Entwickeln, Auswerten und Bewerten eines Vorhersagemodells für Supermarktumsätze
Dieses Lernprogramm zeigt ein End-to-End-Beispiel für einen Synapse Data Science-Workflow in Microsoft Fabric. Das Szenario erstellt ein Prognosemodell, das historische Verkaufsdaten verwendet, um Produktkategorienverkäufe in einem Superstore vorherzusagen.
Die Prognose ist eine entscheidende Ressource im Umsatz. Sie kombiniert historische Daten und Prädiktive Methoden, um Einblicke in zukünftige Trends zu liefern. Prognosen können vergangene Verkäufe analysieren, um Muster zu identifizieren und von Verbraucherverhalten zu lernen, um Bestands-, Produktions- und Marketingstrategien zu optimieren. Dieser proaktive Ansatz verbessert Anpassungsfähigkeit, Reaktionsfähigkeit und Gesamtleistung von Unternehmen auf einem dynamischen Markt.
In diesem Lernprogramm werden die folgenden Schritte behandelt:
- Laden der Daten
- Verwenden sie explorative Datenanalyse, um die Daten zu verstehen und zu verarbeiten.
- Trainieren eines Machine Learning-Modells mit einem Open-Source-Softwarepaket und Nachverfolgen von Experimenten mit MLflow und dem Fabric-Autologging-Feature
- Speichern des endgültigen Machine Learning-Modells und Erstellen von Vorhersagen
- Anzeigen der Modellleistung mit Power BI-Visualisierungen
Voraussetzungen
Holen Sie sich ein Microsoft Fabric-Abonnement. Oder registrieren Sie sich für eine kostenlose Microsoft Fabric-Testversion.
Melden Sie sich bei Microsoft Fabrican.
Verwenden Sie den Erfahrungsschalter auf der unteren linken Seite Ihrer Startseite, um zu Fabric zu wechseln.

- Erstellen Sie bei Bedarf ein Microsoft Fabric Lakehouse, wie in Erstellen eines Lakehouses in Microsoft Fabricbeschrieben.
Durchführung in einem Notebook
Sie können eine der folgenden Optionen wählen, um ein Notebook für das Tutorial zu verwenden.
- Öffnen und Ausführen des integrierten Notizbuchs in der Synapse Data Science-Erfahrung
- Hochladen Ihres Notizbuchs von GitHub in die Synapse Data Science-Erfahrung
Öffnen des integrierten Notizbuchs
Das Beispiel-Notizbuch Umsatzprognose begleitet dieses Lernprogramm.
Um das Beispielnotizbuch für dieses Lernprogramm zu öffnen, befolgen Sie die Anweisungen in Vorbereiten Ihres Systems für Data Science-Lernprogramme.
Fügen Sie ein Lakehouse an das Notebook an, bevor Sie mit der Ausführung von Code beginnen.
Importieren des Notizbuchs aus GitHub
Das Notebook AIsample - Superstore Forecast.ipynb ist diesem Tutorial beigefügt.
Zum Öffnen des zugehörigen Notizbuchs für dieses Lernprogramm folgen Sie den Anweisungen in Vorbereiten Ihres Systems für Data Science-Lernprogramme, um das Notizbuch in Ihren Arbeitsbereich zu importieren.
Wenn Sie den Code lieber von dieser Seite kopieren und einfügen möchten, können Sie ein neues Notizbucherstellen.
Fügen Sie ein Lakehouse an das Notebook an, bevor Sie mit der Ausführung von Code beginnen.
Schritt 1: Laden der Daten
Der Datensatz enthält 9.995 Einträge von Verkäufen verschiedener Produkte. Sie enthält auch 21 Attribute. Diese Tabelle stammt aus der in diesem Notizbuch verwendeten Superstore.xlsx Datei:
| Zeilen-ID | Auftrags-ID | Bestelldatum | Lieferdatum | Versandmodus | Kunden-ID | Kundenname | Segment | Land | Stadt | Staat | Postleitzahl | Region | Produkt-ID | Kategorie | Unterkategorie | Produktname | Umsatz | Menge | Rabatt | Gewinn |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Standardklasse | SO-20335 | Sean O'Donnell | Verbraucher | USA | Fort Lauderdale | Florida | 33311 | Süden | FUR-TA-10000577 | Möbel | Tabellen | Bretford CR4500 Series Slim Rechteckiger Tisch | 957,5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Standardklasse | Standardklasse | Brosina Hoffman | Verbraucher | USA | Los Angeles | Kalifornien | 90032 | West | FUR-TA-10001539 | Möbel | Tabellen | Rechteckige Konferenztische von Chromcraft | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Standardklasse | TB-21520 | Tracy Blumstein | Verbraucher | USA | Philadelphia | Pennsylvania | 19140 | Osten | OFF-EN-10001509 | Büroartikel | Briefumschläge | Poly String Tie Envelopes | 3,264 | 2 | 0.2 | 1.1016 |
Definieren Sie diese Parameter, damit Sie dieses Notizbuch mit verschiedenen Datasets verwenden können:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Laden Sie das Dataset herunter und laden Sie es in das Seehaus hoch.
Dieser Code lädt eine öffentlich verfügbare Version des Datasets herunter und speichert sie dann in einem Fabric Lakehouse:
Wichtig
Fügen Sie dem Notebook ein Lakehouse hinzu, bevor Sie es ausführen. Andernfalls wird eine Fehlermeldung angezeigt.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Einrichten der MLflow-Experimentnachverfolgung
Microsoft Fabric erfasst automatisch die Werte von Eingabeparametern und Ausgabemetriken eines Machine Learning-Modells, während Sie es trainieren. Dadurch werden die Automatischprotokollierungsfunktionen von MLflow erweitert. Die Informationen werden dann am Arbeitsbereich protokolliert, wo Sie mit den MLflow-APIs oder dem entsprechenden Experiment im Arbeitsbereich darauf zugreifen und visualisieren können. Weitere Informationen zu Autologging finden Sie unter Autologging in Microsoft Fabric.
Rufen Sie mlflow.autolog() auf, und legen Sie disable=True fest, um die automatische Microsoft Fabric-Protokollierung in einer Notebooksitzung zu deaktivieren:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Lesen von Rohdaten aus dem Lakehouse
Dieser Code liest Rohdaten aus dem Abschnitt Dateien des Lakehouses. Fügen Sie weitere Spalten für verschiedene Datumsteile hinzu. Die gleichen Informationen werden verwendet, um eine partitionierte Delta-Tabelle zu erstellen. Da die Rohdaten als Excel-Datei gespeichert werden, müssen Sie pandas verwenden, um sie zu lesen:
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Schritt 2: Durchführen einer explorativen Datenanalyse
Importieren von Bibliotheken
Importieren Sie vor einer Analyse die erforderlichen Bibliotheken:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Anzeigen der Rohdaten
Überprüfen Sie manuell eine Teilmenge der Daten, um das Dataset selbst besser zu verstehen, und verwenden Sie die display-Funktion, um den DataFrame zu drucken. Darüber hinaus können die Chart Ansichten ganz einfach Teilmengen des Datasets visualisieren.
display(df)
Dieses Notizbuch konzentriert sich in erster Linie auf die Prognose des Furniture Kategorieumsatzes. Dadurch wird die Berechnung beschleunigt und die Leistung des Modells angezeigt. Dieses Notizbuch verwendet jedoch anpassungsfähige Techniken. Sie können diese Techniken erweitern, um den Umsatz anderer Produktkategorien vorherzusagen.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Vorverarbeitung der Daten
Reale Geschäftsszenarien müssen häufig Umsätze in drei unterschiedlichen Kategorien vorhersagen:
- Eine bestimmte Produktkategorie
- Eine bestimmte Kundenkategorie
- Eine bestimmte Kombination aus Produktkategorie und Kundenkategorie
Legen Sie zunächst unnötige Spalten ab, um die Daten vorzuverarbeiteten. Einige der Spalten (Row ID, Order ID,Customer IDund Customer Name) sind unnötig, da sie keine Auswirkungen haben. Der Gesamtumsatz für eine bestimmte Produktkategorie (Furniture) soll prognostiziert werden, damit die Spalten State, Region, Country, City und Postal Code gelöscht werden können. Um den Umsatz für einen bestimmten Standort oder eine bestimmte Kategorie zu prognostizieren, müssen Sie den Vorverarbeitungsschritt möglicherweise entsprechend anpassen.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Der Datensatz ist auf täglicher Basis strukturiert. Wir müssen die Spalte Order Dateneu abtasten, da wir ein Modell entwickeln möchten, um den Umsatz monatlich zu prognostizieren.
Gruppieren Sie zunächst die Kategorie Furniture nach Order Date. Berechnen Sie dann die Summe der Sales Spalte für jede Gruppe, um den Gesamtumsatz für jeden eindeutigen Order Date Wert zu ermitteln. Resampeln Sie die Sales-Spalte mit der MS-Frequenz, um die Daten monatlich zu aggregieren. Berechnen Sie schließlich den mittleren Verkaufswert für jeden Monat.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Veranschaulichen Sie die Auswirkungen von Order Date auf Sales für die kategorie Furniture:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Vor einer statistischen Analyse müssen Sie das statsmodels Python-Modul importieren. Es stellt Klassen und Funktionen für die Schätzung vieler statistischer Modelle bereit. Außerdem werden Klassen und Funktionen zur Durchführung statistischer Tests und statistischer Datensuche bereitgestellt.
import statsmodels.api as sm
Durchführen einer statistischen Analyse
Eine Zeitreihe verfolgt diese Datenelemente in festgelegten Intervallen nach, um die Variation dieser Elemente im Zeitreihenmuster zu bestimmen:
Ebene: Die grundlegende Komponente, die den Durchschnittswert für einen bestimmten Zeitraum darstellt
Trend-: Beschreibt, ob die Zeitreihe im Laufe der Zeit abnimmt, konstant bleibt oder zunimmt.
Saisonalität: Beschreibt das periodische Signal in der Zeitreihe und sucht nach zyklischen Vorkommen, die sich auf die zunehmenden oder abnehmenden Zeitreihenmuster auswirken
Rauschen/Restwert: Bezieht sich auf die zufälligen Schwankungen und Variabilität in den Zeitreihendaten, die das Modell nicht erklären kann.
In diesem Code beobachten Sie diese Elemente für Ihr Dataset nach der Vorverarbeitung:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
Die Plots beschreiben die Saisonalität, Trends und Lärm in den Prognosedaten. Sie können die zugrunde liegenden Muster erfassen und Modelle entwickeln, die genaue Vorhersagen machen, die widerstandsfähig gegen zufällige Schwankungen sind.
Schritt 3: Trainieren und Nachverfolgen des Modells
Nachdem Sie nun die Daten verfügbar haben, definieren Sie das Prognosemodell. Wenden Sie in diesem Notizbuch das Prognosemodell saisonalen autoregressiven integrierten gleitenden Durchschnitt mit exogenen Faktoren (SARIMAX) an. SARIMAX kombiniert autoregressive (AR) und gleitende Mittelwerte (MA)-Komponenten, saisonale Unterschiede und externe Vorhersager, um genaue und flexible Prognosen für Zeitreihendaten zu erstellen.
Außerdem verwenden Sie MLflow und Fabric für das Autologging, um die Experimente zu protokollieren. Laden Sie hier die Delta-Tabelle aus dem Lakehouse. Sie können andere Delta-Tabellen verwenden, die das Seehaus als Quelle betrachten.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Optimieren von Hyperparametern
SARIMAX berücksichtigt die Parameter, die am regulären autoregressiven integrierten gleitenden Durchschnitt (ARIMA)-Modus beteiligt sind (p, d, q), und fügt die Saisonalitätsparameter hinzu (P, D, Q, s). Diese SARIMAX-Modellargumente werden Reihenfolge (p, d, q) und saisonbedingte Reihenfolge (P, D, Q, s) genannt. Um das Modell zu trainieren, müssen wir daher zunächst sieben Parameter optimieren.
Die Bestellparameter:
p: Die Reihenfolge der AR-Komponente, die die Anzahl der letzten Beobachtungen in der Zeitreihe darstellt, die verwendet wird, um den aktuellen Wert vorherzusagen.Normalerweise sollte dieser Parameter eine nicht negative ganze Zahl sein. Allgemeine Werte befinden sich im Bereich von
0bis3, obwohl höhere Werte möglich sind, abhängig von den spezifischen Datenmerkmalen. Ein höhererpWert gibt einen längeren Speicher vergangener Werte im Modell an.d: Die Differenzierungsordnung, die angibt, wie oft die Zeitreihe differenziert werden muss, um Stationarität zu erreichen.Dieser Parameter sollte eine nicht negative ganze Zahl sein. Allgemeine Werte befinden sich im Bereich von
0bis2. EindWert von0bedeutet, dass die Zeitreihe bereits stationär ist. Höhere Werte geben die Anzahl der erforderlichen Vorgänge zur Differenzbildung an, damit diese stationär werden.q: Die Bestellung der MA-Komponente, die die Anzahl vergangener Fehlerterme mit weißem Rauschen darstellt, die zum Vorhersagen des aktuellen Werts verwendet werden.Dieser Parameter sollte eine nicht negative ganze Zahl sein. Allgemeine Werte befinden sich im Bereich von
0bis3, aber für bestimmte Zeitreihen sind möglicherweise höhere Werte erforderlich. Ein höhererqWert gibt eine stärkere Abhängigkeit von früheren Fehlerbegriffen an, um Vorhersagen zu treffen.
Die Saisonbestellparameter
P: Die saisonbedingte Reihenfolge der AR-Komponente, ähnlich wiep, aber für den saisonalen TeilD: Saisonale Bestellung für die Differenzenbildung, ähnlich wied, allerdings für den saisonalen TeilQ: Die saisonbedingte Reihenfolge der MA-Komponente, ähnlich wieq, aber für den saisonalen Teils: Die Anzahl der Zeitschritte pro Saisonzyklus (z. B. 12 für monatliche Daten mit jährlicher Saisonalität)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX hat andere Parameter:
enforce_stationarity: Ob das Modell die Stationarität der Zeitreihendaten erzwingen soll, bevor das SARIMAX-Modell angepasst wird.Wenn
enforce_stationarityaufTrue(Standardeinstellung) festgelegt ist, gibt es an, dass das SARIMAX-Modell die Stationarität für die Zeitreihendaten erzwingen soll. Das SARIMAX-Modell wendet daraufhin vor der Anpassung des Modells automatisch die Differenzenbildung auf die Zeitreihendaten an, damit diese stationär werden, wie durch died- undD-Bestellungen angegeben. Dies ist eine gängige Praxis, da viele Zeitreihenmodelle, einschließlich SARIMAX, davon ausgehen, dass die Daten stationär sind.Bei einer nicht stationären Zeitreihe (z. B. wenn sie Trends oder Saisonalität zeigt) empfiehlt es sich,
enforce_stationarityaufTruefestzulegen und das SARIMAX-Modell die Differenzierung zu übernehmen, um die Stationarität zu erreichen. Legen Sie für eine stationäre Zeitreihe (z. B. eine ohne Trends oder Saisonalität)enforce_stationarityaufFalsefest, um unnötige Unterschiede zu vermeiden.enforce_invertibility: Steuert, ob das Modell während des Optimierungsprozesses die Invertierbarkeit für die geschätzten Parameter erzwingen soll.Wenn
enforce_invertibilityaufTrue(Standardeinstellung) festgelegt ist, gibt es an, dass das SARIMAX-Modell die Invertierbarkeit für die geschätzten Parameter erzwingen soll. Die Invertierbarkeit stellt sicher, dass das Modell gut definiert ist und dass die geschätzten AR- und MA-Koeffizienten innerhalb des Bereichs der Stationarität landen.Die Invertierbarkeitserzwingung trägt dazu bei, dass das SARIMAX-Modell den theoretischen Anforderungen für ein stabiles Zeitreihenmodell entspricht. Es hilft auch, Probleme mit der Modellschätzung und Stabilität zu verhindern.
Der Standard ist ein AR(1)-Modell. Dies bezieht sich auf (1, 0, 0). Es ist jedoch üblich, verschiedene Kombinationen der Bestellparameter und saisonalen Bestellparameter auszuprobieren und die Modellleistung für ein Dataset zu bewerten. Die entsprechenden Werte können von einer Zeitreihe zu einer anderen variieren.
Die Bestimmung der optimalen Werte umfasst häufig die Analyse der Autokorrelationsfunktion (ACF) und der partiellen Autokorrelationsfunktion (PACF) der Zeitreihendaten. Es umfasst auch häufig die Verwendung von Modellauswahlkriterien - z. B. das Akaike-Informationskriterium (AIC) oder das Bayesische Informationskriterium (BIC).
Optimieren Sie die Hyperparameter:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Nach der Auswertung der vorherigen Ergebnisse können Sie die Werte sowohl für die Ordnungsparameter als auch für die saisonalen Ordnungsparameter bestimmen. Die Wahl ist order=(0, 1, 1) und seasonal_order=(0, 1, 1, 12), die die niedrigste AIC (z. B. 279,58) bieten. Verwenden Sie diese Werte, um das Modell zu trainieren.
Trainieren des Modells
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Dieser Code visualisiert eine Zeitreihenprognose für Möbelumsatzdaten. Die dargestellten Ergebnisse zeigen sowohl die beobachteten Daten als auch die 1-Schritt-Voraus-Prognose mit einem schattierten Bereich für konfidenzintervalle an.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Verwenden Sie predictions, um die Leistung des Modells zu bewerten, indem Sie sie mit den tatsächlichen Werten vergleichen. Der predictions_future Wert gibt die zukünftige Prognose an.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Schritt 4: Bewertung des Modells und Speichern von Vorhersagen
Integrieren Sie die tatsächlichen Werte in die prognostizierten Werte, um einen Power BI-Bericht zu erstellen. Speichern Sie diese Ergebnisse in einer Tabelle im Lakehouse.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Schritt 5: Visualisieren in Power BI
Der Power BI-Bericht zeigt einen mittleren absoluten Prozentfehler (MAPE) von 16,58 an. Die MAPE-Metrik definiert die Genauigkeit einer Prognosemethode. Sie stellt die Genauigkeit der prognostizierten Mengen im Vergleich zu den tatsächlichen Mengen dar.
MAPE ist eine einfache Metrik. Eine 10% MAPE bedeutet, dass die durchschnittliche Abweichung zwischen den prognostizierten und tatsächlichen Werten 10%beträgt, unabhängig davon, ob die Abweichung positiv oder negativ war. Die Standards wünschenswerter MAPE-Werte variieren in verschiedenen Branchen.
Die hellblaue Linie in diesem Diagramm stellt die tatsächlichen Umsatzwerte dar. Die dunkelblaue Linie stellt die prognostizierten Umsatzwerte dar. Der Vergleich der tatsächlichen und prognostizierten Umsätze zeigt, dass das Modell in den ersten sechs Monaten 2023 den Umsatz für die Furniture Kategorie effektiv vorhersagt.
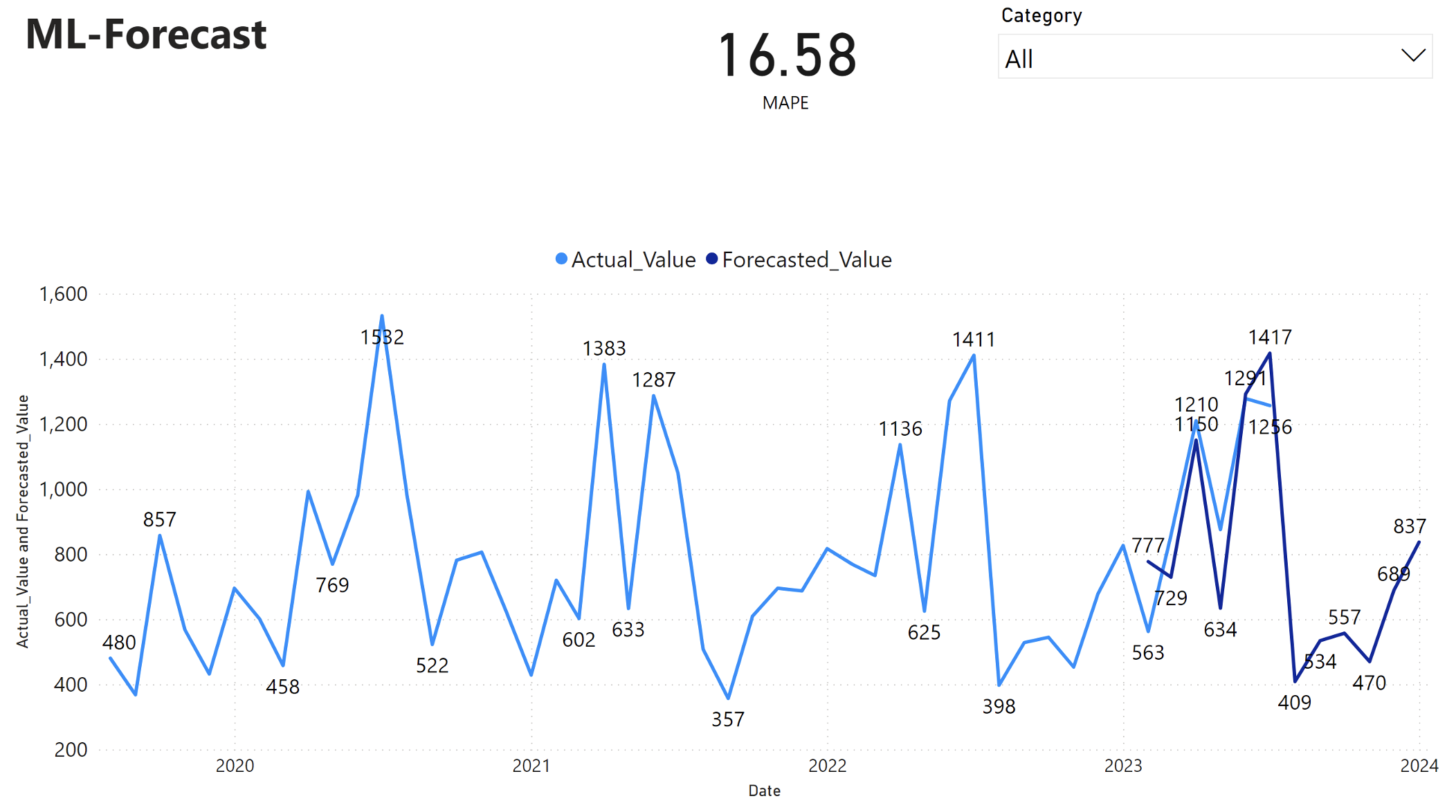
Basierend auf dieser Beobachtung können wir Vertrauen in die Prognosefähigkeiten des Modells haben, für den Gesamtumsatz in den letzten sechs Monaten 2023 und bis 2024. Dieses Vertrauen kann strategische Entscheidungen über die Bestandsverwaltung, die Beschaffung von Rohstoffen und andere geschäftsbezogene Überlegungen informieren.