Verwaltungseinstellungen für Datentechnik-Arbeitsbereiche in Microsoft Fabric
Gilt für:✅ Datentechnik und Data Science in Microsoft Fabric
Wenn Sie einen Arbeitsbereich in Microsoft Fabric erstellen, wird automatisch ein Starterpool erstellt, der diesem Arbeitsbereich zugeordnet ist. Dank der vereinfachten Einrichtung in Microsoft Fabric brauchen Sie die Knoten- oder Computergrößen nicht auszuwählen, da diese Optionen für Sie im Hintergrund behandelt werden. Diese Konfiguration bietet eine schnellere (5–10 Sekunden) Apache Spark-Sitzungsstarterfahrung für Benutzer, um den Einstieg zu erleichtern und Ihre Apache Spark-Aufträge in vielen gängigen Szenarien auszuführen, ohne sich um die Einrichtung der Compute kümmern zu müssen. Für erweiterte Szenarien mit bestimmten Computeanforderungen können Benutzer einen benutzerdefinierten Apache Spark-Pool erstellen und die Knoten auf der Grundlage ihrer Leistungsanforderungen dimensionieren.
Um Änderungen an den Apache Spark-Einstellungen in einem Arbeitsbereich vorzunehmen, sollten Sie über die Administratorrolle für diesen Arbeitsbereich verfügen. Weitere Informationen dazu finden Sie unter Rollen in Arbeitsbereichen.
So verwalten Sie die Spark-Einstellungen für den Pool, der Ihrem Arbeitsbereich zugeordnet ist:
Wechseln Sie zu den Arbeitsbereichseinstellungen in Ihrem Arbeitsbereich, und wählen Sie die Option Datentechnik/Wissenschaft aus, um das Menü zu erweitern:
Die Spark Compute-Option wird im linken Menü angezeigt:
Hinweis
Wenn Sie den standardmäßigen Startpool in einen benutzerdefinierten Spark-Pool ändern, dauert der Sitzungsstart unter Umständen länger (ca. drei Minuten).

Pool
Standardpool für den Arbeitsbereich
Sie können den automatisch erstellten Startpool verwenden oder benutzerdefinierte Pools für den Arbeitsbereich erstellen.
Startpool: Zur Beschleunigung Ihrer Erfahrung werden automatisch vorab aufgefüllte Livepools erstellt. Diese Cluster haben eine mittlere Größe. Der Startpool wird auf eine Standardkonfiguration festgelegt, die auf der erworbenen Fabric-Kapazitäts-SKU basiert. Administrator*innen können die maximale Anzahl von Knoten und Executors basierend auf ihren Skalierungsanforderungen für Spark-Workloads anpassen. Weitere Informationen finden Sie unter Konfigurieren von Startpools
Benutzerdefinierter Spark-Pool: Sie können die Knoten skalieren, automatisch skalieren und Executors gemäß den Anforderungen Ihres Spark-Auftrags dynamisch zuordnen. Um einen benutzerdefinierten Spark-Pool zu erstellen, sollte der Kapazitätsadministrator die Option Angepasste Arbeitsbereichspools im Abschnitt Spark Compute der Kapazitätsadministrator-Einstellungen aktivieren.
Hinweis
Die Steuerung auf Kapazitätsebene für angepasste Arbeitsbereichspools ist standardmäßig aktiviert. Weitere Informationen finden Sie unter Konfigurieren und Verwalten von Datentechnik- und Data Science-Einstellungen für Fabric-Kapazitäten.
Administratoren können benutzerdefinierte Spark-Pools basierend auf ihren Computeanforderungen erstellen, indem sie die Option Neuer Pool auswählen.

Apache Spark für Microsoft Fabric unterstützt Einzelknotencluster, sodass Benutzer eine Mindestknotenkonfiguration von 1 auswählen können. In diesem Fall werden Treiber und Executor auf einem einzelnen Knoten ausgeführt. Diese Einzelknotencluster bieten wiederherstellbare Hochverfügbarkeit bei Knotenausfällen und eine bessere Auftragszuverlässigkeit für Workloads mit geringeren Computeanforderungen. Sie können ferner die Option für die automatische Skalierung für Ihre benutzerdefinierten Spark-Pools aktivieren oder deaktivieren. Wenn die automatische Skalierung aktiviert ist, ruft der Pool neue Knoten innerhalb des vom Benutzer angegebenen maximalen Knotenlimits ab, um die Leistung zu verbessern, und beendet sie nach der Auftragsausführung.
Sie können auch die Option für die dynamische Zuweisung von Executors auswählen, um automatisch innerhalb des maximalen Grenzwerts die optimale Anzahl von Executors zu poolen, die auf der Grundlage des Datenvolumens angegeben wird, um eine bessere Leistung zu erzielen.

Weitere Informationen über Apache Spark Compute for Fabric.
- Anpassen der Computekonfiguration für Elemente: Arbeitsbereichsadministrator*innen können Benutzer*innen das Anpassen von Computekonfigurationen (Eigenschaften auf Sitzungsebene, einschließlich Kern und Arbeitsspeicher für Treiber/Executor) für einzelne Elemente wie Notebooks und Spark-Auftragsdefinitionen mithilfe einer Umgebung ermöglichen.
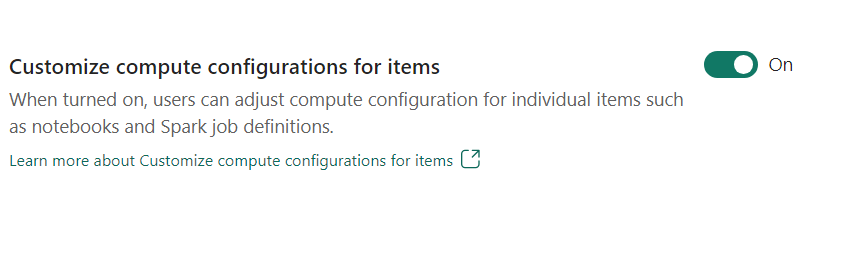
Wenn die Einstellung vom Arbeitsbereichsadministrator deaktiviert wird, werden der Standardpool und die zugehörigen Computekonfigurationen für alle Umgebungen im Arbeitsbereich verwendet.
Environment
Die Umgebung bietet flexible Konfigurationen zum Ausführen Ihrer Spark-Aufträge (Notebooks, Spark-Auftragsdefinitionen). In einer Umgebung können Sie Computeeigenschaften konfigurieren, eine andere Runtime auswählen und Bibliothekspaketabhängigkeiten basierend auf Ihren Workloadanforderungen einrichten.
Auf der Registerkarte „Umgebung“ können Sie die Standardumgebung festlegen. Sie können wählen, welche Spark-Version Sie für den Arbeitsbereich verwenden möchten.
Fabric-Arbeitsbereichsadministrator*innen können eine Umgebung als Standardumgebung für Arbeitsbereiche auswählen.
Sie können auch eine neue Umgebung über das Dropdownmenü Umgebung erstellen.

Wenn Sie die Option für die Standardumgebung deaktivieren, haben Sie die Möglichkeit, die Version der Fabric-Runtime aus den in der Dropdownliste verfügbaren Runtimeversionen auszuwählen.

Weitere Informationen über Apache Spark-Runtimes.
Aufträge
Mit den Auftragseinstellungen können Administratoren die Auftragszulassungslogik für alle Spark-Aufträge im Arbeitsbereich steuern.

Standardmäßig sind alle Arbeitsbereiche mit optimistischer Auftragszulassung aktiviert. Erfahren Sie mehr über die Auftragszulassung für Spark in Microsoft Fabric.
Sie können die Option Maximalkerne für aktive Spark-Aufträge reservieren aktivieren, um den Ansatz für die optimistische Auftragszulassung zu deaktivieren und maximale Kerne für ihre Spark-Aufträge zu reservieren.
Sie können auch das Zeitlimit für Spark-Sitzungen festlegen, um den Sitzungsablauf für alle interaktiven Notebook-Sitzungen anzupassen.
Hinweis
Der standardmäßige Sitzungsablauf ist für die interaktiven Spark-Sitzungen auf 20 Minuten festgelegt.
Hohe Parallelität
Im Modus für hohe Parallelität können Benutzer*innen Spark-Sitzungen in Apache Spark für Fabric Datentechnik- und Data Science-Workloads gemeinsam nutzen. Für die Ausführung eines Elements (etwa eines Notebooks) wird eine Spark-Sitzung verwendet. Ist diese Option aktiviert, können Benutzer*innen eine einzelne Spark-Sitzung für mehrere Notebooks freigeben.

Erfahren Sie mehr über Hohe Parallelität in Apache Spark für Fabric.
Automatische Protokollierung für Machine Learning-Modelle und -Experimente
Administratoren können jetzt die automatische Protokollierung für ihre Machine Learning-Modelle und -Experimente aktivieren. Diese Option erfasst automatisch die Werte von Eingabeparametern, Ausgabemetriken und Ausgabeelementen eines Machine Learning-Modells, während es trainiert wird. Weitere Informationen zur automatischen Protokollierung.

Zugehöriger Inhalt
- Lesen Sie mehr über Apache Spark Runtimes in Fabric – Übersicht, Versionsverwaltung, Unterstützung für mehrere Runtimes und Upgrade des Delta Lake Protocol.
- Weitere Informationen finden Sie in der öffentlichen Dokumentation zu Apache Spark.
- Hier finden Sie Antworten auf häufig gestellte Fragen: Häufig gestellte Fragen zu Apache Spark-Arbeitsbereichs-Verwaltungseinstellungen.