Verwalten von Apache Spark-Bibliotheken in Microsoft Fabric
Bei einer Bibliothek handelt es sich um vordefinierten Code, den Entwickler*innen importieren können, um zusätzliche Funktionen bereitzustellen. Bibliotheken verringern den Zeit- und Arbeitsaufwand für Sie, da sie Code nicht von Grund auf neu schreiben müssen, um allgemeine Aufgaben auszuführen. Importieren Sie stattdessen die Bibliothek und deren Funktionen und Klassen verwenden, um die gewünschten Funktionen zu erhalten. Microsoft Fabric bietet mehrere Mechanismen für die Verwaltung und Verwendung von Bibliotheken.
- Integrierte Bibliotheken: Jede Fabric Spark-Runtime bietet eine Vielzahl beliebter vorinstallierter Bibliotheken. Die vollständige Liste integrierter Bibliotheken finden Sie unter Fabric Spark-Runtime.
- Öffentliche Bibliothek: Öffentliche Bibliotheken stammen aus Repositorys wie PyPI und Conda, die derzeit unterstützt werden.
- Benutzerdefinierte Bibliotheken: Benutzerdefinierte Bibliotheken beziehen sich auf Code, der von Ihnen oder Ihrer Organisation erstellt wurde. Fabric unterstützt sie bei den Formaten .whl, .jar und .tar.gz. Fabric unterstützt TAR.GZ-Dateien nur für die R-Language. Verwenden Sie für benutzerdefinierte Python-Bibliotheken das Format WHL.
Zusammenfassung der bewährten Methoden für die Bibliotheksverwaltung
In den folgenden Szenarien werden bewährte Methoden bei der Verwendung von Bibliotheken in Microsoft Fabric beschrieben.
Szenario 1: Durch Administrator*innen festgelegte Standardbibliotheken für den Arbeitsbereich
Um Standardbibliotheken festzulegen, müssen Sie der Administrator bzw. die Administratorin des Arbeitsbereichs sein. Als Administrator können Sie diese Aufgaben ausführen:
- Eine neue Umgebung erstellen
- Installieren Sie die erforderlichen Bibliotheken in der Umgebung
- Anfügen dieser Umgebung als Arbeitsbereichsstandard
Wenn Ihre Notebooks und Spark-Auftragsdefinitionen im Arbeitsbereich, die an die Arbeitsbereichseinstellungen angefügt sind, starten sie Sitzungen mit den Bibliotheken, die in der Standardumgebung des Arbeitsbereichs installiert sind.
Szenario 2: Beibehalten von Bibliotheksspezifikationen für mindestens ein Codeelement
Wenn Sie über allgemeine Bibliotheken für unterschiedliche Codeelemente verfügen und keine häufige Aktualisierung erfordern, ist es eine gute Wahl die Bibliotheken in einer Umgebung zu installieren und sie an die Codeelemente anzufügen.
Es dauert einige Zeit, bis die Bibliotheken in Umgebungen wirksam werden, wenn sie veröffentlicht werden. Es dauert normalerweise 5-15 Minuten, abhängig von der Komplexität der Bibliotheken. Während dieses Prozesses hilft das System, die potenziellen Konflikte zu lösen und erforderliche Abhängigkeiten herunterzuladen.
Ein Vorteil dieses Ansatzes besteht darin, dass die erfolgreich installierten Bibliotheken garantiert verfügbar sind, wenn die Spark-Sitzung mit der angefügten Umgebung gestartet wird. Es spart den Aufwand für die Verwaltung gemeinsamer Bibliotheken für Ihre Projekte.
Es wird dringend für Pipelineszenarien mit ihrer Stabilität empfohlen.
Szenario 3: Inlineinstallation in interaktiver Ausführung
Wenn Sie die Notebooks verwenden, um Code interaktiv zu schreiben, empfiehlt es sich, mithilfe der Inlineinstallation zusätzliche neue PyPI/conda-Bibliotheken hinzuzufügen oder Ihre benutzerdefinierten Bibliotheken für die einmalige Verwendung zu überprüfen. Mithilfe von Inlinebefehlen in Fabric können Sie die Bibliothek in der aktuellen Spark-Sitzung des Notebooks aktivieren. Sie ermöglicht die Schnellinstallation, aber die installierte Bibliothek wird nicht über verschiedene Sitzungen hinweg beibehalten.
Da %pip install von Zeit zu Zeit unterschiedliche Abhängigkeitsstrukturen generiert, was zu Bibliothekskonflikten führen kann, werden Inlinebefehle in der Pipelineausführung standardmäßig deaktiviert und es wird NICHT empfohlen, sie in Ihren Pipelines zu verwenden.
Zusammenfassung der unterstützten Bibliothekstypen
| Bibliothekstyp | Umgebungsbasierte Bibliotheksverwaltung | Inline-Installation |
|---|---|---|
| Python: öffentlich (PyPI und Conda) | Unterstützt | Unterstützt |
| Python Custom (WHL) | Unterstützt | Unterstützt |
| R: öffentlich (CRAN) | Nicht unterstützt | Unterstützt |
| R benutzerdefiniert (TAR.GZ) | Unterstützt als benutzerdefinierte Bibliothek | Unterstützt |
| JAR | Unterstützt als benutzerdefinierte Bibliothek | Unterstützt |
Inline-Installation
Inlinebefehle unterstützen die Verwaltung von Bibliotheken in den einzelnen Notebooksitzungen.
Inlineinstallation für Python
Das System startet den Python-Interpreter neu, um die Änderung von Bibliotheken anzuwenden. Alle vor dem Ausführen der Befehlszelle definierten Variablen gehen verloren. Wir empfehlen dringend, alle Befehle zum Hinzufügen, Löschen oder Aktualisieren von Python-Paketen am Anfang Ihres Notebooks zu platzieren.
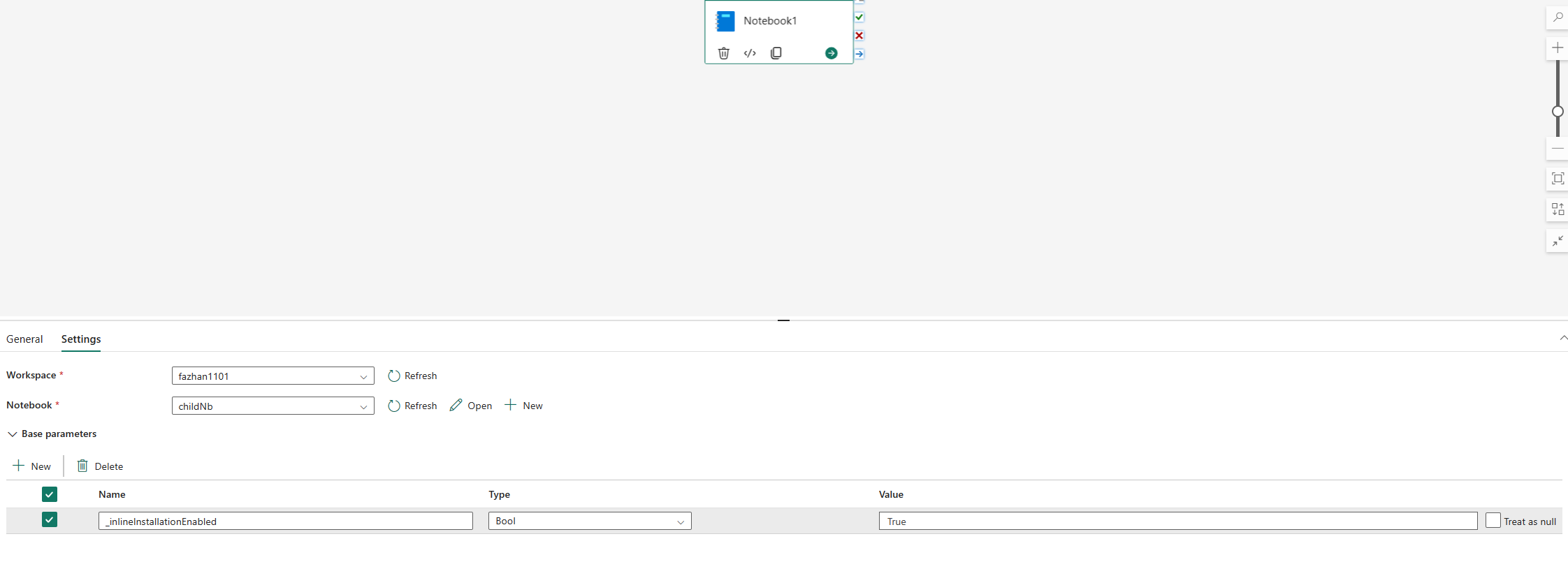
Die Inline-Befehle zur Verwaltung von Python-Bibliotheken sind in der Notebook-Pipelineausführung standardmäßig deaktiviert. Wenn Sie %pip install für die Pipeline aktivieren möchten, fügen Sie „_inlineInstallationEnabled“ als Bool-Parameter gleich „True“ in die Parameter der Notebook-Aktivität ein.
Hinweis
Das %pip install kann von Zeit zu Zeit zu widersprüchlichen Ergebnissen führen. Es wird empfohlen, die Bibliothek in einer Umgebung zu installieren und sie in der Pipeline zu verwenden.
In der Notebookreferenz werden Inlinebefehle zum Verwalten von Python-Bibliotheken nicht unterstützt. Um die Richtigkeit der Ausführung sicherzustellen, wird empfohlen, diese Inlinebefehle aus dem referenzierten Notebook zu entfernen.
Wir empfehlen %pip anstelle von !pip. !pip ist ein integrierter IPython-Shellbefehl mit den folgenden Einschränkungen:
!pipinstalliert nur ein Paket auf dem Treiberknoten, nicht auf Executor-Knoten.- Pakete, die über
!pipinstalliert werden, wirken sich nicht auf Konflikte mit integrierten Paketen aus oder auf Pakete, die bereits in ein Notebook importiert wurden.
%pip handhabt diese Szenarien jedoch. Bibliotheken, die über %pip installiert werden, sind sowohl auf Treiber- als auch auf Executorknoten verfügbar und sind auch dann wirksam, wenn die Bibliothek bereits importiert wurde.
Tipp
Der %conda install-Befehl dauert in der Regel länger als der %pip install-Befehl zum Installieren neuer Python-Bibliotheken. Er überprüft die vollständigen Abhängigkeiten und löst Konflikte.
Sie sollten %conda install install verwenden, um mehr Zuverlässigkeit und Stabilität zu erzielen. Sie können %pip install install verwenden, wenn Sie sicher sind, dass die Bibliothek, die Sie installieren möchten, nicht mit den vorinstallierten Bibliotheken in der Runtime-Umgebung in Konflikt steht.
Für alle verfügbaren Python-Inlinebefehle und -Erklärungen siehe %pip-Befehle und %conda-Befehle.
Verwalten öffentlicher Python-Bibliotheken über die Inlineinstallation
In diesem Beispiel sehen Sie, wie Sie Inlinebefehle verwenden, um Bibliotheken zu verwalten. Angenommen, Sie möchten Altair, eine leistungsstarke Visualisierungsbibliothek für Python, für eine einmalige Datenuntersuchung verwenden. Nehmen wir weiter an, die Bibliothek sei nicht in Ihrem Arbeitsbereich installiert. Das folgende Beispiel verwendet conda-Befehle, um die Schritte zu veranschaulichen.
Sie können Inlinebefehle verwenden, um Altair für Ihre Notebooksitzung zu aktivieren, ohne dass sich dies auf andere Sitzungen des Notebooks oder andere Elemente auswirkt.
Führen Sie die folgenden Befehle in einer Notebook-Code-Zelle aus. Der erste Befehl installiert die Altair-Bibliothek. Installieren Sie außerdem vega_datasets, das ein semantisches Modell enthält, mit dem Sie visualisieren können.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandDie Zellenausgabe gibt das Ergebnis der Installation an.
Importieren Sie das Paket und das Semantikmodell, indem Sie die folgenden Codes in einer anderen Notebookzelle ausführen.
import altair as alt from vega_datasets import dataJetzt können Sie mit der sitzungsspezifischen Altair-Bibliothek herumspielen.
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
Verwalten benutzerdefinierter Python-Bibliotheken über die Inlineinstallation
Sie können Ihre benutzerdefinierten Python-Bibliotheken in den Ressourcenordner Ihres Notebooks oder in die angefügte Umgebung hochladen. Die Ressourcenordner sind das integrierte Dateisystem, das von jedem Notebook und jeder Umgebung bereitgestellt wird. Weitere Details finden Sie in den Notebookressourcen. Nach dem Hochladen können Sie die benutzerdefinierte Bibliothek in eine Codezelle ziehen und dort ablegen. Der Inlinebefehl zum Installieren der Bibliothek wird automatisch generiert. Oder Sie können den folgenden Befehl zum Installieren verwenden.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
R-Inline-Installation
Zum Verwalten von R-Bibliotheken unterstützt Fabric die Befehle install.packages(), remove.packages() und devtools::. Für alle verfügbaren R-Inlinebefehle und -Erläuterungen siehe Befehl install.packagesund dem Befehl remove.package.
Verwalten öffentlicher R-Bibliotheken über die Inlineinstallation
Im folgenden Beispiel werden die Schritte zum Installieren einer öffentlichen R-Bibliothek durchlaufen.
So installieren Sie eine R-Feedbibliothek
Wechseln Sie die Arbeitssprache im Notebook-Menüband auf SparkR (R).
Führen Sie den folgenden Befehl in einer Notebookzelle aus, um die Bibliothek caesar zu installieren.
install.packages("caesar")Nun können Sie die sitzungsspezifische caesar-Bibliothek mit einem Spark-Auftrag ausprobieren.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
Verwalten von Jar-Bibliotheken über die Inlineinstallation
Die .jar-Dateien werden in Notebook-Sitzungen mit folgendem Befehl unterstützt.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
Die Codezelle verwendet den Speicher von Lakehouse als Beispiel. Im Notebook-Explorer können Sie den vollständigen ABFS-Pfad kopieren und im Code ersetzen.
