DevOps
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architecting Cloud Native .NET Applications for Azure“, verfügbar in der .NET-Dokumentation oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

Das bevorzugte Mantra von Softwareberatern ist die Antwort „Es kommt darauf an“ auf jede gestellte Frage. Das liegt nicht daran, dass Softwareberater nicht gerne eine Position beziehen. Es liegt daran, dass es zu Software keine einzelne wahre Antwort auf alle Fragen gibt. Es gibt kein absolutes Richtig und Falsch, sondern eher ein Gleichgewicht zwischen Gegensätzen.
Nehmen wir beispielsweise die beiden großen Ansätze zur Entwicklung von Webanwendungen: Single-Page-Webanwendung (SPAs) und serverseitige Anwendungen. Einerseits ist das Benutzererlebnis mit SPAs tendenziell besser und der Datenverkehr zum Webserver kann minimiert werden, sodass sie auf einem einfachen statischen Hostsystem gehostet werden können. Andererseits sind SPAs in der Regel langsamer zu entwickeln und schwieriger zu testen. Welche ist die richtige Wahl? Nun, das hängt von Ihrer Situation ab.
Auch cloudnative Anwendungen sind gegen diese Gegensätzlichkeit nicht gefeit. Sie haben klare Vorteile in Bezug auf Entwicklungsgeschwindigkeit, Stabilität und Skalierbarkeit, aber ihre Verwaltung kann sich etwas schwieriger gestalten.
Vor Jahren war es nicht ungewöhnlich, dass der Prozess der Überführung einer Anwendung von der Entwicklung in die Produktion einen Monat oder sogar länger dauerte. Unternehmen veröffentlichen Software in einem 6-monatigen oder sogar jährlichen Rhythmus. Sie brauchen nur einen Blick auf Microsoft Windows zu werfen, um eine Vorstellung von dem Rhythmus der Veröffentlichungen zu bekommen, die vor den Tagen von Windows 10 als akzeptabel galten. Fünf Jahre vergingen zwischen Windows XP und Vista, weitere drei Jahre zwischen Vista und Windows 7.
Es hat sich jetzt herausgestellt, dass schnelllebige Unternehmen, die in der Lage sind, Software schnell zu veröffentlichen, einen großen Marktvorteil gegenüber ihren eher trägen Konkurrenten haben. Aus diesem Grund werden größere Updates für Windows 10 jetzt etwa alle sechs Monate durchgeführt.
Die Muster und Methoden, die schnellere und zuverlässigere Releases ermöglichen, um einen Mehrwert für das Unternehmen zu schaffen, werden unter dem Begriff „DevOps“ zusammengefasst. Sie bestehen aus einem breiten Spektrum von Ideen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken, von der Spezifikation einer Anwendung bis hin zur Bereitstellung und dem Betrieb dieser Anwendung.
DevOps entstand vor Microservices und es ist wahrscheinlich, dass die Entwicklung hin zu kleineren, zweckmäßigeren Diensten ohne DevOps nicht möglich gewesen wäre, um die Freigabe und den Betrieb nicht nur einer, sondern vieler Anwendungen in der Produktion zu erleichtern.
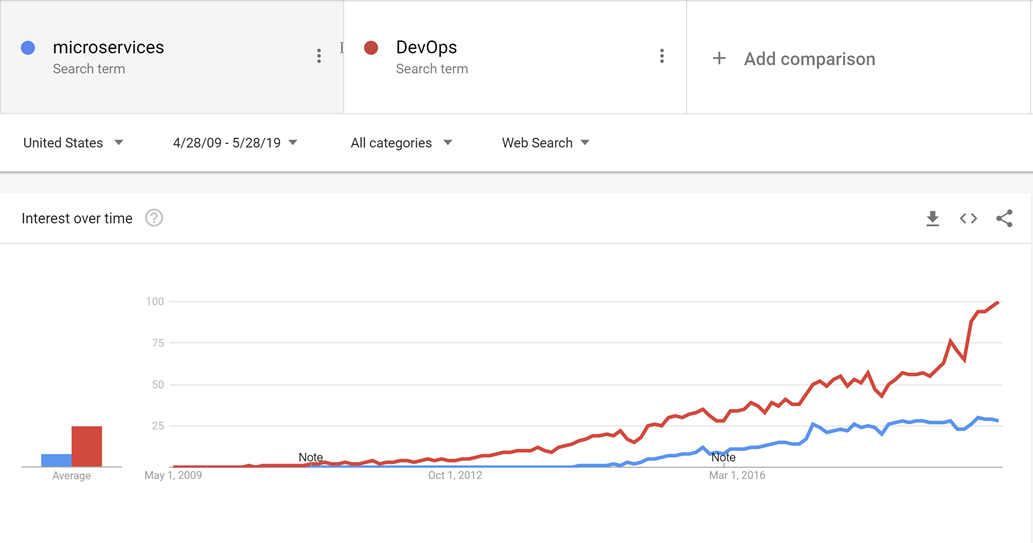
Abbildung 10-1: DevOps und Microservices.
Durch bewährte DevOps-Methoden ist es möglich, die Vorteile cloudnativer Anwendungen zu nutzen, ohne unter einem Berg von Arbeit für den eigentlichen Betrieb der Anwendungen zu ersticken.
Es gibt keinen goldenen Hammer, wenn es um DevOps geht. Niemand kann eine komplette und allumfassende Lösung für die Freigabe und den Betrieb hochwertiger Anwendungen verkaufen. Das liegt daran, dass sich jede Anwendung stark von allen anderen unterscheidet. Es gibt jedoch Tools, die DevOps zu einem weit weniger beängstigenden Unterfangen machen können. Eines dieser Tools ist als Azure DevOps bekannt.
Azure DevOps
Azure DevOps hat einen langen Werdegang hinter sich. Es kann seine Wurzeln bis zu der Zeit zurückverfolgen, als Team Foundation Server zum ersten Mal online ging und durch die verschiedenen Namensänderungen: Visual Studio Online und Visual Studio Team Services. Im Laufe der Jahre ist es jedoch viel mehr geworden als seine Vorgänger.
Azure DevOps ist in fünf Hauptkomponenten unterteilt:

Abbildung 10-2: Azure DevOps.
Azure Repos: Quellcodeverwaltung, die das ehrwürdige Team Foundation Version Control (TFVC) und das branchenweit beliebte Git unterstützt. Pull Requests bieten eine Möglichkeit, Social Coding zu ermöglichen, indem sie die Diskussion über Änderungen anregen, während diese vorgenommen werden.
Azure Boards: Stellt ein Tool zur Nachverfolgung von Problemen und Arbeitselementen zur Verfügung, mit dem Benutzer die Workflows auswählen können, die für sie am besten geeignet sind. Es wird mit einer Reihe von vorkonfigurierten Vorlagen geliefert, darunter solche, die SCRUM- und Kanban-Entwicklungsstile unterstützen.
Azure Pipelines: Ein Verwaltungssystem für Builds und Releases, das eine enge Integration in Azure unterstützt. Die Builds können auf verschiedenen Plattformen ausgeführt werden, von Windows über Linux bis hin zu macOS. Build-Agents können in der Cloud oder lokal bereitgestellt werden.
Azure Test Plans: Mit der Unterstützung der Testverwaltung und der explorativen Tests, die das Feature „Test Plans“ bietet, bleibt kein Mitarbeiter der Qualitätssicherung auf der Strecke.
Azure Artifacts: Ein Artefaktfeed, mit dem Unternehmen ihre eigenen, internen Versionen von NuGet, npm und anderen erstellen können. Es erfüllt einen doppelten Zweck, indem es als Zwischenspeicher für Upstreampakete dient, falls ein zentrales Repository ausfällt.
Die oberste Organisationseinheit in Azure DevOps wird als „Projekt“ bezeichnet. Innerhalb jedes Projekts können die verschiedenen Komponenten, z. B. Azure Artifacts, aktiviert und deaktiviert werden. Jede dieser Komponenten bietet unterschiedliche Vorteile für cloudnative Anwendungen. Die drei nützlichsten sind Repositorys, Boards und Pipelines. Wenn Benutzer ihren Quellcode in einem anderen Repositorystapel wie GitHub verwalten möchten, aber dennoch die Vorteile von Azure Pipelines und anderen Komponenten nutzen möchten, ist das problemlos möglich.
Glücklicherweise haben Entwicklungsteams bei der Auswahl eines Repositorys viele Möglichkeiten. Eine davon ist GitHub.
GitHub Actions
GitHub wurde 2009 gegründet und ist ein weit verbreitetes webbasiertes Repository zum Hosten von Projekten, Dokumentationen und Code. Viele große Technologieunternehmen wie Apple, Amazon, Google und andere verwenden GitHub. GitHub verwendet das verteilte Open-Source-Versionskontrollsystem namens „Git“ als Grundlage. Darüber hinaus legt es seine eigenen Features fest, darunter Fehlernachverfolgung, Featureanforderungen und Pull Requests, Aufgabenverwaltung und Wikis für jede Codebasis.
Mit der Weiterentwicklung von GitHub werden auch DevOps-Features hinzugefügt. GitHub hat z. B. seine eigene CI/CD-Pipeline (Continuous Integration/Continuous Delivery) namens GitHub Actions. GitHub Actions ist ein communitygestütztes Workflowautomatisierungstool. Es ermöglicht DevOps-Teams die Integration in ihre bestehenden Tools, das Kombinieren und Anpassen neuer Produkte und die Einbindung in ihren Softwarelebenszyklus, einschließlich bestehender CI/CD-Partner.
GitHub hat über 40 Millionen Benutzer und ist damit der weltweit größte Host für Quellcode. Im Oktober 2018 wurde GitHub von Microsoft gekauft. Microsoft hat versprochen, dass GitHub eine offene Plattform bleiben wird, die jeder Entwickler nutzen und erweitern kann. Es ist weiterhin als unabhängiges Unternehmen tätig. GitHub bietet Pläne für Unternehmens- und Teamkonten sowie für professionelle und kostenlose Konten.
Quellcodeverwaltung
Die Organisation des Codes für eine cloudnative Anwendung kann eine Herausforderung darstellen. Anstelle einer einzelnen riesigen Anwendung bestehen die cloudnativen Anwendungen in der Regel aus einem Netz von kleineren Anwendungen, die miteinander kommunizieren. Wie überall beim Computing bleibt die beste Anordnung des Codes eine offene Frage. Es gibt Beispiele für erfolgreiche Anwendungen, die verschiedene Arten von Layouts verwenden, aber zwei Varianten scheinen am beliebtesten zu sein.
Bevor Sie sich mit der eigentlichen Quellcodeverwaltung befassen, sollten Sie sich überlegen, wie viele Projekte angemessen sind. Innerhalb eines einzelnen Projekts gibt es Unterstützung für mehrere Repositorys und Buildpipelines. Boards sind etwas komplizierter, aber auch hier können die Aufgaben problemlos mehreren Teams innerhalb eines einzelnen Projekts zugewiesen werden. Es ist möglich, mit einem einzelnen Azure DevOps-Projekt Hunderte oder sogar Tausende von Entwicklern zu unterstützen. Dies ist wahrscheinlich der beste Ansatz, da er allen Entwicklern einen zentralen Ort bietet, von dem aus sie arbeiten können, und die Verwirrung bei der Suche nach der einen Anwendung verringert, wenn die Entwickler nicht sicher sind, in welchem Projekt sie sich befindet.
Die Aufteilung des Codes für Microservices innerhalb des Azure DevOps-Projekts kann eine etwas größere Herausforderung darstellen.
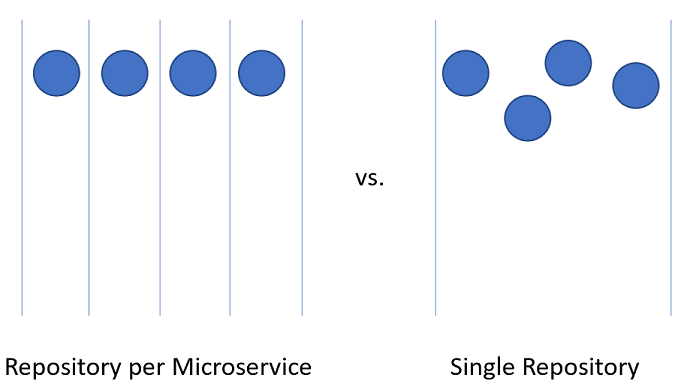
Abbildung 10-3: Ein einzelnes Repository oder mehrere Repositorys.
Repository pro Microservice
Auf den ersten Blick scheint dieser Ansatz der logischste zu sein, um den Quellcode für Microservices aufzuteilen. Jedes Repository kann den Code enthalten, der zum Erstellen des einen Microservice benötigt wird. Die Vorteile dieses Ansatzes liegen auf der Hand:
- Anweisungen zum Erstellen und Verwalten der Anwendung können in einer README-Datei im Stammverzeichnis jedes Repositorys hinzugefügt werden. Wenn Sie in den Repositorys blättern, können Sie diese Anweisungen leicht finden, was die Einarbeitungszeit für Entwickler verkürzt.
- Jeder Dienst befindet sich an einem logischen Ort, der leicht zu finden ist, wenn der Name des Diensts bekannt ist.
- Builds lassen sich leicht so einrichten, dass sie nur dann ausgelöst werden, wenn eine Änderung am eigenen Repository vorgenommen wird.
- Die Anzahl der Änderungen, die in ein Repository einfließen, ist auf die geringe Anzahl von Entwicklern beschränkt, die an dem Projekt arbeiten.
- Die Sicherheit lässt sich leicht einrichten, indem Sie die Repositorys einschränken, für die Entwickler Lese- und Schreibrechte haben.
- Die Einstellungen auf Repositoryebene können von dem Team, das das Repository besitzt, mit einem Minimum an Diskussion mit anderen geändert werden.
Eine der wichtigsten Ideen hinter Microservices ist, dass die Dienste voneinander getrennt werden sollten. Wenn Sie einen domänengesteuerten Entwurf verwenden, um die Begrenzung für Dienste auszuwählen, dienen die Dienste als Transaktionsgrenzen. Datenbankupdates sollten nicht mehrere Dienste umfassen. Diese Sammlung verwandter Daten wird als gebundener Kontext bezeichnet. Diese Idee spiegelt sich in der Isolation der Daten von Microservices in einer Datenbank wider, die vom Rest der Dienste getrennt und unabhängig ist. Es ist sehr sinnvoll, diese Idee bis in den Quellcode hinein zu übernehmen.
Dieser Ansatz ist jedoch nicht unproblematisch. Eines der schwierigsten Entwicklungsprobleme unserer Zeit ist die Verwaltung von Abhängigkeiten. Bedenken Sie die Anzahl der Dateien, aus denen ein durchschnittliches node_modules-Verzeichnis besteht. Eine Neuinstallation von etwas wie create-react-app bringt wahrscheinlich Tausende von Paketen mit sich. Die Frage, wie diese Abhängigkeiten zu handhaben sind, gestaltet sich schwierig.
Wenn eine Abhängigkeit aktualisiert wird, müssen Downstreampakete diese Abhängigkeit ebenfalls aktualisieren. Leider erfordert dies Entwicklungsarbeit, sodass das node_modules-Verzeichnis unweigerlich mehrere Versionen eines einzelnen Pakets enthält, von denen jede von einem anderen Paket abhängt, das in einem etwas anderen Rhythmus mit einer Version versehen wird. Welche Version einer Abhängigkeit sollte bei der Bereitstellung einer Anwendung verwendet werden? Die Version, die sich derzeit in der Produktion befindet? Die Version, die sich derzeit in der Beta-Phase befindet, aber wahrscheinlich in der Produktion sein wird, wenn der Consumer es in die Produktion schafft? Schwierige Probleme, die sich nicht allein mithilfe von Microservices lösen lassen.
Es gibt Bibliotheken, auf die eine Vielzahl von Projekten angewiesen ist. Durch die Aufteilung der Microservices in jeweils ein Repository lassen sich die internen Abhängigkeiten am besten mithilfe des internen Repositorys, Azure Artifacts, auflösen. Bei der Erstellung von Bibliotheken werden die neuesten Versionen in Azure Artifacts für den internen Gebrauch bereitgestellt. Das Downstreamprojekt muss noch manuell aktualisiert werden, um eine Abhängigkeit von den neu aktualisierten Paketen herzustellen.
Ein weiterer Nachteil ergibt sich beim Verschieben von Code zwischen Diensten. Obwohl es schön wäre zu glauben, dass die erste Aufteilung einer Anwendung in Microservices zu 100 % korrekt ist, entspricht es eher der Realität, dass wir selten so vorausschauend sind, dass wir keine Fehler bei der Aufteilung von Diensten machen. Daher müssen die Funktionen und der Code, der sie steuert, von Dienst zu Dienst wechseln: von Repository zu Repository. Wenn Sie von einem Repository zum anderen wechseln, verliert der Code seinen Verlauf. Es gibt viele Fälle, insbesondere bei einer Überwachung, in denen ein vollständiger Verlauf für einen Code von unschätzbarem Wert ist.
Der letzte und wichtigste Nachteil ist die Koordinierung von Änderungen. In einer echten Microserviceanwendung sollte es keine Abhängigkeiten bei der Bereitstellung zwischen den Diensten geben. Es sollte möglich sein, die Dienste A, B und C in beliebiger Reihenfolge bereitzustellen, da sie lose gekoppelt sind. In der Realität kommt es jedoch vor, dass es wünschenswert ist, eine Änderung vorzunehmen, die mehrere Repositorys gleichzeitig betrifft. Einige Beispiele sind die Aktualisierung einer Bibliothek, um eine Sicherheitslücke zu schließen, oder die Änderung eines Kommunikationsprotokolls, das von allen Diensten verwendet wird.
Um eine repositoryübergreifende Änderung vorzunehmen, müssen Sie nacheinander einen Commit für jedes Repository vornehmen. Jede Änderung in jedem Repository muss separat angefordert und überprüft werden. Diese Aktivität kann schwierig zu koordinieren sein.
Eine Alternative zur Verwendung vieler Repositorys besteht darin, den gesamten Quellcode in einem einzelnen riesigen, allwissenden Repository zusammenzufassen.
Einzelnes Repository
Bei diesem Ansatz, der manchmal als Monorepository bezeichnet wird, wird der gesamte Quellcode für jeden Dienst in einem einzelnen Repository abgelegt. Auf den ersten Blick scheint dieser Ansatz eine schreckliche Idee zu sein, die den Umgang mit dem Quellcode unübersichtlich gestaltet. Es gibt jedoch einige deutliche Vorteile, wenn Sie auf diese Weise arbeiten.
Der erste Vorteil besteht darin, dass es einfacher ist, Abhängigkeiten zwischen Projekten zu verwalten. Anstatt sich auf einen externen Artefaktfeed zu verlassen, können sich Projekte direkt gegenseitig importieren. Das bedeutet, dass Aktualisierungen sofort erfolgen und widersprüchliche Versionen wahrscheinlich schon bei der Kompilierung auf der Arbeitsstation des Entwicklers gefunden werden. Dadurch wird ein Teil der Integrationstests nach links verlagert.
Wenn Sie Code zwischen Projekten verschieben, ist es jetzt einfacher, den Verlauf beizubehalten, da die Dateien als verschoben erkannt werden, anstatt neu geschrieben zu werden.
Ein weiterer Vorteil ist, dass weitreichende Änderungen, die über die Grenzen der Dienste hinausgehen, in einem einzelnen Commit vorgenommen werden können. Diese Aktivität reduziert den Aufwand, der entsteht, wenn Sie Dutzende von Änderungen einzeln überprüfen müssen.
Es gibt viele Tools, die eine statische Analyse von Code durchführen können, um unsichere Programmierpraktiken oder eine problematische Verwendung von APIs zu erkennen. In einer Umgebung mit mehreren Repositorys muss jedes Repository durchlaufen werden, um die Probleme darin zu finden. Mit einem einzelnen Repository können Sie die Analyse an einem zentralen Ort ausführen.
Der Ansatz eines einzelnen Repositorys hat auch viele Nachteile. Eine der größten Sorgen ist, dass ein einzelnes Repository Sicherheitsbedenken aufwirft. Wenn der Inhalt eines Repositorys in einem Modell durchsickert, bei dem ein Repository pro Dienst verwendet wird, ist der Verlust an Code minimal. Mit einem einzelnen Repository könnte alles, was das Unternehmen besitzt, verloren gehen. In der Vergangenheit gab es viele Beispiele für solche Fälle, die die Entwicklung ganzer Spiele zum Scheitern brachten. Mehrere Repositorys bieten weniger Angriffsfläche, was für die meisten Sicherheitspraktiken eine wünschenswerte Eigenschaft ist.
Die Größe des einzelnen Repositorys wird wahrscheinlich schnell unüberschaubar werden. Dies hat einige interessante Auswirkungen auf die Leistung. Es kann notwendig werden, spezielle Tools wie Virtual File System for Git (virtuelles Dateisystem für Git) zu verwenden, das ursprünglich entwickelt wurde, um die Erfahrung für Entwickler im Windows-Team zu verbessern.
Häufig läuft das Argument für die Verwendung eines einzelnen Repositorys darauf hinaus, dass Facebook oder Google diese Methode zur Anordnung des Quellcodes verwenden. Wenn der Ansatz für diese Unternehmen gut genug ist, dann ist er sicherlich für alle Unternehmen der richtige Ansatz. Die Wahrheit ist, dass nur wenige Unternehmen in der Größenordnung von Facebook oder Google operieren. Die Probleme, die bei diesen Größenordnungen auftreten, unterscheiden sich von denen, mit denen die meisten Entwickler konfrontiert werden. Was gut für die Gans ist, muss nicht gut für den Gänserich sein.
Letztlich können beide Lösungen verwendet werden, um den Quellcode für Microservices zu hosten. In den meisten Fällen ist jedoch der Verwaltungs- und Entwicklungsaufwand für ein einzelnes Repository die geringen Vorteile nicht wert. Die Aufteilung des Codes auf mehrere Repositorys fördert eine bessere Trennung von Belangen und fördert die Autonomie der Entwicklungsteams.
Standardverzeichnisstruktur
Unabhängig von der Debatte über ein oder mehrere Repositorys erhält jeder Dienst sein eigenes Verzeichnis. Eine der besten Optimierungen, die es Entwicklern ermöglichen, schnell zwischen Projekten zu wechseln, ist die Beibehaltung einer Standardverzeichnisstruktur.
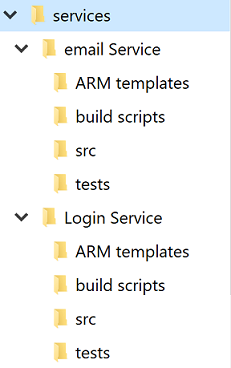
Abbildung 10-4: Standardverzeichnisstruktur.
Bei jedem Erstellen eines neuen Projekts sollten Sie eine Vorlage verwenden, die die richtige Struktur vorgibt. Diese Vorlage kann auch so nützliche Elemente wie das Gerüst für eine README-Datei und eine azure-pipelines.yml einbeziehen. In jeder Microservicearchitektur gestaltet ein hohes Maß an Varianz zwischen den Projekten die Massenvorgänge für die Dienste schwieriger.
Es gibt viele Anbieter, die Vorlagen für ein ganzes Verzeichnis bereitstellen können, das mehrere Quellcodeverzeichnisse enthält. Yeoman ist in der JavaScript-Welt sehr beliebt und GitHub hat kürzlich Repositoryvorlagen veröffentlicht, die einen Großteil der gleichen Funktionen bieten.
Aufgabenverwaltung
Die Verwaltung von Aufgaben kann in jedem Projekt schwierig sein. Im Vorfeld gibt es unzählige Fragen zu der Art von Workflows, die Sie festlegen müssen, um eine optimale Produktivität der Entwickler zu gewährleisten.
Cloudnative Anwendungen sind in der Regel kleiner als traditionelle Softwareprodukte oder zumindest in kleinere Dienste unterteilt. Die Nachverfolgung von Problemen oder Aufgaben im Zusammenhang mit diesen Diensten ist genauso wichtig wie bei jedem anderen Softwareprojekt. Niemand möchte den Überblick über ein Arbeitselement verlieren oder einem Kunden erklären, dass sein Problem nicht ordnungsgemäß protokolliert wurde. Boards werden auf Projektebene konfiguriert, aber innerhalb jedes Projekts können Bereiche definiert werden. Diese ermöglichen eine Aufteilung der Probleme auf mehrere Komponenten. Der Vorteil, die gesamte Arbeit für die gesamte Anwendung an einem Ort aufzubewahren, besteht darin, dass Arbeitselemente leichter von einem Team zum anderen verschoben werden können, da sie besser verstanden werden.
Azure DevOps verfügt über eine Reihe beliebter Vorlagen, die bereits vorkonfiguriert sind. In der einfachsten Konfiguration müssen Sie nur wissen, was sich im Rückstand befindet, woran die Mitarbeiter arbeiten und was bereits erledigt ist. Es ist wichtig, diesen Einblick in den Prozess der Softwareerstellung zu haben, sodass die Arbeit nach Prioritäten geordnet und die erledigten Aufgaben dem Kunden gemeldet werden können. Natürlich halten sich nur wenige Softwareprojekte an einen so einfachen Prozess wie to do, doing und done. Es dauert nicht lange, bis Personen mit dem Hinzufügen von Schritten wie QA oder Detailed Specification zum Prozess beginnen.
Einer der wichtigsten Bestandteile der Agile-Methodik ist die regelmäßige Selbstkontrolle. Diese Bewertungen sollen Erkenntnisse darüber liefern, mit welchen Problemen das Team konfrontiert ist und wie sie verbessert werden können. Häufig bedeutet dies, dass der Fluss von Problemen und Features durch den Entwicklungsprozess geändert werden muss. Es ist also völlig in Ordnung, die Layouts der Boards mit zusätzlichen Stages zu erweitern.
Die Stages in den Boards sind nicht das einzige Organisationstool. Je nach Konfiguration des Boards gibt es eine Hierarchie von Arbeitselementen. Das präziseste Element, das auf einem Board vorkommen kann, ist eine Aufgabe. Eine Aufgabe enthält standardmäßig Felder für einen Titel, eine Beschreibung, eine Priorität, eine Schätzung des verbleibenden Arbeitsaufwands und die Möglichkeit, eine Verknüpfung zu anderen Arbeitselementen oder Entwicklungselementen (Branches, Commits, Pull Requests, Builds und so weiter) herzustellen. Arbeitselemente können in verschiedene Bereiche der Anwendung und verschiedene Iterationen (Sprints) eingeteilt werden, um das Auffinden der Elemente zu erleichtern.
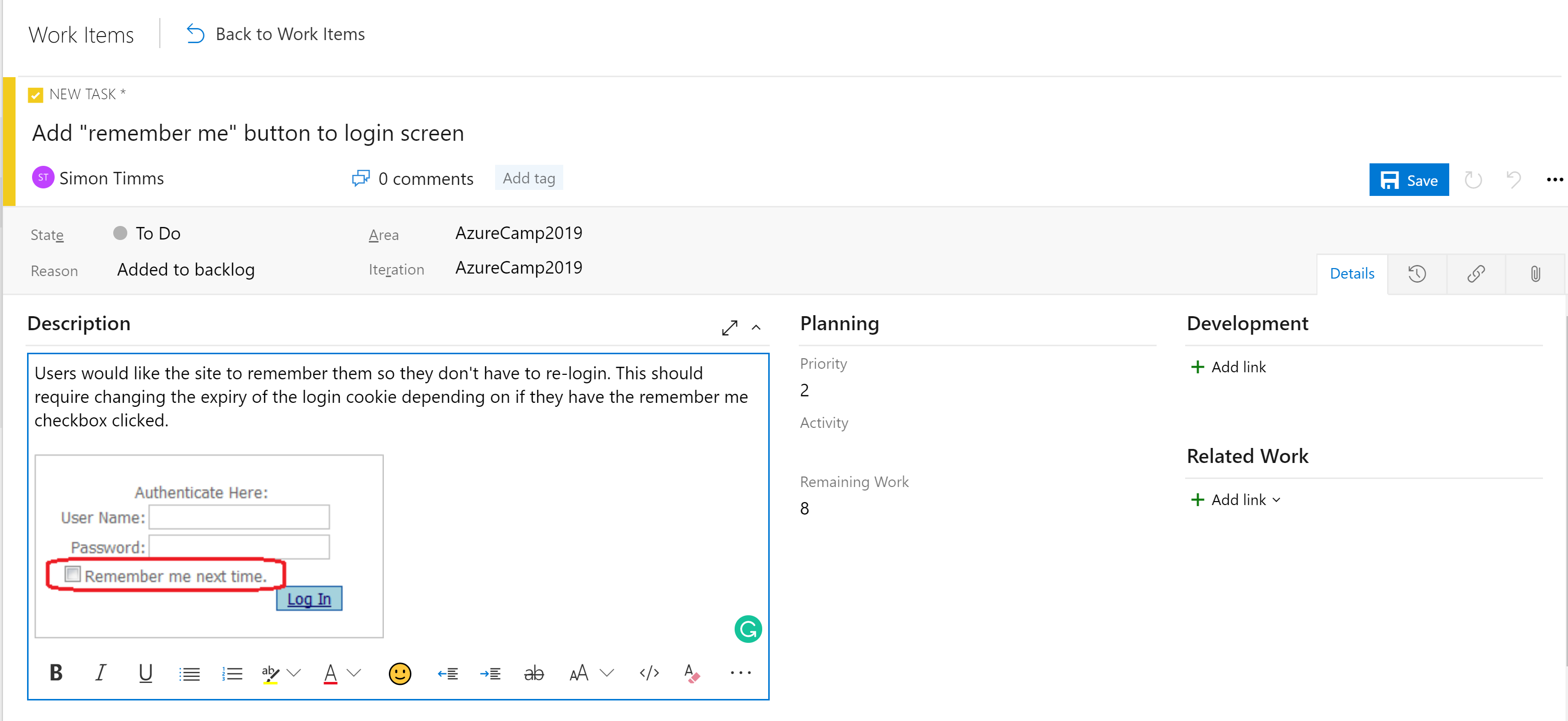
Abbildung 10-5: Aufgabe in Azure DevOps.
Das Beschreibungsfeld unterstützt die normalen Formatvorlagen, die Sie erwarten (fett, kursiv, unterstrichen und durchgestrichen) und die Möglichkeit zum Einfügen von Bildern. Dies macht es zu einem leistungsstarken Tool, das Sie bei der Angabe von Arbeiten oder Fehlern verwenden können.
Aufgaben können zu Features zusammengefasst werden, die eine größere Arbeitseinheit definieren. Features können wiederum in Epen zusammengefasst werden. Die Klassifizierung von Aufgaben in dieser Hierarchie erleichtert es, zu verstehen, wie nah ein großes Feature an der Einführung ist.

Abbildung 10-6: Arbeitselement in Azure DevOps.
Es gibt verschiedene Arten von Ansichten zu den Problemen in Azure Boards. Elemente, die noch nicht geplant sind, werden im Backlog angezeigt. Von dort aus können sie einem Sprint zugewiesen werden. Ein Sprint ist ein Zeitfenster, in dem eine bestimmte Menge an Arbeit erledigt werden soll. Diese Arbeit kann Aufgaben umfassen, aber auch die Auflösung von Tickets. Dort können Sie den gesamten Sprint über den Abschnitt „Sprint-Board“ verwalten. In dieser Ansicht sehen Sie, wie die Arbeit voranschreitet, und können anhand eines Burn-Down-Charts immer wieder neu abschätzen, ob der Sprint erfolgreich sein wird.
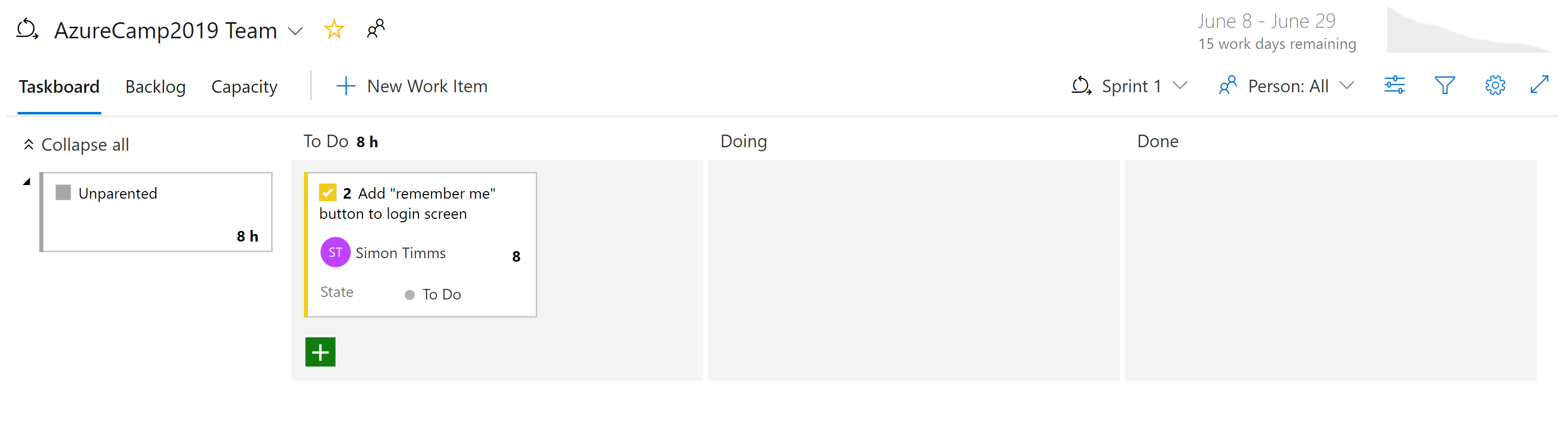
Abbildung 10-7: Board in Azure DevOps.
Mittlerweile sollte klar sein, dass die Boards in Azure DevOps sehr leistungsfähig sind. Für Entwickler gibt es einfache Ansichten zu dem, woran gerade gearbeitet wird. Für Projektmanager gibt es Ansichten zu anstehenden Arbeiten sowie eine Übersicht über die bestehenden Arbeiten. Für Manager gibt es zahlreiche Berichte über die Ressourcenbereitstellung und die Kapazität. Leider gibt es nichts Magisches an cloudnativen Anwendungen, das die Nachverfolgung der Arbeit überflüssig macht. Aber wenn Sie die Arbeit nachverfolgen müssen, gibt es nur wenige Bereiche, in denen die Erfahrung besser ist als in Azure DevOps.
CI/CD-Pipelines
Kaum eine Veränderung im Lebenszyklus der Softwareentwicklung war so revolutionär wie das Aufkommen von Continuous Integration (CI) und Continuous Delivery (CD). Das Erstellen und Ausführen automatisierter Tests für den Quellcode eines Projekts, sobald eine Änderung eingecheckt wird, fängt Fehler frühzeitig ab. Vor dem Aufkommen der Continuous Integration-Builds war es nicht ungewöhnlich, dass Code aus dem Repository abgerufen und dann festgestellt wurde, dass er die Tests nicht bestand oder gar nicht erstellt werden konnte. Dies führte dazu, dass wir die Quelle des Problems aufspüren konnten.
Traditionell erforderte die Lieferung von Software an die Produktionsumgebung eine umfangreiche Dokumentation und eine Liste von Schritten. Jeder dieser Schritte musste manuell ausgeführt werden, was sehr fehleranfällig war.

Abbildung 10-8: Prüfliste.
Das Pendant zu Continuous Integration ist Continuous Delivery, bei dem die kürzlich erstellten Pakete in einer Umgebung bereitgestellt werden. Der manuelle Prozess kann nicht mit der Geschwindigkeit der Entwicklung Schritt halten, sodass die Automatisierung immer wichtiger wird. Prüflisten werden durch Skripts ersetzt, die dieselben Aufgaben schneller und genauer ausführen können als jeder Mensch.
Die Umgebung, in die Continuous Delivery liefert, kann eine Testumgebung sein oder, wie es von vielen großen Technologieunternehmen praktiziert wird, auch die Produktionsumgebung. Letzteres erfordert eine Investition in qualitativ hochwertige Tests, mit denen Sie sicher sein können, dass eine Änderung die Produktion für die Benutzer nicht beeinträchtigt. Genauso wie Continuous Integration Probleme im Code frühzeitig abfängt, fängt Continuous Delivery Probleme bei der Bereitstellung frühzeitig ab.
Die Bedeutung der Automatisierung des Erstellungs- und Bereitstellungsprozesses wird durch cloudnative Anwendungen noch unterstrichen. Die Bereitstellung erfolgt immer häufiger und in immer mehr Umgebungen, sodass eine manuelle Bereitstellung nahezu unmöglich ist.
Azure Builds
Azure DevOps bietet eine Reihe von Tools, die Continuous Integration und die Bereitstellung einfacher denn je gestalten. Diese Tools befinden sich unter Azure Pipelines. Das erste ist Azure Builds, ein Tool zum Ausführen von YAML-basierten Builddefinitionen im großen Stil. Benutzer können entweder ihre eigenen Computer für die Erstellung mitbringen (ideal, wenn der Build eine sorgfältig festgelegte Umgebung erfordert) oder einen Computer aus einem ständig aktualisierten Pool von auf Azure gehosteten virtuellen Computern verwenden. Diese gehosteten Build-Agents sind mit einer breiten Palette von Entwicklungstools vorinstalliert, nicht nur für die .NET-Entwicklung, sondern für alles von der Java- über Python- bis hin zur iPhone-Entwicklung.
DevOps enthält eine breite Palette von sofort einsatzbereiten Builddefinitionen, die für jeden Build angepasst werden können. Die Builddefinitionen werden in einer Datei namens azure-pipelines.yml definiert und in das Repository eingecheckt, sodass sie zusammen mit dem Quellcode mit einer Versionsangabe versehen werden können. Dadurch wird es viel einfacher, Änderungen an der Buildpipeline in einem Branch vorzunehmen, da die Änderungen nur in diesen Branch eingecheckt werden können. Eine beispielhafte azure-pipelines.yml zum Erstellen einer ASP.NET-Webanwendung im vollständigen Framework ist in Abbildung 10-9 dargestellt.
name: $(rev:r)
variables:
version: 9.2.0.$(Build.BuildNumber)
solution: Portals.sln
artifactName: drop
buildPlatform: any cpu
buildConfiguration: release
pool:
name: Hosted VisualStudio
demands:
- msbuild
- visualstudio
- vstest
steps:
- task: NuGetToolInstaller@0
displayName: 'Use NuGet 4.4.1'
inputs:
versionSpec: 4.4.1
- task: NuGetCommand@2
displayName: 'NuGet restore'
inputs:
restoreSolution: '$(solution)'
- task: VSBuild@1
displayName: 'Build solution'
inputs:
solution: '$(solution)'
msbuildArgs: '-p:DeployOnBuild=true -p:WebPublishMethod=Package -p:PackageAsSingleFile=true -p:SkipInvalidConfigurations=true -p:PackageLocation="$(build.artifactstagingdirectory)\\"'
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: VSTest@2
displayName: 'Test Assemblies'
inputs:
testAssemblyVer2: |
**\$(buildConfiguration)\**\*test*.dll
!**\obj\**
!**\*testadapter.dll
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: CopyFiles@2
displayName: 'Copy UI Test Files to: $(build.artifactstagingdirectory)'
inputs:
SourceFolder: UITests
TargetFolder: '$(build.artifactstagingdirectory)/uitests'
- task: PublishBuildArtifacts@1
displayName: 'Publish Artifact'
inputs:
PathtoPublish: '$(build.artifactstagingdirectory)'
ArtifactName: '$(artifactName)'
condition: succeededOrFailed()
Abbildung 10-9: Beispiel für azure-pipelines.yml
Diese Builddefinition verwendet eine Reihe integrierter Aufgaben, die das Erstellen von Builds so einfach gestalten wie das Zusammenbauen eines Lego-Sets (einfacher als der riesige Millennium-Falke). So stellt die NuGet-Aufgabe beispielsweise NuGet-Pakete wieder her, während die VSBuild-Aufgabe die Visual Studio Build-Tools aufruft, um die eigentliche Kompilierung durchzuführen. In Azure DevOps stehen Hunderte von verschiedenen Aufgaben zur Verfügung, und Tausende weitere werden von der Community verwaltet. Unabhängig davon, welche Buildaufgaben Sie ausführen möchten, hat wahrscheinlich schon jemand eine erstellt.
Builds können manuell, durch Einchecken, nach einem Zeitplan oder durch den Abschluss eines anderen Builds ausgelöst werden. In den meisten Fällen ist die Erstellung bei jedem Einchecken wünschenswert. Builds können gefiltert werden, sodass verschiedene Builds für verschiedene Teile des Repositorys oder für verschiedene Branches ausgeführt werden. Dies ermöglicht Szenarien wie das Ausführen von schnellen Builds mit reduzierten Tests bei Pull Requests und das nächtliche Ausführen einer vollständigen Regressionssammlung für den Trunk.
Das Endergebnis eines Builds ist eine Sammlung von Dateien, die als Buildartefakte bekannt sind. Diese Artefakte können an den nächsten Schritt im Erstellungsprozess weitergegeben oder zu einem Azure Artifacts-Feed hinzugefügt werden, damit sie von anderen Builds verwendet werden können.
Azure DevOps-Releases
Builds sorgen für die Kompilierung der Software in ein lieferbares Paket, aber die Artefakte müssen noch in eine Testumgebung gepusht werden, um Continuous Delivery abzuschließen. Azure DevOps verwendet hierfür ein eigenes Tool namens „Releases“. Das Tool „Releases“ verwendet dieselbe Aufgabenbibliothek, die auch für den Build zur Verfügung stand, führt aber ein Konzept von „Stages“ ein. Eine Stage ist eine isolierte Umgebung, in der das Paket installiert ist. So kann ein Produkt beispielsweise eine Entwicklungs-, eine QA- und eine Produktionsumgebung verwenden. Der Code wird kontinuierlich in die Entwicklungsumgebung übertragen, wo automatische Tests ausgeführt werden können. Sobald diese Tests bestanden sind, wird das Release für manuelle Tests in die QA-Umgebung weitergeleitet. Schließlich wird der Code in die Produktionsumgebung gepushed, wo er für alle sichtbar ist.

Abbildung 10-10: Releasepipeline
Jede Stage im Build kann automatisch durch den Abschluss der vorangegangenen Phase ausgelöst werden. In vielen Fällen ist dies jedoch nicht wünschenswert. Die Übernahme von Code in die Produktion erfordert möglicherweise die Zustimmung von jemandem. Das Tool „Releases“ unterstützt dies, indem es genehmigende Personen für jeden Schritt in der Releasepipeline zulässt. Regeln können so festgelegt werden, dass eine bestimmte Person oder Gruppe von Personen ein Release abzeichnen muss, bevor es in Produktion gelangt. Diese Kontrollen ermöglichen manuelle Qualitätskontrollen und die Einhaltung gesetzlicher Anforderungen in Bezug auf die Kontrolle dessen, was in die Produktion gelangt.
Jeder erhält eine Buildpipeline
Die Konfiguration vieler Buildpipelines ist kostenlos, sodass es von Vorteil ist, mindestens über eine Buildpipeline pro Microservice zu verfügen. Idealerweise sind Microservices unabhängig voneinander in jeder Umgebung bereitstellbar, sodass jeder einzelne über seine eigene Pipeline freigegeben werden kann, ohne dass eine Masse an unzusammenhängendem Code freigegeben wird. Jede Pipeline kann über eigene Genehmigungen verfügen, sodass der Buildprozess für jeden Dienst variieren kann.
Versionsverwaltung für Releases
Ein Nachteil bei der Verwendung der Releases-Funktionalität besteht darin, dass sie nicht in einer eingecheckten azure-pipelines.yml-Datei definiert werden kann. Es gibt viele Gründe, warum Sie dies durchführen möchten, von der Definition von Releases für einzelne Branches bis hin zur Aufnahme eines Release-Gerüsts in Ihre Projektvorlage. Glücklicherweise wird daran gearbeitet, einen Teil der Unterstützung der Stages in die Komponente „Build“ zu verlagern. Dies wird als mehrstufiger Build bezeichnet und die erste Version ist jetzt verfügbar!