Planen der Migration von Azure Data Factory
Microsoft Fabric ist das SaaS-Produkt für Datenanalysen von Microsoft, das alle marktführenden Analyseprodukte von Microsoft zu einer einzigen Benutzererfahrung zusammenführt. Fabric Data Factory bietet Workflow-Orchestrierung, Datenverschiebung, Datenreplikation und Datentransformation im Maßstab mit ähnlichen Funktionen, die in Azure Data Factory (ADF) zu finden sind. Wenn Sie bereits über ADF-Investitionen verfügen, die Sie in Fabric Data Factory modernisieren möchten, ist dieses Dokument hilfreich, um Migrationsüberlegungen, Strategien und Ansätze zu verstehen.
Die Migration aus den Azure PaaS ETL/DI-Diensten ADF & Synapse-Pipelines und -Datenflüssen kann mehrere wichtige Vorteile bieten:
- Neue integrierte Pipelinefeatures, einschließlich E-Mail- und Teams-Aktivitäten, ermöglichen das einfache Routing von Nachrichten während der Pipelineausführung.
- Integrierte Funktionen für kontinuierliche Integration und Übermittlung (CI/CD) (Bereitstellungspipelinen) erfordern keine externe Integration in Git-Repositorys.
- Die Arbeitsbereichintegration mit Ihrem OneLake Data Lake ermöglicht ein einfaches Analyse-Management aus einer Hand.
- Das Aktualisieren ihrer semantischen Datenmodelle ist in Fabric mit einer vollständig integrierten Pipelineaktivität einfach.
Microsoft Fabric ist eine integrierte Plattform für Self-Service- und IT-verwaltete Unternehmensdaten. Mit exponentiellem Wachstum in Datenvolumen und Komplexität fordern Fabric-Kunden Unternehmenslösungen, die sicher, einfach zu verwalten und für alle Benutzer in den größten Organisationen zugänglich sind.
In den letzten Jahren investierte Microsoft erhebliche Anstrengungen, um skalierbare Cloudfunktionen für Premium bereitzustellen. Zu diesem Zweck ermöglicht Data Factory in Fabric sofort ein großes Ökosystem von Datenintegrationsentwicklern und Datenintegrationslösungen, die über Jahrzehnte aufgebaut wurden, um den vollständigen Satz von Features und Funktionen anzuwenden, die weit über vergleichbare Funktionen hinausgehen, die in früheren Generationen verfügbar sind.
Natürlich fragen Kunden, ob es eine Möglichkeit gibt, ihre Datenintegrationslösungen in Fabric zu konsolidieren. Zu den häufig gestellten Fragen gehören:
- Funktioniert die gesamte Funktionalität, auf die wir angewiesen sind, in Fabric-Pipelines?
- Welche Funktionen sind nur in Fabric-Pipelines verfügbar?
- Wie migrieren wir vorhandene Pipelines zu Fabric-Pipelines?
- Was ist die Roadmap von Microsoft für die Erfassung von Unternehmensdaten?
Plattformunterschiede
Wenn Sie eine gesamte ADF-Instanz migrieren, gibt es viele wichtige Unterschiede zwischen ADF und Data Factory in Fabric, die beim Migrieren zu Fabric wichtig wird. Wir untersuchen einige dieser wichtigen Unterschiede in diesem Abschnitt.
Ausführlichere Informationen zur funktionalen Zuordnung von Features zwischen Azure Data Factory und Fabric Data Factory finden Sie unter Compare Data Factory in Fabric und Azure Data Factory.
Integrationslaufzeiten
In ADF sind Integrationsruntimes (IRs) Konfigurationsobjekte, die Compute darstellen, die von ADF zum Abschließen der Datenverarbeitung verwendet wird. Zu diesen Konfigurationseigenschaften gehören die Azure-Region für Cloud-Computing und die Größen der Data-Flow-Spark-Computing-Einheiten. Andere IR-Typen umfassen selbst gehostete IRs (SHIRs) für lokale Datenkonnektivität, SSIS-IRs für die Ausführung von SQL Server Integration Services-Paketen und Vnet-fähige Cloud-IRs.
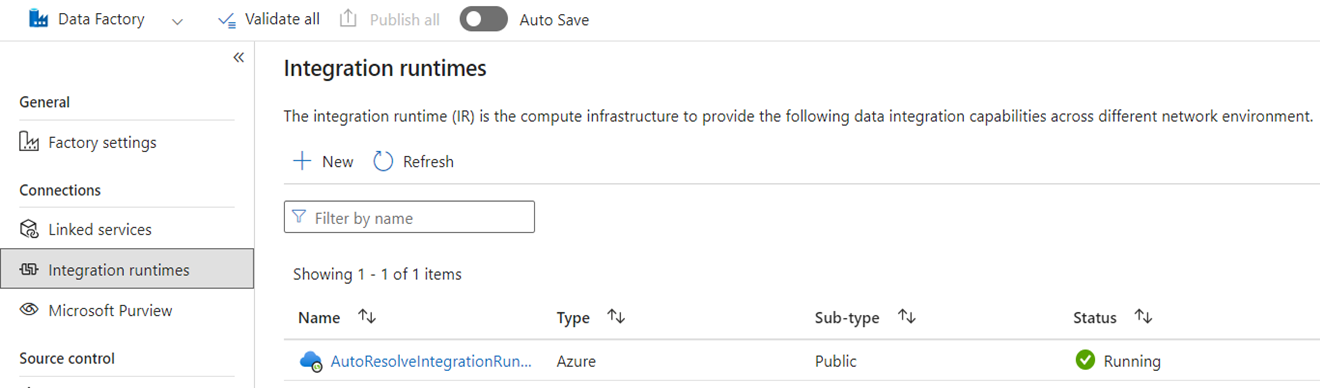
Microsoft Fabric ist ein SaaS-Produkt (Software-as-a-Service), während ADF ein PaaS-Produkt (Platform-as-a-Service) ist. Diese Unterscheidung bedeutet in Bezug auf Integrationslaufzeiten, dass Sie nichts für die Verwendung von Pipelines oder Datenflüssen in Fabric konfigurieren müssen, da standardmäßig cloudbasierte Compute in der Region verwendet werden soll, in der sich Ihre Fabric-Kapazitäten befinden. SSIS-IRs sind in Fabric nicht vorhanden, und für die lokale Datenkonnektivität verwenden Sie eine Fabric-spezifische Komponente, bekannt als das lokale Daten-Gateway (OPDG). Und für die netzwerkbasierte Konnektivität mit gesicherten Netzwerken verwenden Sie das Virtual Network Data Gateway in Fabric.
Bei der Migration von ADF zu Fabric müssen Sie keine Azure-IRs (öffentliches Netzwerk) migrieren. Sie müssen Ihre SHIRs als OPDGs und für virtuelle Netzwerk aktivierte Azure IRs als Virtual Network Data Gateways neu erstellen.
Rohrleitungen
Pipelines sind die grundlegende Komponente von ADF, die für den primären Workflow und die Orchestrierung Ihrer ADF-Prozesse für Datenbewegungen, Datentransformation und Prozess-Orchestrierung verwendet wird. Pipelines in Fabric Data Factory sind nahezu identisch mit denen in ADF, weisen jedoch zusätzliche Komponenten auf, die gut zum SaaS-Modell passen, das auf Power BI basiert. Diese Ähnlichkeit umfasst systemeigene Aktivitäten für E-Mails, Teams und Semantikmodellaktualisierungen.
Die JSON-Definition von Pipelines in Fabric Data Factory unterscheidet sich geringfügig von ADF aufgrund von Unterschieden im Anwendungsmodell zwischen den beiden Produkten. Aufgrund dieses Unterschieds ist es nicht möglich, JSON-Pipelines zu kopieren/einzufügen, Pipelines zu importieren/zu exportieren oder auf ein ADF-Git-Repository zu verweisen.
Wenn Sie Ihre ADF-Pipelines als Fabric-Pipelines neu erstellen, verwenden Sie im Wesentlichen dieselben Workflowmodelle und Fähigkeiten, die Sie in ADF verwendet haben. Die Hauptüberlegung ist mit Linked Services und Datasets zu tun, bei denen es sich um Konzepte in ADF handelt, die in Fabric nicht vorhanden sind.
Verknüpfte Dienste
In ADF definieren verknüpfte Dienste die Konnektivitätseigenschaften, die zum Herstellen einer Verbindung mit Ihren Datenspeichern für Datenverschiebungs-, Datentransformations- und Datenverarbeitungsaktivitäten erforderlich sind. In Fabric müssen Sie diese Definitionen als Verbindungen neu erstellen, die Eigenschaften für Ihre Aktivitäten wie "Kopieren" und "Datenflüsse" sind.
Datensätze
Datasets definieren das Shape, die Position und den Inhalt Ihrer Daten in ADF, sind aber nicht als Entitäten in Fabric vorhanden. Um Dateneigenschaften wie Datentypen, Spalten, Ordner, Tabellen usw. in Fabric Data Factory-Pipelines zu definieren, definieren Sie diese Merkmale inline innerhalb von Pipelineaktivitäten und innerhalb des Connection-Objekts, auf das zuvor im Abschnitt "Verknüpfter Dienst" verwiesen wird.
Datenflüsse
In Data Factory for Fabric bezieht sich der Begriff Datenflüsse auf die codefreien Datentransformationsaktivitäten, während in ADF dasselbe Feature als Datenflüssebezeichnet wird. Fabric Data Factory-Datenflüsse verfügen über eine Benutzeroberfläche, die auf Power Query basiert, die in der ADF-Power Query-Aktivität verwendet wird. Der zum Ausführen von Datenflüssen in Fabric verwendete Rechner ist ein nativer Ausführungsmechanismus, der für groß angelegte Datenumwandlungen mit der neuen Fabric Data Warehouse-Recheneinheit skaliert werden kann.
In ADF basieren Datenflüsse auf der Synapse Spark-Infrastruktur und werden mithilfe einer Konstruktionsbenutzeroberfläche definiert, die eine zugrunde liegende domänenspezifische Sprache (DSL) verwendet, die als Datenflussskriptbezeichnet wird. Diese Definitionssprache unterscheidet sich erheblich von den Power Query-basierten Datenflüssen in Fabric, die eine Definitionssprache verwenden, die als M- bezeichnet wird, um ihr Verhalten zu definieren. Aufgrund dieser Unterschiede bei Benutzeroberflächen, Sprachen und Ausführungsmodulen sind Fabric -Datenflüsse und ADF -Datenflüsse nicht kompatibel, und Sie müssen Ihre ADF--Datenflüsse bei einem Upgrade auf Fabric als Fabric -Datenflüsse neu erstellen.
Auslöser
Triggers weisen ADF an, eine Pipeline basierend auf einem Gesamtbetrachtungszeitraum, auf rollierenden Fensterzeitsegmenten, dateibasierten Ereignissen oder benutzerdefinierten Ereignissen auszuführen. Diese Features sind in Fabric ähnlich, obwohl die zugrunde liegende Implementierung unterschiedlich ist.
In Fabric existieren Trigger nur als Pipelinekonzept. Das größere Framework, das Pipelinetrigger in Fabric nutzen, ist als Data Activator bekannt und handelt sich um ein Ereignis- und Warnungssubsystem der Echtzeit-Intelligenzfunktionen in Fabric.
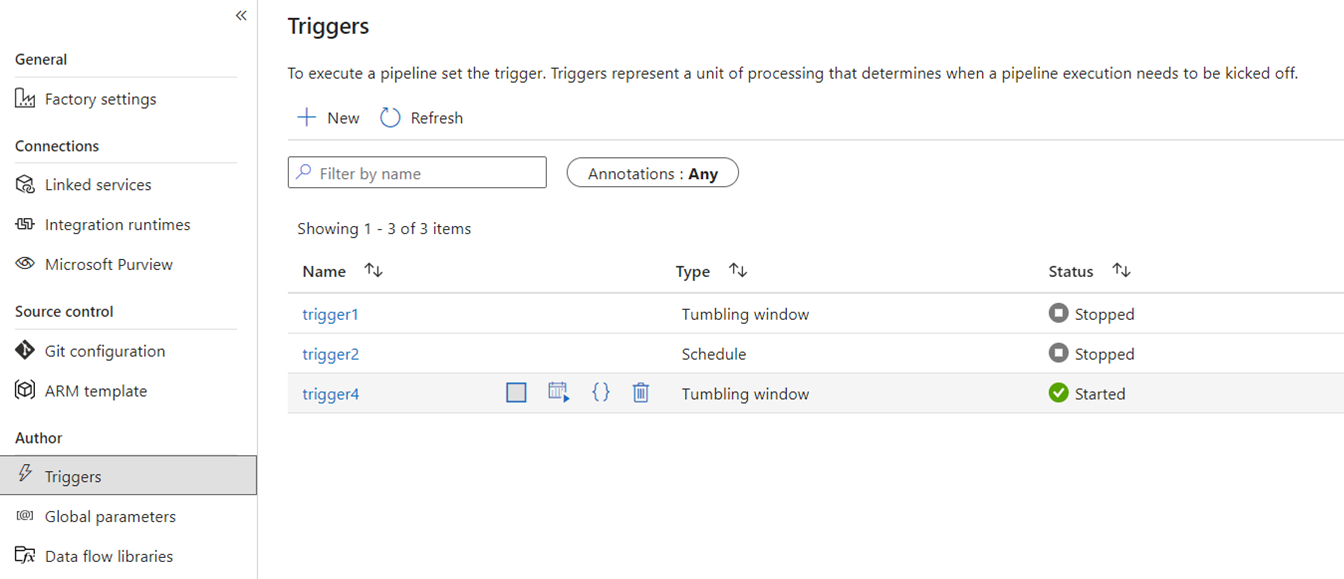
Fabric Data Activator verfügt über Warnungen, die zum Erstellen von Dateiereignistriggern und benutzerdefinierten Ereignistriggern verwendet werden können. Obwohl Zeitplantrigger eine separate Entität in Fabric sind, die als Zeitpläne bekannt sind. Diese Zeitpläne befinden sich auf Plattformebene in Fabric und nicht spezifisch für Pipelines. Sie werden auch nicht als Trigger in Fabric bezeichnet.
Wenn Sie Ihre Trigger von ADF zu Fabric migrieren möchten, erwägen Sie, Ihre Zeitplantrigger neu zu erstellen und zwar einfach als Zeitpläne, die Eigenschaften Ihrer Fabric-Pipelines sind. Verwenden Sie für alle anderen Triggertypen die Schaltfläche "Trigger" in der Fabric-Pipeline, oder verwenden Sie den Datenaktivator nativ in Fabric.
Debuggen
Das Debuggen von Pipelines ist in Fabric einfacher als in ADF. Diese Einfachheit liegt daran, dass Fabric Data Factory-Pipelines nicht über ein separates Konzept von Debugmodus verfügen, die Sie in ADF-Pipelines und Datenflüssen finden. Wenn Sie ihre Pipeline erstellen, befinden Sie sich stattdessen immer im interaktiven Modus. Um Ihre Pipelines zu testen und zu debuggen, müssen Sie nur, wenn Sie im Entwicklungszyklus bereit sind, den Play-Button auf der Symbolleiste des Pipeline-Editors auswählen. Pipelines in Fabric enthalten nicht das Schritt-für-Schritt-Muster debug until (Debuggen bis) für das interaktive Debuggen. Stattdessen verwenden Sie in Fabric den Aktivitätsstatus und legen nur die Aktivitäten fest, die Sie als aktiv testen möchten, während alle anderen Aktivitäten auf "inaktiv" festgelegt werden, um dieselben Test- und Debugmuster zu erzielen. Im folgenden Video erfahren Sie, wie Sie diese Debugerfahrung in Fabric erreichen.
Ändern der Datenerfassung
Change Data Capture (CDC) in ADF ist eine Previewfunktion, die es ermöglicht, Daten schnell und schrittweise zu verschieben, indem die CDC-Features auf der Seite der Datenquellen Ihrer Datenspeicher angewendet werden. Um Ihre CDC-Artefakte zu Fabric Data Factory zu migrieren, erstellen Sie diese Artefakte als Kopierauftrag-Elemente in Ihrem Fabric-Arbeitsbereich neu. Dieses Feature bietet ähnliche Funktionen der inkrementellen Datenverschiebung mit einer benutzerfreundlichen Benutzeroberfläche, ohne dass eine Pipeline erforderlich ist, genau wie in ADF CDC. Weitere Informationen finden Sie im Kopierauftrag für Data Factory in Fabric.
Azure Synapse-Link
Obwohl in ADF nicht verfügbar, verwenden Synapse-Pipeline-Benutzer häufig Azure Synapse Link, um Daten aus SQL-Datenbanken auf schlüsselfertige Weise in ihren Data Lake zu replizieren. In Fabric erstellen Sie die Azure Synapse Link Artefakte als Spiegelungselemente in Ihrem Arbeitsbereich neu. Weitere Informationen finden Sie unter Fabric-Datenbankspiegelung.
SQL Server Integration Services (SSIS)
SSIS ist das lokale Datenintegrations- und ETL-Tool, das Microsoft mit SQL Server ausgeliefert. In ADF können Sie Ihre SSIS-Pakete mithilfe der ADF SSIS IR in die Cloud verschieben. In Fabric verfügen wir nicht über das Konzept von IRs, daher ist diese Funktionalität heute nicht möglich. Wir arbeiten jedoch daran, die SSIS-Paketausführung nativ aus Fabric zu aktivieren, die wir in Kürze auf das Produkt bringen möchten. In der Zwischenzeit besteht die beste Möglichkeit zum Ausführen von SSIS-Paketen in der Cloud mit Fabric Data Factory darin, eine SSIS IR in Ihrer ADF-Factory zu starten und dann eine ADF-Pipeline aufzurufen, um Ihre SSIS-Pakete aufzurufen. Sie können eine ADF-Pipeline aus Ihren Fabric-Pipelines remote aufrufen, indem Sie die im folgenden Abschnitt beschriebene aufgerufene Pipelineaktivität verwenden.
Aktivität „Pipeline aufrufen“
Eine häufige Aktivität, die in ADF-Pipelines verwendet wird, ist das Ausführen der Pipelineaktivität, mit der Sie eine andere Pipeline in Ihrer Factory aufrufen können. In Fabric haben wir diese Aktivität als Aktivität „Pipeline aufrufen“ verbessert. Weitere Informationen finden Sie in der Dokumentation Aufrufen der Pipelineaktivität.
Diese Aktivität ist nützlich für Migrationsszenarien, in denen Sie über viele ADF-Pipelines verfügen, die ADF-spezifische Features wie Zuordnen von Datenflüssen oder SSIS verwenden. Sie können diese Pipelines wie in ADF- oder sogar Synapse-Pipelines verwalten und diese Pipeline dann über die neue Fabric Data Factory-Pipeline inline aufrufen, indem Sie die Aufrufpipelineaktivität verwenden und auf die Remote-Factorypipeline verweisen.
Beispielmigrationsszenarien
Die folgenden Szenarien sind häufige Migrationsszenarien, die beim Migrieren von ADF zu Fabric Data Factory auftreten können.
Szenario Nr. 1: ADF-Pipelines und Datenflüsse
Die primären Anwendungsfälle für Factorymigrationen basieren auf der Modernisierung Ihrer ETL-Umgebung vom PaaS-Modell der ADF-Factory auf das neue Fabric SaaS-Modell. Die zu migrierenden primären Factoryelemente sind Pipelines und Datenflüsse. Es gibt mehrere grundlegende Factoryelemente, die Sie für die Migration außerhalb dieser beiden Elemente auf oberster Ebene planen müssen: verknüpfte Dienste, Integrationslaufzeiten, Datasets und Trigger.
- Verknüpfte Dienste müssen in Fabric als Verbindungen in Ihren Pipelineaktivitäten neu erstellt werden.
- Datasets sind in Factory nicht verfügbar. Die Eigenschaften Ihrer Datasets werden als Eigenschaften innerhalb von Pipelineaktivitäten wie "Kopieren" oder "Nachschlagen" dargestellt, während Connections andere Dataseteigenschaften enthalten.
- Integrationslaufzeiten sind in Fabric nicht vorhanden. Ihre selbst gehosteten IRs können jedoch mithilfe von lokalen Datengateways (OPDG) in Fabric und IRs von Azure Virtual Network als verwaltete virtuelle Netzwerkgateways in Fabric neu erstellt werden.
- Diese ADF-Pipelineaktivitäten sind nicht in Fabric Data Factory enthalten:
- Data Lake Analytics (U-SQL) – Dieses Feature ist ein veralteter Azure-Dienst.
- Überprüfungsaktivität – Die Überprüfungsaktivität in ADF ist eine Hilfsaktivität, die Sie in Ihren Fabric-Pipelines ganz einfach mithilfe einer Get Metadata-Aktivität, einer Pipelineschleife und einer If-Aktivität neu erstellen können.
- Power Query – In Fabric werden alle Datenflüsse mithilfe der Power Query-Benutzeroberfläche erstellt, sodass Sie einfach Ihren M-Code aus Ihren ADF-Power Query-Aktivitäten kopieren und einfügen und als Datenflüsse in Fabric erstellen können.
- Wenn Sie eine der ADF-Pipelinefunktionen verwenden, die in Fabric Data Factory nicht gefunden werden, verwenden Sie die Aufrufpipelineaktivität in Fabric, um Ihre vorhandenen Pipelines in ADF aufzurufen.
- Die folgenden ADF-Pipelineaktivitäten werden in eine Einzelzweckaktivität zusammengefasst:
- Azure Databricks-Aktivitäten (Notizbuch, Jar, Python)
- Azure HDInsight (Hive, Pig, MapReduce, Spark, Streaming)
Die folgende Abbildung zeigt die Konfigurationsseite des ADF-Datasets mit den Dateipfad- und Komprimierungseinstellungen:
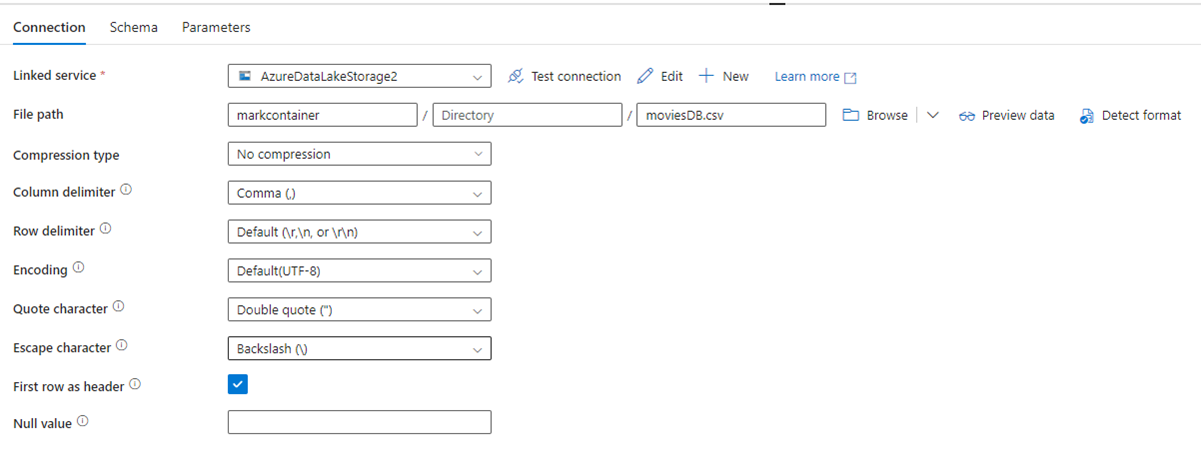
Die folgende Abbildung zeigt die Konfiguration der Kopieraktivität für Data Factory in Fabric, wobei die Komprimierung und der Dateipfad direkt in die Aktivität integriert sind.
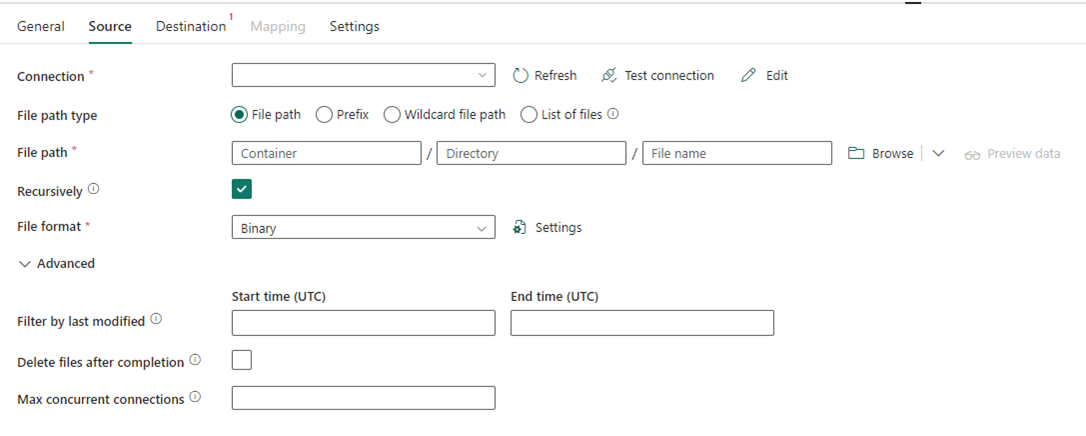
Szenario Nr. 2: ADF mit CDC, SSIS und Airflow
CDC & Airflow in ADF sind Vorschaufeatures, während SSIS in ADF seit vielen Jahren ein allgemein verfügbares Feature ist. Jedes dieser Features erfüllt unterschiedliche Anforderungen an die Datenintegration, erfordert jedoch besondere Aufmerksamkeit bei der Migration von ADF zu Fabric. Change Data Capture (CDC) ist ein ADF-Konzept der obersten Ebene, in Fabric wird diese Funktion jedoch als Kopierauftrag angezeigt.
Airflow ist das cloudverwaltete Apache Airflow-Feature von ADF und ist auch in Fabric Data Factory verfügbar. Sie sollten in der Lage sein, das gleiche Airflow-Quell-Repository zu verwenden oder Ihre DAGs zu übernehmen und den Code in das Fabric Airflow-Angebot mit wenig bis zu keiner Änderung einzufügen.
Szenario Nr. 3: Git-fähige Data Factory-Migration zu Fabric
Es ist üblich, obwohl nicht erforderlich, dass Ihre ADF- oder Synapse-Fabriken und -Arbeitsbereiche mit Ihrem eigenen externen Git-Anbieter in ADO oder GitHub verbunden sind. In diesem Szenario müssen Sie Ihre Werks- und Arbeitsbereichselemente zu einem Fabric-Arbeitsbereich migrieren und dann die Git-Integration in Ihren Fabric-Arbeitsbereich einrichten.
Fabric bietet zwei primäre Möglichkeiten zum Aktivieren von CI/CD auf Arbeitsbereichsebene: Git-Integration, bei der Sie Ihr eigenes Git-Repository in ADO mitbringen und über Fabric eine Verbindung damit herstellen können; und integrierte Bereitstellungspipelines, in denen Sie Code in höhere Umgebungen befördern können, ohne dass Sie ein eigenes Git-Repository bereitstellen müssen.
In beiden Fällen funktioniert Ihr vorhandenes Git-Repository von ADF nicht mit Fabric. Stattdessen müssen Sie auf ein neues Repository verweisen oder eine neue Bereitstellungspipeline in Fabric starten und Ihre Pipelineartefakte in Fabric neu erstellen.
Einbinden Ihrer vorhandenen ADF-Instanzen direkt in einen Fabric-Arbeitsbereich
Zuvor wurde die Verwendung der Aktivität zum Aufrufen einer Pipeline in Fabric Data Factory als Mechanismus zur Aufrechterhaltung bestehender ADF-Pipeline-Investitionen erläutert und wie diese inline über Fabric aufgerufen werden können. Innerhalb von Fabric können Sie dieses ähnliche Konzept einen Schritt weiterführen und die gesamte Fabrik in Ihrem Fabric-Arbeitsbereich als ein einheimisches Fabric-Element einbinden.
Weitere Informationen zu Verwendungsszenarios finden Sie unter Szenarios für die Zusammenarbeit und Bereitstellung von Inhalten.
Die Bereitstellung Ihrer Azure Data Factory in Ihrem Fabric-Arbeitsbereich bringt viele Vorteile in Betracht. Wenn Sie noch nicht mit Fabric arbeiten und Ihre Fabriken im selben Glasbereich nebeneinander halten möchten, können Sie sie in Fabric einbinden, damit Sie beide innerhalb von Fabric verwalten können. Die vollständige ADF-Benutzeroberfläche ist jetzt über Ihre eingebundene Factory verfügbar, in der Sie Ihre ADF-Factoryelemente vollständig über den Fabric-Arbeitsbereich überwachen, verwalten und bearbeiten können. Dieses Feature vereinfacht den Migrationsstart dieser Elemente in Fabric als native Fabric-Artefakte. Dieses Feature dient in erster Linie der benutzerfreundlichen Verwendung und erleichtert das Anzeigen Ihrer ADF-Fabriken in Ihrem Fabric-Arbeitsbereich. Die tatsächliche Ausführung der Pipelines, Aktivitäten, Integrationslaufzeiten usw. erfolgt jedoch weiterhin innerhalb Ihrer Azure-Ressourcen.
Verwandte Inhalte
Überlegungen zur Migration von ADF zu Data Factory in Fabric