Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Diese Inhalte sind ein Auszug aus dem eBook „.NET Microservices Architecture for Containerized .NET Applications“, verfügbar unter .NET Docs oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

In verteilten Systemen wie Anwendungen, die auf Microservices basieren, gibt es ein allgegenwärtiges Risiko für Teilfehler. Zum Beispiel kann ein einzelner Microservice oder Container fehlschlagen oder für eine kurze Zeit nicht verfügbar sein, oder eine einzelne VM oder ein Server kann abstürzen. Da Clients und Dienste separate Vorgänge sind, kann ein Dienst möglicherweise nicht schnell genug auf die Anforderung eines Clients reagieren. Der Dienst ist möglicherweise überlastet und antwortet sehr langsam auf Anforderungen, oder er ist aufgrund von Netzwerkproblemen vorübergehend nicht verfügbar.
Nehmen Sie sich ein Beispiel an der Seite „Auftragsdetails“ der Beispielanwendung „eShopOnContainers“. Wenn der Microservice für Bestellungen nicht mehr reagiert, wenn der Benutzer versucht, einen Auftrag zu übermitteln, würde eine schlechte Implementierung des Clientprozesses (die MVC-Webanwendung) Threads auf unbestimmte Zeit blockieren, da er auf eine Antwort wartet, z.B. wenn der Clientcode synchrone RPCs ohne Timeout verwendet. Dies reduziert nicht nur die Benutzerfreundlichkeit, denn zusätzlich verbraucht oder blockiert jeder Wartevorgang ohne Reaktion einen Thread. Threads sind in hochgradig skalierbaren Anwendungen jedoch sehr wertvoll. Wenn viele Threads blockiert werden, sind für die Laufzeit der Anwendung irgendwann keine Threads mehr verfügbar. In diesem Fall kann es dazu kommen, dass die Anwendung wie in Abbildung 8-1 dargestellt global statt nur teilweise nicht mehr reagiert.
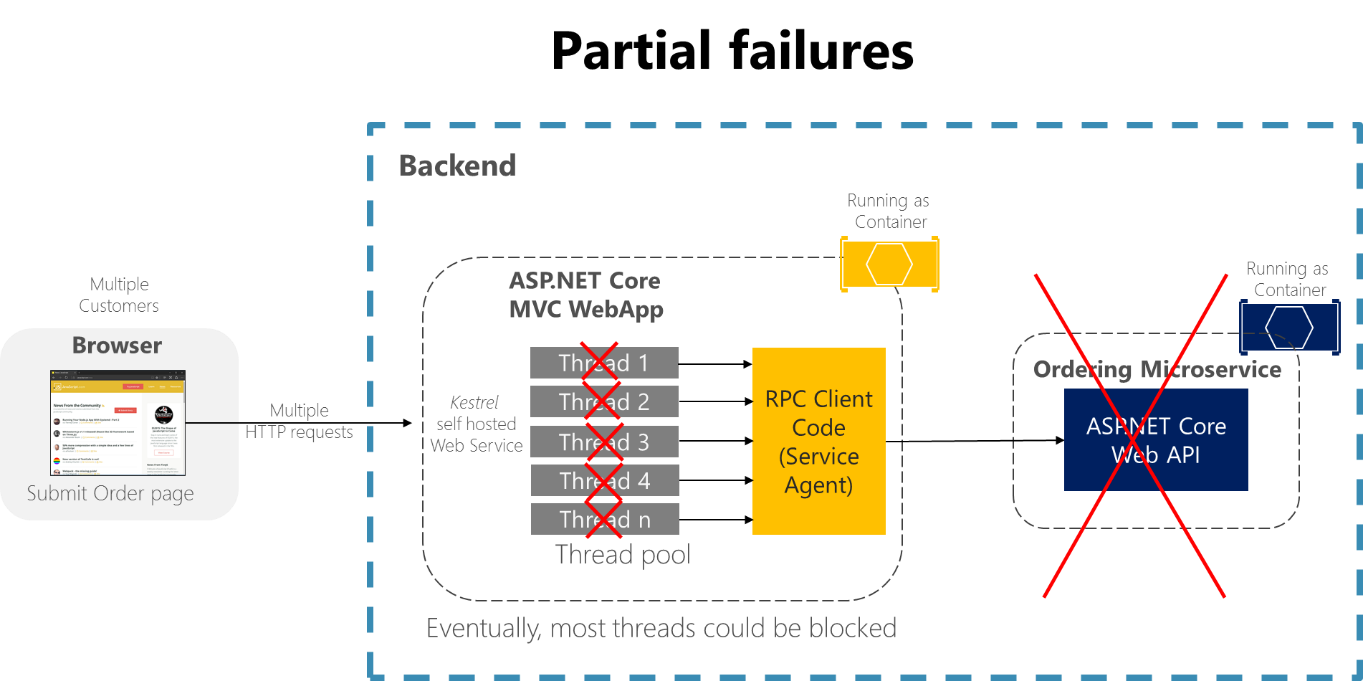
Abbildung 8-1. Teilfehler treten wegen Abhängigkeiten auf, die die Verfügbarkeit von Dienstthreads beeinflussen
In einer großen, auf Microservices basierten Anwendung können Teilfehler vor allem verstärkt werden, wenn der Großteil der internen Interaktionen von Microservices auf synchronen HTTP-Aufrufen basiert (dies gilt als Antimuster). Stellen Sie sich ein System vor, das täglich Millionen von eingehenden Aufrufen empfängt. Wenn Ihr System schlecht entworfen ist und auf langen Ketten von synchronen HTTP-Aufrufen basiert, können diese eingehenden Aufrufe in vielen weiteren Millionen von ausgehenden Aufrufen (z. B. ein Verhältnis von 1:4) an dutzende interne Microservices als synchrone Abhängigkeiten resultieren. Diese Situation wird in Abbildung 8-2 veranschaulicht, insbesondere in Abhängigkeit #3, die eine Kette beginnt, indem sie Abhängigkeit #4 aufruft, die wiederum #5 aufruft.
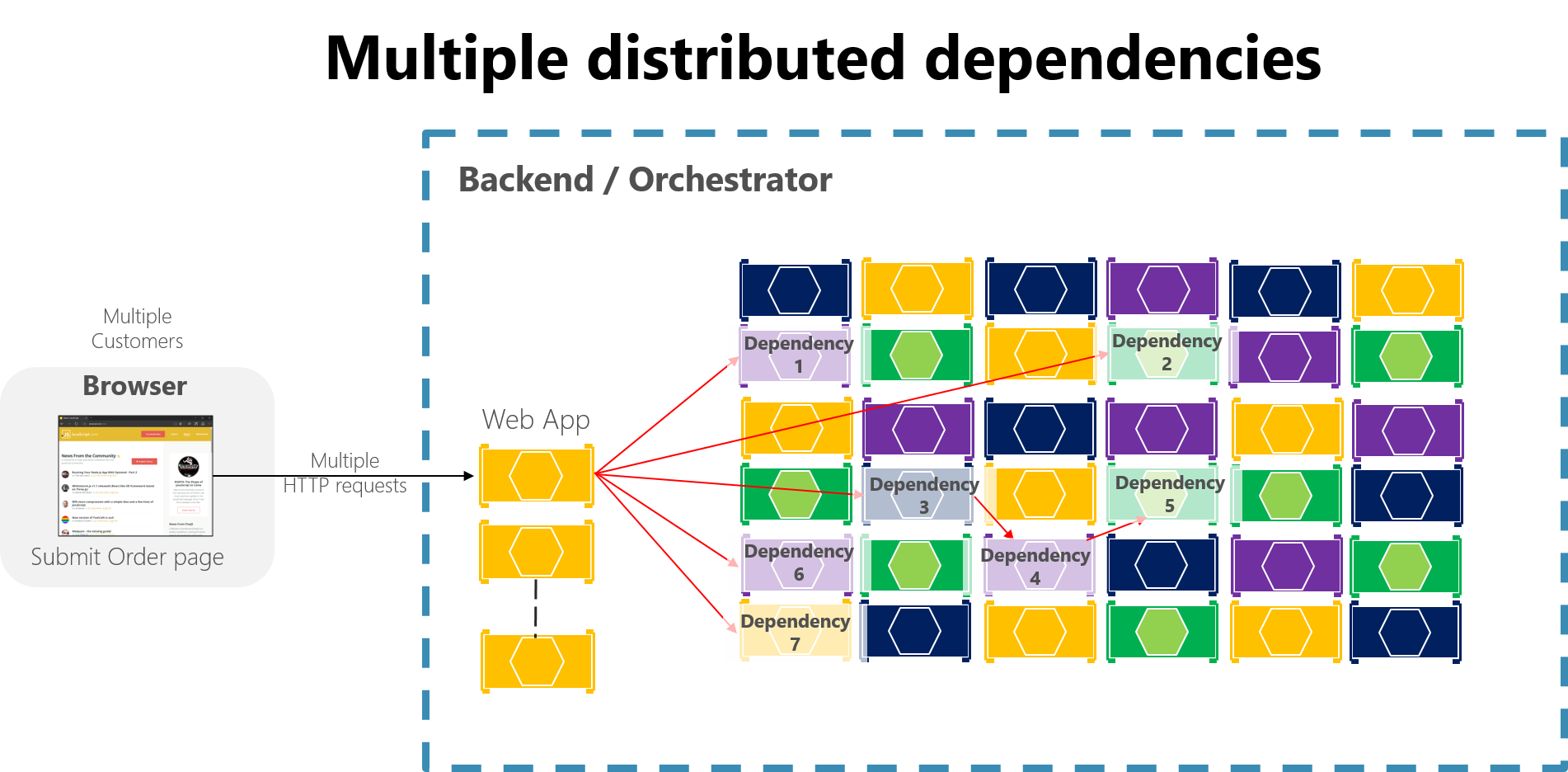
Abbildung 8-2. Die Auswirkungen eines falschen Entwurfs mit langen Ketten von HTTP-Anforderungen
Zeitweilige Fehler sind in einem verteilten und cloudbasierten System garantiert, auch wenn jede Abhängigkeit eine hervorragende Verfügbarkeit aufweist. Diese Tatsache müssen Sie berücksichtigen.
Wenn Sie keine Techniken für die Fehlertoleranz entwerfen oder implementieren, können selbst kleine Ausfälle verstärkt werden. Wegen dieser ausbreitenden Wirkung würden zum Beispiel 50 Abhängigkeiten mit einer Verfügbarkeit von 99,99% für mehrere Stunden im Monat ausfallen. Wenn eine Microserviceabhängigkeit beim Behandeln einer großen Anzahl von Anforderungen fehlschlägt, kann dieser Fehler schnell alle verfügbaren Anforderungsthreads in jedem Dienst beanspruchen und die gesamte Anwendung zum Abstürzen bringen.
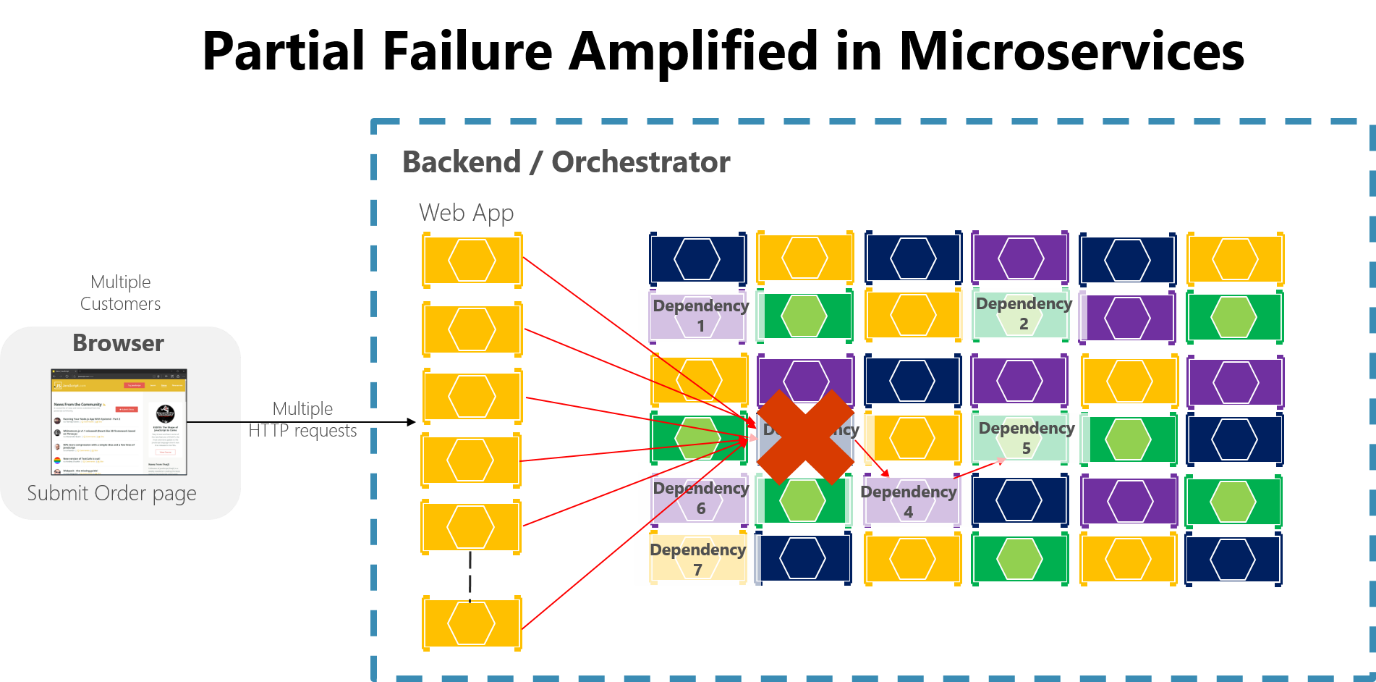
Abbildung 8-3. Teilfehler, der durch Microservices mit langen Ketten von synchronen HTTP-Aufrufen verstärkt wurde
Zur Minimierung dieses Problems wird im Abschnitt Asynchrone Integration von Microservices erzwingt die Autonomie eines Microservice dieses Leitfadens empfohlen, die asynchrone Kommunikation zwischen den internen Microservices zu verwenden.
Darüber hinaus ist es wichtig, dass Sie Ihre Microservices und Clientanwendungen dafür entwerfen, Teilfehler zu behandeln – d.h. robuste Microservices und Clientanwendungen zu erstellen.
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.