Konfigurieren der Azure SQL-Datenbank in einer Kopieraktivität
In diesem Artikel wird beschrieben, wie Sie die Kopieraktivität in der Datenpipeline verwenden, um Daten aus und in die Azure SQL-Datenbank zu kopieren.
Unterstützte Konfiguration
Informationen zur Konfiguration der einzelnen Registerkarten unter der Kopieraktivität finden Sie in den folgenden Abschnitten.
Allgemein
Informationen zum Konfigurieren der Registerkarte Allgemein finden Sie unter Allgemeine Einstellungen.
Quelle
Die folgenden Eigenschaften werden für Azure SQL-Datenbank unter der Registerkarte Quelle einer Kopieraktivität unterstützt.

Die folgenden Eigenschaften sind erforderlich:
- Datenspeichertyp: Wählen Sie Externaus.
- Verbindung: Wählen Sie eine Azure SQL-Datenbankverbindung aus der Verbindungsliste aus. Wenn die Verbindung nicht vorhanden ist, erstellen Sie eine neue Azure SQL-Datenbankverbindung, indem Sie Neueauswählen.
- Verbindungstyp: Wählen Sie Azure SQL-Datenbankaus.
- Tabelle: Wählen Sie die Tabelle in Ihrer Datenbank aus der Dropdownliste aus. Sie können auch Bearbeiten aktivieren, um den Tabellennamen manuell einzugeben.
- Vorschaudaten: Wählen Sie Vorschaudaten aus, um eine Vorschau der Daten in der Tabelle anzuzeigen.
Unter Advancedkönnen Sie die folgenden Felder angeben:
Abfrage-verwenden: Sie können Tabelle, Abfrage-oder gespeicherte Prozedurauswählen. In der folgenden Liste wird die Konfiguration jeder Einstellung beschrieben:
Tabelle: Wenn Sie diese Schaltfläche auswählen, lesen Sie Daten aus der Tabelle, die Sie in Tabelle angegeben haben.
Abfrage: Geben Sie die benutzerdefinierte SQL-Abfrage zum Lesen der Daten an. Ein Beispiel ist
select * from MyTable. Oder wählen Sie das Bleistiftsymbol aus, das im Code-Editor bearbeitet werden soll.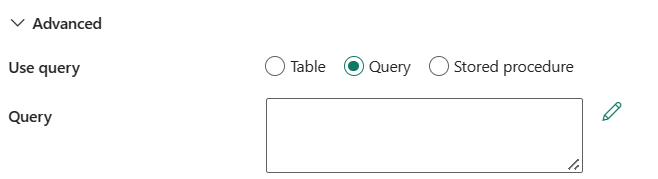
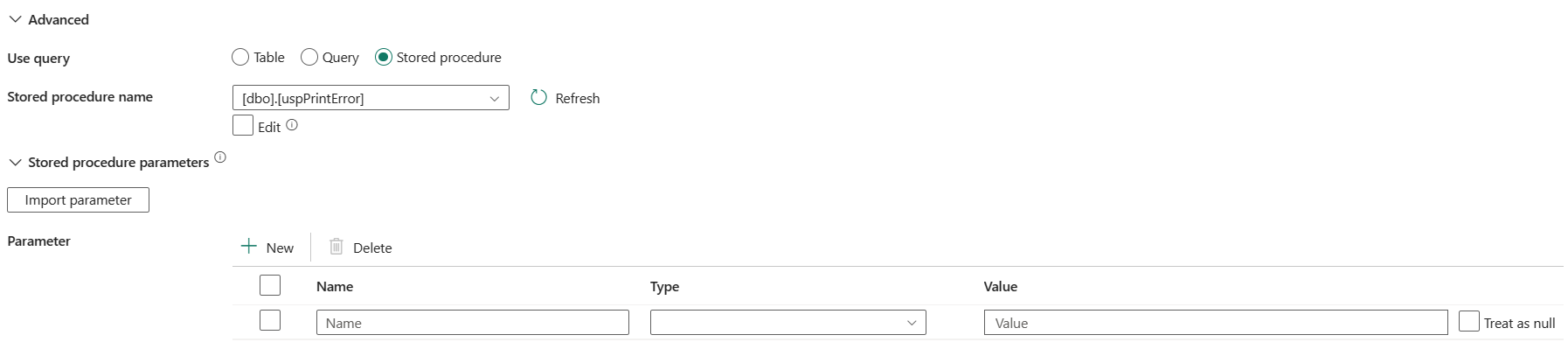
Gespeicherte Prozedur: Verwenden Sie die gespeicherte Prozedur, die Daten aus der Quelltabelle liest. Die letzte SQL-Anweisung muss eine SELECT-Anweisung in der gespeicherten Prozedur sein.
Name der gespeicherten Prozedur: Wählen Sie die gespeicherte Prozedur aus, oder geben Sie den Namen der gespeicherten Prozedur manuell an, wenn Sie das Kontrollkästchen bearbeiten, um Daten aus der Quelltabelle zu lesen.
Parameter für gespeicherte Prozeduren: Geben Sie Werte für gespeicherte Prozedurparameter an. Zulässige Werte sind Name- oder Wertpaare. Die Namen und die Groß-/Kleinschreibung von Parametern müssen den Namen und der Groß-/Kleinschreibung der Parameter der gespeicherten Prozedur entsprechen.
Abfragetimeout (Minuten): Geben Sie den Timeout für die Ausführung des Abfragebefehls an, der Standardwert ist 120 Minuten. Wenn für diese Eigenschaft ein Parameter festgelegt ist, sind zulässige Werte Zeitbereich, z. B. "02:00:00" (120 Minuten).
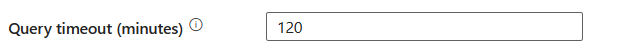
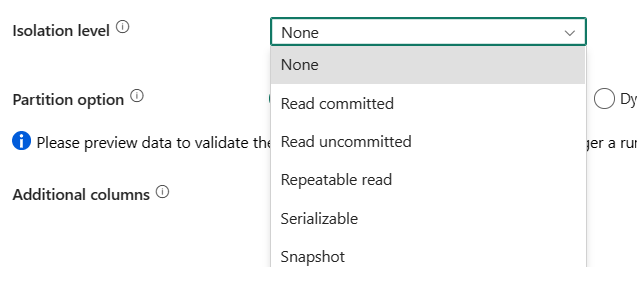
Isolationsebene: Gibt das Transaktionssperrverhalten für die SQL-Quelle an. Zulässige Werte sind: None, ReadCommitted, ReadUncommitted, RepeatableRead, Serializable oder Snapshot. Wenn der Wert nicht angegeben ist, wird die Isolationsstufe None verwendet. Weitere Informationen finden Sie unter IsolationLevel-Enumeration.
Partitionsoption: Geben Sie die Datenpartitionierungsoptionen an, die zum Laden von Daten aus der Azure SQL-Datenbank verwendet werden. Zulässige Werte sind: Keine (Standard), Physische Partitionen von Tabellen, und Dynamischer Bereich. Wenn eine Partitionsoption aktiviert ist (d. h. nicht Keine), wird der Grad der Parallelität zum gleichzeitigen Laden von Daten aus einer Azure SQL-Datenbank durch die parallele Kopie Einstellung für die Kopieraktivität gesteuert.

Keine: Wählen Sie diese Einstellung aus, um keine Partition zu verwenden.
Physische Partitionen der Tabelle: Wenn Sie eine physische Partition verwenden, werden die Partitionsspalte und der Mechanismus automatisch basierend auf Ihrer physischen Tabellendefinition bestimmt.
Dynamischer Bereich: Wenn Sie eine Abfrage mit parallel aktivierter Funktion verwenden, ist der Bereichspartitionsparameter(
?DfDynamicRangePartitionCondition) erforderlich. Beispielabfrage:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.- Partitionsspaltenname: Geben Sie den Namen der Quellspalte als „integer“ oder „date/datetime“ (
int,smallint,bigint,date,smalldatetime,datetime,datetime2oderdatetimeoffset) an, der bei der Bereichspartitionierung für das parallele Kopieren verwendet wird. Wenn nicht angegeben, wird der Index oder der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet. - Partitionsobergrenze: Geben Sie den maximalen Wert der Partitionsspalte für das Teilen des Partitionsbereichs an. Dieser Wert wird verwendet, um die Partitionsstride zu bestimmen, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen im Tabellen- oder Abfrageergebnis werden partitioniert und kopiert.
- Partitionsuntergrenze: Geben Sie den Mindestwert der Partitionsspalte für das Teilen des Partitionsbereichs an. Dieser Wert wird verwendet, um die Partitionsstride zu bestimmen, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen im Tabellen- oder Abfrageergebnis werden partitioniert und kopiert.
- Partitionsspaltenname: Geben Sie den Namen der Quellspalte als „integer“ oder „date/datetime“ (
Zusätzliche Spalten: Fügen Sie weitere Datenspalten hinzu, um den relativen Pfad oder statischen Wert der Quelldateien zu speichern. Für Letzteres wird ein Ausdruck unterstützt. Weitere Informationen finden Sie unter Hinzufügen zusätzlicher Spalten während des Kopiervorgangs.


Bestimmungsort
Die folgenden Eigenschaften werden für die Azure SQL-Datenbank unter der Registerkarte Ziel einer Kopieraktivität unterstützt.

Die folgenden Eigenschaften sind erforderlich:
- Datenspeichertyp: Wählen Sie Externaus.
- Verbindung: Wählen Sie eine Azure SQL-Datenbankverbindung aus der Verbindungsliste aus. Wenn die Verbindung nicht vorhanden ist, erstellen Sie eine neue Azure SQL-Datenbankverbindung, indem Sie Neueauswählen.
- Verbindungstyp: Wählen Sie Azure SQL-Datenbankaus.
- Tabelle: Wählen Sie die Tabelle in Ihrer Datenbank aus der Dropdownliste aus. Oder wählen Sie Bearbeiten aus, um Ihren Tabellennamen manuell einzugeben.
- Vorschaudaten: Wählen Sie Vorschaudaten aus, um eine Vorschau der Daten in der Tabelle anzuzeigen.
Unter Advancedkönnen Sie die folgenden Felder angeben:
Schreibverhalten: Definiert das Schreibverhalten, wenn die Quelle Dateien aus einem dateibasierten Datenspeicher ist. Sie können Einfügen, Upsert oder Gespeicherte Prozedur auswählen.

Einfügen: Wählen Sie diese Option aus, wenn Ihre Quelldaten Einsätze enthalten.
Upsert: Wählen Sie diese Option aus, wenn Ihre Quelldaten sowohl Einfügungen als auch Aktualisierungen enthalten.
TempDB-verwenden: Geben Sie an, ob eine globale temporäre Tabelle oder physische Tabelle als Zwischentabelle für upsert verwendet werden soll. Standardmäßig verwendet der Dienst die globale temporäre Tabelle als Zwischentabelle, und dieses Kontrollkästchen ist aktiviert.
Benutzer-DB-Schemaauswählen: Wenn das Kontrollkästchen "TempDB verwenden" nicht aktiviert ist, geben Sie das Zwischenschema zum Erstellen einer Zwischentabelle an, wenn eine physische Tabelle verwendet wird.
Anmerkung
Sie müssen über die Berechtigung zum Erstellen und Löschen von Tabellen verfügen. Standardmäßig verwendet eine Zwischentabelle das gleiche Schema wie eine Zieltabelle.
Schlüsselspalten: Geben Sie die Spaltennamen für eindeutige Zeilenidentifikation an. Es kann entweder ein einzelner Schlüssel oder eine Reihe von Tasten verwendet werden. Wenn nicht angegeben, wird der Primärschlüssel verwendet.
Gespeicherte Prozedur: Verwenden Sie die gespeicherte Prozedur, die definiert, wie Quelldaten in eine Zieltabelle angewendet werden. Diese gespeicherte Prozedur wird pro Batch aufgerufen.
Name der gespeicherten Prozedur: Wählen Sie die gespeicherte Prozedur aus, oder geben Sie den Namen der gespeicherten Prozedur manuell an, wenn Sie das Kontrollkästchen bearbeiten, um Daten aus der Quelltabelle zu lesen.
Parameter für gespeicherte Prozeduren: Geben Sie Werte für gespeicherte Prozedurparameter an. Zulässige Werte sind Name- oder Wertpaare. Die Namen und die Groß-/Kleinschreibung von Parametern müssen den Namen und der Groß-/Kleinschreibung der Parameter der gespeicherten Prozedur entsprechen.
Tabellensperre für Masseneinfügung: Wählen Sie Ja oder Nein aus. Verwenden Sie diese Einstellung, um die Kopierleistung während eines Masseneinfügevorgangs in einer Tabelle ohne Index von mehreren Clients zu verbessern. Weitere Informationen finden Sie unter BULK INSERT (Transact-SQL).
Tabellenoption: Gibt an, ob die Zieltabelle automatisch erstellt werden soll, wenn die Tabelle im Quellschema nicht vorhanden ist. Wählen Sie Keine oder Tabelle automatisch erstellen aus. Die automatische Tabellenerstellung wird nicht unterstützt, wenn das Ziel eine gespeicherte Prozedur angibt.
Vorkopierskript: Geben Sie ein Skript für die Kopieraktivität an, das ausgeführt werden soll, bevor bei jeder Ausführung Daten in eine Zieltabelle geschrieben werden. Sie können diese Eigenschaft verwenden, um die vorgeladenen Daten zu bereinigen.
Zeitlimit für Batchschreibvorgang: Geben Sie die Wartezeit an, bis der Batcheinfügevorgang beendet ist, bevor er eine Zeitüberschreitung verursacht. Der zulässige Wert ist „timespan“. Der Standardwert ist "00:30:00" (30 Minuten).
Schreibbatchgröße: Geben Sie die Anzahl der Zeilen an, die in die SQL-Tabelle pro Batch eingefügt werden sollen. Der zulässige Wert ist eine ganze Zahl (Anzahl von Zeilen). Standardmäßig bestimmt der Dienst dynamisch die entsprechende Batchgröße basierend auf der Zeilengröße.
Maximale Anzahl gleichzeitiger Verbindungen: Geben Sie die Obergrenze der gleichzeitigen Verbindungen zum Datenspeicher an, die während des Ausführens der Aktivität hergestellt werden. Geben Sie einen Wert nur an, wenn Sie gleichzeitige Verbindungen einschränken möchten.
Analyse von Leistungsmetriken deaktivieren: Diese Einstellung wird verwendet, um Metriken wie DTU, DWU, RU usw. zu sammeln, um die Optimierung und Empfehlungen der Kopierleistung zu optimieren. Wenn Sie über dieses Verhalten besorgt sind, wählen Sie dieses Kontrollkästchen aus.
Zuordnung
Für die Konfiguration der Registerkarte Zuordnung gilt Folgendes: Wenn Sie keine SQL-Datenbank mit automatischer Tabellenerstellung als Ziel verwenden, wechseln Sie zu Zuordnung.
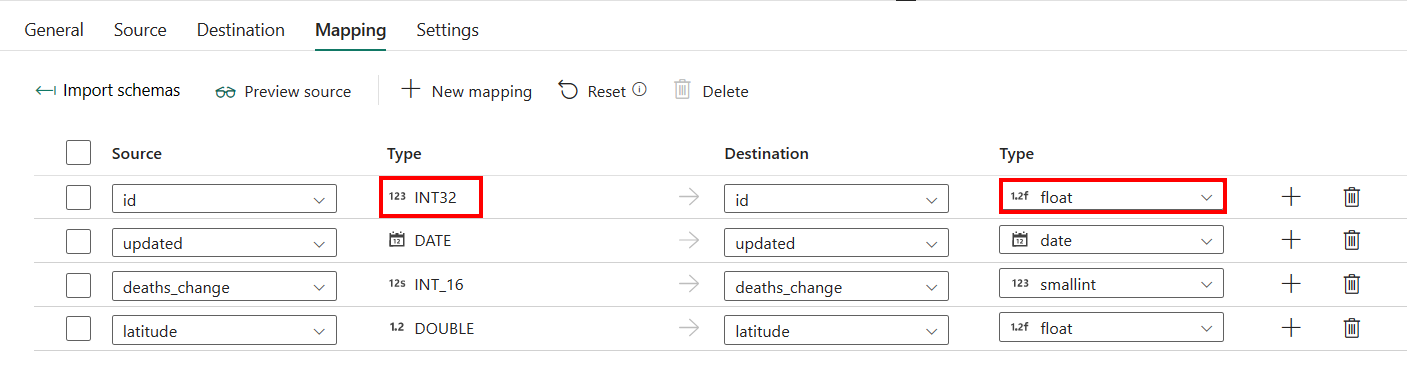
Wenn Sie eine SQL-Datenbank mit automatisch erstellten Tabellen als Ziel verwenden, außer der Konfiguration in Mapping, können Sie den Typ für Ihre Zielspalten bearbeiten. Nachdem Sie Importschemasausgewählt haben, können Sie den Spaltentyp in Ihrem Ziel angeben.
Beispielsweise ist der Typ der Spalte ID in der Quelle int, und Sie können ihn in den Float-Typ ändern, wenn Sie ihn der Zielspalte zuordnen.
Einstellungen
Wechseln Sie für die Konfiguration der Registerkarte Einstellungen zu Konfigurieren der anderen Einstellungen auf der Registerkarte „Einstellungen“.
Parallele Kopie aus Azure SQL-Datenbank
Der Azure SQL-Datenbankkonnektor in Kopieraktivitäten bietet integrierte Datenpartitionierung, um Daten parallel zu kopieren. Sie finden die Optionen für die Datenpartitionierung auf der Registerkarte Quelle der Kopieraktivität.
Wenn Sie partitionierte Kopie aktivieren, führt kopieraktivität parallele Abfragen für Ihre Azure SQL-Datenbankquelle aus, um Daten nach Partitionen zu laden. Der parallele Grad wird durch den Grad der Kopierparallelität auf der Registerkarte "Kopieraktivitätseinstellungen" gesteuert. Wenn Sie z. B. Grad der Kopier parallelität auf vier festlegen, generiert der Dienst gleichzeitig vier Abfragen basierend auf Ihrer angegebenen Partitionsoption und -einstellungen, und jede Abfrage ruft einen Teil von Daten aus Ihrer Azure SQL-Datenbank ab.
Sie werden empfohlen, parallele Kopie mit Datenpartitionierung zu aktivieren, insbesondere wenn Sie eine große Menge von Daten aus Ihrer Azure SQL-Datenbank laden. Im Folgenden werden Konfigurationen für verschiedene Szenarien vorgeschlagen. Beim Kopieren von Daten in einen dateibasierten Datenspeicher wird empfohlen, in einen Ordner als mehrere Dateien zu schreiben (nur den Ordnernamen angeben), in diesem Fall ist die Leistung besser als das Schreiben in eine einzelne Datei.
| Szenario | Vorgeschlagene Einstellungen |
|---|---|
| Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen | Partitionsoption: Physische Partitionen der Tabelle. Während der Ausführung erkennt der Dienst automatisch die physischen Partitionen und kopiert Daten nach Partitionen. Um zu überprüfen, ob Ihre Tabelle physische Partitionen hat oder nicht, können Sie auf diese Abfrageverweisen. |
| Vollständiger Ladevorgang aus einer großen Tabelle, ohne physische Partitionen, aber mit einer Ganzzahlen- oder einer Datumzeit-Spalte für die Datenpartitionierung. | Partitionsoptionen: Partition des dynamischen Bereichs. Partitionsspalte (optional): Geben Sie die Spalte an, die zum Partitionieren von Daten verwendet wird. Ohne Angabe wird der Index oder die Primärschlüsselspalte verwendet. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle, alle Zeilen in der Tabelle werden partitioniert und kopiert. Wenn nicht angegeben, erkennen Kopieraktivitäten die Werte automatisch. Wenn Ihre Partitionsspalte "ID" z. B. Werte von 1 bis 100 aufweist und Sie die untere Grenze auf 20 und die obere Grenze auf 80 festlegen, wobei die Parallelverarbeitung auf 4 gesetzt ist, ruft der Dienst Daten durch 4 Partitionen ab – IDs in den Bereichen <=20, [21, 50], [51, 80] und >=81. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage ohne physische Partitionen, aber mit einer integer- oder date/datetime-Spalte für die Datenpartitionierung. | Partitionsoptionen: Partition des dynamischen Bereichs. Abfrage: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>Partitionsspalte: Geben Sie die Spalte an, die zum Partitionieren von Daten verwendet wird. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle, alle Zeilen im Abfrageergebnis werden partitioniert und kopiert. Wenn nichts angegeben wurde, wird der Wert für die Kopieraktivität automatisch erkannt. Wenn ihre Partitionsspalte "ID" z. B. Werte von 1 bis 100 aufweist und Sie die untere Grenze als 20 und die obere Grenze als 80 festlegen, mit paralleler Kopie als 4, ruft der Dienst Daten nach 4 Partitionen ab– IDs im Bereich <=20, [21, 50], [51, 80] und >=81. Hier sind weitere Beispielabfragen für verschiedene Szenarien: • Abfrage der gesamten Tabelle: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Abfrage aus einer Tabelle mit Spaltenauswahl und zusätzlichen Where-Klausel-Filtern: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Abfrage mit Unterabfragen: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Abfrage mit Partition in Unterabfrage: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Bewährte Methoden zum Laden von Daten mit partitionsoption:
- Wählen Sie eine unverwechselbare Spalte als Partitionsspalte (z. B. Primärschlüssel oder eindeutiger Schlüssel) aus, um Datenverzerrung zu vermeiden.
- Wenn die Tabelle über eine integrierte Partition verfügt, verwenden Sie die Partitionsoption physische Partitionen der Tabelle, um eine bessere Leistung zu erzielen.
Beispielabfrage zum Überprüfen der physischen Partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Wenn die Tabelle eine physische Partition aufweist, wird "HasPartition" wie folgt als "Ja" angezeigt.

Tabellenzusammenfassung
Die folgenden Tabellen enthalten weitere Informationen zur Kopieraktivität in der Azure SQL-Datenbank.
Quelle
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Datenspeichertyp | Ihr Datenspeichertyp. | Extern | Ja | / |
| Verbindung | Ihre Verbindung zum Quelldatenspeicher. | <Ihre Verbindung> | Ja | connection |
| Verbindungstyp | Ihr Verbindungstyp. Wählen Sie Azure SQL-Datenbank aus. | Azure SQL-Datenbank | Ja | / |
| Tabelle | Ihre Quell-Datentabelle. | <Name Ihrer Zieltabelle> | Ja | Schema Tisch |
| Abfrage verwenden | Die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. | •Nichts • Abfrage •Gespeicherte Prozedur |
Nein | • sqlReaderQuery • sqlReaderStoredProcedureName, storedProcedureParameters |
| Abfragetimeout | Das Timeout für die Ausführung des Abfragebefehls beträgt standardmäßig 120 Minuten. | Zeitbereich | Nein | queryTimeout |
| Isolationsstufe | Gibt das Transaktionssperrverhalten für die SQL-Quelle an. | •Nichts • ReadCommitted • ReadUncommitted • RepeatableRead •Serialisierbar •Schnappschuss |
Nein | Isolationsebene |
| Partitionsoption | Die Datenpartitionierungsoptionen zum Laden von Daten aus der Azure SQL-Datenbank. | •Nichts • Physische Partitionen der Tabelle • Dynamikbereich |
Nein | Partitionsoption • PhysicalPartitionsOfTable • DynamicRange |
| Zusätzliche Spalten | Fügen Sie weitere Datenspalten hinzu, um den relativen Pfad oder statischen Wert der Quelldateien zu speichern. Für Letzteres wird ein Ausdruck unterstützt. | • Name •Wert |
Nein | additionalColumns: • Name •Wert |
Bestimmungsort
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Datenspeichertyp | Ihr Datenspeichertyp. | Extern | Ja | / |
| Verbindung | Ihre Verbindung zum Zieldatenspeicher. | <Ihre Verbindung> | Ja | connection |
| Verbindungstyp | Ihr Verbindungstyp. Wählen Sie Azure SQL Databaseaus. | Azure SQL-Datenbank | Ja | / |
| Tabelle | Ihre Zieldatentabelle. | <Name Ihrer Zieltabelle> | Ja | Schema Tisch |
| Schreibverhalten | Definiert das Schreibverhalten, wenn die Quelle Dateien aus einem dateibasierten Datenspeicher ist. | • Einfügen • Upsert •Gespeicherte Prozedur |
Nein | writeBehavior: • Einfügen • Upsert • sqlWriterStoredProcedureName, sqlWriterTableType, storedProcedureParameters |
| Tabellensperre für Masseneinfügung | Verwenden Sie diese Einstellung, um die Kopierleistung während eines Masseneinfügevorgangs in einer Tabelle ohne Index von mehreren Clients zu verbessern. | Ja oder nein | Nein | sqlWriterUseTableLock: wahr oder falsch |
| Tabellenoption | Gibt an, ob die Zieltabelle automatisch erstellt werden soll, wenn sie nicht basierend auf dem Quellschema vorhanden ist. | •Nichts • Automatisches Erstellen einer Tabelle |
Nein | tableOption: • automatisch Erstellen |
| Skript vor Kopiervorgang | Ein Skript für den Kopiervorgang, das ausgeführt werden soll, bevor bei jedem Durchlauf Daten in eine Zieltabelle geschrieben werden. Sie können diese Eigenschaft nutzen, um die vorab geladenen Daten zu bereinigen. | <Skript vor Kopiervorgang> (Zeichenfolge) |
Nein | preCopyScript |
| Zeitlimit für Batchschreibvorgang | Wartezeit für den Abschluss des Batcheinfügevorgangs, bis das Timeout wirksam wird. Der zulässige Wert ist „timespan“. Der Standardwert ist "00:30:00" (30 Minuten). | Zeitbereich | Nein | writeBatchTimeout |
| Schreibbatchgröße | Die Anzahl der Zeilen, die pro Batch in die SQL-Tabelle eingefügt werden sollen. Standardmäßig bestimmt der Dienst dynamisch die entsprechende Batchgröße basierend auf der Zeilengröße. | <Anzahl von Zeilen> (ganze Zahl) |
Nein | writeBatchSize |
| Maximal zulässige Anzahl paralleler Verbindungen | Die obere Grenze der gleichzeitigen Verbindungen, die während der Ausführung der Aktivität mit dem Datenspeicher eingerichtet wurden. Geben Sie einen Wert nur an, wenn Sie gleichzeitige Verbindungen einschränken möchten. | <oberer Grenzwert für gleichzeitige Verbindungen> (ganze Zahl) |
Nein | maxConcurrentConnections |
| Analyse der Leistungsmetriken deaktivieren | Diese Einstellung wird verwendet, um Metriken wie DTU, DWU, RU usw. für die Optimierung der Kopierleistung und Empfehlungen zu sammeln. Wenn Sie über dieses Verhalten besorgt sind, aktivieren Sie dieses Kontrollkästchen. | Aktivieren oder deaktivieren | Nein | disableMetricsCollection: wahr oder falsch |