Abrechnungs- und Nutzungsberichte für Apache Spark in Microsoft Fabric
Gilt für:✅ Datentechnik und Data Science in Microsoft Fabric
In diesem Artikel werden die Computeauslastung und die Berichterstellung für ApacheSpark erläutert, das den Fabric-Workloads für Datentechnik und Data Science in Microsoft Fabric zugrunde liegt. Die Computeauslastung umfasst Lakehouse-Operationen wie Tabellenvorschau, Laden in Delta, Notebookausführungen über die Schnittstelle, geplante Ausführungen, durch Notebookschritte in den Pipelines ausgelöste Ausführungen und Ausführungen von Apache Spark-Jobdefinitionen.
Genau wie andere Umgebungen in Microsoft Fabric verwendet auch die Datentechnikumgebung die Kapazität, die einem Arbeitsbereich zugeordnet ist, um diese Aufträge auszuführen, und Ihre Gesamtkapazitätsgebühren werden im Azure-Portal unter Ihrem Microsoft Cost Management-Abonnement angezeigt. Weitere Informationen zu Ihrer Fabric-Abrechnung finden Sie unter Grundlegendes zu Ihrer Azure-Rechnung für eine Fabric-Kapazität.
Fabric-Kapazität
Benutzer*innen können eine Fabric-Kapazität von Azure erwerben, indem sie ein Azure-Abonnement verwenden. Die Größe der Kapazität bestimmt die verfügbare Rechenleistung. Bei Apache Spark für Fabric entspricht jede erworbene CU zwei virtuellen Apache Spark-Kernen. Wenn Sie also beispielsweise die Fabric-Kapazität F128 erwerben, entspricht dies 256 virtuellen Spark-Kernen. Eine Fabric-Kapazität wird gemeinsam von allen Arbeitsbereichen genutzt, die ihr hinzugefügt werden und in denen die insgesamt zulässige Apache Spark-Computekapazität von allen Jobs, die von allen einer Kapazität zugeordneten Arbeitsbereichen übermittelt werden, geteilt wird. Informationen zu den verschiedenen SKUs, zur Zuweisung und Drosselung von Kernen für Spark finden Sie unter Parallelitätsgrenzwerte und Warteschlangen in Apache Spark für Microsoft Fabric.
Spark-Computekonfiguration und erworbene Kapazität
Apache Spark-Compute für Fabric bietet zwei Optionen für die Computekonfiguration.
Startpools: Diese Standardpools sind eine schnelle und einfache Möglichkeit, Spark innerhalb von Sekunden auf der Microsoft Fabric-Plattform zu verwenden. Sie können Spark-Sitzungen sofort verwenden, anstatt darauf zu warten, dass Spark die Knoten für Sie eingerichtet hat. Das hilft Ihnen, mehr mit Daten zu erledigen und schneller Erkenntnisse zu erhalten. Was die Abrechnung und Kapazitätsnutzung angeht: Gebühren fallen an, wenn Sie mit der Ausführung Ihres Notebooks, Ihrer Spark-Auftragsdefinition oder Ihres Lakehouse-Vorgangs beginnen. Leerlaufzeiten der Cluster im Pool werden Ihnen nicht in Rechnung gestellt.
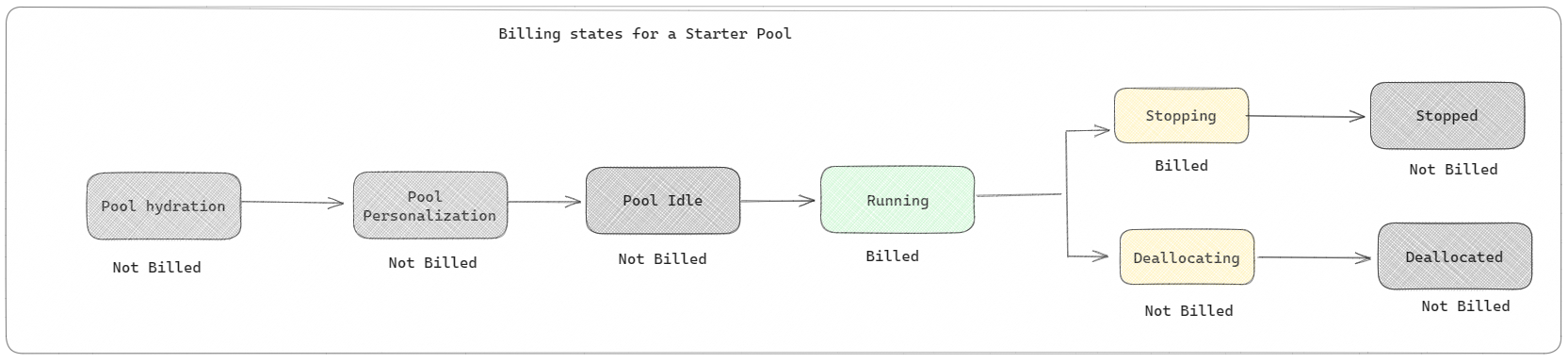
Wenn beispielsweise ein Notebookauftrag an einen Starterpool übermittelt wird, wird Ihnen nur der Zeitraum in Rechnung gestellt, in dem die Notebooksitzung aktiv ist. Die abgerechnete Zeit schließt nicht die Leerlaufzeit oder die Zeit ein, die zum Personalisieren der Sitzung mit dem Spark-Kontext erforderlich ist. Weitere Informationen zum Konfigurieren von Starterpools in Abhängigkeit von der erworbenen Kapazitäts-SKU für Fabric finden Sie unter Konfigurieren von Startpools in Microsoft Fabric.
Spark-Pools: Hierbei handelt es sich um benutzerdefinierte Pools, bei denen Sie anpassen können, welche Größe von Ressourcen Sie für Ihre Datenanalyseaufgaben benötigen. Sie können Ihrem Spark-Pool einen Namen geben und auswählen, wie viele und wie große Knoten (die Computer, die die Arbeit erledigen) Sie verwenden möchten. Sie können Spark außerdem mitteilen, wie die Anzahl der Knoten angepasst werden soll, je nachdem, wie viel Arbeit Sie haben. Das Erstellen eines Spark-Pools ist kostenlos. Sie zahlen nur, wenn Sie einen Spark-Auftrag im Pool ausführen, und dann richtet Spark die Knoten für Sie ein.
- Die Größe und Anzahl der Knoten, die Sie in Ihrem benutzerdefinierten Spark-Pool betreiben können, hängt von Ihrer Microsoft Fabric-Kapazität ab. Sie können diese Spark-VCores verwenden, um Knoten unterschiedlicher Größe für Ihren benutzerdefinierten Spark-Pool zu erstellen, solange die Gesamtzahl der Spark-VCores 128 nicht überschreitet.
- Die Abrechnung von Spark-Pools entspricht der von Starter-Pools, bei denen Sie nicht für die von Ihnen erstellten benutzerdefinierten Spark-Pools bezahlen, es sei denn, Sie haben eine aktive Spark-Sitzung erstellt, um eine Notebook- oder Spark-Auftragsdefinition auszuführen. Ihnen wird nur die Zeit in Rechnung gestellt, die Ihre Aufträge ausgeführt werden. Zeiten wie die Clustererstellung und die Belegungsfreigabe nach Abschluss des Auftrags werden nicht in Rechnung gestellt.
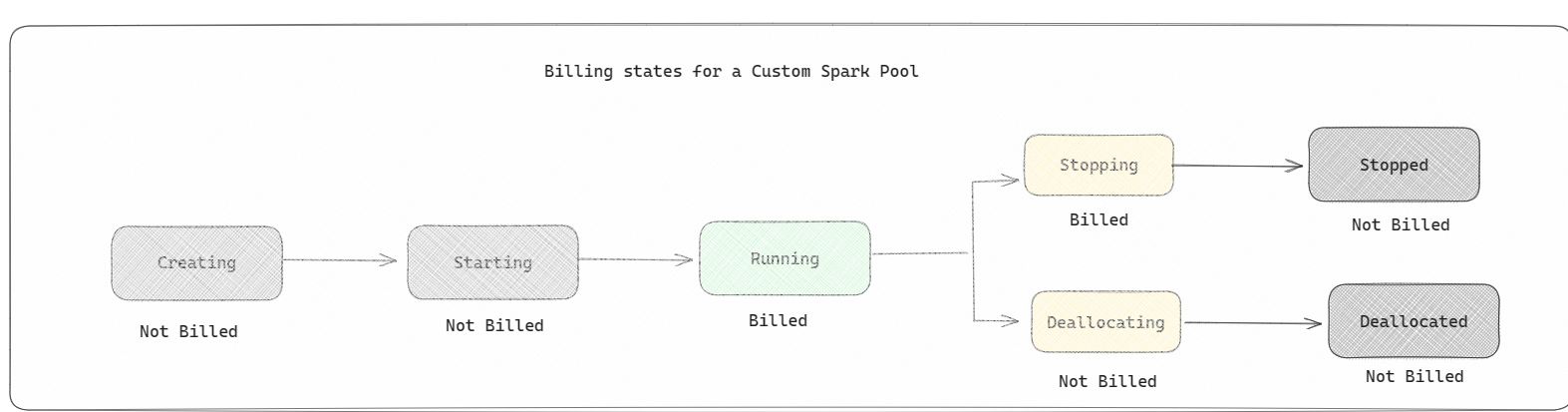
Wenn Sie beispielsweise einen Notebookauftrag an einen benutzerdefinierten Spark-Pool übermitteln, wird Ihnen nur der Zeitraum in Rechnung gestellt, in dem die Sitzung aktiv ist. Die Abrechnung für diese Notebooksitzung endet, sowie die Spark-Sitzung beendet wird oder abgelaufen ist. Die Zeit zum Abrufen von Clusterinstanzen aus der Cloud oder die Zeit zum Initialisieren des Spark-Kontexts wird Ihnen nicht in Rechnung gestellt. Weitere Informationen zum Konfigurieren von Spark-Pools in Abhängigkeit von der erworbenen Kapazitäts-SKU für Fabric finden Sie unter Was ist Spark-Compute in Microsoft Fabric?.


Hinweis
Der standardmäßige Ablaufzeitzeitraum für die Starterpools und Spark Pools, die Sie erstellen, ist auf 20 Minuten festgelegt. Wenn Sie Ihren Spark-Pool nach Ablauf Ihrer Sitzung 2 Minuten lang nicht verwenden, wird die Zuordnung Ihres Spark-Pools aufgehoben. Um die Sitzung und die Abrechnung nach Abschluss der Ausführung Ihres Notizbuchs vor ablaufendem Zeitraum der Sitzung zu beenden, können Sie entweder über das Startmenü der Notizbücher auf die Schaltfläche „Sitzung beenden“ klicken oder zur Überwachungshubseite wechseln und die Sitzung dort beenden.
Nutzungsberichte für Spark-Compute
Die Microsoft Fabric-Kapazitätsmetriken-App bietet Einblicke in die Kapazitätsauslastung für alle Fabric-Workloads an einem zentralen Ort. Sie wird von Kapazitätsadministrator*innen verwendet, um die Leistung von Workloads und deren Nutzung in Relation zur erworbenen Kapazität zu überwachen.
Wählen Sie nach der Installation der App in der Auswahlliste Elementtyp auswählen: den Elementtyp Notebook, Lakehouse oder Spark-Auftragsdefinition aus. Das Menübanddiagramm mit mehreren Metriken kann jetzt auf einen gewünschten Zeitrahmen festgelegt werden, um die Verwendung aller ausgewählten Elemente zu verstehen.
Alle Spark-bezogenen Vorgänge werden als Hintergrundvorgänge klassifiziert. Der Kapazitätsverbrauch von Spark wird unter einem Notebook, einer Spark-Auftragsdefinition oder einem Lakehouse angezeigt und nach Vorgangsname und Element aggregiert. Beispiel: Wenn Sie einen Notebook-Auftrag ausführen, können Sie im Bericht die Notebook-Ausführung, die von dem Notebook beanspruchten CUs (Gesamtanzahl der virtuellen Spark-Kerne geteilt durch zwei, da eine CU zwei virtuellen Spark-Kernen entspricht) und die Dauer des Auftrags sehen.
 Weitere Informationen zu Spark-Kapazitätsauslastungs-Berichten finden Sie unter Überwachen des Apache Spark-Kapazitätsverbrauchs
Weitere Informationen zu Spark-Kapazitätsauslastungs-Berichten finden Sie unter Überwachen des Apache Spark-Kapazitätsverbrauchs
Abrechnungsbeispiel
Nehmen Sie das folgende Szenario als Beispiel:
Es gibt eine Kapazität (C1), die einen Fabric-Workspace (W1) hostet, und dieser Arbeitsbereich enthält das Lakehouse LH1 und das Notebook NB1.
- Alle Spark-Vorgänge, die das Notebook NB1 oder das Lakehouse LH1 ausführen, werden für die Kapazität C1 gemeldet.
Erweitern Sie dieses Beispiel nun auf ein Szenario mit einer weiteren Kapazität C2, die einen weiteren Fabric-Arbeitsbereich W2 hostet, und dieser Arbeitsbereich enthält eine Spark-Jobdefinition (SJD1) und das Lakehouse (LH2).
- Wenn die Spark-Auftragsdefinition SDJ2 aus dem Workspace W2 Daten aus dem Lakehouse LH1 liest, wird die Verwendung für die Kapazität C2 gemeldet, die dem Arbeitsbereich W2 zugeordnet ist, in dem das Element gehostet wird.
- Wenn das Notebook NB1 einen Lesevorgang im Lakehouse LH2 ausführt, wird der Kapazitätsverbrauch für die Kapazität C1 gemeldet, die dem Arbeitsbereich W1 zugrunde liegt, der das Notebook-Element hostet.