Übermitteln und Ausführen von Sitzungsaufträgen mit der Livy-API
Hinweis
Die Livy-API für Fabric Datentechnik befindet sich in der Vorschau.
Gilt für:✅ Datentechnik und Data Science in Microsoft Fabric
Übermitteln von Spark-Batchaufträgen mit der Livy-API für Fabric Datentechnik.
Voraussetzungen
Fabric Premium- oder Testkapazität, mit einem Lakehouse.
Ein Remoteclient wie Visual Studio Code mit Jupyter Notebooks, PySpark und die Microsoft Authentication Library (MSAL) für Python.
Für den Zugriff auf die Fabric-REST-API ist ein Microsoft Entra-App-Token erforderlich. Registrieren einer Anwendung bei der Microsoft Identity Platform.
Einige Daten in Ihrem Lakehouse; dieses Beispiel verwendet NYC Taxi & Limousine Commission green_tripdata_2022_08 eine Parkettdatei, die in Lakehouse geladen wurde.
Die Livy-API definiert einen einheitlichen Endpunkt für Vorgänge. Ersetzen Sie die Platzhalter {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} und {Fabric_LakehouseID} durch die entsprechenden Werte, wenn Sie den Beispielen in diesem Artikel folgen.
Konfigurieren von Visual Studio Code für Ihre Livy-API-Sitzung
Wählen Sie Lakehouse-Einstellungen in Ihrem Fabric Lakehouse aus.

Navigieren Sie zum Abschnitt Livy-Endpunkt.
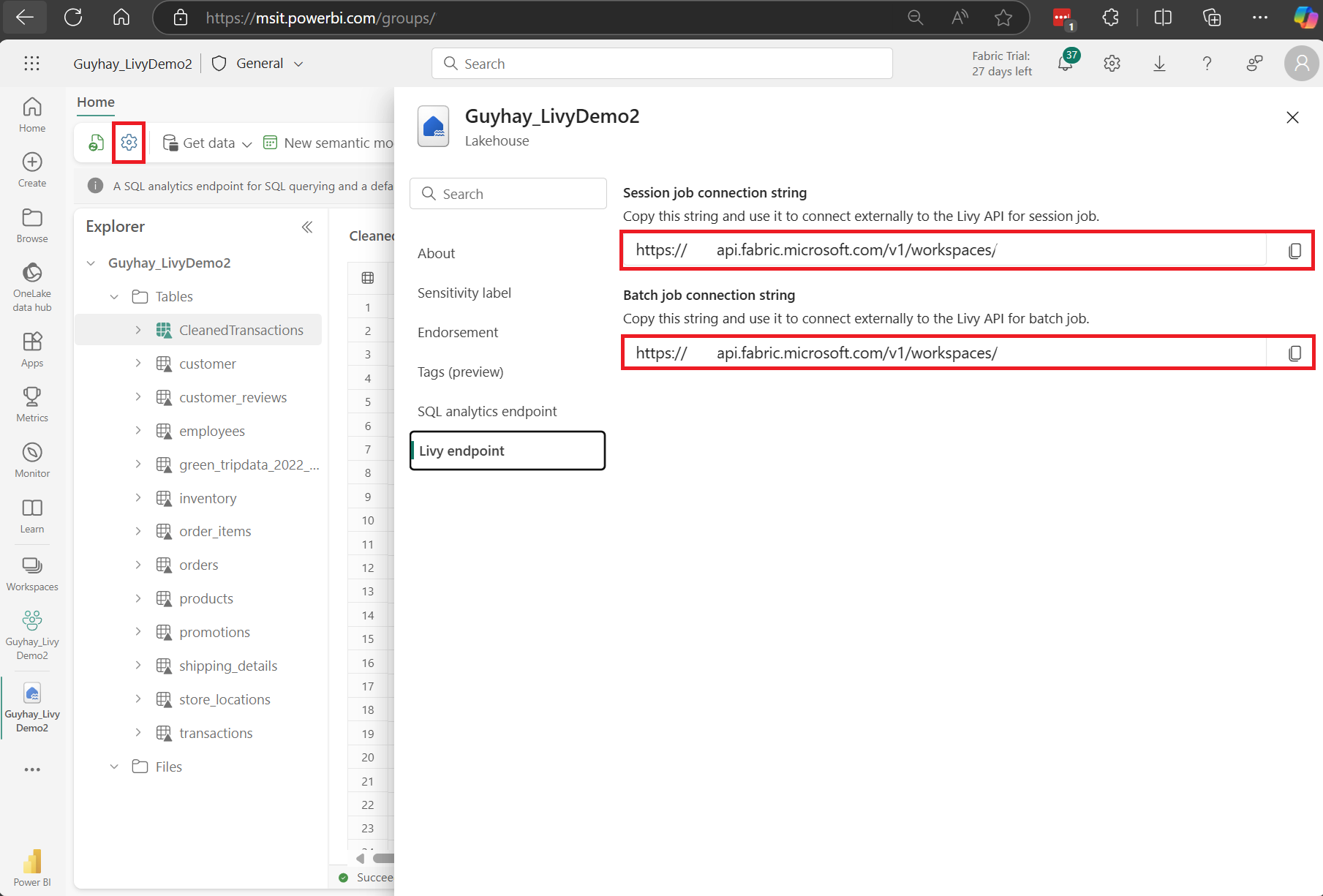
Kopieren Sie die Verbindungszeichenfolge des Sitzungsauftrags (erstes rotes Feld im Bild) in Ihren Code.
Navigieren Sie zum Microsoft Entra Admin Center, und kopieren Sie sowohl die Anwendungs-ID (Client-ID) als auch die Verzeichnis-ID (Mandant) in Ihren Code.
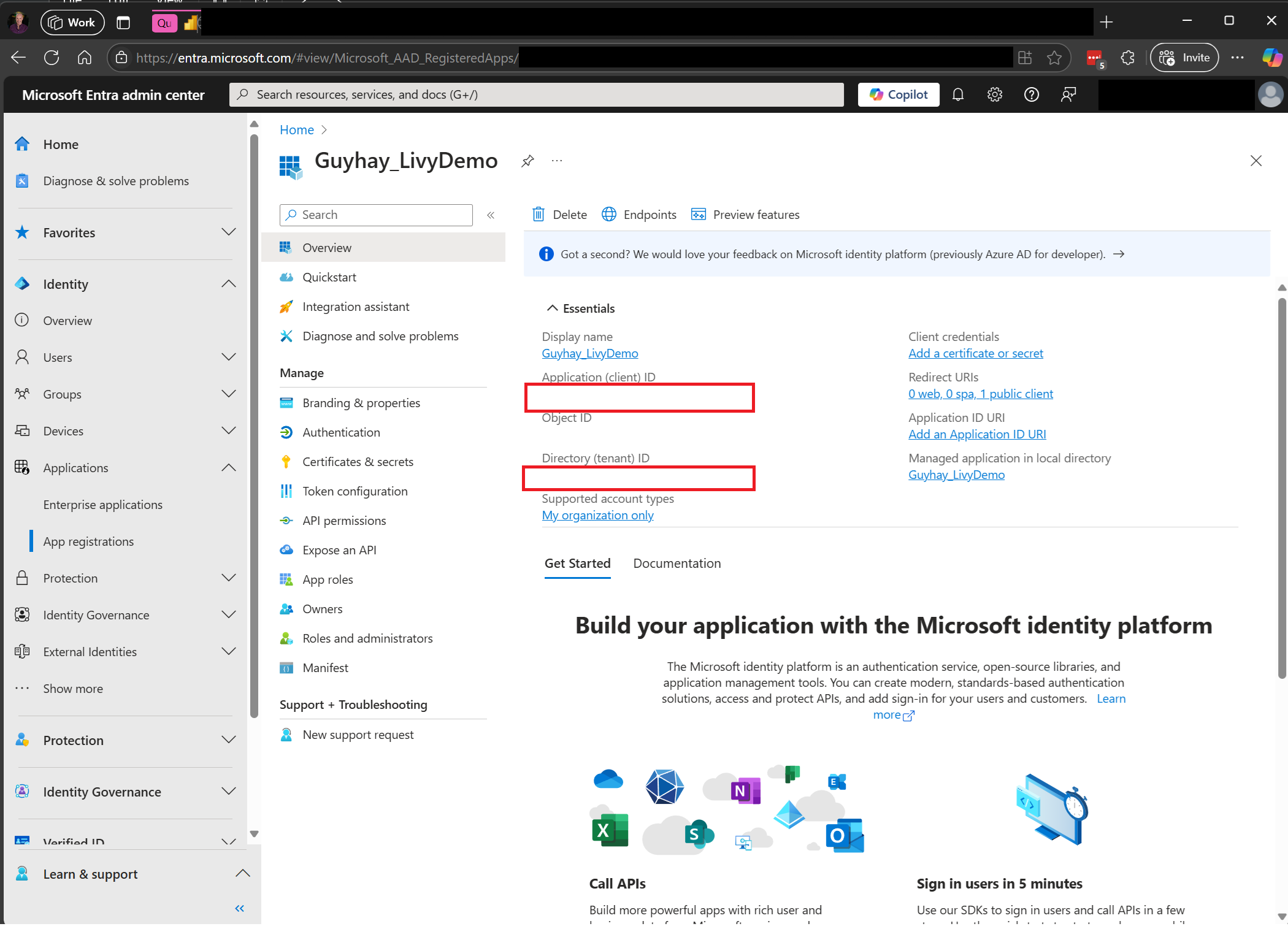



Erstellen einer Livy-API Spark-Sitzung
Erstellen Sie ein
.ipynb-Notizbuch in Visual Studio Code, und fügen Sie den folgenden Code ein.from msal import PublicClientApplication import requests import time tenant_id = "Entra_TenantID" client_id = "Entra_ClientID" workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/sessions" headers = {"Authorization": "Bearer " + access_token}Führen Sie das Notebookfenster aus. In Ihrem Browser sollte ein Popupfenster erscheinen, in dem Sie die Identität auswählen können, mit der Sie sich anmelden möchten.
Nachdem Sie die Identität ausgewählt haben, mit der Sie sich anmelden möchten, werden Sie auch aufgefordert, die API-Berechtigungen für die Microsoft Entra-App-Registrierung zu genehmigen.
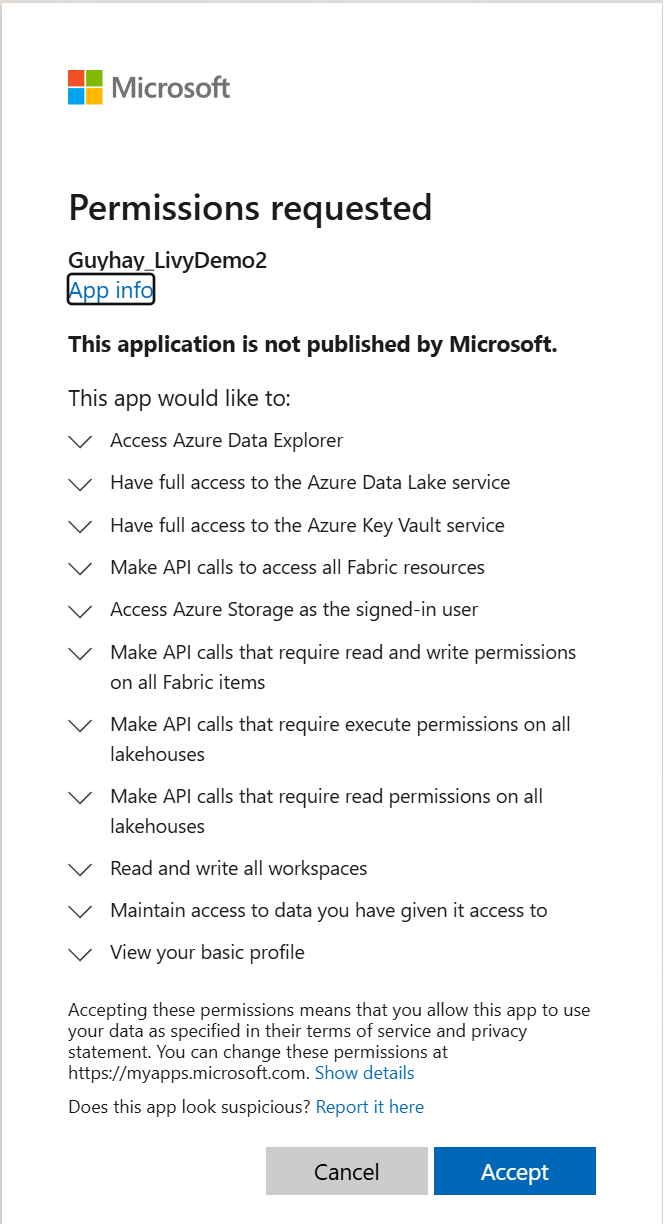
Schließen Sie das Browserfenster nach Abschluss der Authentifizierung.

In Visual Studio Code sollte das Microsoft Entra-Token zurückgegeben werden.
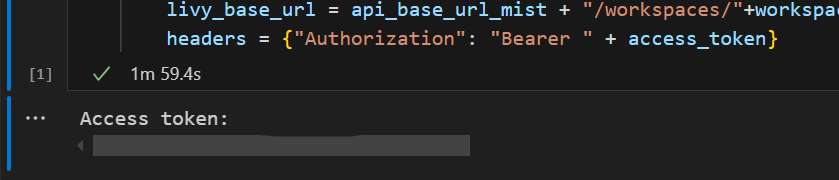
Fügen Sie eine weitere Notebookzelle hinzu, und fügen Sie diesen Code ein.
create_livy_session = requests.post(livy_base_url, headers=headers, json={}) print('The request to create the Livy session is submitted:' + str(create_livy_session.json())) livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json())Führen Sie die Notebookzelle aus. Sie sollten eine Zeile sehen, die gedruckt wird, während die Livy-Sitzung erstellt wird.

Sie können überprüfen, ob die Livy-Sitzung erstellt wird, indem Sie die [Anzeigen Ihrer Aufträge im Monitoring Hub](#Anzeigen Ihrer Aufträge im Monitoring Hub) verwenden.





Übermitteln einer spark.sql-Anweisung mithilfe der Livy-API Spark-Sitzung
Fügen Sie eine weitere Notebookzelle hinzu, und fügen Sie diesen Code ein.
# call get session API livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json()) while get_session_response.json()["state"] != "idle": time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) execute_statement = livy_session_url + "/statements" payload_data = { "code": "spark.sql(\"SELECT * FROM green_tripdata_2022_08 where fare_amount = 60\").show()", "kind": "spark" } execute_statement_response = requests.post(execute_statement, headers=headers, json=payload_data) print('the statement code is submitted as: ' + str(execute_statement_response.json())) statement_id = str(execute_statement_response.json()['id']) get_statement = livy_session_url+ "/statements/" + statement_id get_statement_response = requests.get(get_statement, headers=headers) while get_statement_response.json()["state"] != "available": # Sleep for 5 seconds before making the next request time.sleep(5) print('the statement code is submitted and running : ' + str(execute_statement_response.json())) # Make the next request get_statement_response = requests.get(get_statement, headers=headers) rst = get_statement_response.json()['output']['data']['text/plain'] print(rst)Führen Sie die Notebookzelle aus. Sie sollten mehrere inkrementelle Zeilen sehen, die gedruckt werden, wenn der Auftrag übermittelt wird und die Ergebnisse zurückgegeben werden.
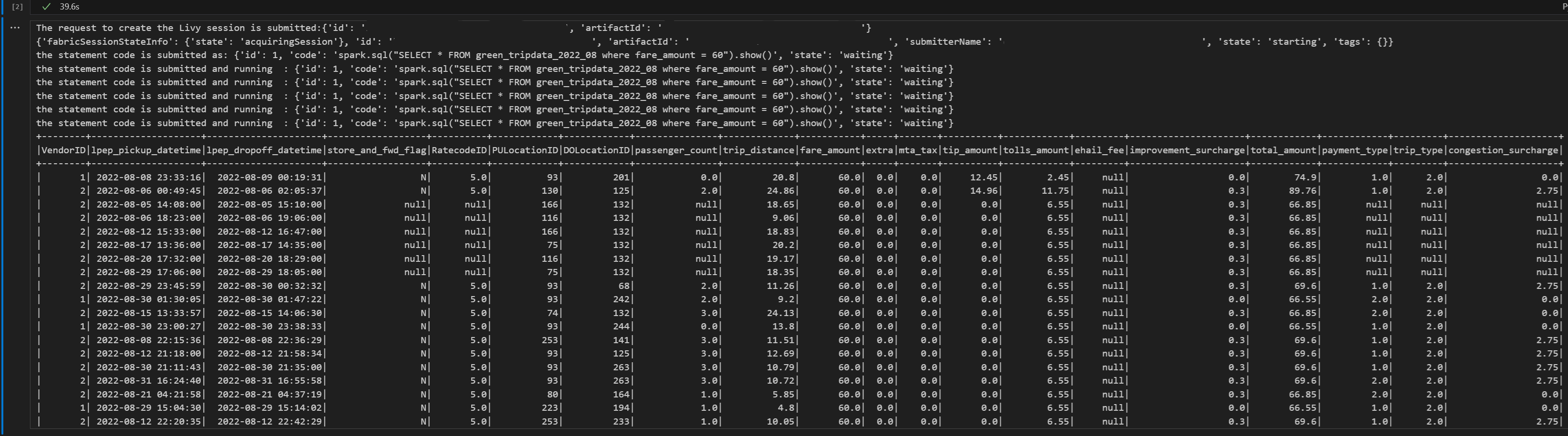

Übermitteln einer zweiten spark.sql-Anweisung mithilfe der Livy-API Spark-Sitzung
Fügen Sie eine weitere Notebookzelle hinzu, und fügen Sie diesen Code ein.
# call get session API livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json()) while get_session_response.json()["state"] != "idle": time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) execute_statement = livy_session_url + "/statements" payload_data = { "code": "spark.sql(\"SELECT * FROM green_tripdata_2022_08 where tip_amount = 10\").show()", "kind": "spark" } execute_statement_response = requests.post(execute_statement, headers=headers, json=payload_data) print('the statement code is submitted as: ' + str(execute_statement_response.json())) statement_id = str(execute_statement_response.json()['id']) get_statement = livy_session_url+ "/statements/" + statement_id get_statement_response = requests.get(get_statement, headers=headers) while get_statement_response.json()["state"] != "available": # Sleep for 5 seconds before making the next request time.sleep(5) print('the statement code is submitted and running : ' + str(execute_statement_response.json())) # Make the next request get_statement_response = requests.get(get_statement, headers=headers) rst = get_statement_response.json()['output']['data']['text/plain'] print(rst)Führen Sie die Notebookzelle aus. Sie sollten mehrere inkrementelle Zeilen sehen, die gedruckt werden, wenn der Auftrag übermittelt wird und die Ergebnisse zurückgegeben werden.
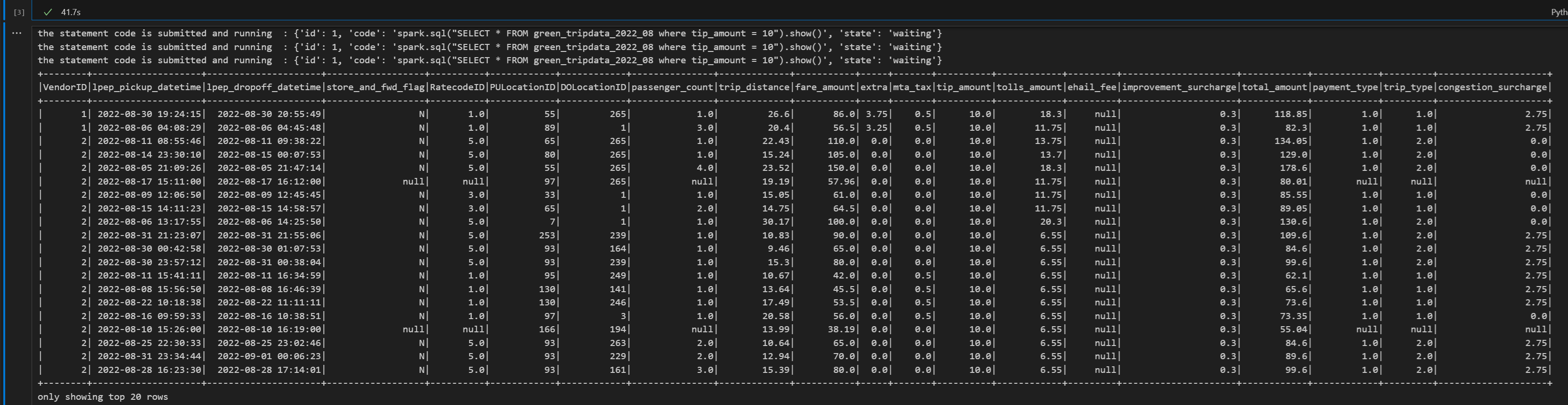

Schließen Sie die Livy-Sitzung mit einer dritten Anweisung
Fügen Sie eine weitere Notebookzelle hinzu, und fügen Sie diesen Code ein.
# call get session API with a delete session statement get_session_response = requests.get(livy_session_url, headers=headers) print('Livy statement URL ' + livy_session_url) response = requests.delete(livy_session_url, headers=headers) print (response)
Anzeigen Ihrer Aufträge im Monitoring Hub
Sie können auf den Überwachungshub zugreifen, um verschiedene Apache Spark-Aktivitäten anzuzeigen, indem Sie in den Navigationslinks auf der linken Seite „Überwachen“ auswählen.
Bei laufenden oder abgeschlossenen Sitzungen können Sie den Sitzungsstatus anzeigen, indem Sie zu „Überwachen“ navigieren.
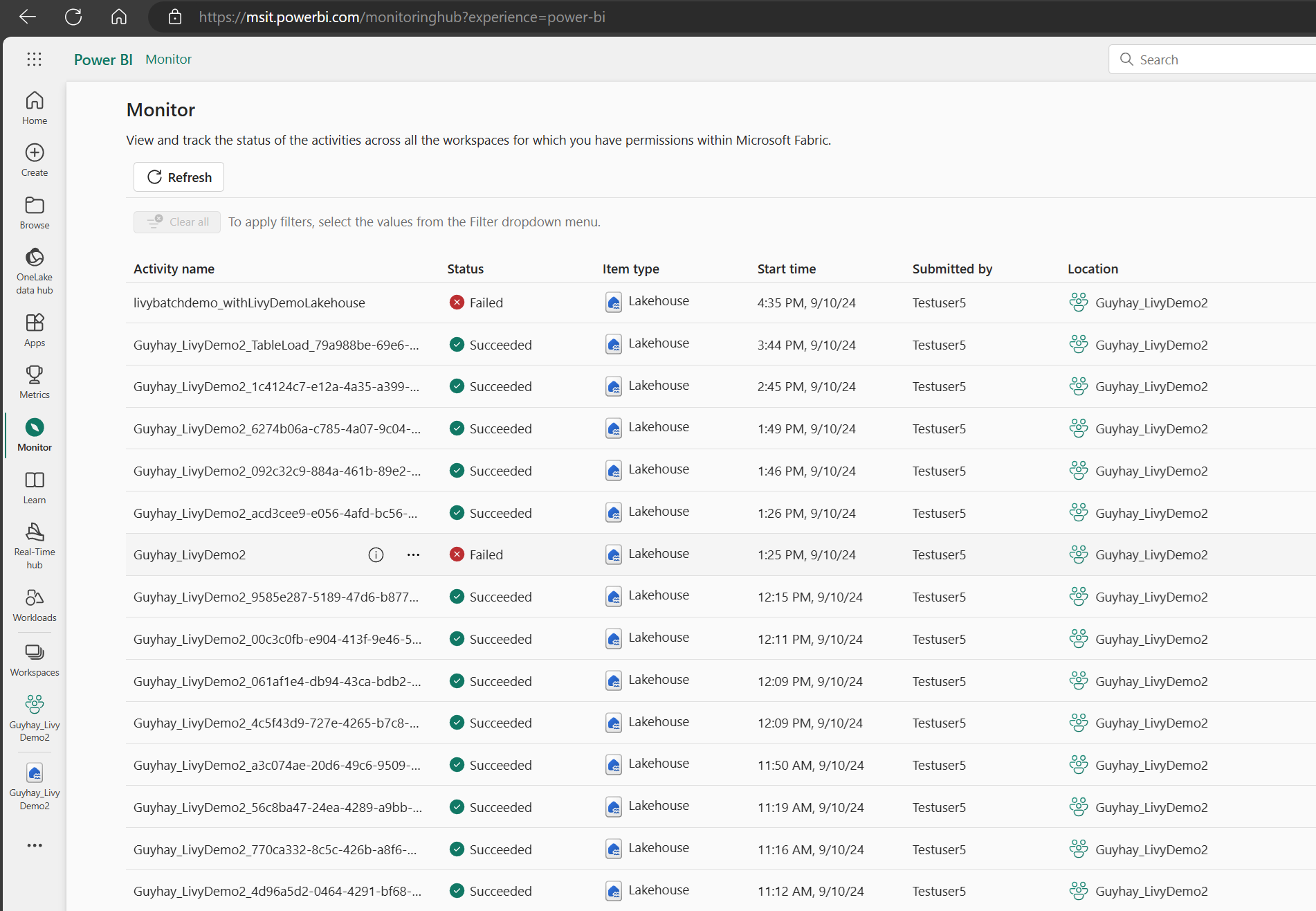
Wählen Sie den Namen der letzten Aktivität aus, und öffnen Sie sie.
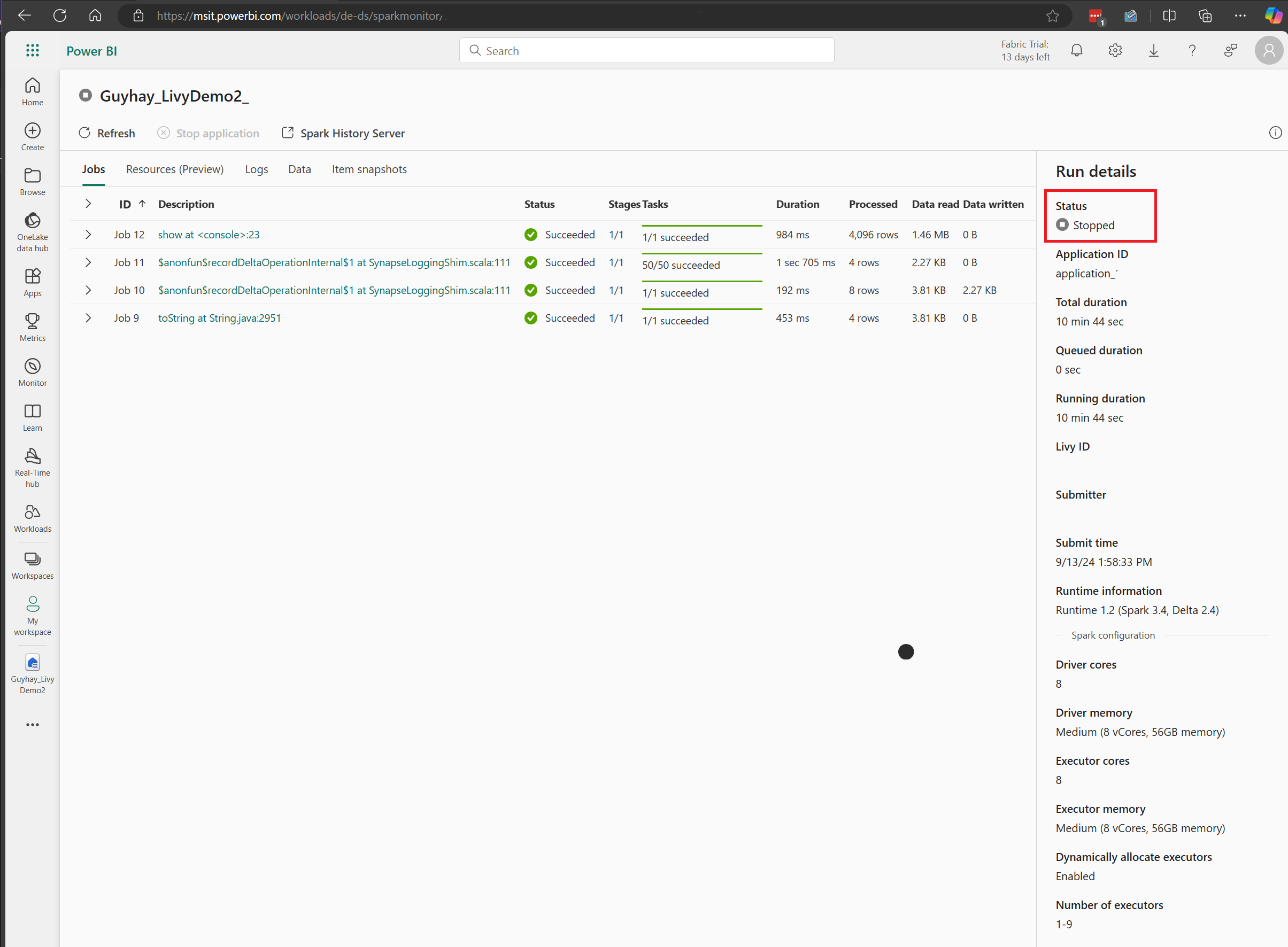
In diesem Livy-API-Sitzungsfall können Sie Ihre vorherigen Sitzungsübermittlungen, Ausführungsdetails, Spark-Versionen und Konfigurationen einsehen. Beachten Sie den Status „Angehalten“ oben rechts.

Um den gesamten Prozess zusammenzufassen: Sie benötigen einen Remote-Client wie Visual Studio Code, ein Microsoft Entra-App-Token, eine Livy-API-Endpunkt-URL, eine Authentifizierung gegenüber Ihrem Lakehouse und schließlich eine Session-Livy-API.