Business Continuity und Disaster Recovery
Die Business Application Platform (BAP) von Microsoft bietet Business Continuity and Disaster Recovery (BCDR)-Funktionen für alle Produktionstyp-Umgebungen in Dynamics 365 und Power Platform SAAS-Anwendungen. In diesem Artikel werden Details und Vorgehensweisen beschrieben, die Microsoft anwendet, um sicherzustellen, dass Ihre Produktionsdaten bei regionalen Ausfällen stabil sind.
Datensicherung von Produktionsumgebungen
Microsoft ist bestrebt, die höchste Serviceverfügbarkeit für Ihre wichtigen Anwendungen und Daten zu gewährleisten. Microsoft stellt sicher, dass die Basisinfrastruktur und die Plattformdienste über seine Architektur für Geschäftskontinuität und Notfallwiederherstellung verfügbar sind, indem geografische Redundanz zugelassen wird, bei der alle Daten aus Produktionsumgebungen – mit Ausnahme von Standardumgebungen – in der gekoppelten, sekundären Region gesichert werden. Diese Datensicherungen werden als geografisch sekundäre Sicherungen bezeichnet, die während der Zeit eingerichtet werden, in der die primäre Umgebung bereitgestellt wird.
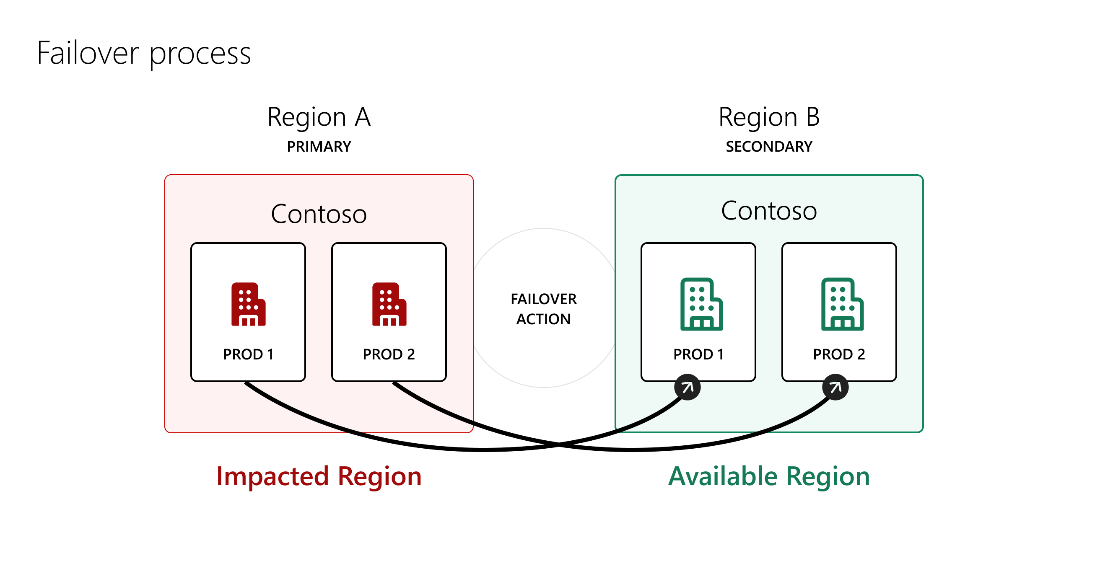
Die obige Abbildung zeigt, dass, wenn die primäre Region A während eines Ausfalls beeinträchtigt wird, Produktionsumgebungen von Region A ein Failover auf die sekundäre Region B durchführen, die fehlerfrei ist. Für andere Arten von Umgebungen wie Standardumgebungen, Testversionen, Sandboxumgebungen, Teams- oder Entwicklungsumgebungen werden keine Maßnahmen ergriffen.
Weitere Informationen zum Datenschutz in Nicht-Produktionsumgebungen finden Sie unter Umgebungen sichern und wiederherstellen.
Wie werden Sie über einen Ausfall benachrichtigt?
Der primäre Kommunikationskanal ist das Dashboard für den Dienststatus (SHD, Service Health Dashboard) innerhalb der Microsoft- und Power Platform-Admin-Center. Das Microsoft-Kommunikationsteam initiiert den Prozess, indem es erste Mitteilungen veröffentlicht, um Sie über den Ausfall zu informieren und bei Bedarf erforderliche Aktualisierungen auf dem SHD zu veröffentlichen. Weitere Informationen zum Anzeigen Ihrer Nachrichten im Admin Center finden Sie unter Homepage-Dashboard. Um besser vorbereitet zu sein, besuchen Sie die Seite Bereitschaft.
Failover- und Failback-Prozesse und Kriterien für die Geschäftskontinuität
Failover und Failback sind die beiden Hauptaufgaben, die während des Business Continuity and Disaster Recovery (BCDR)-Prozesses ausgeführt werden. Der Zweck besteht darin, die Auswirkungen einer Katastrophe auf die Verfügbarkeit und Leistung kritischer Geschäftsfunktionen und -Anwendungen zu minimieren.
Failover ist der Prozess, bei dem von Ihrem primären Produktionsstandort auf eine festgelegte geografisch sekundären Sicherung aller Systeme und Daten umgestellt wird. Nach Abschluss des Failover-Vorgangs können Sie vom geosekundären Speicherort aus auf Ihre Produktionsumgebung zugreifen.
Wichtig
Während die Finance and Operations-Apps nach einer Failover-Wartung in der sekundären Region ausgeführt werden, sind Paketbereitstellungen, Financial Reporting und Power BI-Berichte nicht verfügbar.
Unter Failback versteht man den Prozess der Wiederherstellung der Produktion an ihrem ursprünglichen Standort nach einer Katastrophe oder einer geplanten Wartungsperiode.
Als Teil des Microsoft-Standards für Geschäftskontinuität und Notfallwiederherstellung (BCDR) können Kunden sicher sein, dass jeder Onlinedienst innerhalb von Microsoft seinen BCDR-Plan jährlich überprüft, testet und aktualisiert. Der Microsoft Cloud Business Continuity and Disaster Recovery Plan Validation Report ist für Kunden auf dem Service Trust Portal verfügbar.
Bei einem unvorhergesehenen regionsweiten Ausfall, z. B. bei einer Naturkatastrophe, welche die gesamte Azure-Region betrifft, werden die folgenden Schritte und Prozesse ausgeführt.
| Verantwortlichkeit von Microsoft | Verantwortlichkeiten des Kunden |
|---|---|
| Wenn Microsoft einen Ausfall erkennt und feststellt, dass Kunden betroffen sind, sendet das Kommunikationsteam von Microsoft die erforderlichen Mitteilungen und hält das Service-Health-Dashboard mit den erforderlichen Informationen auf dem neuesten Stand. | Ohne |
| Wenn ein Ausfall auftritt, führt Microsoft ein automatisches Failover der Produktionsinstanzen in die sekundäre Region durch, wenn es bei dem Kunden zu KEINEM DATENVERLUST gekommen ist. | Ohne |
| Wenn ein Ausfall auftritt, stellt Microsoft fest, dass ein DATENVERLUST aufgetreten ist, und das Failover der Umgebung wird nicht ohne Zustimmung/Genehmigung des Kunden initiiert. | Sobald der Kunde sich des anhaltenden Ausfalls bewusst ist und die Auswirkungen sieht, liegt es in der Verantwortung des Kunden: - Um Microsoft über den Support zu kontaktieren und herauszufinden, wie hoch der Datenverlust sein würde, wenn ein Failover eingeleitet wird. - Wenn der Datenverlust in einem für ihre Organisationsstandards akzeptablen Ausmaß liegt, sollten Kunden über den Support ihre Einwilligung erteilen, damit Microsoft einen Failover einleiten kann. |
| Wenn Microsoft feststellt, dass die primäre Region wieder online und voll funktionsfähig ist, wird ein FAILBACK auf den Produktionsinstanzen durchgeführt. Während des geplanten Failback-Vorgangs kommt es nicht zu Datenverlusten. Bei Benutzenden kann es jedoch in diesem Zeitfenster zu kurzen Unterbrechungen oder Verbindungsabbrüchen kommen. | Ohne |
Notfallwiederherstellung im Self-Service (Vorschauversion)
[Dieser Abschnitt ist Teil der Dokumentation zur Vorabversion und kann geändert werden.]
Wichtig
- Dies ist eine Vorschauversion.
- Funktionen in der Vorschauversion sind nicht für den Produktionseinsatz gedacht und können eine eingeschränkte Funktionalität aufweisen. Diese Funktionen unterliegen den ergänzenden Nutzungsbedingungen und stehen vor dem offiziellen Release zur Verfügung, damit die Kundschaft frühen Zugriff darauf erhalten und Feedback geben können.
Die Notfallwiederherstellung ist eine Power Platform Premium-Infrastrukturfunktion, mit der Kunden im Self-Service ein Umgebungsfailover zwischen Regionen initiieren können. Kunden haben in ihrem Mandanten in der Regel mehrere Umgebungen unterschiedlichen Typs erstellt. Diese Funktion ist insbesondere für Produktionsumgebungen verfügbar und kann für jede Umgebung aktiviert werden. Derzeit ist diese Funktion für Finanz- und Betriebsproduktionsumgebungen nicht verfügbar.
Die Notfallwiederherstellung im Self-Service aktivieren
Sie müssen die Notfallwiederherstellung im Self-Service für eine Umgebung aktivieren, bevor Sie die Funktion verwenden können. Dies ist eine einmalige Aktion, die Ressourcen bereitstellt und den Prozess der Replizierung von Daten zwischen dem primären und dem sekundären Speicherort startet. Dies kann bis zu 48 Stunden dauern. Fachkräfte für die Administration werden benachrichtigt, wenn der Vorgang abgeschlossen ist.
Das Aktivieren der Notfallwiederherstellung in einer Umgebung wirkt sich nicht auf die Umgebung oder die darin enthaltenen Daten aus.
Gehen Sie wie folgt vor, um die Notfallwiederherstellung zu aktivieren.
- Gehen Sie zur Liste der Umgebungen im Power Platform Admin Center.
- Wählen Sie die Produktionsumgebung aus, in der Sie die Notfallwiederherstellung im Self-Service aktivieren möchten.
- Wählen Sie Notfallwiederherstellung in der Befehlsleiste oben auf der Seite aus. Der Bereich Notfallwiederherstellung wird angezeigt.
- Stellen Sie den Umschalter auf Aktiviert um.
- Wählen Sie Speichern.
- Die Umgebung wird kurz auf der Seite Details bearbeiten platziert.
- Die Seite Umgebungsdetails wird erscheint und zeigt an, dass der Prozess zum Aktivieren der Funktion begonnen hat.
Es gibt zwei Gründe, die Sie eventuell zwingen, dieses Feature zu verwenden:
- Notfallwiederherstellungsübung.
- Notfallreaktion im Falle eines größeren regionalen Ausfalls.
Notfallwiederherstellungsübungen
Möglicherweise hat Ihr Unternehmen in Ihren internen Plänen für die Geschäftskontinuität Notfallwiederherstellungsübungen als Anforderung dokumentiert. Manche Branchen und Unternehmen sind auch aufgrund staatlicher Vorschriften verpflichtet, ihre BCDR-Kapazitäten zu überprüfen. In diesen Fällen führen Sie vielleicht eine Notfallwiederherstellungsübung für eine Umgebung aus. Mit einer Notfallwiederherstellungsübung können Sie eine Notfallwiederherstellung im Self-Service durchführen, ohne Daten zu verlieren. Die Failover-Aktion kann etwas länger dauern, da alle verbleibenden Daten in die sekundäre Region repliziert werden.
Es wird empfohlen, Übungen an einer Kopie einer Produktionsumgebung durchzuführen, da es dabei zu Downtime kommt, die mehrere Minuten dauern kann. Sie können z. B. eine Produktionsumgebung in eine Umgebung vom Typ Sandbox kopieren und dann den Typ von Sandbox in Produktion ändern.
Notfallreaktions-Failover
Diese Option wird voraussichtlich in einem Notfall gewählt, d. h. wenn es in der primären Region zu einem Ausfall gekommen ist und nicht auf Umgebungen oder Daten zugegriffen werden kann. Wenn Sie diese Option auswählen, fällt die Umgebung aus, ohne außer den Daten, die vor dem Ausfall repliziert wurden, noch weitere zu kopieren.
Wenn Sie eine Notfallreaktion durchführen, sehen Sie die Menge des Datenverlusts in der Zeit, die Sie mit Ihrem Recovery Point Objective (RPO) vergleichen können. Wenn Sie feststellen, dass dies akzeptabel ist, können Sie fortfahren. Die Umgebung wird im Ausführungszustand ausgeführt, bis die Notfallwiederherstellung abgeschlossen ist und die Umgebung in der sekundären Region wieder im Normalbetrieb läuft.
Rückkehr zur primären Region
Nachdem Sie Ihre Übung abgeschlossen haben oder ein Ausfall behoben wurde, sollten Sie die Umgebung wieder in die primäre Region wechseln. Eine Umgebung läuft in der gekoppelten Region eventuell mit begrenzten Ressourcen. Während dieses Vorgangs gibt es keinen Datenverlust.
Notfallwiederherstellungsstatus der Umgebung
Fachkräfte für die Administration können den aktuellen Notfallwiederherstellungsstatus und den Speicherort einer Umgebung auf der Seite Umgebungsdetails ermitteln. Fachkräfte für die Administration können auch in der Befehlsleiste Notfallwiederherstellung auswählen, um den Bereich Notfallwiederherstellung zu öffnen.
Sie können die Wartezeit bei der Datenreplikation jederzeit überprüfen, indem Sie Notfallwiederherstellung und dann Notfallreaktion als Grund für die Notfallwiederherstellung auswählen. Dadurch wird ein Bestätigungsdialogfeld geöffnet, der die letzte Replikationszeit zwischen Regionen für diese Umgebung enthält. Sie können Abbrechen auswählen, wenn Sie nur den potenziellen Datenverlust im Falle eines Failover-Vorgangs überprüfen wollten. Beachten Sie, dass der Zeitpunkt der letzten Synchronisierung zu verschiedenen Zeiten immer unterschiedlich ist, da die Daten kontinuierlich repliziert werden.
Ihren Geschäftskontinuitätsplan dokumentieren
Sie sollten Sie unbedingt Notfallwiederherstellungsübungen oder, falls Sie sich dafür entscheiden, eine Notfallreaktion durchführen, bevor eine echte Katastrophe eintritt, damit Sie alle Schritte dokumentieren können, die für alle für Power Platform externen Integrationspunkte erforderlich sind. In diesem Fall ist Ihr Unternehmen besser auf die Wiederherstellung vorbereitet, wenn es zu einer echten Katastrophe kommt.
Hinweis zur Vorschauversion
Während der Vorschauversion fallen für dieses Feature keine Kosten an. Kunden können es nicht deaktivieren. Wenn das Feature allgemein verfügbar wird, können Vorschaukunden die Funktionalität beibehalten oder sie durch Microsoft deaktivieren lassen. Es wirkt sich nicht auf den Speicherort oder die Funktionen Ihrer primären Umgebung aus, wenn Sie sich entscheiden, während der allgemeinen Verfügbarkeit kein Upgrade durchzuführen.