Transformieren von Daten durch Ausführen einer Azure Databricks-Aktivität
Mit der Azure Databricks-Aktivität in Data Factory für Microsoft Fabric können Sie die folgenden Azure Databricks-Aufträge orchestrieren:
- Notebook
- JAR
- Python
Dieser Artikel enthält eine schrittweise exemplarische Vorgehensweise, in der beschrieben wird, wie Sie eine Azure Databricks-Aktivität mithilfe der Data Factory-Benutzeroberfläche erstellen.
Voraussetzungen
Um zu beginnen, müssen die folgenden Voraussetzungen erfüllt sein:
- Ein Mandantenkonto mit einem aktiven Abonnement. Sie können kostenlos ein Konto erstellen.
- Ein Arbeitsbereich wurde erstellt.
Konfigurieren einer Azure Databricks-Aktivität
Führen Sie die folgenden Schritte aus, um eine Azure Databricks-Aktivität in einer Pipeline zu verwenden:
Konfigurieren der Verbindung
Erstellen Sie eine neue Pipeline in Ihrem Arbeitsbereich.
Klicken Sie auf „Pipelineaktivität hinzufügen“, und suchen Sie nach Azure Databricks.
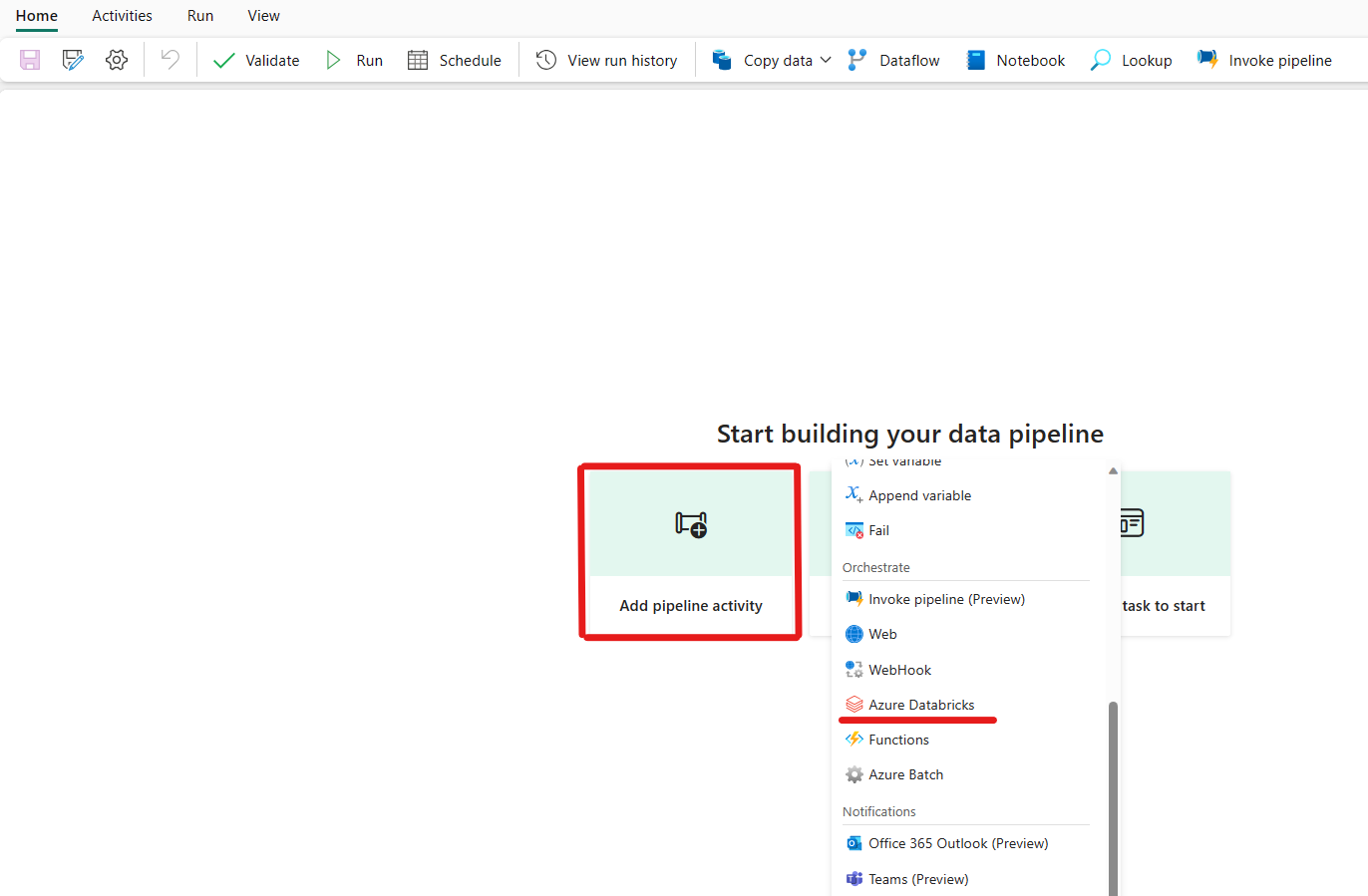
Alternativ können Sie im Bereich Aktivitäten der Pipeline nach Azure Databricks suchen und den Dienst dann auswählen, um ihn der Pipelinecanvas hinzuzufügen.
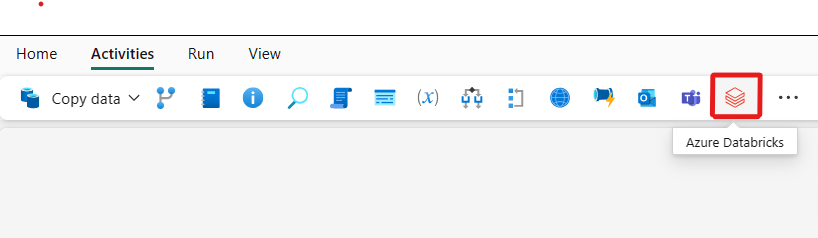
Wählen Sie die neue Azure Databricks-Aktivität auf der Canvas aus, wenn sie noch nicht ausgewählt ist.
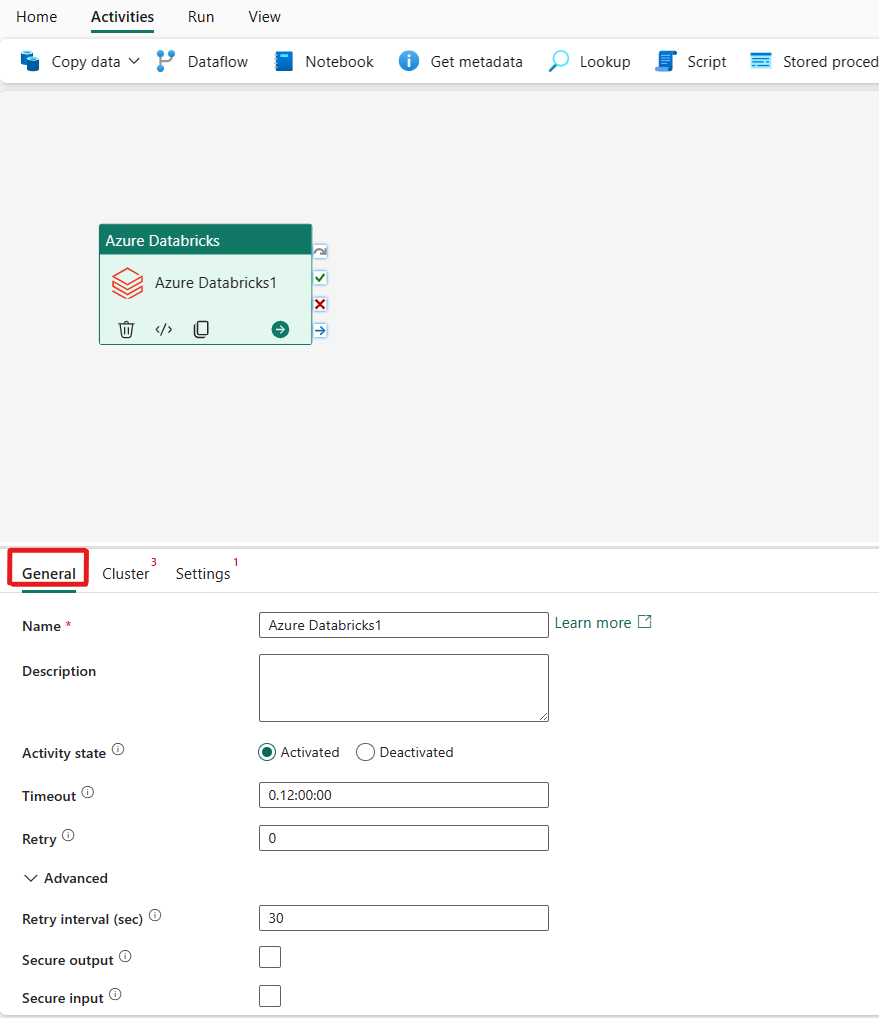
Informationen zum Konfigurieren der Registerkarte Allgemein finden Sie unter Allgemeine Einstellungen.
Konfigurieren von Clustern
Wählen Sie die Registerkarte Cluster aus. Anschließend können Sie eine vorhandene Azure Databricks-Verbindung auswählen oder eine neue erstellen und dann einen neuen Auftragscluster, einen vorhandenen interaktiven Cluster oder einen vorhandenen Instanzpool auswählen.
Abhängig von der für den Cluster ausgewählten Option füllen Sie die entsprechenden Felder wie dargestellt aus.
- Unter Neuer Auftragscluster und Vorhandener Instanzpool können Sie auch die Anzahl der Worker konfigurieren und Spotinstanzen aktivieren.
Sie können auch zusätzliche Clustereinstellungen angeben, wie z. B. Clusterrichtlinie, Spark-Konfiguration, Spark-Umgebungsvariablen und benutzerdefinierte Tags, wie für den Cluster erforderlich, mit dem Sie eine Verbindung herstellen. Databricks-Initialisierungsskripts und ein Zielpfad für Clusterprotokolle können ebenfalls in den zusätzlichen Clustereinstellungen hinzugefügt werden.
Hinweis
Alle erweiterten Clustereigenschaften und dynamische Ausdrücke, die im verknüpften Dienst von Azure Data Factory und Azure Databricks unterstützt werden, werden jetzt auch in der Azure Databricks-Aktivität in Microsoft Fabric unter dem Abschnitt „Zusätzliche Clusterkonfiguration“ in der Benutzeroberfläche unterstützt. Da diese Eigenschaften jetzt in der Benutzeroberfläche der Aktivität enthalten sind, können sie mühelos mit einem Ausdruck (dynamischer Inhalt) verwendet werden, ohne dass die erweiterte JSON-Spezifikation im verknüpften Dienst von Azure Data Factory und Azure Databricks erforderlich ist.
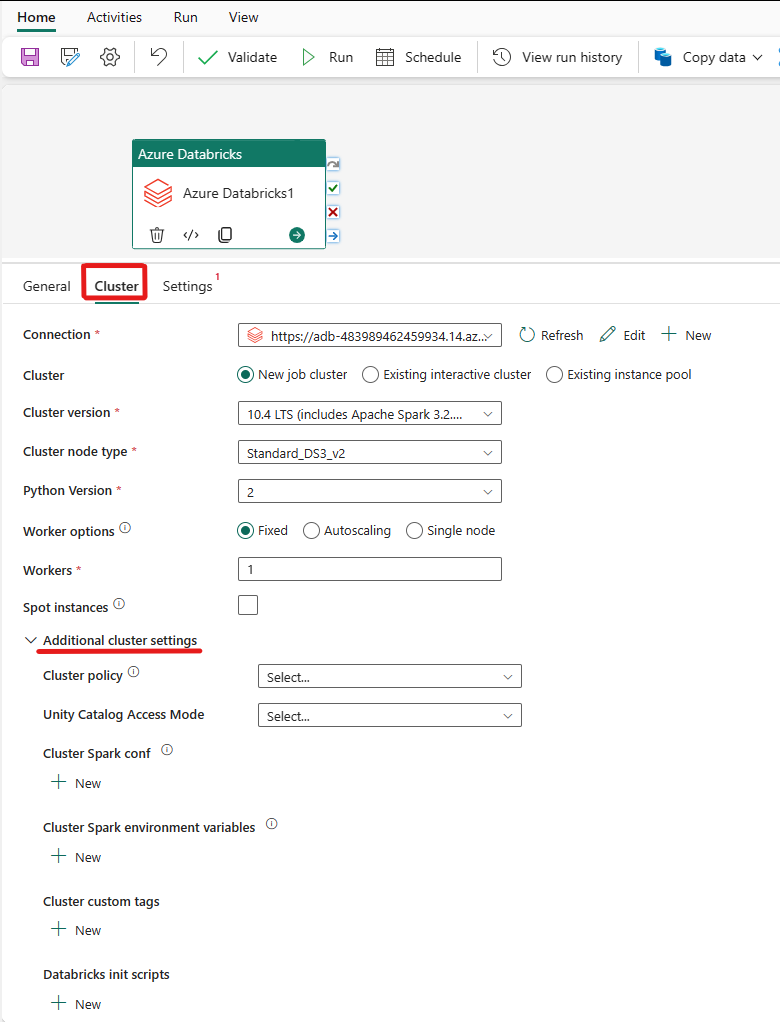
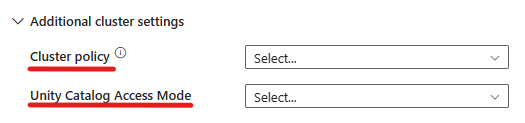
Die Azure Databricks-Aktivität unterstützt jetzt auch die Clusterrichtlinie und den Unity Catalog Support.
- In den erweiterten Einstellungen haben Sie die Möglichkeit, die Clusterrichtlinie auszuwählen, damit Sie angeben können, welche Clusterkonfigurationen zulässig sind.
- Außerdem können Sie in den erweiterten Einstellungen den Unity Catalog-Zugriffsmodus als zusätzliche Sicherheitsmaßnahme konfigurieren. Die verfügbaren Zugriffsmodustypen sind:
- Einzelbenutzerzugriffsmodus Dieser Modus wurde für Szenarien entwickelt, in denen jeder Cluster von einem einzelnen Benutzer verwendet wird. Dadurch wird sichergestellt, dass der Datenzugriff innerhalb des Clusters nur auf diesen Benutzer beschränkt ist. Dieser Modus ist nützlich für Aufgaben, die isolations- und individuelle Datenverarbeitung erfordern.
- Modus für gemeinsam genutzten Zugriff In diesem Modus können mehrere Benutzer auf denselben Cluster zugreifen. Er kombiniert die Data Governance des Unity-Katalogs mit den älteren Zugriffssteuerungslisten (Access Control Lists, ACLs). Dieser Modus ermöglicht den gemeinsamen Datenzugriff, während Governance- und Sicherheitsprotokolle beibehalten werden. Es hat jedoch bestimmte Einschränkungen, z. B. keine Unterstützung von Databricks Runtime ML, Spark-Submit-Aufträgen und spezifische Spark-APIs und UDFs.
- Kein Zugriffsmodus Dieser Modus deaktiviert die Interaktion mit dem Unity-Katalog, was bedeutet, dass Cluster keinen Zugriff auf Daten haben, die vom Unity-Katalog verwaltet werden. Dieser Modus ist für Workloads nützlich, für die die Governance-Features des Unity-Katalogs nicht erforderlich sind.
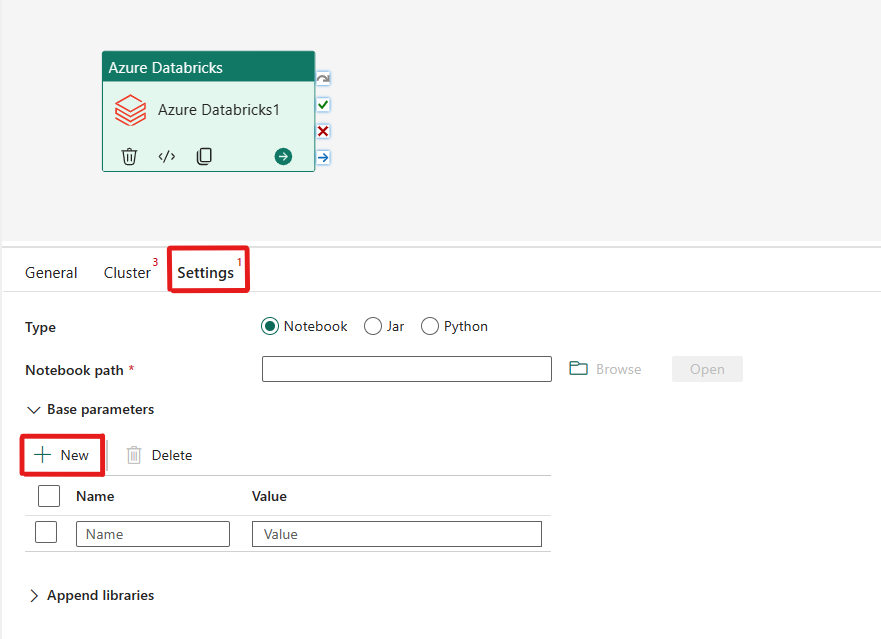
Konfigurieren von Einstellungen
Wenn Sie die Registerkarte Einstellungen auswählen, können Sie zwischen drei Optionen wählen, abhängig davon, welchen Azure Databricks-Typ Sie orchestrieren möchten.

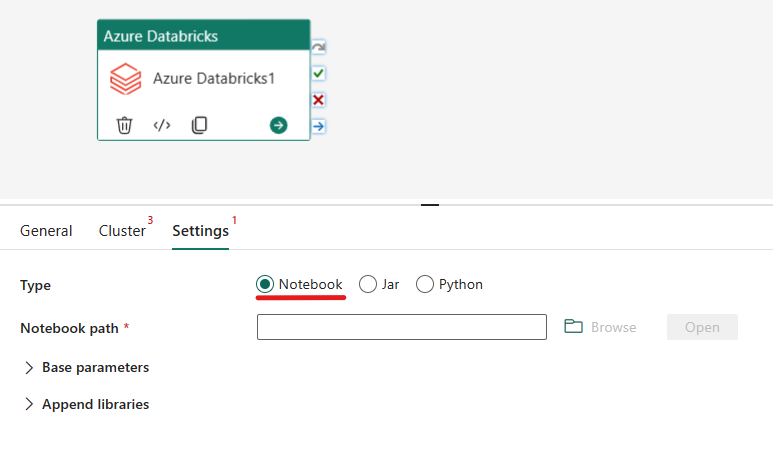
Orchestrieren des Typs „Notebook“ in der Azure Databricks-Aktivität:
Auf der Registerkarte Einstellungen können Sie das Optionsfeld Notebook auswählen, um ein Notebook auszuführen. Sie müssen den Notebook-Pfad, der in Azure Databricks ausgeführt werden soll, optionale Basisparameter, die an das Notebook übergeben werden sollen, und alle zusätzlichen Bibliotheken angeben, die im Cluster installiert werden sollen, um den Auftrag auszuführen.
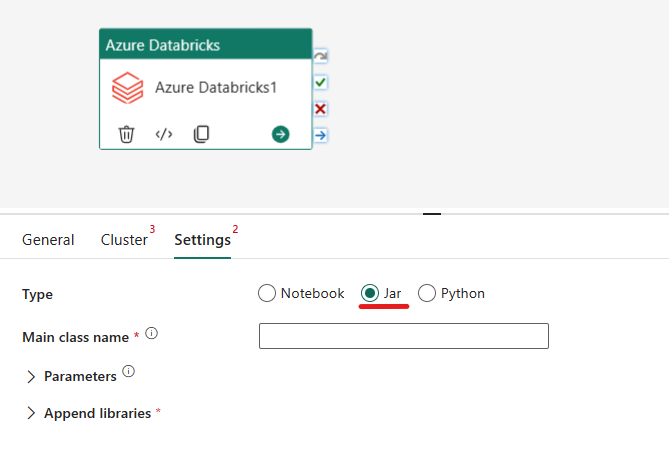
Orchestrieren des Typs „JAR“ in Azure Databricks-Aktivitäten:
Auf der Registerkarte Einstellungen können Sie das Optionsfeld Jar auswählen, um eine JAR-Datei auszuführen. Sie müssen den Klassennamen, der in Azure Databricks ausgeführt werden soll, optionale Basisparameter, die an die JAR-Datei übergeben werden sollen, und alle zusätzlichen Bibliotheken angeben, die im Cluster installiert werden sollen, um den Auftrag auszuführen.
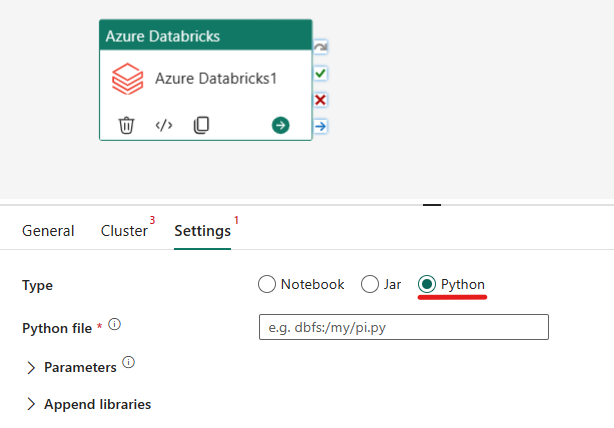
Orchestrieren des Typs „Python“ in der Azure Databricks-Aktivität:
Auf der Registerkarte Einstellungen können Sie das Optionsfeld Python auswählen, um eine Python-Datei auszuführen. Sie müssen den Pfad in Azure Databricks zu einer Python-Datei, die ausgeführt werden soll, optionale Basisparameter, die übergeben werden sollen, und alle zusätzlichen Bibliotheken angeben, die im Cluster installiert werden sollen, um den Auftrag auszuführen.
Unterstützte Bibliotheken für Azure Databricks-Aktivitäten
In der oben genannten Definition der Databricks-Aktivität können Sie die folgenden Bibliothekstypen angeben: JAR, EGG, WHL, Maven, PyPI, CRAN.
Weitere Informationen zu Bibliothekstypen finden Sie in der Databricks-Dokumentation.
Übergeben von Parametern zwischen Azure Databricks-Aktivitäten und -Pipelines
Mithilfe der baseParameters-Eigenschaft in der Databricks-Aktivität können Sie Parameter an Notebooks übergeben.
In bestimmten Fällen müssen Sie möglicherweise bestimmte Werte aus dem Notebook an den Dienst zurückgeben, die für die Ablaufsteuerung (Bedingungsüberprüfungen) im Dienst oder von Downstreamaktivitäten (Größenbeschränkung ist 2 MB) genutzt werden können.
Sie können in Ihrem Notebook beispielsweise dbutils.notebook.exit("returnValue") aufrufen, um den entsprechenden Rückgabewert (returnValue) an den Dienst zurückzugeben.
Mit einem Ausdruck wie
@{activity('databricks activity name').output.runOutput}können Sie die Ausgabe im Dienst verwenden.
Speichern und Ausführen oder Planen der Pipeline
Nachdem Sie alle anderen Aktivitäten konfiguriert haben, die für Ihre Pipeline erforderlich sind, wechseln Sie oben im Pipeline-Editor zur Registerkarte Start, und klicken Sie auf die Schaltfläche „Speichern“, um die Pipeline zu speichern. Wählen Sie Ausführen aus, um sie direkt auszuführen, oder Planen, um sie zu planen. Sie können hier auch den Ausführungsverlauf anzeigen oder andere Einstellungen konfigurieren.
