Kommunikation in einer Microservicearchitektur
Tipp
Diese Inhalte sind ein Auszug aus dem eBook „.NET Microservices Architecture for Containerized .NET Applications“, verfügbar unter .NET Docs oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

In einer monolithischen-Anwendung, die in einem einzelnen Prozess ausgeführt wird, rufen sich die Komponenten gegenseitig mit Methoden- oder Funktionsaufrufen auf Sprachebene auf. Diese können stark gekoppelt sein, wenn Sie Objekte mit Code erstellen (z.B. new ClassName()), oder entkoppelt aufgerufen werden, wenn Sie die Abhängigkeitsinjektion verwenden, indem Sie auf Abstraktionen und nicht auf konkrete Objektinstanzen verweisen. In beiden Fällen werden die Objekte innerhalb des gleichen Prozesses ausgeführt. Die größte Herausforderung bei der Änderung einer monolithischen Anwendung in eine auf Microservices basierende Anwendung besteht in der Änderung des Kommunikationsmechanismus. Eine direkte Konvertierung von prozessinternen Methodenaufrufen in RPC-Aufrufe bei Diensten verursacht eine wortreiche und ineffiziente Kommunikation, die in verteilten Umgebungen nicht zufriedenstellend funktioniert. Die Herausforderungen beim ordnungsgemäßen Entwerfen eines verteilten Systems gut bekannt, dass es dazu sogar den Kanon Irrtümer der verteilten Verarbeitung gibt. Darin werden Vermutungen aufgeführt, die Entwickler häufig anstellen, wenn sie von monolithischen zu verteilten Entwürfen wechseln.
Es gibt nicht eine, sondern mehrere Lösungen. Bei einer Lösung werden die Unternehmensmicroservices so weit wie möglich isoliert. Anschließend verwenden Sie zwischen den internen Microservices eine asynchrone Kommunikation und ersetzen die für die prozessinterne Kommunikation zwischen Objekten typische differenzierte Kommunikation durch die undifferenzierte Kommunikation. Hierzu können Sie Aufrufe gruppieren und Daten zurückgeben, welche die Ergebnisse mehrerer interner Aufrufe an den Client aggregieren.
Bei einer auf Microservices basierenden Anwendung handelt es sich um ein verteiltes System, das in mehreren Prozessen oder Services ausgeführt wird und normalerweise sogar mehrere Server oder Hosts übergreift. Jede Dienstinstanz ist in der Regel ein Prozess. Daher müssen Dienste bei der Interaktion ein prozessinternes Kommunikationsprotokoll wie HTTP, AMQP oder ein Binärprotokoll wie TCP verwenden. Welches Protokoll verwendet wird, hängt von der Art des jeweiligen Diensts ab.
Die Microservice-Community unterstützt den Ansatz „smart endpoints and dumb pipes“ (intelligente Endpunkte und dumme Pipes). Dieses Motto unterstützt einen Entwurf, der zwischen Microservices möglichst entkoppelt und innerhalb eines einzelnen Microservices möglichst kohäsiv ist. Wie zuvor erläutert wurde, verfügt jeder Microservice über seine eigenen Daten und seine eigene Domänenlogik. Die Microservices, die eine End-to-End-Anwendung erstellen, sind jedoch in der Regel einfach choreografiert, indem REST-Kommunikationen statt komplexer Protokolle wie WS-* und flexible, ereignisgesteuerte Kommunikationen statt zentralisierter Geschäftsprozessorchestratoren verwendet werden.
Die zwei häufig verwendeten Protokolle sind HTTP-Anforderung/-Antwort mit Ressourcen-APIs (bei den meisten Abfragen) und asynchrones Lightweight-Messaging, das bei der Kommunikation von Updates mehrere Microservices übergreifend zum Einsatz kommt. In den folgenden Abschnitten werden diese Protokolle näher erläutert.
Kommunikationstypen
Clients und Dienste können über viele verschiedene Kommunikationstypen miteinander kommunizieren, von denen alle unterschiedliche Szenarios und Ziele zum Gegenstand haben. Diese Kommunikationstypen können zunächst in zwei Achsen klassifiziert werden.
Auf der ersten Achse wird definiert, ob das Protokoll synchron oder asynchron ist:
Synchrones Protokoll. HTTP ist ein synchrones Protokoll. Der Client sendet eine Anforderung und wartet auf eine Antwort vom Dienst. Das geschieht unabhängig von der Ausführung des Clientcodes, der synchron (Thread ist blockiert) oder asynchron (Thread ist nicht blockiert und die Antwort erreicht schließlich einen Rückruf) sein könnte. Wichtig ist in diesem Zusammenhang, dass das Protokoll (HTTP/HTTPS) synchron ist und der Clientcode den Vorgang nur dann fortsetzen kann, wenn er die Antwort vom HTTP-Server empfängt.
Asynchrones Protokoll. Andere Protokolle wie z.B. AMQP (ein Protokoll, das von vielen Betriebssystemen und Cloudumgebungen unterstützt wird) verwenden asynchrone Nachrichten. Der Absender des Clientcodes oder der Nachricht wartet in der Regel nicht auf eine Antwort. Er sendet die Nachricht so, als würde er eine Nachricht an eine RabbitMQ-Warteschlange oder einen anderen Nachrichtenbroker senden.
Auf der zweiten Achse wird definiert, ob die Kommunikation über einen einzelnen oder mehrere Empfänger verfügt:
Einzelner Empfänger. Jede Anforderung muss von genau einem Empfänger oder Dienst verarbeitet werden. Ein Beispiel für diese Kommunikation ist das Befehlsmuster.
Mehrere Empfänger. Jede Anforderung kann von 0 (null) bis hin zu mehreren Empfängern verarbeitet werden. Dieser Kommunikationstyp muss asynchron sein. Ein Beispiel hierfür ist der Mechanismus publish/subscribe, der in Mustern wie der ereignisgesteuerten Architektur verwendet wird. Diese basiert bei der Verteilung von Datenupdates über Ereignisse zwischen mehreren Microservices auf einer Ereignisbusschnittstelle oder einem Nachrichtenbroker. Sie wird in der Regel über einen Servicebus oder ein mit Azure Service Bus vergleichbares Artefakt unter Verwendung von Themen und Abonnements implementiert.
Eine auf Microservices basierende Anwendung verwendet häufig eine Kombination aus diesen Kommunikationstypen. Am häufigsten wird als Kommunikationstyp die Kommunikation über einzelne Empfänger mit einem synchronen Protokoll wie HTTP/HTTPS verwendet, wenn ein regulärer HTTP-Dienst der Web-API aufgerufen wird. Zudem verwenden Microservices für die asynchrone Kommunikation zwischen Microservices in der Regel Messagingprotokolle.
Sie sollten sich mit diesen Achsen vertraut machen, um die möglichen Kommunikationsmechanismen zu kennen. Beim Erstellen von Microservices spielen Sie jedoch keine bedeutende Rolle. Bei der Integration von Microservices stehen weder die asynchronen Eigenschaften der Clientthreadausführung noch die asynchronen Eigenschaften des ausgewählten Protokolls im Vordergrund. Was wirklich wichtig ist, ist die Möglichkeit, Ihre Microservices asynchron integrieren zu können und gleichzeitig die Unabhängigkeit der Microservices zu erhalten. Dies wird im folgenden Abschnitt erläutert.
Asynchrone Integration von Microservices erzwingt die Unabhängigkeit eines Microservices
Wie zuvor erwähnt, steht bei der Erstellung einer auf Microservices basierenden Anwendung die Integrationsart Ihrer Microservices im Vordergrund. Im Idealfall sollten Sie versuchen, die Kommunikation zwischen den internen Microservices zu minimieren. Je weniger Kommunikation zwischen Microservices stattfindet, desto besser. In vielen Fällen müssen Sie die Microservices integrieren. Wenn dies erforderlich ist, gilt als entscheidende Regel, dass die Kommunikation zwischen den Microservices asynchron sein sollte. Das bedeutet nicht, dass Sie ein bestimmtes Protokoll verwenden müssen (z.B. asynchrones Messaging im Vergleich zu synchronem HTTP). Es bedeutet lediglich, dass die Kommunikation zwischen Microservices nur über die asynchrone Verteilung von Daten erfolgen sollte. Versuchen Sie jedoch beim ersten Vorgang der HTTP-Anforderung/Antwort des Diensts nicht von anderen internen Microservices abhängig zu sein.
Machen Sie sich möglichst nie von synchroner Kommunikation (Anforderung/Antwort) zwischen mehreren Microservices abhängig, auch nicht bei Abfragen. Das Ziel der einzelnen Microservices besteht darin, autonom und für den Clientconsumer verfügbar zu sein. Dies gilt auch dann, wenn die anderen Dienste der End-to-End-Anwendung inaktiv oder fehlerhaft sind. Wenn Sie einen Aufruf von einem Microservice an andere Microservices ausführen möchten (z.B. das Ausführen einer HTTP-Anforderung für eine Datenabfrage), um eine Antwort für eine Clientanwendung bereitstellen zu können, verfügen Sie über eine Architektur, die beim Fehlschlagen einiger Microservices nicht stabil sein wird.
Darüber hinaus verlieren Ihre Microservices durch HTTP-Abhängigkeiten zwischen Microservices, z.B. beim Erstellen langer Anforderungs-/Antwortzyklen mit HTTP-Anforderungsketten (s. erster Abschnitt von Abbildung 4-15), ihre Unabhängigkeit. Zudem wird ihre Leistung beeinträchtigt, sobald einer der Dienste in dieser Kette nicht ordnungsgemäß funktioniert.
Je mehr Sie synchrone Abhängigkeiten zwischen Microservices hinzufügen, z.B. in Form von Abfrageanforderungen, desto schlechter wird die Gesamtantwortzeit bei den Client-Apps.
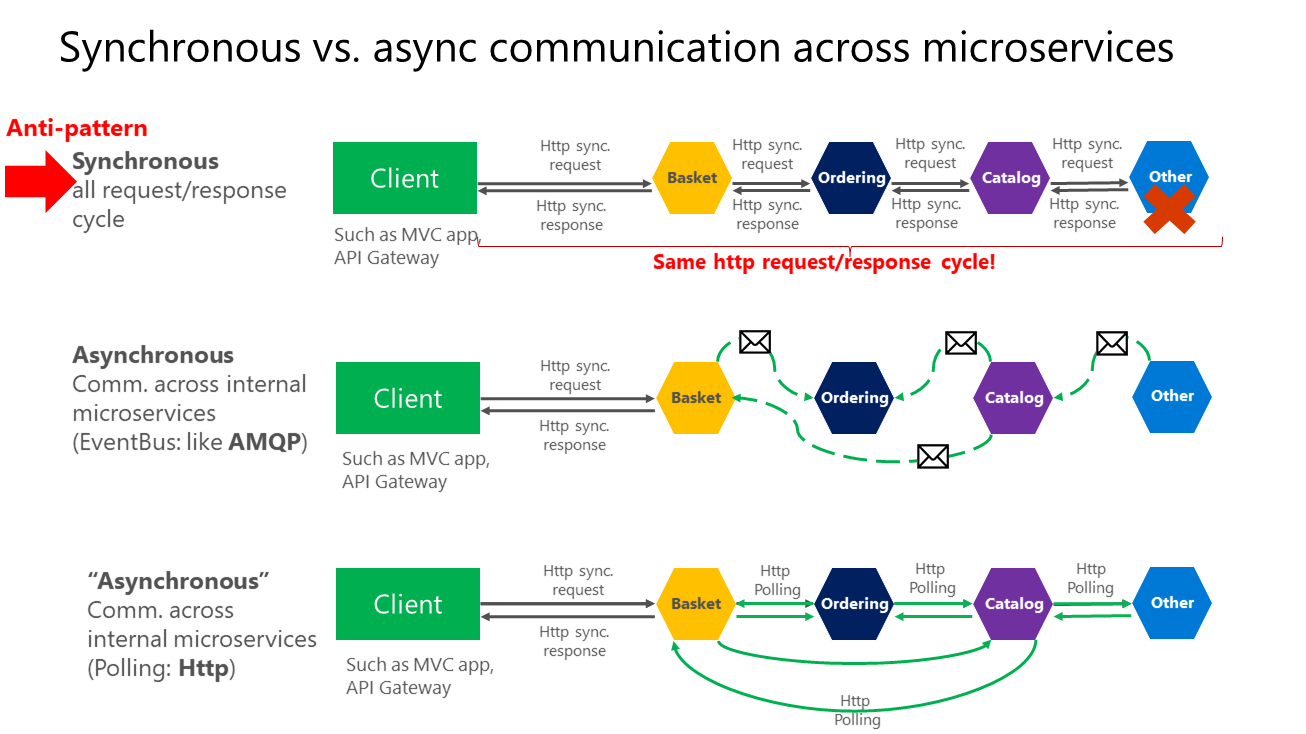
Abbildung 4-15. Antimuster und Muster bei der Kommunikation zwischen Microservices
Wie in dem obigen Diagramm gezeigt, wird in der synchronen Kommunikation eine „Kette“ von Anforderungen zwischen Microservices erstellt, während die Clientanforderung verarbeitet wird. Dies ist ein Antimuster. In der asynchronen Kommunikation verwenden Microservices asynchrone Nachrichten oder HTTP-Abrufe zur Kommunikation mit anderen Microservices – die Clientanforderung wird sofort beantwortet.
Wenn Ihr Microservice eine weitere Aktion in einem anderen Microservice auslösen muss, sollten Sie diese Aktion möglichst nicht synchron und im Rahmen des ursprünglichen Anforderungs- und Antwortvorgangs des Microservices ausführen. Führen Sie die Aktion stattdessen asynchron aus (über asynchrones Messaging oder Integrationsereignisse, Warteschlangen usw.). Rufen Sie die Aktion jedoch möglichst nicht synchron im Rahmen des ursprünglichen synchronen Anforderungs- und Antwortvorgangs auf.
Und schließlich sollten Sie sich nicht auf die Erstellung synchroner Anforderungen für Daten stützen, wenn Ihr ursprünglicher Microservice Daten benötigt, die ursprünglich zu anderen Microservices gehörten (an diesem Punkt treten beim Erstellen von Microservices die meisten Probleme auf). Stattdessen können Sie diese Daten (nur die benötigten Attribute) in der Datenbank des ersten Dienstes replizieren oder verteilen, indem Sie die letztliche Konsistenz verwenden (in der Regel über Integrationsereignisse, wie in den folgenden Abschnitten erläutert).
Wie zuvor im Abschnitt Identifizieren von Domänenmodellgrenzen für jeden Microservice erwähnt, stellt das Duplizieren einiger Daten in mehreren Microservices keinen falschen Entwurf dar. Im Gegenteil: Dadurch können Sie die Daten in die spezifische Sprache bzw. Benennungen dieser zusätzlichen Domäne oder des begrenzten Kontexts übersetzen. In der Anwendung eShopOnContainers gibt es beispielsweise den Microservice identity-api, der bei der Entität User für die meisten Benutzerdaten zuständig ist. Wenn Sie jedoch Daten über den Benutzer im Microservice Ordering speichern müssen, speichern Sie diese unter einer anderen Entität mit dem Namen Buyer. Die Entität Buyer weist die gleiche Identität wie die ursprüngliche Entität User auf, sie verfügt jedoch möglicherweise nur über die Attribute, die von der Domäne Ordering benötigt werden, und nicht über das gesamte Benutzerprofil.
Sie können für die Microservices übergreifende asynchrone Übertragung und Weitergabe von Daten ein beliebiges Protokoll verwenden, um die letztliche Konsistenz zu erhalten. Wie bereits erwähnt, könnten Sie Integrationsereignisse mithilfe eines Ereignisbus oder Nachrichtenbrokers verwenden. Alternativ könnten Sie auch HTTP verwenden, indem Sie stattdessen die anderen Dienste abrufen. Die Vorgehensweise ist nicht wichtig. Wichtig ist, dass Sie keine synchronen Abhängigkeiten zwischen Ihren Microservices schaffen.
In den folgenden Abschnitten werden die verschiedenen Kommunikationsstile erläutert, die für die Verwendung in einer auf Microservices basierenden Anwendung in Betracht kommen.
Kommunikationsstile
Abhängig von dem zu verwendenden Kommunikationstyp können Sie zwischen vielen Protokollen und Optionen auswählen, die für die Kommunikation verwendet werden können. Wenn Sie einen synchronen, auf Anforderungen/Antworten basierenden Kommunikationsmechanismus verwenden, kommen am häufigsten HTTP- und REST-Protokolle zum Einsatz, insbesondere dann, wenn Sie Ihre Dienste außerhalb des Docker-Hosts oder des Microserviceclusters veröffentlichen. Bei der internen Kommunikation zwischen Diensten (innerhalb Ihres Docker-Hosts oder Microserviceclusters) können Sie auch Kommunikationsmechanismen im Binärformat verwenden (z.B. WCF über TCP und Binärformat). Alternativ können Sie auch asynchrone, nachrichtenbasierte Kommunikationsmechanismen wie AMQP verwenden.
Es gibt auch mehrere Nachrichtenformate wie JSON, XML oder sogar Binärformate, die effizienter sein können. Wenn es sich bei dem von Ihnen ausgewählten Binärformat um keinen Standard handelt, sollten Sie Ihre Dienste nicht mit diesem Format öffentlich veröffentlichen. Sie könnten für die interne Kommunikation zwischen Ihren Microservices ein nicht standardmäßiges Format verwenden. Dies wäre bei der Kommunikation zwischen Microservices innerhalb Ihres Docker-Hosts oder Microserviceclusters (z.B. Docker-Orchestratoren) oder bei proprietären Clientanwendungen möglich, die mit den Microservices kommunizieren.
Kommunikation über Anforderungen/Antworten mit HTTP und REST
Wenn ein Client die Kommunikation über Anforderungen/Antworten verwendet, sendet er eine Anforderung an einen Dienst. Der Dienst verarbeitet die Anforderung dann und sendet eine Antwort zurück. Die Kommunikation über Anforderungen/Antworten eignet sich besonders zum Abfragen von Daten für eine Echtzeit-Benutzeroberfläche (eine Live-Benutzeroberfläche) über Client-Apps. Daher wird dieser Kommunikationsmechanismus (s. Abbildung 4-16) in einer Microservicearchitektur wahrscheinlich bei den meisten Abfragen verwendet.
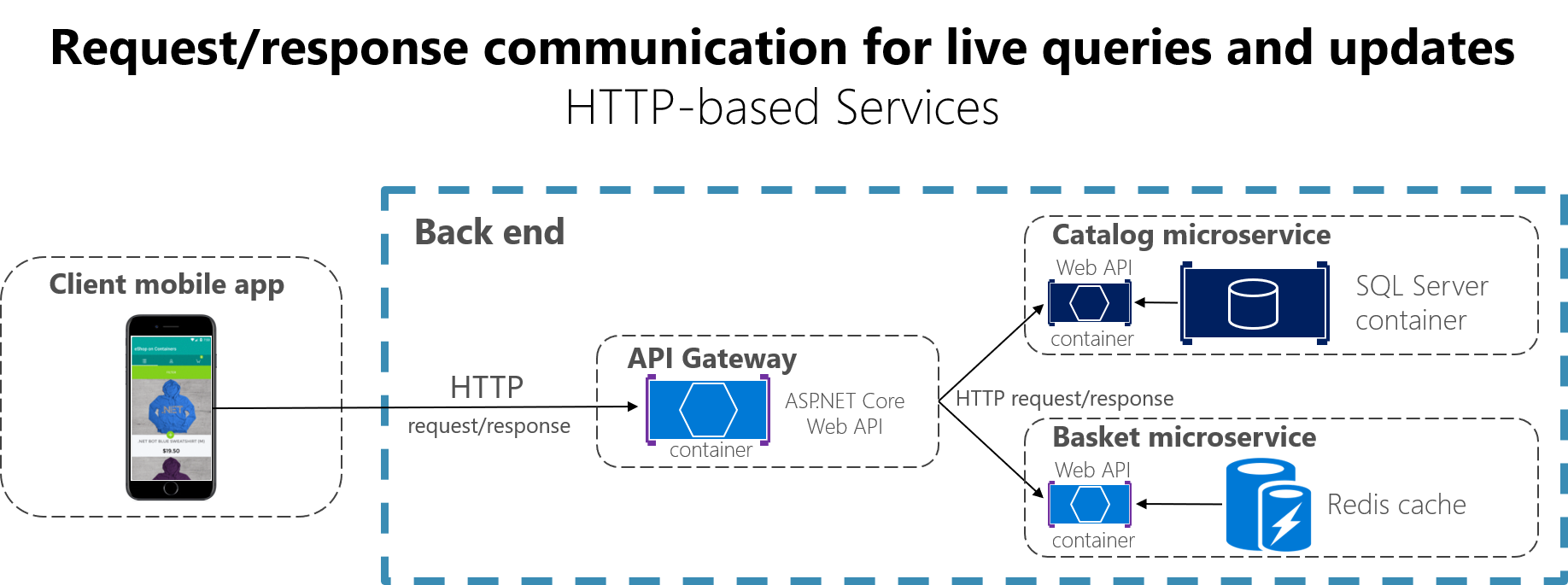
Abbildung 4-16. Verwenden der Kommunikation über HTTP-Anforderungen/-Antworten (synchron oder asynchron)
Wenn ein Client die Kommunikation über Anforderungen/Antworten verwendet, setzt er voraus, dass die Antwort innerhalb kurzer Zeit (in der Regel nach weniger als einer Sekunde oder höchstens ein paar Sekunden) eintreffen wird. Bei verzögerten Antworten müssen Sie eine asynchrone Kommunikation implementieren, die auf Messagingmustern und Messagingtechnologien basiert. Dieser Ansatz unterscheidet sich von dem Ansatz, der im nächsten Abschnitt erläutert wird.
Ein beliebter Architekturstil für die Kommunikation über Anforderungen/Antworten ist REST. Dieser Ansatz basiert auf dem HTTP-Protokoll, das HTTP-Verben wie GET, POST und PUT umfasst, und ist eng daran gekoppelt. REST ist bei der Erstellung von Diensten der am häufigsten verwendete Architekturstil für die Kommunikation. Sie können REST-Dienste implementieren, wenn Sie ASP.NET Core Web-API-Dienste entwickeln.
Die Verwendung von HTTP-REST-Diensten als Interface Definition Language bietet einen Mehrwert. Wenn Sie beispielsweise Swagger-Metadaten für die Beschreibung Ihrer Dienst-API verwenden, können Sie Tools verwenden, die Client-Stubs generieren. Diese können Ihre Dienste direkt erkennen und verwenden.
Zusätzliche Ressourcen
Martin Fowler. Richardson Maturity Model Eine Beschreibung des REST-Modells.
https://martinfowler.com/articles/richardsonMaturityModel.htmlSwagger (offizielle Website).
https://swagger.io/
Auf HTTP basierende Push- und Echtzeitkommunikation
Eine andere Möglichkeit (in der Regel zu anderen Zwecken als REST) ist eine in Echtzeitkommunikation und eine 1:n-Kommunikation mit Frameworks der höheren Ebene wie ASP.NET SignalR und Protokollen wie WebSockets.
Wie in Abbildung 4-17 zu sehen ist, bedeutet HTTP-Kommunikation in Echtzeit, dass Sie über Servercode verfügen können, der bei Zurverfügungstellung der Daten Inhalte mithilfe von Push an verbundene Clients überträgt, statt den Server auf eine Clientanforderung nach neuen Daten warten zu lassen.
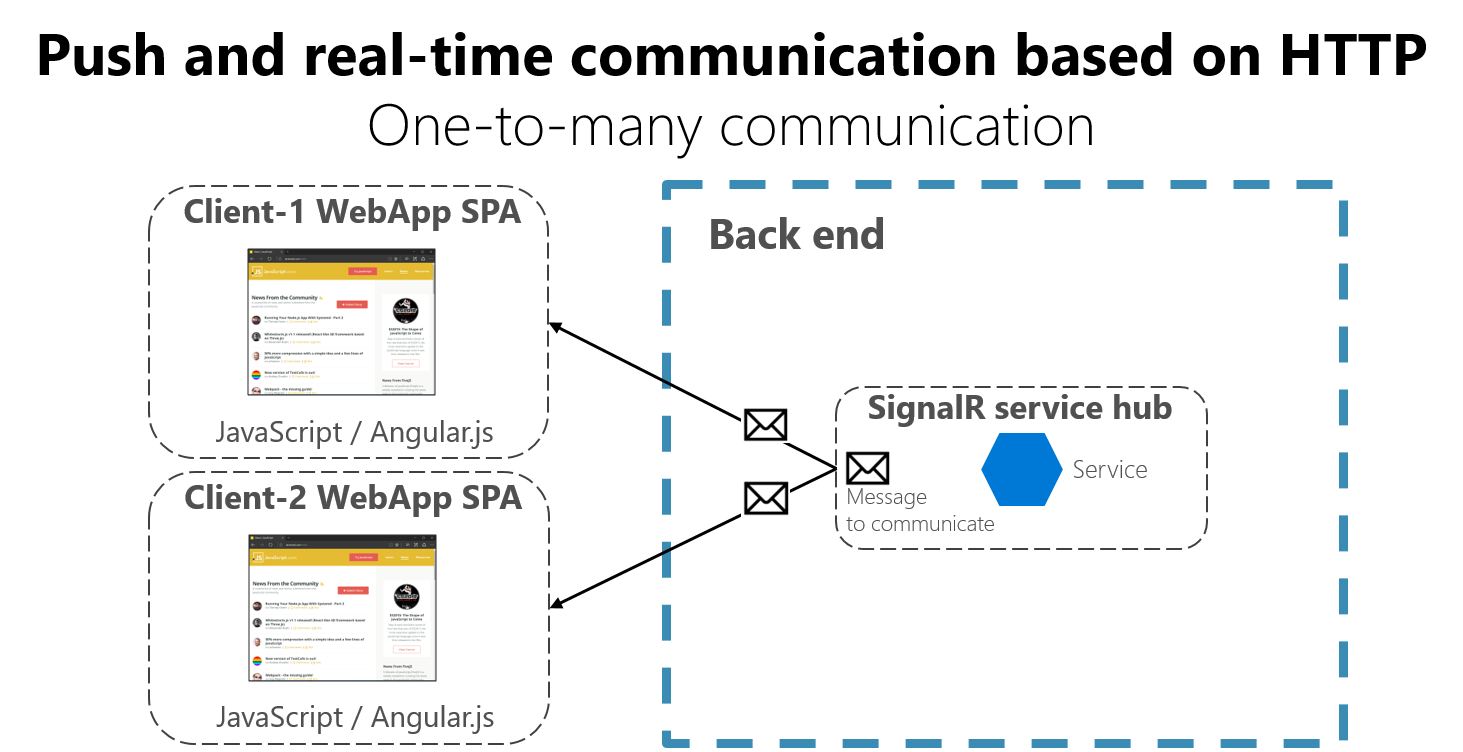
Abbildung 4-17. Asynchrone 1:n-Nachrichtenkommunikation in Echtzeit
SignalR ist ein guter Ansatz für die Echtzeitkommunikation, um Inhalte von einem Back-End-Server an Clients zu übertragen. Da die Kommunikation in Echtzeit erfolgt, werden die Änderungen in Client-Apps praktisch sofort angezeigt. Dies wird normalerweise von einem Protokoll wie WebSockets unter Verwendung vieler WebSockets-Verbindungen (eine pro Client) gesteuert. Ein typisches Beispiel ist, wenn ein Dienst die Bewertungsänderung eines Sportspiels an viele Client-Apps gleichzeitig überträgt.