Parquet-Format in Data Factory in Microsoft Fabric
In diesem Artikel wird erläutert, wie Sie das Parquet-Format in der Datenpipeline von Data Factory in Microsoft Fabric konfigurieren.
Unterstützte Funktionen
Das Parquet-Format wird für die folgenden Aktivitäten und Connectors als Quelle und Ziel unterstützt.
| Kategorie | Connector/Aktivität |
|---|---|
| Unterstützter Connector | Amazon S3 |
| Amazon S3 Compatible | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| Dateisystem | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Lakehouse-Dateien | |
| Oracle Cloud Storage | |
| SFTP | |
| Unterstützte Aktivität | Kopieraktivität (Quelle/Ziel) |
| Lookup-Aktivität | |
| GetMetadata-Aktivität | |
| Delete-Aktivität |
Parquet-Format in Copy-Aktivität
Um das Parquet-Format zu konfigurieren, wählen Sie Ihre Verbindung in der Quelle oder im Ziel der Datenpipeline-Copy-Aktivität und anschließend die Option Parquet in der Dropdownliste Dateiformat aus. Wählen Sie für die weitere Konfiguration dieses Formats Einstellungen aus.
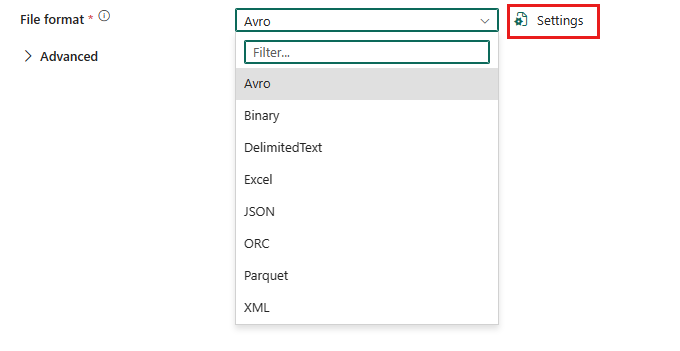
Parquet-Format als Quelle
Nachdem Sie im Abschnitt Dateiformat die Option Einstellungen ausgewählt haben, werden die folgenden Eigenschaften im Popupdialogfeld Dateiformateinstellungen angezeigt.
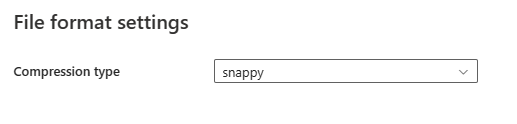
- Komprimierungstyp: Wählen Sie im Dropdownmenü den Codec für die Komprimierung aus, der zum Lesen von Parquet-Dateien verwendet wird. Sie haben folgende Auswahlmöglichkeiten: Keine, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2) oder lz4hadoop.
Parquet-Format als Ziel
Nach Auswahl von Einstellungen werden die folgenden Eigenschaften im Popupdialogfeld Dateiformateinstellungen angezeigt.
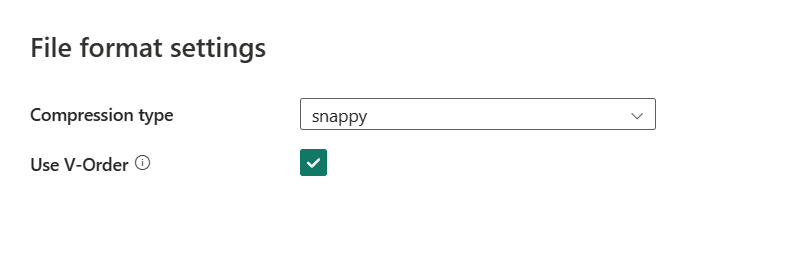
Komprimierungstyp: Wählen Sie im Dropdownmenü den Codec für die Komprimierung aus, der zum Schreiben von Parquet-Dateien verwendet wird. Sie haben folgende Auswahlmöglichkeiten: Keine, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2) oder lz4hadoop.
V-Reihenfolge verwenden: Aktiviert eine Optimierung der Schreibzeit für das Parquet-Dateiformat. Weitere Informationen finden Sie unter Delta Lake-Tabellenoptimierung und V-Reihenfolge. Sie ist standardmäßig aktiviert.
Auf der Registerkarte Ziel werden in den Einstellungen Erweitert die folgenden Eigenschaften zum Parquet-Format angezeigt.
- Max. Anzahl Zeilen pro Datei: Wenn Sie Daten in einen Ordner schreiben, können Sie wahlweise in mehrere Dateien schreiben und die maximale Anzahl von Zeilen pro Datei angeben. Geben Sie die maximalen Anzahl von Zeilen an, die Sie pro Datei schreiben möchten.
- Dateinamenpräfix: Wird angewendet, wenn Max. Anzahl Zeilen pro Datei konfiguriert ist. Geben Sie das Dateinamenpräfix beim Schreiben von Daten in mehrere Dateien an, das zu diesem Muster führt:
<fileNamePrefix>_00000.<fileExtension>. Wenn keine Angabe erfolgt, wird das Dateinamenpräfix automatisch generiert. Diese Eigenschaft wird nicht angewendet, wenn die Quelle ein dateibasierter Speicher oder ein Datenspeicher mit aktivierter Partitionsoption ist.
Tabellenzusammenfassung
Parquet als Quelle
Die folgenden Eigenschaften werden im Abschnitt Quelle der Copy-Aktivität unterstützt, wenn das Parquet-Format verwendet wird.
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Dateiformat | Das Dateiformat aus, das Sie verwenden möchten. | Parquet | Ja | Typ (unter datasetSettings):Parquet |
| Komprimierungstyp | Der zum Lesen von Parquet-Dateien verwendete Codec für die Komprimierung. | Folgende Optionen stehen zur Auswahl: None gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
Nein | compressionCodec: gzip snappy lzo Brotli zstd lz4 lz4frame bz2 lz4hadoop |
Parquet als Ziel
Die folgenden Eigenschaften werden im Abschnitt Ziel der Copy-Aktivität unterstützt, wenn das Parquet-Format verwendet wird.
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Dateiformat | Das Dateiformat aus, das Sie verwenden möchten. | Parquet | Ja | Typ (unter datasetSettings):Parquet |
| V-Reihenfolge verwenden | Aktiviert eine Optimierung der Schreibzeit für das Parquet-Dateiformat. | Aktiviert oder deaktiviert | Nein | enableVertiParquet |
| Komprimierungstyp | Der zum Schreiben von Parquet-Dateien verwendete Codec für die Komprimierung. | Folgende Optionen stehen zur Auswahl: None gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
Nein | compressionCodec: gzip snappy lzo Brotli zstd lz4 lz4frame bz2 lz4hadoop |
| Max. Anzahl Zeilen pro Datei | Wenn Sie Daten in einen Ordner schreiben, können Sie wahlweise in mehrere Dateien schreiben und die maximale Anzahl von Zeilen pro Datei angeben. Geben Sie die maximalen Anzahl von Zeilen an, die Sie pro Datei schreiben möchten. | <Ihr Wert für die max. Zeilenzahl pro Datei> | Nein | maxRowsPerFile |
| Dateinamenpräfix | Wird angewendet, wenn Max. Anzahl Zeilen pro Datei konfiguriert ist. Geben Sie das Dateinamenpräfix beim Schreiben von Daten in mehrere Dateien an, das zu diesem Muster führt: <fileNamePrefix>_00000.<fileExtension>. Wenn keine Angabe erfolgt, wird das Dateinamenpräfix automatisch generiert. Diese Eigenschaft wird nicht angewendet, wenn die Quelle ein dateibasierter Speicher oder ein Datenspeicher mit aktivierter Partitionsoption ist. |
<Ihr Dateinamenpräfix> | Nein | fileNamePrefix |