Python-Plug-In
Gilt für: ✅Microsoft Fabric✅Azure Data Explorer
Das Python-Plug-In führt eine benutzerdefinierte Funktion (User-Defined Function, UDF) mithilfe eines Python-Skripts aus. Das Python-Skript ruft tabellarische Daten als Eingabe ab und erzeugt eine tabellarische Ausgabe. Die Laufzeit des Plug-Ins wird in Sandkasten gehostet, die auf den Knoten des Clusters ausgeführt werden.
Syntax
T evaluate | [hint.distribution = (singleper_node | )] [hint.remote = (autolocal | )] python(output_schema, Skript [ script_parameters] [,, external_artifacts][, spill_to_disk])
Erfahren Sie mehr über Syntaxkonventionen.
Parameter
| Name | Type | Erforderlich | Beschreibung |
|---|---|---|---|
| output_schema | string |
✔️ | Ein type Literal, das das Ausgabeschema der tabellarischen Daten definiert, die vom Python-Code zurückgegeben wird. Das Format lautet: typeof(ColumnName: ColumnType[, ...]). Beispiel: typeof(col1:string, col2:long). Verwenden Sie die folgende Syntax, um das Eingabeschema zu erweitern: typeof(*, col1:string, col2:long) |
| Skript | string |
✔️ | Das zu ausführende gültige Python-Skript. Informationen zum Generieren von mehrzeiligen Zeichenfolgen finden Sie in den Verwendungstipps. |
| script_parameters | dynamic |
Ein Eigenschaftenbehälter mit Namenwertpaaren, die als reserviertes kargs Wörterbuch an das Python-Skript übergeben werden sollen. Weitere Informationen finden Sie unter Reservierte Python-Variablen. |
|
| hint.distribution | string |
Ein Hinweis auf die Ausführung des Plug-Ins, die über mehrere Clusterknoten verteilt werden sollen. Der Standardwert ist single. single bedeutet, dass eine einzelne Instanz des Skripts über die gesamten Abfragedaten ausgeführt wird. per_node bedeutet: Wenn die Abfrage vor der Verteilung des Python-Blocks ausgeführt wird, wird eine Instanz des Skripts auf jedem Knoten auf den darin enthaltenen Daten ausgeführt. |
|
| hint.remote | string |
Dieser Hinweis ist nur für clusterübergreifende Abfragen relevant. Der Standardwert ist auto. auto bedeutet, dass der Server automatisch entscheidet, in welchem Cluster der Python-Code ausgeführt wird. Festlegen des Werts, um die Ausführung des Python-Codes im lokalen Cluster zu local erzwingen. Verwenden Sie es, falls das Python-Plug-In auf dem Remotecluster deaktiviert ist. |
|
| external_artifacts | dynamic |
Ein Eigenschaftenbehälter mit Namen und URL-Paaren für Artefakte, auf die über den Cloudspeicher zugegriffen werden kann. Weitere Informationen finden Sie unter "Verwenden externer Artefakte". | |
| spill_to_disk | bool |
Gibt eine alternative Methode zum Serialisieren der Eingabetabelle in die Python-Sandbox an. Zum Serialisieren großer Tabellen legen sie fest, um true die Serialisierung zu beschleunigen und die Sandbox-Speicherauslastung erheblich zu verringern. Der Standardwert ist true. |
Reservierte Python-Variablen
Die folgenden Variablen sind für die Interaktion zwischen Kusto-Abfragesprache und dem Python-Code reserviert.
df: Die tabellarischen Eingabedaten (die Werte obenT) alspandasDataFrame.kargs: Der Wert des arguments script_parameters als Python-Wörterbuch.result: Einpandasvom Python-Skript erstelltes DataFrame, dessen Wert zu den tabellarischen Daten wird, die an den Kusto-Abfrageoperator gesendet werden, der auf das Plug-In folgt.
Aktivieren des Plug-Ins
Das Plug-In ist standardmäßig deaktiviert. Bevor Sie beginnen, überprüfen Sie die Liste der Voraussetzungen. Informationen zum Aktivieren des Plug-Ins und Auswählen der Version des Python-Bilds finden Sie unter Aktivieren von Spracherweiterungen auf Ihrem Cluster.
Python-Sandkastenbild
Informationen zum Ändern der Version des Python-Images in ein anderes verwaltetes Image oder ein benutzerdefiniertes Image finden Sie unter Ändern des Python-Spracherweiterungsbilds auf Ihrem Cluster.
Eine Liste der Pakete für die verschiedenen Python-Bilder finden Sie in der Python-Paketreferenz.
Hinweis
- Standardmäßig importiert das Plug-In numpy als np und pandas als pd. Optional können Sie andere Module nach Bedarf importieren.
- Einige Pakete sind möglicherweise nicht mit den Einschränkungen kompatibel, die von der Sandbox erzwungen werden, in der das Plug-In ausgeführt wird.
Verwenden der Erfassung von Abfrage- und Aktualisierungsrichtlinien
- Verwenden Sie das Plug-In in Abfragen, die folgendes sind:
- Definiert als Teil einer Aktualisierungsrichtlinie, deren Quelltabelle bei Verwendung von Nicht-Streaming-Aufnahme aufgenommen wird.
- Führen Sie als Teil eines Befehls aus, der aus einer Abfrage einnimmt, z
.set-or-append. B. .
- Sie können das Plug-In nicht in einer Abfrage verwenden, die als Teil einer Updaterichtlinie definiert ist, deren Quelltabelle mithilfe der Streamingaufnahme aufgenommen wird.
Beispiele
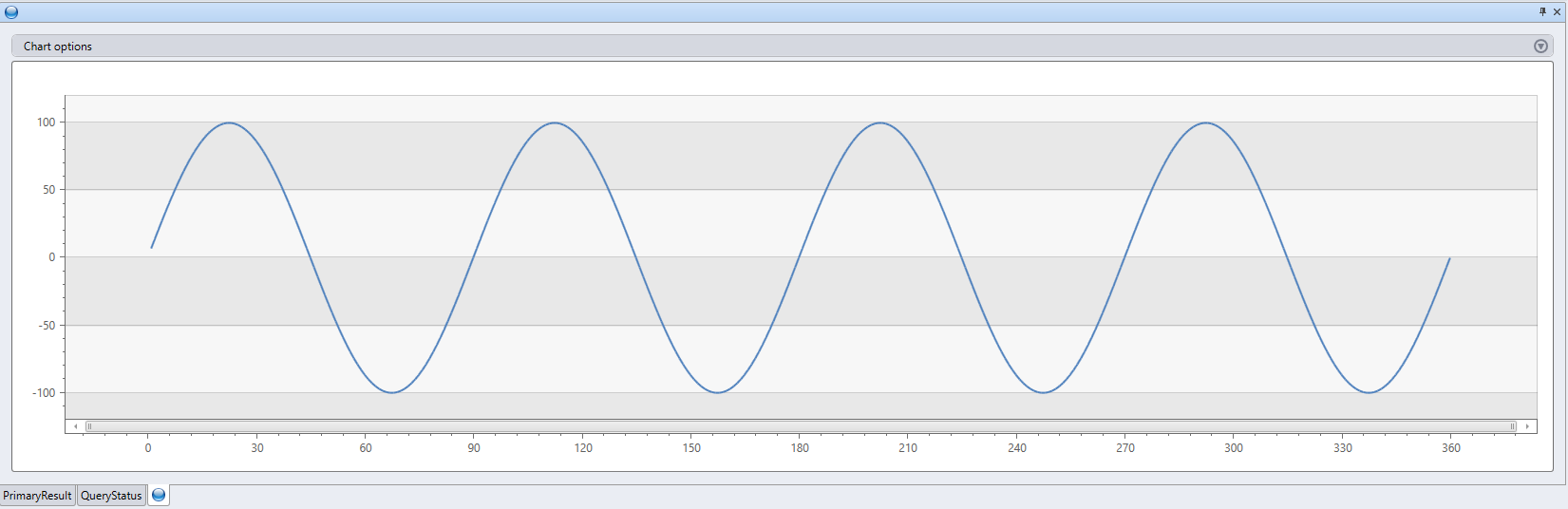
range x from 1 to 360 step 1
| evaluate python(
//
typeof(*, fx:double), // Output schema: append a new fx column to original table
```
result = df
n = df.shape[0]
g = kargs["gain"]
f = kargs["cycles"]
result["fx"] = g * np.sin(df["x"]/n*2*np.pi*f)
```
, bag_pack('gain', 100, 'cycles', 4) // dictionary of parameters
)
| render linechart
print "This is an example for using 'external_artifacts'"
| evaluate python(
typeof(File:string, Size:string), ```if 1:
import os
result = pd.DataFrame(columns=['File','Size'])
sizes = []
path = '.\\\\Temp'
files = os.listdir(path)
result['File']=files
for file in files:
sizes.append(os.path.getsize(path + '\\\\' + file))
result['Size'] = sizes
```,
external_artifacts =
dynamic({"this_is_my_first_file":"https://kustoscriptsamples.blob.core.windows.net/samples/R/sample_script.r",
"this_is_a_script":"https://kustoscriptsamples.blob.core.windows.net/samples/python/sample_script.py"})
)
| Datei | Größe |
|---|---|
| this_is_a_script | 120 |
| this_is_my_first_file | 105 |
Leistungstipps
- Verringern Sie das Eingabe-Dataset des Plug-Ins auf die erforderliche Mindestmenge (Spalten/Zeilen).
- Verwenden Sie Filter für das Quelldatenset, wenn möglich, mit der Abfragesprache von Kusto.
- Wenn Sie eine Berechnung für eine Teilmenge der Quellspalten ausführen möchten, projizieren Sie nur diese Spalten, bevor Sie das Plug-In aufrufen.
- Verwenden Sie
hint.distribution = per_node, wann immer die Logik in Ihrem Skript verteilt werden kann.- Sie können auch den Partitionsoperator für die Partitionierung des Eingabedatensets verwenden.
- Verwenden Sie kustos Abfragesprache, wenn möglich, um die Logik Ihres Python-Skripts zu implementieren.
Verwendungstipps
Um mehrzeilige Zeichenfolgen zu generieren, die das Python-Skript in Ihrem Abfrage-Editor enthalten, kopieren Sie Ihr Python-Skript aus Ihrem bevorzugten Python-Editor (Jupyter, Visual Studio Code, PyCharm usw.), fügen Sie sie in Ihren Abfrage-Editor ein, und schließen Sie dann das vollständige Skript zwischen Zeilen ein, die drei aufeinander folgende Backticks enthalten. Zum Beispiel:
```
python code
```Verwenden Sie den
externaldataOperator , um den Inhalt eines Skripts abzurufen, das Sie an einem externen Speicherort gespeichert haben, z. B. Azure Blob Storage.
Beispiel
let script =
externaldata(script:string)
[h'https://kustoscriptsamples.blob.core.windows.net/samples/python/sample_script.py']
with(format = raw);
range x from 1 to 360 step 1
| evaluate python(
typeof(*, fx:double),
toscalar(script),
bag_pack('gain', 100, 'cycles', 4))
| render linechart
Verwenden externer Artefakte
Externe Artefakte aus dem Cloudspeicher können für das Skript zur Verfügung gestellt und zur Laufzeit verwendet werden.
Die URLs, auf die von der Eigenschaft für externe Artefakte verwiesen wird, müssen folgendes sein:
- In der Popuprichtlinie des Clusters enthalten.
- Geben Sie an einem öffentlich verfügbaren Speicherort die erforderlichen Anmeldeinformationen an, wie im Speicher Verbindungszeichenfolge erläutert.
Hinweis
Beim Authentifizieren externer Artefakte mit verwalteten Identitäten muss die SandboxArtifacts Verwendung auf der Clusterebene für verwaltete Identitätsrichtlinie definiert werden.
Die Artefakte werden für das Skript zur Nutzung aus einem lokalen temporären Verzeichnis zur Verfügung gestellt. .\Temp Die im Eigenschaftenbehälter angegebenen Namen werden als lokale Dateinamen verwendet. Vgl. Beispiele.
Informationen zum Verweisen auf externe Pakete finden Sie unter Installieren von Paketen für das Python-Plug-In.
Aktualisieren des Caches für externe Artefakte
Externe Artefaktdateien, die in Abfragen verwendet werden, werden in Ihrem Cluster zwischengespeichert. Wenn Sie Aktualisierungen ihrer Dateien im Cloudspeicher vornehmen und eine sofortige Synchronisierung mit Ihrem Cluster erfordern, können Sie den Befehl ".clear cluster cache external-artifacts" verwenden. Dieser Befehl löscht die zwischengespeicherten Dateien und stellt sicher, dass nachfolgende Abfragen mit der neuesten Version der Artefakte ausgeführt werden.
Installieren von Paketen für das Python-Plug-In
In den meisten Anwendungsfällen möchten Sie möglicherweise ein benutzerdefiniertes Bild erstellen.
Möglicherweise möchten Sie Pakete selbst installieren, aus den folgenden Gründen:
- Sie sind nicht berechtigt, ein benutzerdefiniertes Bild zu erstellen.
- Das Paket ist privat.
- Sie möchten eine Ad-hoc-Paketinstallation zum Testen erstellen und nicht den Aufwand für das Erstellen eines benutzerdefinierten Images wünschen.
Installieren Sie Pakete wie folgt:
Voraussetzungen
Erstellen Sie einen BLOB-Container, um die Pakete zu hosten, vorzugsweise an derselben Stelle wie Ihr Cluster. Angenommen,
https://artifactswestus.blob.core.windows.net/pythonIhr Cluster befindet sich in West-USA.Ändern Sie die Popuprichtlinie des Clusters, um den Zugriff auf diesen Standort zuzulassen.
Für diese Änderung sind AllDatabasesAdmin-Berechtigungen erforderlich.
Führen Sie beispielsweise den folgenden Befehl aus, um den Zugriff auf ein Blob zu aktivieren, in
https://artifactswestus.blob.core.windows.net/pythondem sich ein Blob befindet:
.alter-merge cluster policy callout @'[ { "CalloutType": "sandbox_artifacts", "CalloutUriRegex": "artifactswestus\\.blob\\.core\\.windows\\.net/python/","CanCall": true } ]'
Installieren von Paketen
Laden Sie für öffentliche Pakete in PyPi oder anderen Kanälen das Paket und dessen Abhängigkeiten herunter.
- Führen Sie in einem cmd-Fenster in Ihrer lokalen Windows Python-Umgebung Folgendes aus:
pip wheel [-w download-dir] package-name.Erstellen Sie eine ZIP-Datei, die das erforderliche Paket und die zugehörigen Abhängigkeiten enthält.
- Bei privaten Paketen zippen Sie den Ordner des Pakets und die Ordner ihrer Abhängigkeiten.
- Zippen Sie für öffentliche Pakete die Dateien, die im vorherigen Schritt heruntergeladen wurden.
Hinweis
- Stellen Sie sicher, dass Sie das Paket herunterladen, das mit dem Python-Modul und der Plattform der Sandbox-Runtime kompatibel ist (derzeit 3.6.5 unter Windows)
- Stellen Sie sicher, dass Sie die
.whlDateien selbst und nicht den übergeordneten Ordner komprimieren. - Sie können Dateien für Pakete überspringen
.whl, die bereits mit derselben Version im Basis-Sandkastenimage vorhanden sind.
Laden Sie die gezippte Datei in einen BLOB im Artefaktspeicherort hoch (aus Schritt 1).
Rufen Sie das
pythonPlug-In auf.- Geben Sie den
external_artifactsParameter mit einem Eigenschaftenbehälter namens an, und verweisen Sie auf die ZIP-Datei (die URL des Blobs, einschließlich eines SAS-Tokens). - Importieren
ZipackageSie in Ihrem Inline-Python-Code diesandbox_utilsMethode mit dem Namen der ZIP-Datei, und rufen Sie sieinstall()auf.
- Geben Sie den
Beispiel
Installieren Sie das Faker-Paket , das gefälschte Daten generiert.
range ID from 1 to 3 step 1
| extend Name=''
| evaluate python(typeof(*), ```if 1:
from sandbox_utils import Zipackage
Zipackage.install("Faker.zip")
from faker import Faker
fake = Faker()
result = df
for i in range(df.shape[0]):
result.loc[i, "Name"] = fake.name()
```,
external_artifacts=bag_pack('faker.zip', 'https://artifacts.blob.core.windows.net/Faker.zip?*** REPLACE WITH YOUR SAS TOKEN ***'))
| Kennung | Name |
|---|---|
| 1 | Gary Tapia |
| 2 | Emma Evans |
| 3 | Ashley Bowen |
Zugehöriger Inhalt
Weitere Beispiele für UDF-Funktionen, die das Python-Plug-In verwenden, finden Sie in der Funktionsbibliothek.
Das Python-Plug-In führt eine benutzerdefinierte Funktion (User-Defined Function, UDF) mithilfe eines Python-Skripts aus. Das Python-Skript ruft tabellarische Daten als Eingabe ab und erzeugt eine tabellarische Ausgabe.
Syntax
T | evaluate [ (singleper_node | )] [hint.remotehint.distribution = = (autolocal | )] python(output_schema , Skript [, script_parameters] [, spill_to_disk])
Erfahren Sie mehr über Syntaxkonventionen.
Parameter
| Name | Type | Erforderlich | Beschreibung |
|---|---|---|---|
| output_schema | string |
✔️ | Ein type Literal, das das Ausgabeschema der tabellarischen Daten definiert, die vom Python-Code zurückgegeben wird. Das Format lautet: typeof(ColumnName: ColumnType[, ...]). Beispiel: typeof(col1:string, col2:long). Verwenden Sie die folgende Syntax, um das Eingabeschema zu erweitern: typeof(*, col1:string, col2:long) |
| Skript | string |
✔️ | Das zu ausführende gültige Python-Skript. Informationen zum Generieren von mehrzeiligen Zeichenfolgen finden Sie in den Verwendungstipps. |
| script_parameters | dynamic |
Ein Eigenschaftenbehälter mit Namenwertpaaren, die als reserviertes kargs Wörterbuch an das Python-Skript übergeben werden sollen. Weitere Informationen finden Sie unter Reservierte Python-Variablen. |
|
| hint.distribution | string |
Ein Hinweis auf die Ausführung des Plug-Ins, die über mehrere Clusterknoten verteilt werden sollen. Der Standardwert ist single. single bedeutet, dass eine einzelne Instanz des Skripts über die gesamten Abfragedaten ausgeführt wird. per_node bedeutet: Wenn die Abfrage vor der Verteilung des Python-Blocks ausgeführt wird, wird eine Instanz des Skripts auf jedem Knoten auf den darin enthaltenen Daten ausgeführt. |
|
| hint.remote | string |
Dieser Hinweis ist nur für clusterübergreifende Abfragen relevant. Der Standardwert ist auto. auto bedeutet, dass der Server automatisch entscheidet, in welchem Cluster der Python-Code ausgeführt wird. Festlegen des Werts, um die Ausführung des Python-Codes im lokalen Cluster zu local erzwingen. Verwenden Sie es, falls das Python-Plug-In auf dem Remotecluster deaktiviert ist. |
|
| spill_to_disk | bool |
Gibt eine alternative Methode zum Serialisieren der Eingabetabelle in die Python-Sandbox an. Zum Serialisieren großer Tabellen legen sie fest, um true die Serialisierung zu beschleunigen und die Sandbox-Speicherauslastung erheblich zu verringern. Der Standardwert ist true. |
Reservierte Python-Variablen
Die folgenden Variablen sind für die Interaktion zwischen Kusto-Abfragesprache und dem Python-Code reserviert.
df: Die tabellarischen Eingabedaten (die Werte obenT) alspandasDataFrame.kargs: Der Wert des arguments script_parameters als Python-Wörterbuch.result: Einpandasvom Python-Skript erstelltes DataFrame, dessen Wert zu den tabellarischen Daten wird, die an den Kusto-Abfrageoperator gesendet werden, der auf das Plug-In folgt.
Aktivieren des Plug-Ins
Das Plug-In ist standardmäßig deaktiviert. Bevor Sie beginnen, aktivieren Sie das Python-Plug-In in Ihrer KQL-Datenbank.
Python-Sandkastenbild
Eine Liste der Pakete für die verschiedenen Python-Bilder finden Sie in der Python-Paketreferenz.
Hinweis
- Standardmäßig importiert das Plug-In numpy als np und pandas als pd. Optional können Sie andere Module nach Bedarf importieren.
- Einige Pakete sind möglicherweise nicht mit den Einschränkungen kompatibel, die von der Sandbox erzwungen werden, in der das Plug-In ausgeführt wird.
Verwenden der Erfassung von Abfrage- und Aktualisierungsrichtlinien
- Verwenden Sie das Plug-In in Abfragen, die folgendes sind:
- Definiert als Teil einer Aktualisierungsrichtlinie, deren Quelltabelle bei Verwendung von Nicht-Streaming-Aufnahme aufgenommen wird.
- Führen Sie als Teil eines Befehls aus, der aus einer Abfrage einnimmt, z
.set-or-append. B. .
- Sie können das Plug-In nicht in einer Abfrage verwenden, die als Teil einer Updaterichtlinie definiert ist, deren Quelltabelle mithilfe der Streamingaufnahme aufgenommen wird.
Beispiele
range x from 1 to 360 step 1
| evaluate python(
//
typeof(*, fx:double), // Output schema: append a new fx column to original table
```
result = df
n = df.shape[0]
g = kargs["gain"]
f = kargs["cycles"]
result["fx"] = g * np.sin(df["x"]/n*2*np.pi*f)
```
, bag_pack('gain', 100, 'cycles', 4) // dictionary of parameters
)
| render linechart
Leistungstipps
- Verringern Sie das Eingabe-Dataset des Plug-Ins auf die erforderliche Mindestmenge (Spalten/Zeilen).
- Verwenden Sie Filter für das Quelldatenset, wenn möglich, mit der Abfragesprache von Kusto.
- Wenn Sie eine Berechnung für eine Teilmenge der Quellspalten ausführen möchten, projizieren Sie nur diese Spalten, bevor Sie das Plug-In aufrufen.
- Verwenden Sie
hint.distribution = per_node, wann immer die Logik in Ihrem Skript verteilt werden kann.- Sie können auch den Partitionsoperator für die Partitionierung des Eingabedatensets verwenden.
- Verwenden Sie kustos Abfragesprache, wenn möglich, um die Logik Ihres Python-Skripts zu implementieren.
Verwendungstipps
Um mehrzeilige Zeichenfolgen zu generieren, die das Python-Skript in Ihrem Abfrage-Editor enthalten, kopieren Sie Ihr Python-Skript aus Ihrem bevorzugten Python-Editor (Jupyter, Visual Studio Code, PyCharm usw.), fügen Sie sie in Ihren Abfrage-Editor ein, und schließen Sie dann das vollständige Skript zwischen Zeilen ein, die drei aufeinander folgende Backticks enthalten. Zum Beispiel:
```
python code
```Verwenden Sie den
externaldataOperator , um den Inhalt eines Skripts abzurufen, das Sie an einem externen Speicherort gespeichert haben, z. B. Azure Blob Storage.
Beispiel
let script =
externaldata(script:string)
[h'https://kustoscriptsamples.blob.core.windows.net/samples/python/sample_script.py']
with(format = raw);
range x from 1 to 360 step 1
| evaluate python(
typeof(*, fx:double),
toscalar(script),
bag_pack('gain', 100, 'cycles', 4))
| render linechart
Zugehöriger Inhalt
Weitere Beispiele für UDF-Funktionen, die das Python-Plug-In verwenden, finden Sie in der Funktionsbibliothek.