Übersicht über Modelltypen in Microsoft Syntex
Gilt für: ✓ Alle benutzerdefinierten Modelle | ✓ Alle vordefinierten Modelle
Das Verständnis Ihrer Inhalte in Microsoft Syntex beginnt mit Dokumentverarbeitungsmodellen. Mit Dokumentverarbeitungsmodellen können Sie Dokumente identifizieren und klassifizieren, die in SharePoint-Dokumentbibliotheken hochgeladen werden, und dann die benötigten Informationen aus jeder Datei extrahieren.
Wenn es auf eine SharePoint-Dokumentbibliothek angewendet wird, ist das Modell einem Inhaltstyp zugeordnet und verfügt über Spalten zum Speichern der extrahierten Informationen. Der von Ihnen erstellte Inhaltstyp wird im SharePoint-Inhaltstypkatalog gespeichert. Sie können auch vorhandene Inhaltstypen verwenden, um deren Schema zu verwenden.
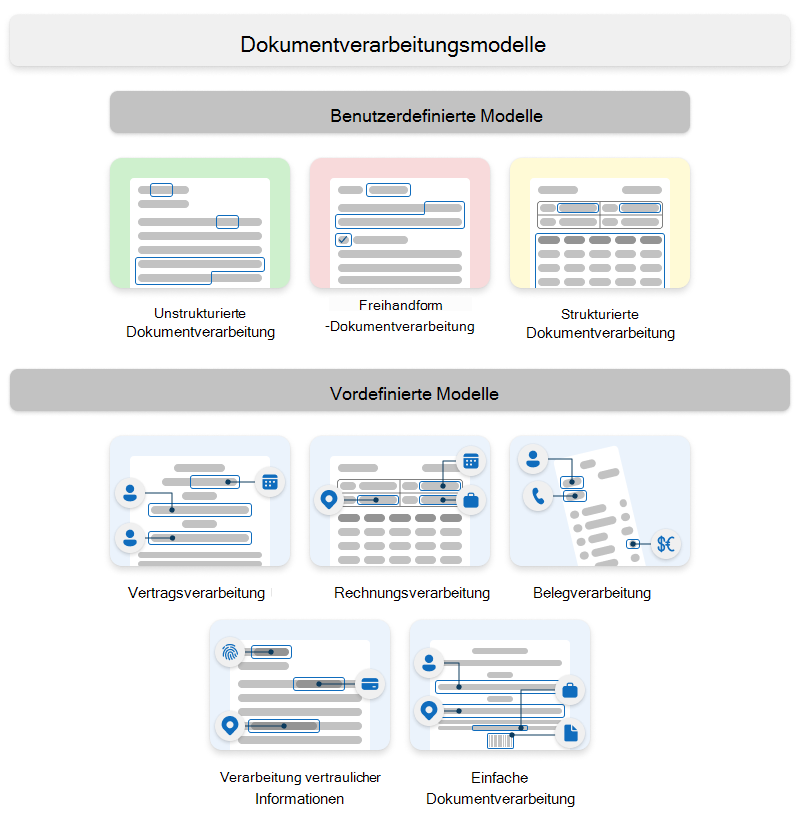
Syntex verwendet benutzerdefinierte Modelle und vordefinierte Modelle.
Modelle können entweder Unternehmensmodelle sein, die in einem Inhaltscenter erstellt werden, oder lokale Modelle, die auf Ihrer lokalen SharePoint-Website erstellt werden.
Benutzerdefinierte Modelle
Der Typ des benutzerdefinierten Modells, das Sie auswählen, hängt von den verwendeten Dateitypen, dem Format und der Struktur der Dateien sowie davon ab, wo Sie das Modell anwenden möchten.
Benutzerdefinierte Modelle umfassen:
- Unstrukturierte Dokumentverarbeitung
- Freihandform-Dokumentverarbeitung
- Strukturierte Dokumentverarbeitung
Informationen zu den parallelen Unterschieden in benutzerdefinierten Modellen finden Sie unter Vergleichen von benutzerdefinierten Modellen.
Unstrukturierte Dokumentverarbeitung
Verwenden Sie das unstrukturierte Dokumentverarbeitungsmodell, um Dokumente automatisch zu klassifizieren und Informationen daraus zu extrahieren. Es eignet sich am besten für unstrukturierte Dokumente, z. B. Briefe oder Verträge. Diese Dokumente müssen Text enthalten, der anhand von Phrasen oder Mustern erkannt werden kann. Der erkannte Text bestimmt sowohl den Dateityp (seine Klassifizierung) als auch das, was extrahiert werden soll (die Extraktoren).
So könnte beispielsweise ein unstrukturiertes Dokument ein Vertragsverlängerungsdokument sein, das auf unterschiedliche Weise verfasst sein kann. Im Textkörper jedes Vertragsverlängerungsdokuments sind jedoch konsistent Informationen vorhanden, z. B. die Textzeichenfolge "Service start date of" gefolgt von einem tatsächlichen Datum.
Dieser Modelltyp unterstützt die breiteste Palette von Dateitypen und mehr als 40 Sprachen.
Wenn Sie ein unstrukturiertes Dokumentverarbeitungsmodell erstellen, verwenden Sie die Option Einzelklassenmodell .
Weitere Informationen finden Sie unter Übersicht über die unstrukturierte Dokumentverarbeitung.
Freihandform-Dokumentverarbeitung
Verwenden Sie das Freihandform-Dokumentverarbeitungsmodell, um automatisch Informationen aus unstrukturierten und Freihandformdokumenten wie Briefen und Verträgen zu extrahieren, in denen die Informationen an einer beliebigen Stelle im Dokument angezeigt werden können.
Freihandform-Dokumentverarbeitungsmodelle verwenden Microsoft Power Apps AI Builder , um Modelle in Syntex zu erstellen und zu trainieren.
Hinweis
Das Freihandform-Dokumentverarbeitungsmodell ist in einigen Regionen noch nicht verfügbar. Weitere Informationen finden Sie unter Featureverfügbarkeit nach Region.
Da Ihr organization Briefe und Dokumente in großen Mengen aus verschiedenen Quellen wie Post, Fax und E-Mail empfängt, kann die Bearbeitung dieser Dokumente und die manuelle Eingabe in eine Datenbank sehr viel Zeit in Anspruch nehmen. Durch die Verwendung von KI zum Extrahieren von Text und anderen Informationen aus diesen Dokumenten automatisiert dieses Modell diesen Prozess.
Dieser Modelltyp ist die beste Option für Dokumente in PDF- oder Bilddateien, wenn Sie keine automatische Klassifizierung des Dokumenttyps erfordern und mehr als 40 Sprachen unterstützen.
Wenn Sie ein Freihandform-Dokumentverarbeitungsmodell erstellen, verwenden Sie die Option Freihandform-Extraktionsmodell .
Weitere Informationen finden Sie unter Übersicht über die strukturierte Und Freihanddokumentverarbeitung.
Strukturierte Dokumentverarbeitung
Verwenden Sie das strukturierte Dokumentverarbeitungsmodell, um Feld- und Tabellenwerte automatisch zu identifizieren. Dies eignet sich am besten für strukturierte oder teilweise strukturierte Dokumente, z. B. Formulare und Rechnungen.
Strukturierte Dokumentverarbeitungsmodelle verwenden die Microsoft Power Apps AI Builder-Dokumentverarbeitung (früher als Formularverarbeitung bezeichnet), um Modelle in Syntex zu erstellen und zu trainieren.
Dieser Modelltyp unterstützt die breiteste Palette von Sprachen und wird trainiert, um das Layout Ihres Formulars anhand von Beispieldokumenten zu verstehen, und dann lernt, nach den Daten zu suchen, die Sie aus ähnlichen Speicherorten extrahieren müssen. Forms haben in der Regel ein strukturiertes Layout, bei dem sich Entitäten am gleichen Ort befinden (z. B. eine Sozialversicherungsnummer auf einem Steuerformular).
Wenn Sie ein strukturiertes Dokumentverarbeitungsmodell erstellen, verwenden Sie die Option Strukturiertes Extraktionsmodell .
Weitere Informationen finden Sie unter Übersicht über die strukturierte Und Freihanddokumentverarbeitung.
Vordefinierte Modelle
Wenn Sie kein benutzerdefiniertes Modell erstellen müssen, können Sie ein vordefiniertes Dokumentverarbeitungsmodell verwenden, das bereits für bestimmte strukturierte Dokumente trainiert wurde.
Zu den vordefinierten Modellen gehören:
- Vertragsverarbeitung
- Rechnungsverarbeitung
- Belegverarbeitung
- Verarbeitung vertraulicher Informationen
- Einfache Dokumentverarbeitung
Vordefinierte Modelle sind vortrainiert, um Dokumente und die strukturierten Informationen in den Dokumenten zu erkennen. Anstatt ein neues benutzerdefiniertes Modell von Grund auf neu erstellen zu müssen, können Sie ein vorhandenes vortrainiertes Modell durchlaufen, um bestimmte Felder hinzuzufügen, die den Anforderungen Ihrer organization entsprechen.
Vertragsverarbeitung
Das vordefinierte Vertragsverarbeitungsmodell analysiert und extrahiert wichtige Informationen aus Vertragsdokumenten. Die API analysiert Verträge in verschiedenen Formaten und extrahiert wichtige Vertragsinformationen wie Den Namen des Kunden oder der Partei, die Rechnungsadresse, die Zuständigkeit und das Ablaufdatum.
Weitere Informationen zu Vertragsverarbeitungsmodellen finden Sie unter Verwenden eines vordefinierten Modells zum Extrahieren von Informationen aus Verträgen.
Rechnungsverarbeitung
Das vordefinierte Rechnungsverarbeitungsmodell analysiert und extrahiert wichtige Informationen aus Verkaufsrechnungen. Die API analysiert Rechnungen in verschiedenen Formaten und extrahiert wichtige Rechnungsinformationen wie Kundenname, Rechnungsadresse, Fälligkeitsdatum und fälligen Betrag.
Weitere Informationen zu Rechnungsverarbeitungsmodellen finden Sie unter Verwenden eines vordefinierten Modells zum Extrahieren von Informationen aus Rechnungen.
Belegverarbeitung
Das vordefinierte Belegverarbeitungsmodell analysiert und extrahiert wichtige Informationen aus Verkaufsbelegen. Die API analysiert gedruckte und handschriftliche Belege und extrahiert wichtige Beleginformationen wie Händlername, Telefonnummer des Händlers, Transaktionsdatum, Steuern und Transaktionssumme.
Weitere Informationen zu Belegverarbeitungsmodellen finden Sie unter Verwenden eines vordefinierten Modells zum Extrahieren von Informationen aus Belegen.
Verarbeitung vertraulicher Informationen
Das vordefinierte Modell zur Verarbeitung vertraulicher Informationen analysiert, erkennt und extrahiert wichtige Informationen aus Dokumenten. Die API analysiert Verträge in verschiedenen Formaten und extrahiert wichtige vertrauliche Informationen wie Sozialversicherungsnummern, Finanzkontonummern, Führerscheinnummern und andere persönliche Informationen.
Weitere Informationen zu Modellen zur Verarbeitung vertraulicher Informationen finden Sie unter Verwenden eines vordefinierten Modells zum Erkennen vertraulicher Informationen aus Dokumenten.
Einfache Dokumentverarbeitung
Das vordefinierte einfache Dokumentverarbeitungsmodell bietet eine flexible, vortrainierte Lösung zum Extrahieren von Schlüssel-Wert-Paaren, Auswahlmarkierungen und benannten Entitäten aus grundlegenden strukturierten Dokumenten. Im Gegensatz zu anderen vordefinierten Modellen mit festen Schemas kann dieses Modell Schlüssel identifizieren, die anderen möglicherweise fehlen, was eine wertvolle Alternative zur benutzerdefinierten Modellbezeichnung und zum Training bietet. Dieses Modell unterstützt auch Barcodes und Spracherkennung.
Weitere Informationen zu einfachen Dokumentverarbeitungsmodellen finden Sie unter Verwenden eines vordefinierten Modells zum Erkennen vertraulicher Informationen aus Dokumenten.