Erstellen und Verwalten von Apache Spark-Auftragsdefinitionen in Visual Studio Code
Die Visual Studio (VS) Code-Erweiterung für Synapse unterstützt die CURD-Auftragsdefinition von Spark (Erstellen, Aktualisieren, Lesen und Löschen) in Fabric in vollem Umfang. Nach dem Erstellen einer Spark-Auftragsdefinition können Sie weitere Referenzbibliotheken hochladen, eine Anforderung zum Ausführen der Spark-Auftragsdefinition senden und den Ausführungsverlauf überprüfen.
Erstellen einer Spark-Auftragsdefinition
So erstellen Sie eine neue Spark-Auftragsdefinition:
Wählen Sie im VS Code-Explorer die Option Spark-Auftragsdefinition erstellen aus.

Geben Sie die anfänglich erforderlichen Felder ein: „name“, „referenced lakehouse“ und „default lakehouse“.
Die Anforderung wird verarbeitet und der Name Ihrer neu erstellten Spark-Auftragsdefinition wird unter dem Stammknoten Spark-Auftragsdefinition im VS Code-Explorer angezeigt. Unter dem Namensknoten „Spark-Auftragsdefinition“ werden drei Unterknoten angezeigt:
- Dateien: Liste der Hauptdefinitionsdatei und weiterer Bibliotheken, auf die verwiesen wird. Sie können neue Dateien aus dieser Liste hochladen.
- Lakehouse: Liste aller Lakehouses, auf die von dieser Spark-Auftragsdefinition verwiesen wird. Das Standard-Lakehouse ist in der Liste markiert, und Sie können über den relativen Pfad
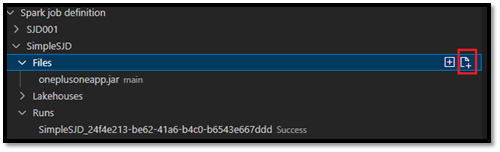
Files/…, Tables/…darauf zugreifen. - Ausführen: Liste des Ausführungsverlaufs dieser Spark-Auftragsdefinition und der Auftragsstatus jeder Ausführung.
Hochladen einer Hauptdefinitionsdatei in eine Bibliothek, auf die verwiesen wird
Zum Hochladen oder Überschreiben der Hauptdefinitionsdatei wählen Sie die Option Hauptdatei hinzufügen aus.
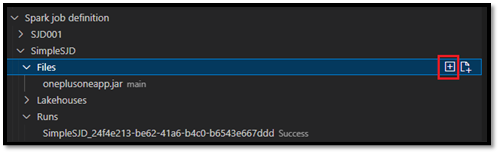
Zum Hochladen der Bibliotheksdatei, auf die die Hauptdefinitionsdatei verweist, wählen Sie die Option Lib-Datei hinzufügen aus.
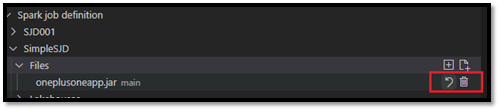
Nachdem Sie eine Datei hochgeladen haben, können Sie sie überschreiben, indem Sie auf die Option Datei aktualisieren klicken und eine neue Datei hochladen, oder Sie können die Datei über die Option Löschen löschen.
Übermitteln einer Ausführungsanforderung
So übermitteln Sie eine Anforderung zum Ausführen der Spark-Auftragsdefinition aus VS Code:
Wählen Sie in den Optionen rechts neben dem Namen der Spark-Auftragsdefinition, die Sie ausführen möchten, die Option Spark-Auftrag ausführen aus.

Nachdem Sie die Anforderung übermittelt haben, wird im Knoten Ausführungen in der Explorer-Liste eine neue Apache Spark-Anwendung angezeigt. Sie können den ausgeführten Auftrag abbrechen, indem Sie die Option Spark-Auftrag abbrechen auswählen.
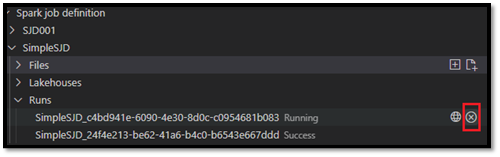
Öffnen einer Spark-Auftragsdefinition im Fabric-Portal
Sie können die Seite zum Erstellen von Spark-Auftragsdefinitionen im Fabric-Portal öffnen, indem Sie die Option Im Browser öffnen auswählen.
Sie können außerdem Im Browser öffnen neben einer abgeschlossenen Ausführung auswählen, um die Detailüberwachungsseite dieser Ausführung anzuzeigen.

Debuggen des Quellcodes für die Spark-Auftragsdefinition (Python)
Wenn die Spark-Auftragsdefinition mit PySpark (Python) erstellt wird, können Sie das PY-Skript der Hauptdefinitionsdatei und der Datei, auf die verwiesen wird, herunterladen und das Quellskript in VS Code debuggen.
Zum Herunterladen des Quellcodes wählen Sie rechts neben der Spark-Auftragsdefinition die Option Spark-Auftragsdefinition debuggen aus.

Nachdem der Download abgeschlossen ist, wird der Ordner des Quellcodes automatisch geöffnet.
Wählen Sie die Option Den Autoren vertrauen aus, wenn Sie dazu aufgefordert werden. (Diese Option wird nur beim ersten Öffnen des Ordners angezeigt. Wenn Sie diese Option nicht auswählen, können Sie das Quellskript nicht debuggen oder ausführen. Weitere Informationen finden Sie unter Sicherheit von Vertrauensstellungen im Visual Studio Code-Arbeitsbereich.)
Wenn Sie den Quellcode bereits heruntergeladen haben, werden Sie aufgefordert, zu bestätigen, dass Sie die lokale Version durch den neuen Download überschreiben möchten.
Hinweis
Im Stammordner des Quellskripts erstellt das System einen Unterordner namens conf. In diesem Ordner enthält eine Datei namens lighter-config.json einige Systemmetadaten, die für die Remoteausführung erforderlich sind. Nehmen Sie KEINE Änderungen daran vor.
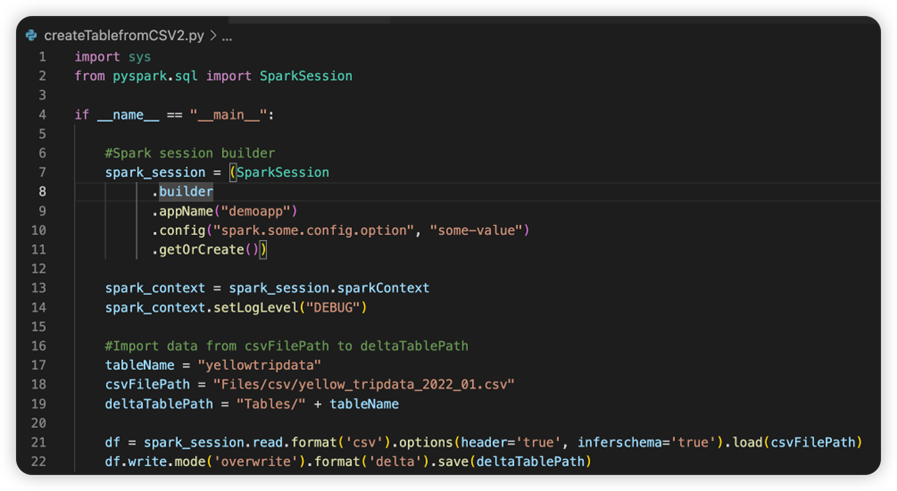
Die Datei mit dem Namen sparkconf.py enthält einen Codeschnipsel, den Sie zum Einrichten des SparkConf-Objekts hinzufügen müssen. Zum Aktivieren des Remotedebuggens stellen Sie sicher, dass das SparkConf-Objekt ordnungsgemäß eingerichtet ist. Die folgende Abbildung zeigt die ursprüngliche Version des Quellcodes.
Das nächste Bild ist der aktualisierte Quellcode, nachdem Sie den Codeschnipsel kopiert und eingefügt haben.
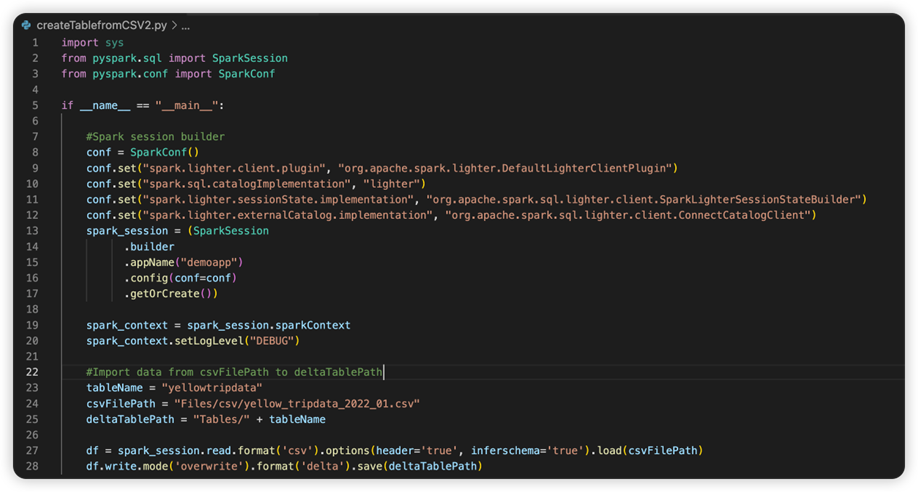
Nachdem Sie den Quellcode mit der erforderlichen Conf aktualisiert haben, müssen Sie den richtigen Python-Interpreter auswählen. Achten Sie darauf, den aus der synapse-spark-kernel-Conda-Umgebung installierten auszuwählen.
Bearbeiten der Eigenschaften von Spark-Auftragsdefinitionen
Sie können die Detaileigenschaften von Spark-Auftragsdefinitionen bearbeiten, z. B. Befehlszeilenargumente.
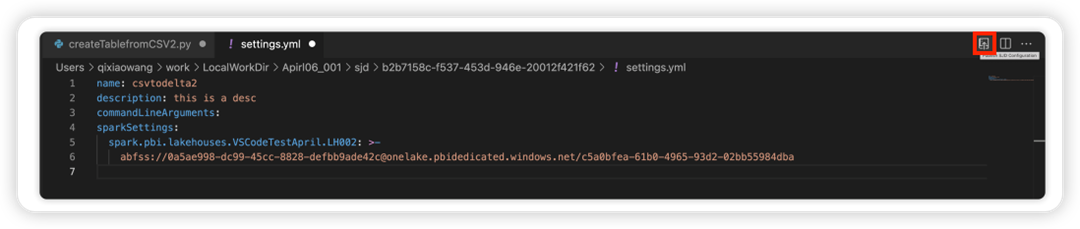
Wählen Sie die Option SJD-Konfiguration aktualisieren aus, um eine settings.yml-Datei zu öffnen. Die vorhandenen Eigenschaften füllen den Inhalt dieser Datei auf.
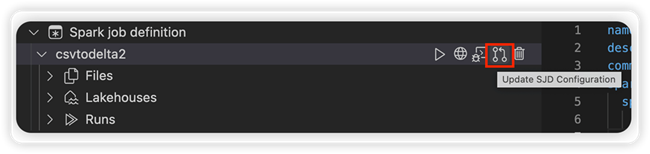
Aktualisieren und speichern Sie die YML-Datei.
Wählen Sie oben rechts die Option SJD-Eigenschaft veröffentlichen aus, um die Änderung wieder mit dem Remotearbeitsbereich zu synchronisieren.