Transformieren von Daten durch Ausführen einer Azure HDInsight-Aktivität
Mit der Azure HDInsight-Aktivität in Data Factory für Microsoft Fabric können Sie die folgenden Azure HDInsight-Auftragstypen orchestrieren:
- Ausführen von Hive-Abfragen
- Aufrufen eines MapReduce-Programms
- Ausführen von Pig-Abfragen
- Ausführen eines Spark-Programms
- Ausführen eines Hadoop-Stream-Programms
Dieser Artikel enthält eine schrittweise exemplarische Vorgehensweise, in der beschrieben wird, wie Sie eine Azure HDInsight-Aktivität mithilfe der Data Factory-Schnittstelle erstellen.
Voraussetzungen
Um zu beginnen, müssen die folgenden Voraussetzungen erfüllt sein:
- Ein Mandantenkonto mit einem aktiven Abonnement. Sie können kostenlos ein Konto erstellen.
- Ein Arbeitsbereich wurde erstellt.
Hinzufügen einer Azure HDInsight (HDI)-Aktivität zu einer Pipeline mit Benutzeroberfläche
Erstellen Sie eine neue Datenpipeline in Ihrem Arbeitsbereich.
Suchen Sie auf der Karte der Startseite nach Azure HDInsight und wählen Sie es aus, oder wählen Sie die Aktivität in der Leiste Aktivitäten aus, um sie dem Pipeline-Kollaborationsbereich hinzuzufügen.
Erstellen der Aktivität auf der Karte der Startseite:
Erstellen der Aktivität über die Aktivitätsleiste:
Wählen Sie die neue Azure HDInsight-Aktivität auf dem Kollaborationsbereich des Pipeline-Editors aus, wenn sie nicht bereits ausgewählt ist.
Informationen zur Konfiguration der Optionen auf der Registerkarte Allgemeine Einstellungen finden Sie in der Anleitung Allgemeine Einstellungen.

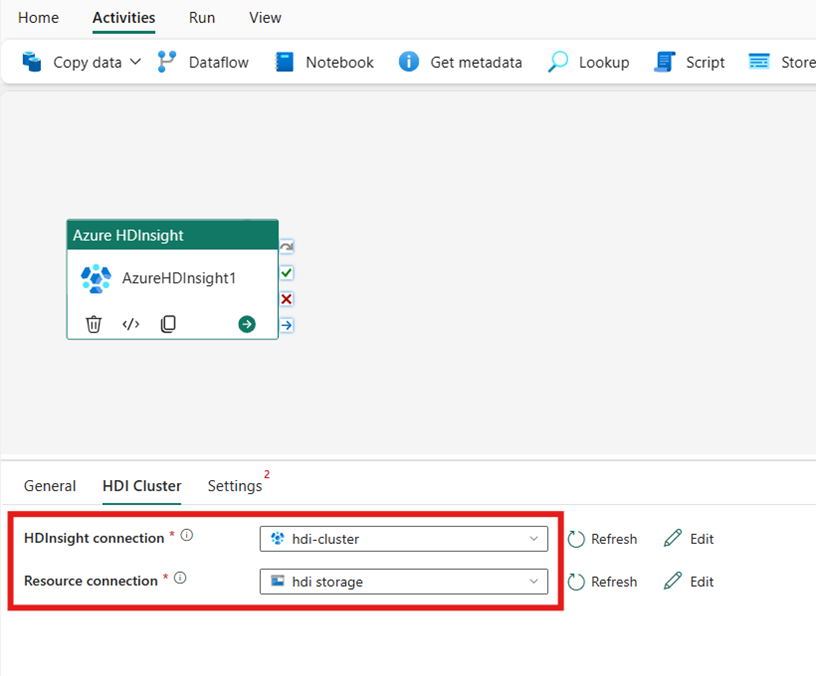
Konfigurieren des HDI-Clusters
Wählen Sie die Registerkarte HDI-Cluster aus. Anschließend können Sie eine vorhandene oder eine neue HDInsight-Verbindung erstellen.
Wählen Sie für die Ressourcenverbindung den Azure Blob Storage aus, der auf Ihren Azure HDInsight-Cluster verweist. Sie können ein vorhandenes Blob Store auswählen oder ein neues erstellen.
Konfigurieren von Einstellungen
Wählen Sie die Registerkarte Einstellungen aus, um die erweiterten Einstellungen für die Aktivität anzuzeigen.
Alle erweiterten Clustereigenschaften und dynamische Ausdrücke, die im verknüpften Azure Data Factory- und Synapse Analytics HDInsight-Dienst unterstützt werden, werden jetzt auch in der Azure HDInsight-Aktivität für Data Factory in Microsoft Fabric unter dem Abschnitt Advanced in der Benutzeroberfläche unterstützt. Diese Eigenschaften unterstützen alle benutzerfreundliche, parametrisierte Ausdrücke mit dynamischem Inhalt.
Clustertyp
Um Einstellungen für Ihren HDInsight-Cluster zu konfigurieren, wählen Sie zuerst den Typ aus den verfügbaren Optionen aus, einschließlich Hive, Map Reduce, Pig, Spark und Streaming.
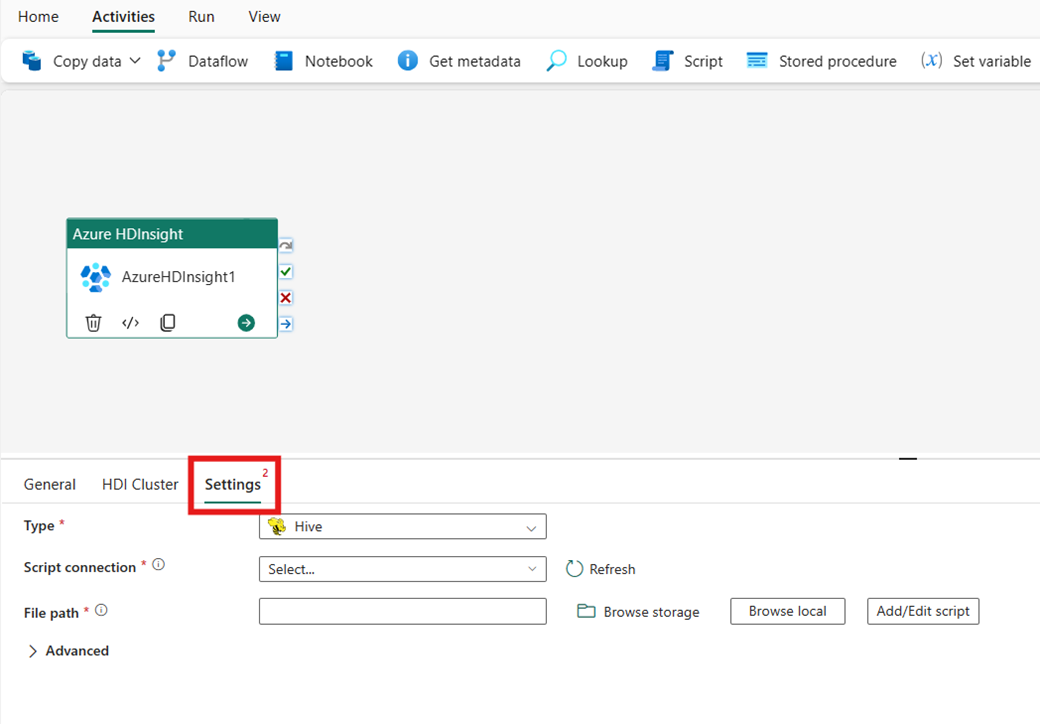
Hive
Wenn Sie Hive für Typ auswählen, führt die Aktivität eine Hive-Abfrage aus. Optional können Sie die Skriptverbindung angeben, die auf ein Speicherkonto verweist, das den Hive-Typ enthält. Standardmäßig wird die Speicherverbindung verwendet, die Sie auf der Registerkarte HDI-Cluster angegeben haben. Sie müssen den Dateipfad angeben, der in Azure HDInsight ausgeführt werden soll. Optional können Sie weitere Konfigurationen im Abschnitt Advanced, Debuginformationen, Abfragetimeout, Argumente, Parameter und Variablen angeben.
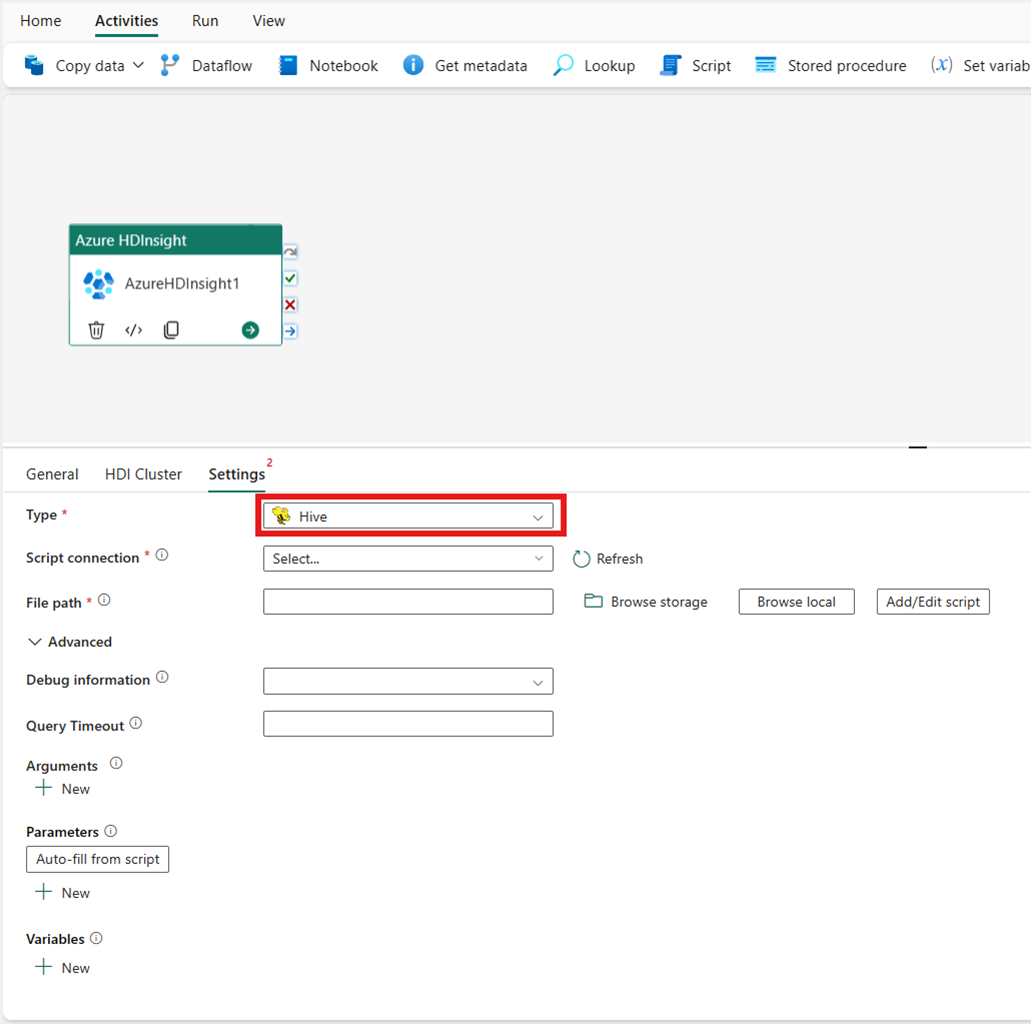
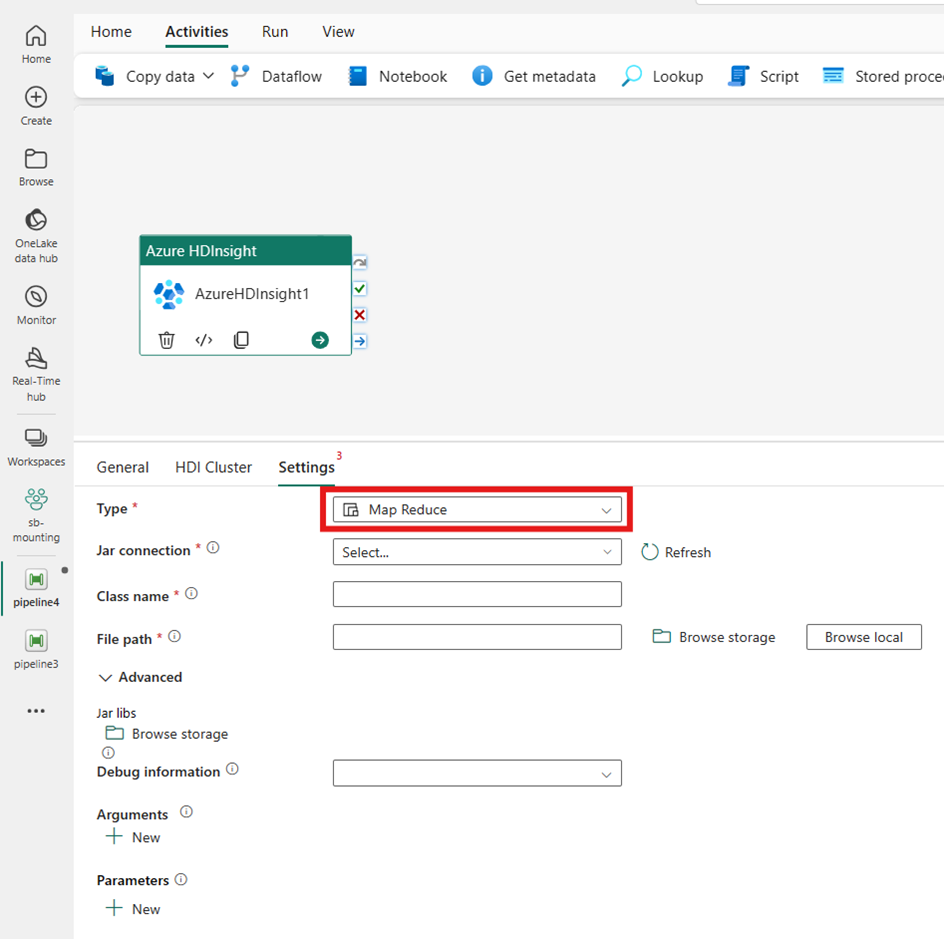
Map Reduce
Wenn Sie Map Reduce für Typ auswählen, ruft die Aktivität ein Map-Reduce-Programm auf. Optional können Sie in der Jar-Verbindung angeben, die auf ein Speicherkonto verweist, das den Map Reduce-Typ enthält. Standardmäßig wird die Speicherverbindung verwendet, die Sie auf der Registerkarte HDI-Cluster angegeben haben. Sie müssen den Klassennamen und Dateipfad angeben, die in Azure HDInsight ausgeführt werden sollen. Optional können Sie im Abschnitt Advanced weitere Konfigurationsdetails angeben, z. B. das Importieren von Jar-Bibliotheken, Debuginformationen, Argumente und Parameter.
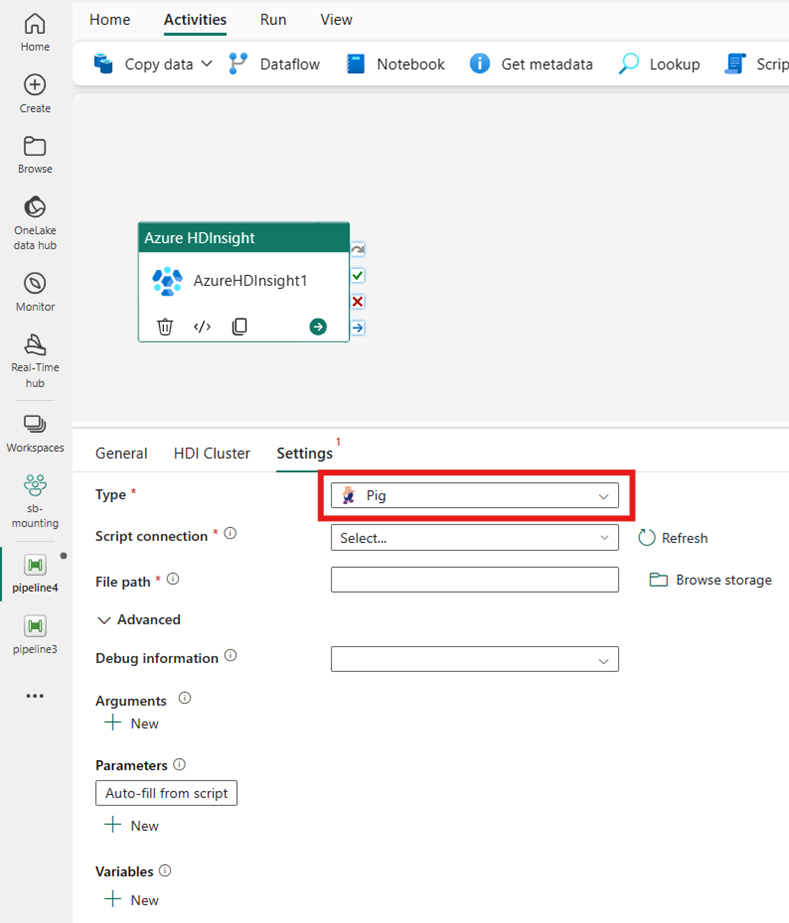
Pig
Wenn Sie Pig für Typ auswählen, ruft die Aktivität eine Pig-Abfrage auf. Optional können Sie die Einstellung für die Skriptverbindung angeben, die auf ein Speicherkonto verweist, das den Pig-Typ enthält. Standardmäßig wird die Speicherverbindung verwendet, die Sie auf der Registerkarte HDI-Cluster angegeben haben. Sie müssen den Dateipfad angeben, der in Azure HDInsight ausgeführt werden soll. Optional können Sie im Abschnitt Advanced weitere Konfigurationen wie Debug-Informationen, Argumente, Parameter und Variablen angeben.
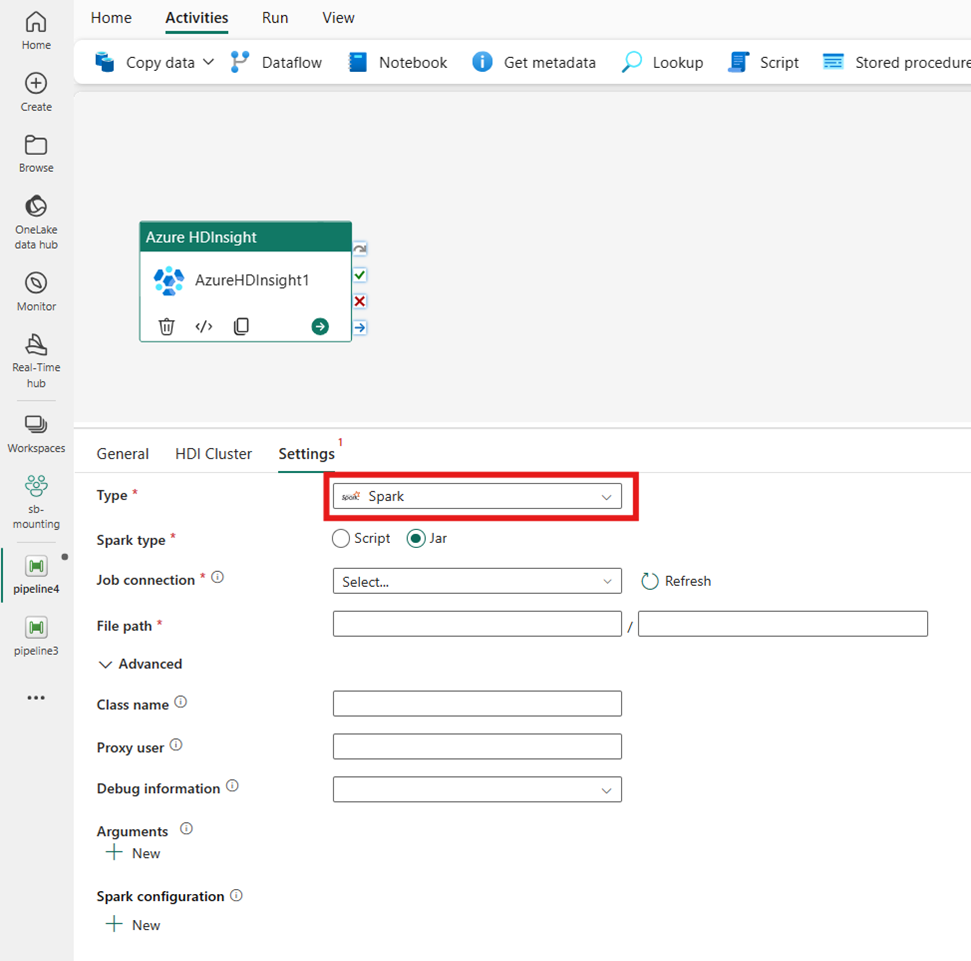
Spark
Wenn Sie Spark für Typ auswählen, ruft die Aktivität ein Spark-Programm auf. Wählen Sie entweder Skript oder Jar für den Spark-Typ aus. Optional können Sie die Jobverbindung angeben, die auf ein Speicherkonto verweist, das den Spark-Typ enthält. Standardmäßig wird die Speicherverbindung verwendet, die Sie auf der Registerkarte HDI-Cluster angegeben haben. Sie müssen den Dateipfad angeben, der in Azure HDInsight ausgeführt werden soll. Optional können Sie weitere Konfigurationen angeben, z. B. Klassenname, Proxy-Benutzer, Debug-Informationen, Argumente und Spark-Konfiguration im Abschnitt Advanced.
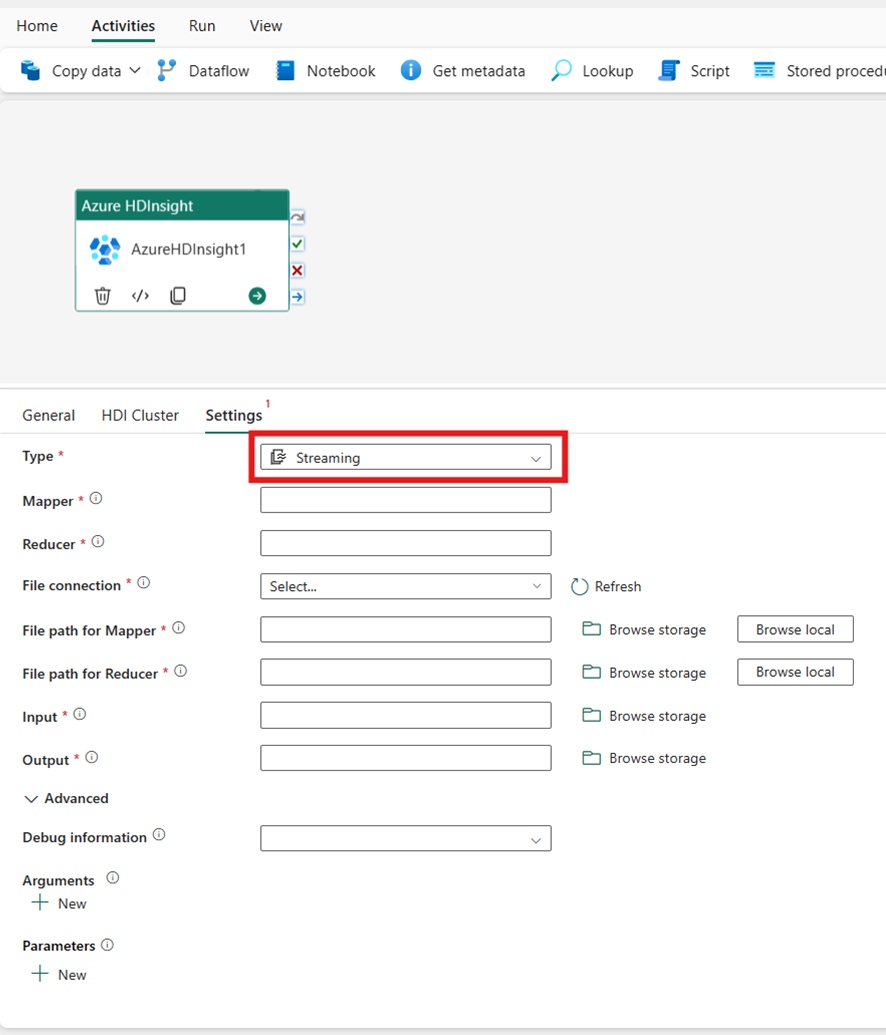
Streaming
Wenn Sie Streaming für Typ auswählen, ruft die Aktivität ein Streaming-Programm auf. Geben Sie die Namen Mapper und Reducer an und Sie können optional die Dateiverbindung angeben, die auf das Speicherkonto verweist, das den Streamingtyp enthält. Standardmäßig wird die Speicherverbindung verwendet, die Sie auf der Registerkarte HDI-Cluster angegeben haben. Sie müssen den Dateipfad für Mapper und den Dateipfad für Reducer angeben, die auf Azure HDInsight ausgeführt werden sollen. Fügen Sie auch die Eingabe- und Ausgabeoptionen für den WASB-Pfad ein. Optional können Sie im Abschnitt Advanced weitere Konfigurationen wie Debug-Informationen, Argumente, Parameter angeben.
Eigenschaftsverweis
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Für die Hadoop-Streamingaktivität ist der Aktivitätstyp „HDInsightStreaming“. | Ja |
| mapper | Gibt den Namen der ausführbaren Zuordnungsdatei (Mapper) an. | Ja |
| reducer | Gibt den Namen der ausführbaren Reduzierungsdatei (Reducer) an. | Ja |
| combiner | Gibt den Namen der ausführbaren Kombinierungsdatei (Combiner) an. | No |
| Dateiverbindung | Verweis auf einen verknüpften Azure Storage-Dienst, der zum Speichern der Mapper-, Combiner- und Reducer-Programme verwendet wird. | No |
| Hier werden nur die Verbindungen von Azure Blob Storage und ADLS Gen2 unterstützt. Wenn Sie diese Verbindung nicht angeben, wird die in der HDInsight-Verbindung definierte Speicherverbindung verwendet. | ||
| filePath | Geben Sie ein Array mit Pfaden zu den Mapper-, Combiner- und Reducer-Programmen an, die im Azure Storage gespeichert sind, auf den die Dateiverbindung verweist. | Ja |
| input | Gibt den WASB-Pfad zur Eingabedatei für den Mapper an. | Ja |
| output | Gibt den WASB-Pfad zur Ausgabedatei für den Reducer an. | Ja |
| getDebugInfo | Gibt an, ob die Protokolldateien in den Azure Storage-Speicher kopiert werden, der vom HDInsight-Cluster verwendet (oder) von „scriptLinkedService“ angegeben wird. | No |
| Zulässige Werte: „None“, „Always“ oder „Failure“. Standardwert: Keine. | ||
| Argumente | Gibt ein Array von Argumenten für einen Hadoop-Auftrag an. Die Argumente werden als Befehlszeilenargumente an jeden Vorgang übergeben. | No |
| defines | Geben Sie Parameter als Schlüssel-Wert-Paare für Verweise innerhalb des Hive-Skripts an. | No |
Speichern und Ausführen oder Planen der Pipeline
Nachdem Sie alle anderen Aktivitäten konfiguriert haben, die für Ihre Pipeline erforderlich sind, wechseln Sie oben im Pipeline-Editor zur Registerkarte Start, und klicken Sie auf die Schaltfläche „Speichern“, um die Pipeline zu speichern. Wählen Sie Ausführen aus, um sie direkt auszuführen, oder Planen, um sie zu planen. Sie können hier auch den Ausführungsverlauf anzeigen oder andere Einstellungen konfigurieren.
