Durchsuchen von Daten in Ihrer gespiegelten Datenbank mit Notebooks
Sie können die aus Ihrer gespiegelten Datenbank replizierten Daten mit Spark-Abfragen in Notebooks untersuchen.
Notebooks sind ein leistungsstarkes Code-Element, mit dem Sie Apache Spark-Jobs und Experimente zum maschinellen Lernen mit Ihren Daten entwickeln können. Sie können Notizbücher im Fabric Lakehouse verwenden, um Ihre gespiegelten Tabellen zu erkunden.
Voraussetzungen
- Führen Sie das Lernprogramm aus, um eine gespiegelte Datenbank aus der Quelldatenbank zu erstellen.
- Tutorial: Konfigurieren der gespiegelten Microsoft Fabric-Datenbank für Azure Cosmos DB (Vorschau)
- Tutorial: Konfigurieren von in Microsoft Fabric gespiegelten Datenbanken aus Azure Databricks (Vorschau)
- Tutorial: Konfigurieren von in Microsoft Fabric gespiegelten Datenbanken aus Azure SQL-Datenbank
- Tutorial: Konfigurieren von in Microsoft Fabric gespiegelten Datenbanken aus Azure SQL Managed Instance (Vorschau)
- Tutorial: Konfigurieren von gespiegelten Microsoft Fabric-Datenbanken aus Snowflake
Eine Verknüpfung erstellen
Sie müssen zunächst eine Verknüpfung von Ihren gespiegelten Tabellen in das Lakehouse erstellen und dann Notebooks mit Spark-Abfragen in Ihrem Lakehouse erstellen.
Öffnen Sie im Fabric-Portal Datentechnik.
Wenn Sie noch kein Lakehouse erstellt haben, wählen Sie Lakehouse aus, und erstellen Sie ein neues Lakehouse, indem Sie ihm einen Namen geben.
Wählen Sie Daten abrufen - >Neue Verknüpfung aus.
Wählen Sie Microsoft OneLake aus.
Sie können alle Ihre gespiegelte Datenbanken im Fabric-Arbeitsbereich anzeigen.
Wählen Sie die Spiegeldatenbank aus, die Sie Ihrem Lakehouse als Verknüpfung hinzufügen möchten.
Wählen Sie die gewünschten Tabellen aus der Spiegeldatenbank aus.
Wählen Sie Weiter und dann Erstellen aus.
Im Explorer können Sie nun ausgewählte Tabellendaten in Ihrem Lakehouse sehen.
Tipp
Sie können andere Daten direkt in Lakehouse hinzufügen oder Verknüpfungen wie S3, ADLS Gen2 mitbringen. Sie können zum SQL-Analyseendpunkt des Lakehouse navigieren und die Daten über alle diese Quellen hinweg mit gespiegelten Daten nahtlos verknüpfen.
Um diese Daten in Spark zu untersuchen, wählen Sie die
...Punkte neben einer beliebigen Tabelle. Wählen Sie Neues Notebook oder Vorhandenes Notebook, um mit der Analyse zu beginnen.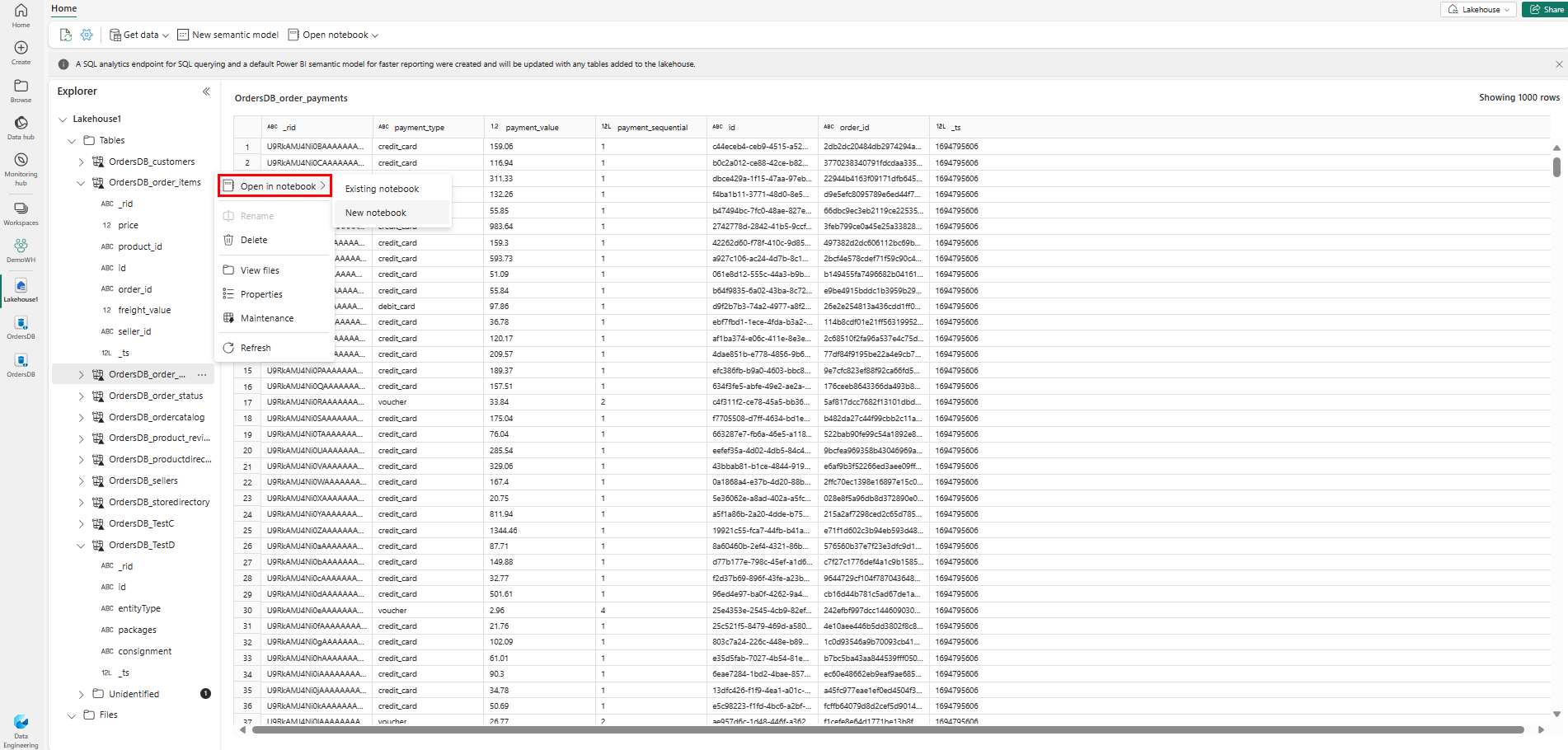
Das Notebook wird automatisch geöffnet und der DataFrame mit einer
SELECT ... LIMIT 1000Spark SQL-Abfrage geladen.- Neue Notebooks können bis zu zwei Minuten benötigen, bis sie vollständig geladen werden. Sie können diese Verzögerung vermeiden, indem Sie ein vorhandenes Notebook mit einer aktiven Sitzung verwenden.

- Neue Notebooks können bis zu zwei Minuten benötigen, bis sie vollständig geladen werden. Sie können diese Verzögerung vermeiden, indem Sie ein vorhandenes Notebook mit einer aktiven Sitzung verwenden.


