Preise für Data Factory in Microsoft Fabric
Data Factory in Microsoft Fabric bietet serverlose und elastische Datenintegrationsdienstfunktionen, die für die Cloudebene entwickelt wurden. Es gibt keine feste Rechenleistung, die Sie für Spitzenlasten einplanen müssen. Vielmehr müssen Sie beim Erstellen von Pipelines und Datenflüssen angeben, welche Vorgänge durchgeführt werden sollen, was sich in der Menge der verbrauchten Fabric-Kapazitätseinheiten niederschlägt, die Sie mit der Microsoft Fabric-Kapazitätsmetriken-App weiter verfolgen können, um Ihre Verbrauchsmetriken zu planen und zu verwalten. Auf diese Weise können Sie die ETL-Prozesse wesentlich skalierbarer gestalten. Außerdem wird Data Factory, wie andere Fabric-Umgebungen, auf Basis eines verbrauchsbasierten Plans abgerechnet, sodass Sie nur für die tatsächliche Nutzung bezahlen.
Microsoft Fabric-Kapazitäten
Fabric ist eine einheitliche Datenplattform, die gemeinsame Erfahrungen, Architektur, Governance, Compliance und Abrechnung bietet. Die Kapazitäten liefern die Rechenleistung, die all diese Erfahrungen ermöglicht. Sie bieten eine einfache und einheitliche Möglichkeit, Ressourcen entsprechend der Kundennachfrage zu skalieren, und können mit einem SKU-Upgrade problemlos erweitert werden.
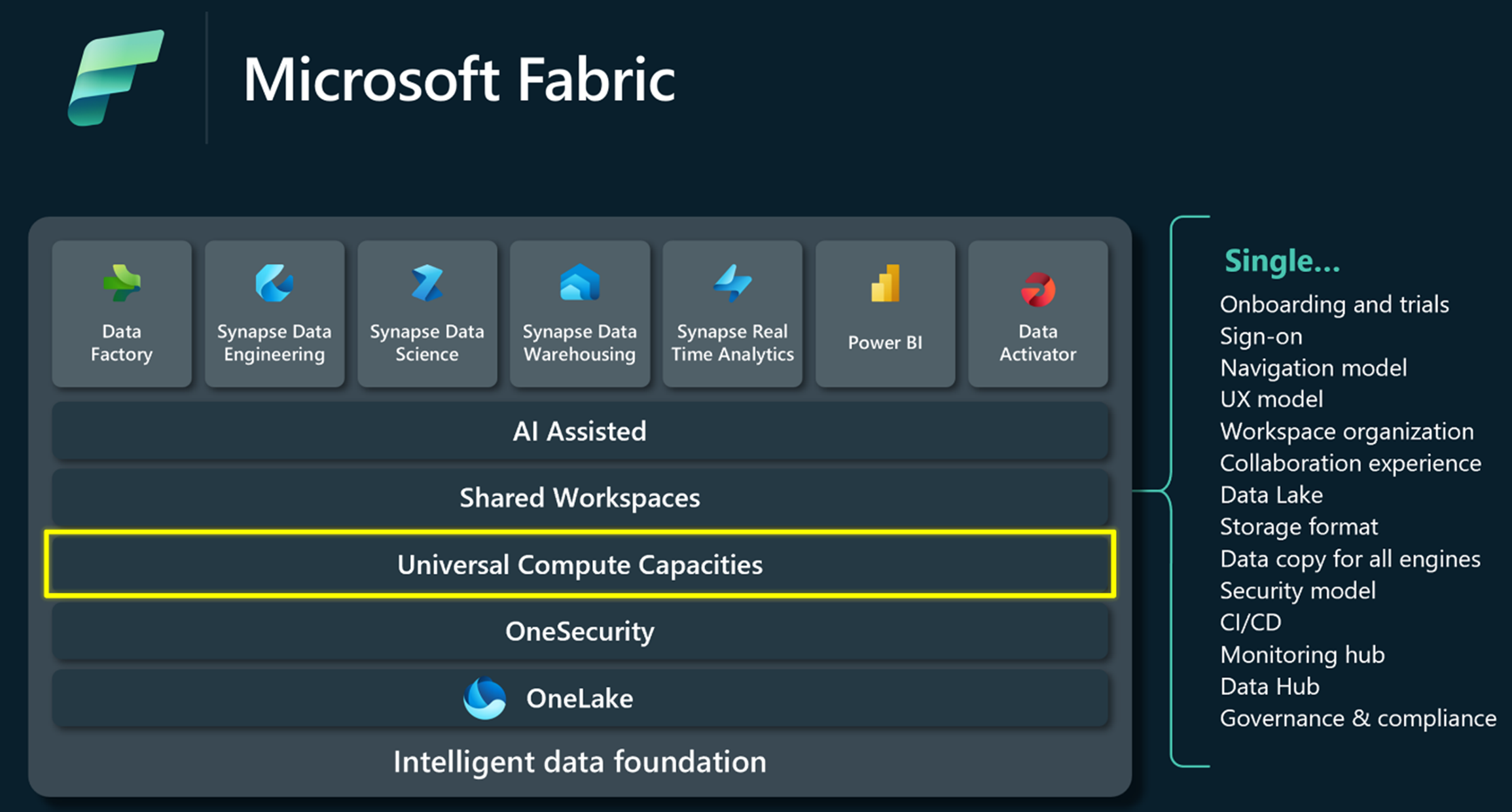
Sie können ihre Fabric Data Factory-Ausführungskosten problemlos mit vereinfachter Abrechnung verwalten. Zusätzliche Benutzer erfordern keine Kostenverwaltung pro Benutzer, und Sie können Geld sparen, indem Sie die Fabric-Kapazitäten für Ihre Datenintegrationsprojekte im Voraus planen und festlegen. Mit der nutzungsbasierten Option können Sie Ihre Kapazitäten ganz einfach nach oben und unten skalieren, um die Rechenleistung anzupassen und die Kapazitäten zu pausieren, wenn sie nicht gebraucht werden, um Kosten zu sparen. Erfahren Sie mehr über Fabric-Kapazitäten und verbrauchsbasierte Abrechnung.
Data Factory-Preise für Verbrauchseinheiten
Ganz gleich, ob Sie ein Citizen Developer oder professioneller Entwickler sind, mit Data Factory können Sie Datenintegrationslösungen auf Unternehmensniveau mit Dataflows und Datenpipelines der nächsten Generation entwickeln. Diese Erfahrungen laufen auf mehreren Diensten mit unterschiedlichen Kapazitätseinheiten. Datenpipelines verwenden die Verbrauchseinheiten Datenorchestrierung und Datenverschiebung, während Dataflow Gen2 Standard Compute und High Scale Compute verwendet. Wie bei anderen Fabric-Oberflächen ist die übliche Verbrauchseinheit für den Speicherverbrauch OneLake Storage.

Preisbeispiele
Hier sind einige Beispielszenarien für die Preisgestaltung von Datenpipelines:
- Laden von 1-TB-Parquet in ein Data Warehouse
- Laden von 1-TB-Parquet in ein Data Warehouse über Staging
- Laden von 1-TB-CSV-Dateien in eine Lakehouse-Tabelle
- Laden von 1-TB-CSV-Dateien in eine Lakehouse-Datei mit binärer Kopie
- Laden von 1-TB-Parquet in eine Lakehouse-Tabelle
Hier sind einige Preisbeispiele für Dataflow Gen2:
- Laden von lokaler 2-GB-CSV-Datei in eine Lakehouse-Tabelle
- Laden von 2-GB-Parquet in eine Lakehouse-Tabelle