Verwenden eines vordefinierten Modells zum Extrahieren von Informationen aus einfachen Dokumenten in Microsoft Syntex
Das einfache Dokumentverarbeitungsmodell bietet eine flexible, vortrainierte Lösung zum Extrahieren von Informationen aus grundlegenden strukturierten Dokumenten, einschließlich Informationen wie:
Schlüssel-Wert-Paare – Stellen Sie sich diese wie Bezeichnungen und die entsprechenden Informationen vor, z. B. "Name: Adele Vance".
Auswahlmarkierungen : Dies sind Kontrollkästchen oder andere Markierungen, die Auswahlmöglichkeiten oder Auswahlmöglichkeiten in einem Dokument angeben.
Benannte Entitäten : Dies sind bestimmte Elemente wie Namen von Personen, Orten oder Organisationen, die im Text eines Dokuments erwähnt werden.
Barcodes: Dies sind maschinenlesbare Darstellungen von Daten, die zu Nachverfolgungs- oder Identifizierungszwecken in einem Dokument verwendet werden können.
Im Gegensatz zu anderen vordefinierten Modellen mit festen Schemas kann dieses Modell Schlüssel identifizieren, die anderen möglicherweise fehlen, was eine wertvolle Alternative zur benutzerdefinierten Modellbezeichnung und zum Training bietet. Dieses Modell unterstützt auch Barcodes und Spracherkennung.
Dokumenttypen
Die einfache Dokumentverarbeitung eignet sich am besten für die Arten von Dokumenten, die strukturierte Informationen enthalten, z. B.:
Forms: Diese weisen häufig eindeutige Felder und Bezeichnungen auf, sodass Schlüssel-Wert-Paare leichter extrahiert werden können.
Rechnungen : Enthalten in der Regel konsistente Layouts mit Tabellen und Schlüssel-Wert-Paaren.
Belege : Ähnlich wie Rechnungen verfügen sie über strukturierte Daten, die leicht extrahiert werden können.
Verträge : Enthalten klar definierte Abschnitte und Klauseln, die effektiv analysiert werden können.
Kontoauszüge : Fügen Sie Tabellen und strukturierte Daten ein, die sich ideal für die Extraktion eignen.
Diese Dokumente profitieren von den OCR-Funktionen (Optical Character Recognition) und Deep Learning-Prozessen, die zum Extrahieren von Schlüssel-Wert-Paaren, Auswahlmarkierungen, Tabellen und benannten Entitäten verwendet werden.
Hinweis
Derzeit ist dieses Modell für .pdf- und Bilddateitypen und in mehr als 100 Sprachen verfügbar. Weitere unterstützte Dateitypen werden in zukünftigen Versionen hinzugefügt.
Führen Sie die folgenden Schritte aus, um ein einfaches Dokumentverarbeitungsmodell zu verwenden:
- Schritt 1: Erstellen des Modells
- Schritt 2: Hochladen einer Beispieldatei zur Analyse
- Schritt 3: Auswählen von Extraktoren für Ihr Modell
- Schritt 4: Anwenden des Modells
Schritt 1: Erstellen des Modells
Befolgen Sie die Anweisungen unter Erstellen eines Modells in Syntex , um ein einfaches Dokumentverarbeitungsmodell zu erstellen. Fahren Sie dann mit den folgenden Schritten fort, um Ihr Modell abzuschließen.
Schritt 2: Hochladen einer Beispieldatei zur Analyse
Wählen Sie auf der Seite Modelle im Abschnitt Zu analysierende Datei hinzufügen die Option Datei hinzufügen aus.
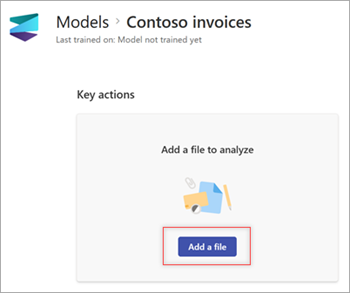
Wählen Sie auf der Seite Dateien zum Analysieren des Modells die Option Hinzufügen aus, um die datei zu finden, die Sie verwenden möchten.
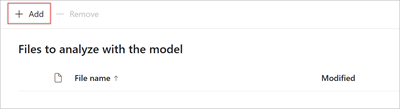
Wählen Sie auf der Seite Datei aus der Bibliothek für Trainingsdateien hinzufügen die Datei und dann Hinzufügen aus.
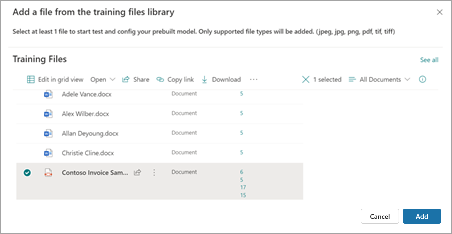
Wählen Sie auf der Seite Dateien zum Analysieren des Modells die Option Weiter aus.
Schritt 3: Auswählen von Extraktoren für Ihr Modell
Auf der Detailseite des Extraktors sehen Sie den Dokumentbereich auf der rechten Seite und den Bereich Extraktoren auf der linken Seite. Im Bereich Extraktoren wird die Liste der Extraktoren angezeigt, die im Dokument identifiziert wurden.
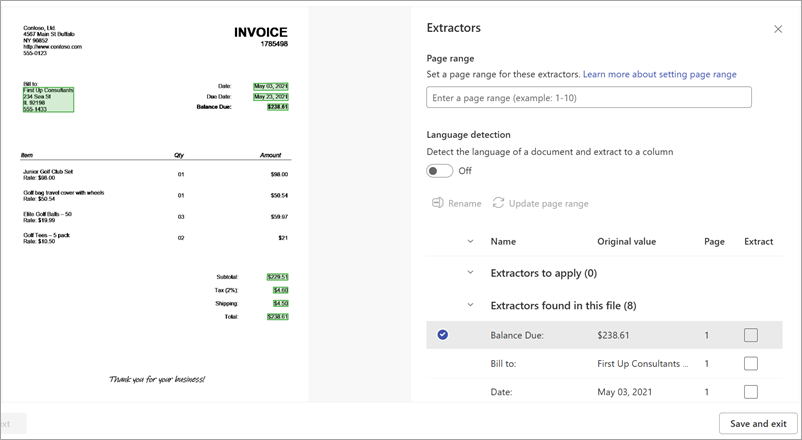
Die Entitätsfelder, die im Dokumentbereich grün hervorgehoben sind, sind die Elemente, die vom Modell bei der Analyse der Datei erkannt wurden. Wenn Sie eine zu extrahierende Entität auswählen, ändert sich das hervorgehobene Feld in Blau. Wenn Sie sich später entscheiden, die Entität nicht einzuschließen, ändert sich das hervorgehobene Feld in Grau. Die Hervorhebungen erleichtern die Anzeige des aktuellen Zustands der von Ihnen ausgewählten Extraktoren.
Tipp
Um die Entitätsfelder zu vergrößern oder zu verkleinern, verwenden Sie das Mausrad oder die Zoomsteuerelemente am unteren Rand des Dokumentbereichs.
Auswählen einer Extraktorentität
Je nach Wunsch können Sie einen Extraktor entweder im Dokumentbereich oder im Bereich Extraktoren auswählen.
- Um einen Extraktor aus dem Dokumentbereich auszuwählen, wählen Sie das Entitätsfeld aus.
- Um einen Extraktor aus dem Bereich Extraktoren auszuwählen, aktivieren Sie in der Spalte Extrahieren das entsprechende Kontrollkästchen rechts neben dem Entitätsnamen.
Wenn Sie einen Extraktor auswählen, wird das Feld Extraktor auswählen? im Dokumentbereich angezeigt. Im Feld werden der Schlüsselname (der für den Extraktor generierte Name), der erkannte Wert (der Wert dieses Felds im Dokument), der Spaltentyp und die Option zum Auswählen der Entität als Extraktor angezeigt.
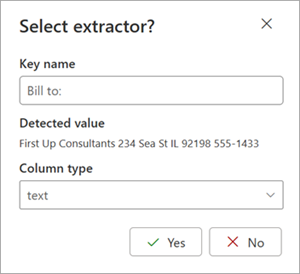
Der Schlüsselname wird als Spaltenname verwendet, wenn das Modell auf eine SharePoint-Bibliothek angewendet wird. Sie können den Schlüsselnamen bei Bedarf in einen aussagekräftigeren Namen ändern. Der Spaltentyp zeigt, wie die Informationen in einer Bibliothek angezeigt werden. Sie können den Spaltentyp ändern, um anzuzeigen, wie die Informationen angezeigt werden sollen. Wenn das Modell auf eine Bibliothek angewendet wird, können Sie mithilfe der Spaltenformatierung angeben, wie es im Dokument aussehen soll.
Wählen Sie weiterhin andere Extraktoren aus, die Sie verwenden möchten. Sie können auch weitere Dateien hinzufügen, die für diese Modellkonfiguration analysiert werden sollen.
Umbenennen eines Extraktors
Es gibt drei Möglichkeiten, einen Extraktor umzubenennen:
Wählen Sie im Dokumentbereich der Seite mit den Extraktordetails das Entitätsfeld aus. Geben Sie im Feld Extraktor auswählen? im Feld Schlüsselname einen neuen Namen für den Extraktor ein.
Wählen Sie auf der Seite Mit den Extraktordetails im Bereich Extraktoren den Extraktor aus, den Sie umbenennen möchten, und wählen Sie dann Umbenennen aus.
Wählen Sie auf der Startseite des Modells im Abschnitt Extraktoren den Extraktor aus, den Sie umbenennen möchten, und wählen Sie dann Umbenennen aus.
Festlegen eines Seitenbereichs für die Verarbeitung
Bei diesem Modell können Sie angeben, dass anstelle der gesamten Datei ein Seitenbereich für eine Datei verarbeitet werden soll. Wählen Sie im Bereich Extraktoren im Abschnitt Seitenbereich die Seite aus, die verarbeitet werden soll. Standardmäßig ist die Einstellung Seitenbereich leer. Wenn kein Seitenbereich angegeben wird, wird das gesamte Dokument verarbeitet. Weitere Informationen finden Sie unter Festlegen eines Seitenbereichs zum Extrahieren von Informationen aus bestimmten Seiten.
Erkennen der Sprache eines Dokuments
Bei diesem Modell können Sie die Sprache eines Dokuments erkennen und in eine Spalte extrahieren. Schalten Sie im Bereich Extraktoren im Abschnitt Spracherkennung um, um die Spracherkennung zu aktivieren. Es zeigt Ihnen den ISO-Code der erkannten Sprache an.

Sie können die Spracherkennung auch im Bereich Modelleinstellungen für das Modell aktivieren oder deaktivieren.
Schritt 4: Anwenden des Modells
Um Änderungen zu speichern und zur Startseite des Modells zurückzukehren, wählen Sie im Bereich Extraktoren die Option Speichern und beenden aus.
Wenn Sie bereit sind, das Modell auf eine Bibliothek anzuwenden, wählen Sie im Dokumentbereich Weiter aus. Wählen Sie im Bereich Zu Bibliothek hinzufügen die Bibliothek aus, der Sie das Modell hinzufügen möchten, und wählen Sie dann Hinzufügen aus.
Informationen zu Dateitypen, Sprachen, optischer Zeichenerkennung und anderen Überlegungen zu diesem vordefinierten Modell finden Sie unter Anforderungen und Einschränkungen für die vordefinierte Dokumentverarbeitung in SharePoint.