff auf Kundendaten erforderlich. Mit der Power Platform-Kunden-Lockbox stellt Microsoft eine Schnittstelle zur Verfügung, über die Kunden Datenzugriffsanforderungen in den seltenen Fällen, in denen ein Zugriff auf Kundendaten erforderlich ist, überprüfen und genehmigen (oder ablehnen) können. Es wird in Fällen verwendet, in denen ein Microsoft-Techniker auf Kundendaten zugreifen muss, sei es wegen eines vom Kunden initiierten Supporttickets oder eines von Microsoft identifizierten Problems. Weitere Informationen finden Sie unter Sicherer Zugriff auf Kundendaten mit Customer Lockbox in Power Platform and Dynamics 365.
Sicherheits-Updates
Die Service-Teams führen regelmäßig die folgenden Maßnahmen durch, um die Sicherheit des Systems zu gewährleisten:
- Scans des Service, um mögliche Sicherheitsrisiken zu identifizieren
- Bewertungen des Service, um sicherzustellen, dass die Schlüsselsicherheitskontrollen effektiv funktionieren
- Auswertungen des Service, um durch das MSCR (Microsoft Security Response Center) ermittelte Sicherheitsrisiken zu prüfen (das MSCR überwacht externe Sicherheitswebsites)
Diese Teams identifizieren und verfolgen auch alle identifizierten Probleme und ergreifen bei Bedarf schnelle Maßnahmen zur Behebung von Risiken.
Wie finde ich mehr zu Sicherheitsupdate heraus?
Da die Service-Teams bestrebt sind, Behebungen von Risiken so vorzunehmen, dass keine Ausfallzeiten des Dienstes erforderlich sind, sehen Administratoren in der Regel keine Nachrichten-Center-Benachrichtigungen für Sicherheitsupdates. Wenn ein Sicherheitsupdate eine Auswirkung auf den Service erfordert, gilt es als geplante Wartung und wird mit der geschätzten Wirkungsdauer und dem Fenster, in dem die Arbeiten stattfinden, gebucht.
Weitere Informationen zur Sicherheit finden Sie unter Trust Center.
Ihr Wartungsfenster verwalten
Microsoft führt regelmäßig Updates und Wartungen durch, um die Leistung, Sicherheit und Verfügbarkeit zu gewährleisten, und neue Features und Funktionen bereitzustellen. Dieser Update-Prozess liefert wöchentlich Sicherheits- und kleinere Service-Verbesserungen, wobei jedes Update nach einem sicheren Bereitstellungsplan, der in Stationen angeordnet ist, Region für Region ausgerollt wird. Informationen über Ihr Standard-Wartungsfenster für Umgebungen finden Sie unter Richtlinien und Kommunikation für Servicevorfälle. Weitere Informationen finden Sie auch unter Wartungsfenster verwalten.
Stellen Sie sicher, dass das Azure-Registrierungsportal die Kontaktinformationen des Administrators enthält, damit Sicherheitsvorgänge direkt über einen internen Prozess benachrichtigt werden können. Weitere Informationen finden Sie unter Benachrichtigungseinstellungen aktualisieren.
Organisationsausrichtung
Das Cloud Adoption Framework für Azure bietet Anleitungen zur Planung von Vorfällen und Sicherheitsmaßnahmen. Weitere Informationen finden Sie unter Sicherheitsvorgänge.
Verwandte Informationen
- Microsoft Sentinel-Lösung für Microsoft Power Platform Übersicht
- Automatisch Vorfälle aus Microsoft-Sicherheitswarnungen erstellen
- Führen Sie mithilfe der Hunts-Funktion eine End-to-End-Bedrohungssuche durch
- Verwenden Sie Hunts, um in Microsoft Sentinel eine durchgängige proaktive Bedrohungssuche durchzuführen
- Vorfall Antwort Übersicht
Sicherheitscheckliste
Lesen Sie die vollständigen Empfehlungen.