Analysieren von Daten mit Azure Machine Learning
In diesem Tutorial wird Azure Machine Learning-Designer verwendet, um ein Predictive Machine Learning-Modell zu erstellen. Das Modell basiert auf den in Azure Synapse gespeicherten Daten. Das Szenario für das Tutorial besteht darin vorherzusagen, ob ein Kunde wahrscheinlich ein Fahrrad kauft oder nicht, damit Adventure Works, der Fahrradladen, eine gezielte Marketingkampagne erstellen kann.
Voraussetzungen
Zum Durchlaufen dieses Tutorials benötigen Sie Folgendes:
- einen SQL-Pool, der mit AdventureWorksDW-Beispieldaten vorab geladen wurde. Informationen zur Bereitstellung dieses SQL-Pools finden Sie unter Erstellen eines SQL-Pools. Wählen Sie darin die Option zum Laden der Beispieldaten. Wenn Sie bereits ein Data Warehouse aber noch keine Beispieldaten haben, können Sie Beispieldaten manuell laden.
- einen Azure Machine Learning-Arbeitsbereich. Folgen Sie diesem Tutorial, um einen neuen zu erstellen.
Abrufen von Daten
Die verwendeten Daten befinden sich in „AdventureWorksDW“ in der Ansicht „dbo.vTargetMail“. Um den Datenspeicher in diesem Tutorial verwenden zu können, werden die Daten zuerst in das Azure Data Lake Storage-Konto exportiert, da Azure Synapse zurzeit keine Datasets unterstützt. Azure Data Factory kann zum Exportieren von Daten aus dem Data Warehouse in Azure Data Lake Storage mithilfe der Kopieraktivität genutzt werden. Verwenden Sie die folgende Abfrage für den Import:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Sobald die Daten in Azure Data Lake Storage zur Verfügung stehen, werden Datenspeicher in Azure Machine Learning verwendet, um eine Verbindung mit Azure Storage-Diensten herzustellen. Führen Sie die folgenden Schritte aus, um einen Datenspeicher und ein entsprechendes Dataset zu erstellen:
Starten Sie Azure Machine Learning Studio entweder über das Azure-Portal, oder melden Sie sich bei Azure Machine Learning Studio an.
Klicken Sie im linken Bereich des Abschnitts Verwalten auf Datenspeicher und dann auf Neuer Datenspeicher.
Geben Sie einen Namen für den Datenspeicher an, wählen Sie den Typ „Azure Blob Storage“ aus, und geben Sie den Speicherort und die Anmeldeinformationen an. Klicken Sie dann auf Erstellen.
Klicken Sie anschließend im Abschnitt Ressourcen im linken Bereich auf Datasets. Wählen Sie Dataset erstellen mit der Option Aus Datenspeicher aus.
Geben Sie den Namen des Datasets an, und wählen Sie als Typ Tabellarisch aus. Klicken Sie dann auf Weiter, um den Vorgang fortzusetzen.
Wählen Sie im Abschnitt Datenspeicher auswählen oder erstellen die Option Zuvor erstellter Datenspeicher aus. Wählen Sie den zuvor erstellten Datenspeicher aus. Klicken Sie auf „Weiter“, und geben Sie Einstellungen für Pfad und Datei an. Vergessen Sie nicht, die Spaltenüberschrift anzugeben, wenn es eine in den Dateien gibt.
Klicken Sie abschließend auf Erstellen, um das Dataset zu erstellen.
Konfigurieren des Designerexperiments
Führen Sie als Nächstes die folgenden Schritte für die Designerkonfiguration aus:
Klicken Sie im Abschnitt Autor im linken Bereich auf die Registerkarte Designer.
Wählen Sie Benutzerfreundliche vorgefertigte Module aus, um eine neue Pipeline zu erstellen.
Geben Sie im Bereich „Einstellungen“ rechts den Namen der Pipeline an.
Wählen Sie außerdem in der Schaltfläche „Einstellungen“ für einen zuvor bereitgestellten Cluster einen Zielcomputecluster für das gesamte Experiment aus. Schließen Sie den Bereich „Einstellungen“.
Importieren der Daten
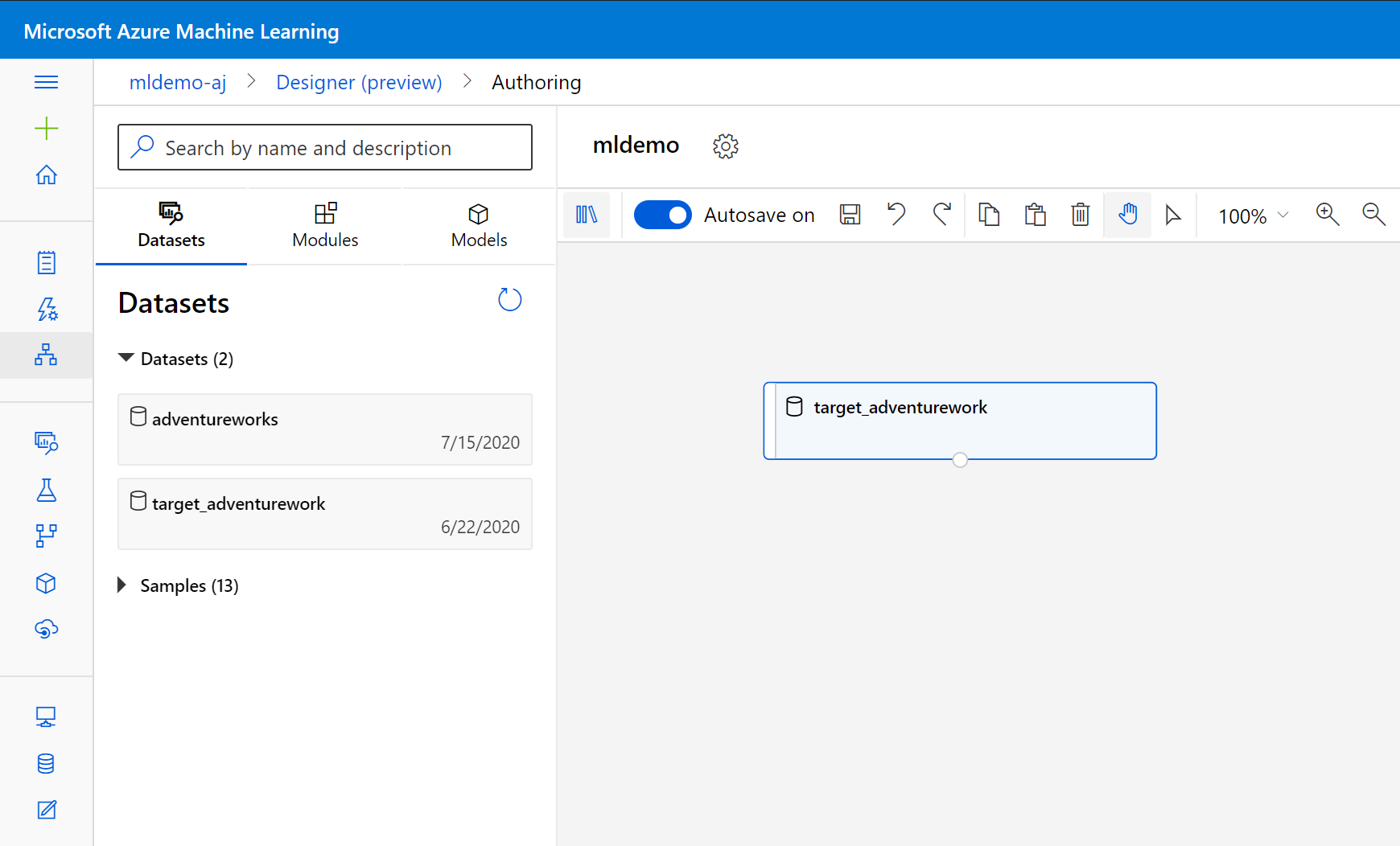
Wählen Sie im linken Bereich unter dem Suchfeld die Unterregisterkarte Datasets aus.
Ziehen Sie das zuvor erstellte Dataset in den Zeichenbereich.
Bereinigen der Daten
Löschen Sie Spalten, die für das Modell nicht relevant sind, um die Daten zu bereinigen. Führen Sie dafür die folgenden Schritte aus:
Wählen Sie im linken Bereich die Unterregisterkarte Komponenten aus.
Ziehen Sie unter Datentransformation < Manipulation die Komponente Spalten im Dataset auswählen in den Zeichenbereich. Verbinden Sie diese Komponente mit der Komponente Dataset.
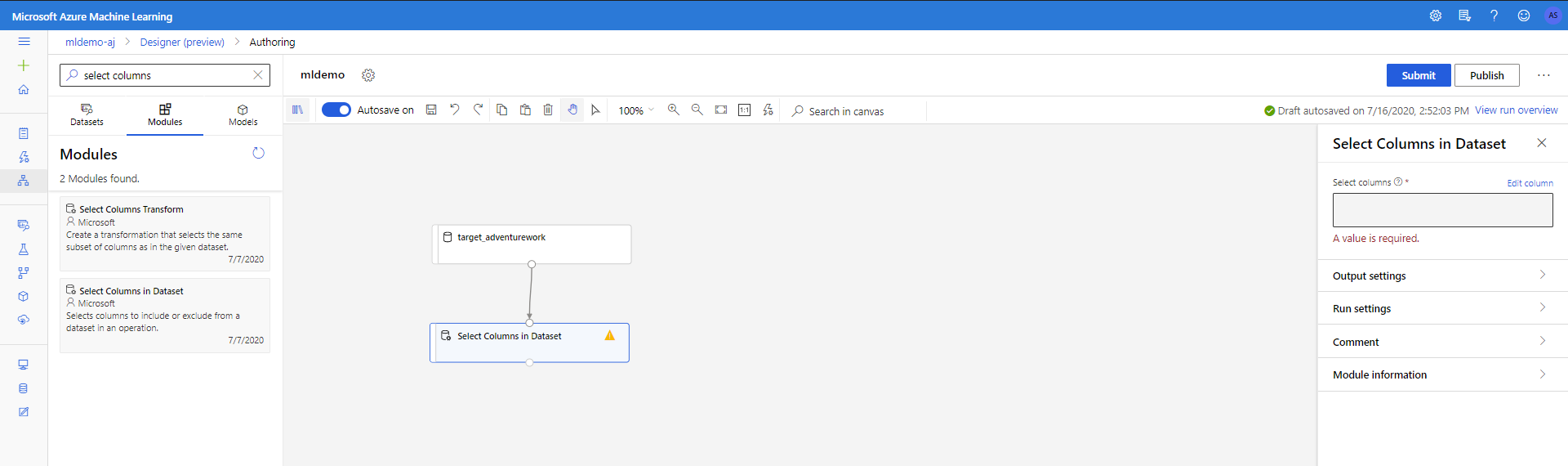
Klicken Sie auf die Komponente, um den Eigenschaftenbereich zu öffnen. Klicken Sie auf „Spalte bearbeiten“, um anzugeben, welche Spalten gelöscht werden sollen.
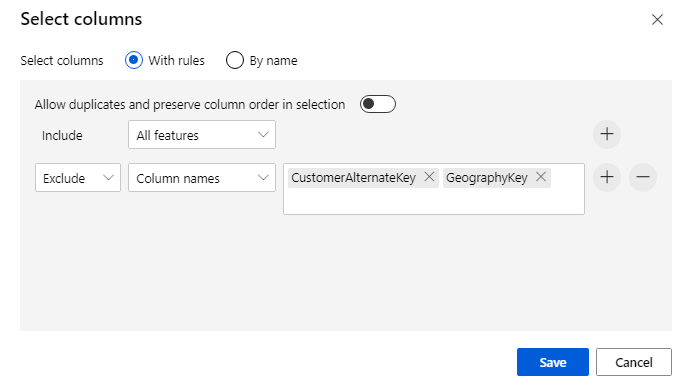
Schließen Sie zwei Spalten aus: „CustomerAlternateKey“ und „GeographyKey“. Klicken Sie unten auf der Seite auf Speichern.

Erstellen des Modells
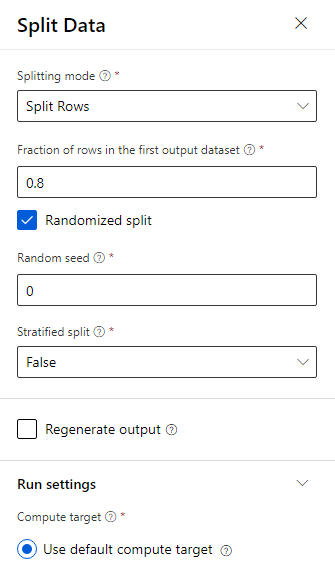
Die Daten werden „80–20“ aufgeteilt: 80 % zum Trainieren eines Machine Learning-Modells und 20 % zum Testen des Modells. In diesem binären Klassifizierungsproblem werden „Two-Class“-Algorithmen verwendet.
Ziehen Sie die Komponente Daten aufteilen in den Zeichenbereich.
Geben Sie im Eigenschaftenbereich für Fraction of rows in the first output dataset (Anteil der Zeilen im ersten Ausgabedataset) den Wert „0,8“ ein.
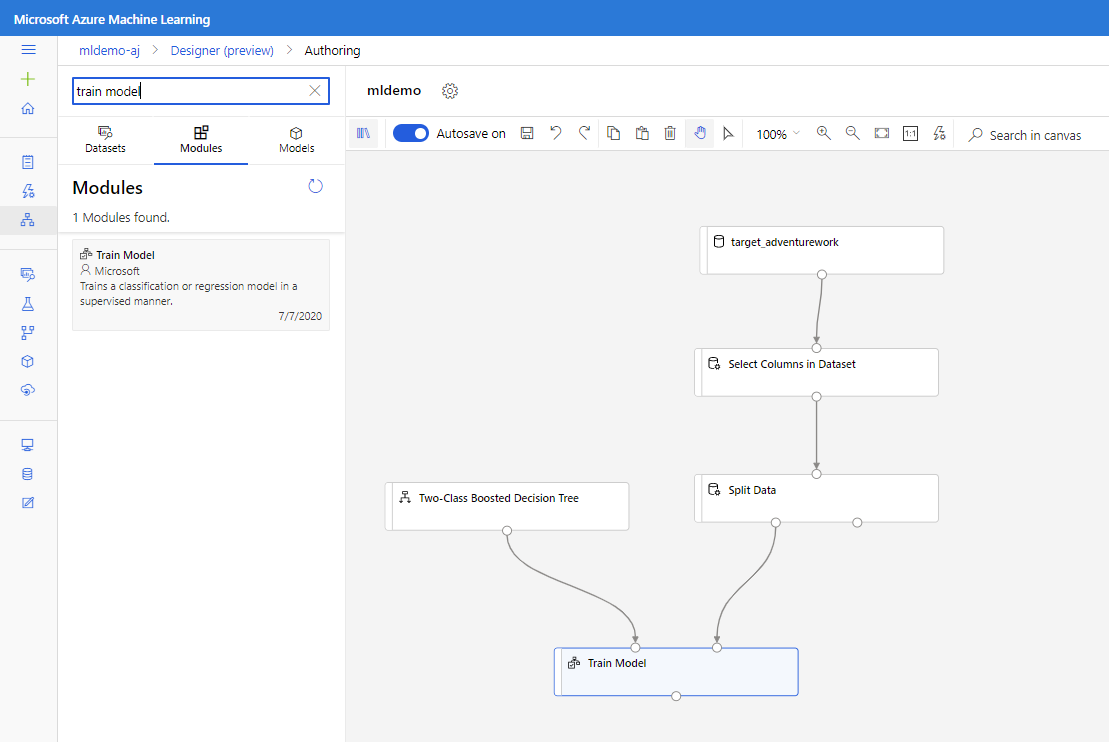
Ziehen Sie die Komponente Verstärkte Entscheidungsstruktur mit zwei Klassen in den Zeichenbereich.
Ziehen Sie die Komponente Modell trainieren in den Zeichenbereich. Nehmen Sie Eingaben vor, indem Sie es mit den Modulen Verstärkte Entscheidungsstruktur mit zwei Klassen (ML-Algorithmus) und Daten aufteilen (Daten zum Trainieren des Algorithmus) verbinden.
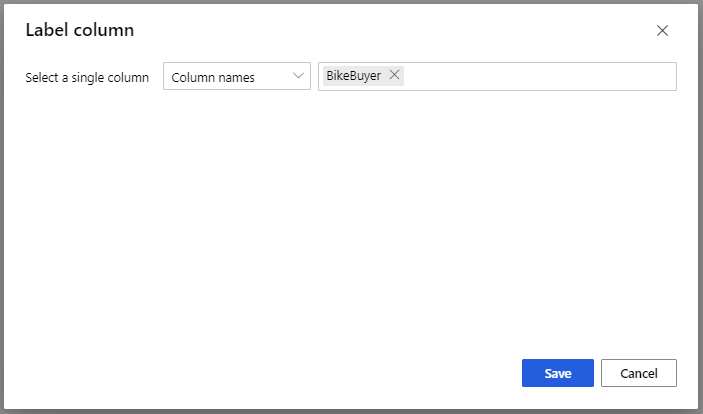
Wählen Sie beim Modul „Train Model“ im Bereich „Eigenschaften“ die Option Bezeichnungsspalte und dann „Spalte bearbeiten“ aus. Wählen Sie die Spalte BikeBuyer (Fahrradkäufer) als die vorherzusagende Spalte und dann Speichern aus.
Bewertung des Modells
Testen Sie jetzt die Leistung des Modells bei Testdaten. Es werden zwei verschiedene Algorithmen verglichen, um zu sehen, welche Leistung besser ist. Führen Sie dafür die folgenden Schritte aus:
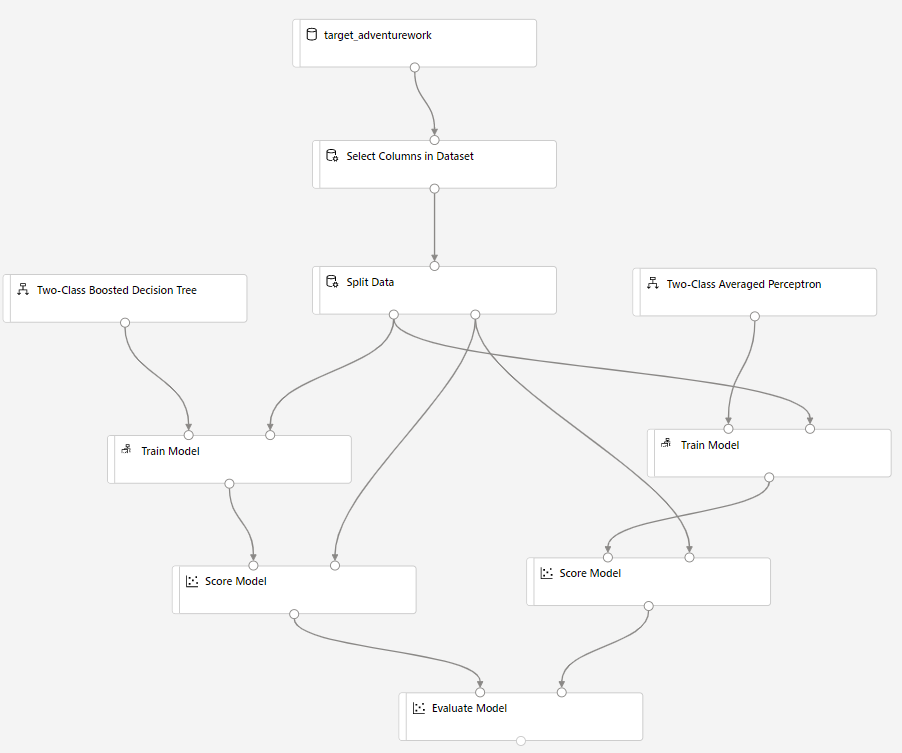
Ziehen Sie die Komponente Score Model in den Zeichenbereich, und verbinden Sie sie mit den Komponenten Train Model und Daten aufteilen.
Ziehen Sie Two-Class Averaged Perceptron (Gemitteltes Perzeptron mit zwei Klassen) in den Experimentbereich. Sie werden jetzt die Leistung dieses Algorithmus mit dem Modul „Two-Class Boosted Decision Tree“ vergleichen.
Kopieren Sie die Komponenten Train Model und Score Model, und fügen Sie sie im Zeichenbereich ein.
Ziehen Sie die Komponente Evaluate Model in den Zeichenbereich, um die beiden Algorithmen zu vergleichen.
Klicken Sie auf Übermitteln, um die Pipelineausführung einzurichten.
Sobald die Ausführung abgeschlossen ist, klicken Sie mit der rechten Maustaste auf die Komponente Evaluate Model, und klicken Sie auf Auswertungsergebnisse visualisieren.
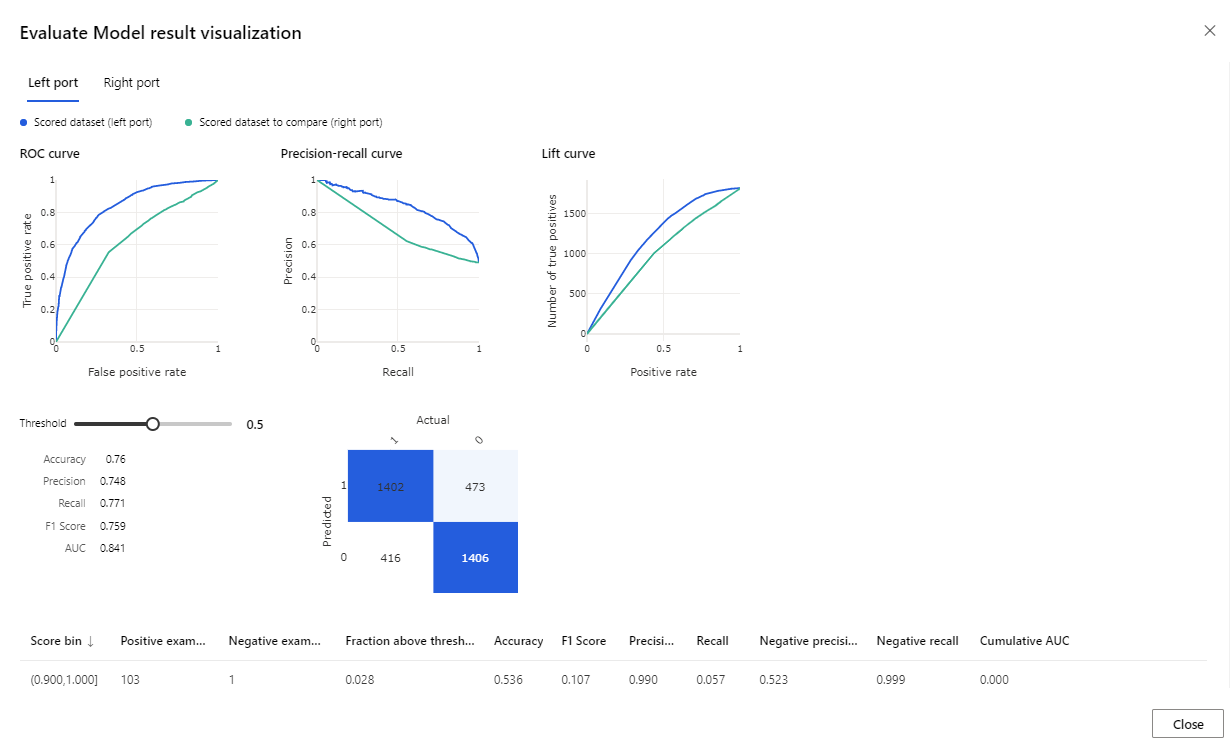

Folgende Metriken stehen zur Verfügung: ROC-Kurve, Genauigkeit-Trefferquote-Diagramm und Prognosegütekurve. Beim Blick auf diese Metriken sehen Sie, dass mit dem ersten Modell eine bessere Leistung als mit dem zweiten erzielt wurde. Wenn Sie sich anschauen möchten, was das erste Modell vorhergesagt hat, klicken Sie mit der rechten Maustaste auf die Komponente „Score Model“, und klicken Sie auf das Dataset „Visualize Scored“, um die vorhergesagten Ergebnisse anzuzeigen.
Wie Sie sehen können, wurden Ihrem Testdatensatz zwei weitere Spalten hinzugefügt.
- Bewertete Wahrscheinlichkeiten: Die Wahrscheinlichkeit, dass es sich bei einem Kunden um einen Fahrradkäufer handelt.
- Bewertete Beschriftungen: die vom Modell vorgenommene Klassifizierung – Fahrradkäufer (1) oder kein Fahrradkäufer (0). Der Wahrscheinlichkeitsschwellenwert für die Beschriftung ist auf 50 Prozent festgelegt, kann aber angepasst werden.
Durch einen Vergleich der Spalte „BikeBuyer“ (tatsächliche Werte) mit „Bewertete Beschriftungen“ (Vorhersage) können Sie die Leistung des Modells ermitteln. Als Nächstes können Sie anhand dieses Modells Vorhersagen für neue Kunden treffen. Sie können dieses Modell als Webdienst veröffentlichen oder Ergebnisse in Azure Synapse zurückschreiben.
Nächste Schritte
Weitere Informationen zu Azure Machine Learning finden Sie unter Einführung in Machine Learning in Azure.
Hier erfahren Sie mehr über die integrierte Bewertung im Data Warehouse.