Tutorial: Verwenden des Designers zum Bereitstellen eines Machine Learning-Modells
In Teil 1 dieses Tutorials haben Sie ein lineares Regressionsmodell trainiert, das Autopreise vorhersagt. In diesem zweiten Teil verwenden Sie den Azure Machine Learning-Designer, um das Modell bereitzustellen, damit andere es verwenden können.
Hinweis
Der Designer unterstützt zwei Komponententypen: klassische vorkonfigurierte Komponenten (v1) und benutzerdefinierte Komponenten (v2). Diese beiden Komponententypen sind NICHT kompatibel.
Klassische vorkonfigurierte Komponenten bieten vordefinierte Komponenten, die vor allem für die Datenverarbeitung und für herkömmliche Machine Learning-Aufgaben wie Regression und Klassifizierung genutzt werden. Dieser Komponententyp wird weiterhin unterstützt, aber es werden keine neuen Komponenten hinzugefügt.
Benutzerdefinierte Komponenten ermöglichen es Ihnen, Ihren eigenen Code als Komponente bereitzustellen. Sie unterstützen die arbeitsbereichsübergreifende Freigabe und die reibungslose Dokumenterstellung über Machine Learning Studio-, CLI v2- und SDK v2-Schnittstellen.
Für neue Projekte wird empfohlen, benutzerdefinierte Komponenten zu verwenden, die mit Azure Machine Learning v2 kompatibel sind und weiterhin neue Updates erhalten.
Dieser Artikel gilt für klassische vordefinierte Komponenten und ist nicht mit CLI v2 und SDK v2 kompatibel.
In diesem Tutorial:
- Erstellen einer Echtzeit-Rückschlusspipeline
- Erstellen eines Rückschlussclusters
- Bereitstellen des Echtzeitendpunkts
- Testen des Echtzeitendpunkts
Voraussetzungen
Absolvieren Sie den ersten Teil des Tutorials, um zu erfahren, wie Sie im Designer ein Machine Learning-Modell trainieren und bewerten.
Wichtig
Falls die in diesem Dokument erwähnten grafischen Elemente bei Ihnen nicht angezeigt werden, z. B. Schaltflächen in Studio oder im Designer, verfügen Sie unter Umständen nicht über die richtige Berechtigungsebene für den Arbeitsbereich. Wenden Sie sich an Ihren Azure-Abonnementadministrator, um sich zu vergewissern, dass Ihnen die richtige Zugriffsebene gewährt wurde. Weitere Informationen finden Sie unter Verwalten von Benutzern und Rollen.
Erstellen einer Echtzeit-Rückschlusspipeline
Zum Bereitstellen Ihrer Pipeline müssen Sie zunächst die Trainingspipeline in eine Echtzeit-Rückschlusspipeline konvertieren. Dadurch werden die Trainingskomponenten entfernt und Webdiensteingaben und -ausgaben für die Verarbeitung von Anforderungen hinzugefügt.
Hinweis
Das Feature Rückschlusspipeline erstellen unterstützt Trainingspipelines, die nur die im Designer integrierten Komponenten enthalten und über eine Komponente wie Modell trainieren verfügen, die das trainierte Modell ausgibt.
Erstellen einer Echtzeit-Rückschlusspipeline
Wählen Sie Pipelines im seitlichen Navigationsbereich aus, und öffnen Sie dann den von Ihnen erstellten Pipelineauftrag. Wählen Sie auf der Detailseite oberhalb der Pipelinecanvas die Auslassungspunkte ... und dann Rückschlusspipeline erstellen>Echtzeit-Rückschlusspipeline aus.

Ihre neue Pipeline sieht nun wie folgt aus:
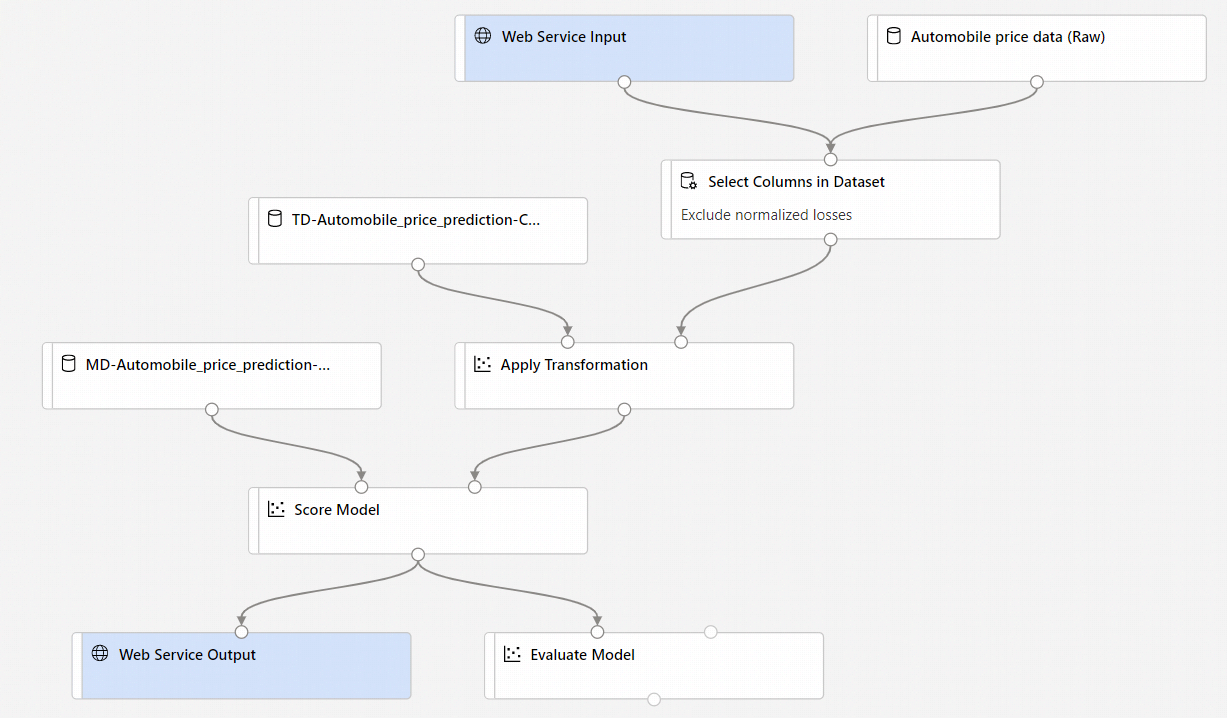
Wenn Sie Rückschlusspipeline erstellen auswählen, passiert Folgendes:
- Das trainierte Modell wird als Komponente Dataset in der Komponentenpalette gespeichert. Sie finden es unter My Datasets (Meine Datasets).
- Trainingskomponenten wie Modell trainieren und Daten aufteilen werden entfernt.
- Das gespeicherte trainierte Modell wird wieder der Pipeline hinzugefügt.
- Die Komponenten Webdiensteingabe und Webdienstausgabe werden hinzugefügt. Diese Komponenten zeigen, wo Benutzerdaten in die Pipeline gelangen und wo sie zurückgegeben werden.
Hinweis
Standardmäßig erwartet die Webdiensteingabe dasselbe Datenschema wie die Komponentenausgabedaten, die eine Verbindung mit demselben Downstreamport herstellen. In diesem Beispiel stellen Webdiensteingabe und Automobilpreisdaten (Rohdaten) eine Verbindung mit derselben Downstreamkomponente her. Daher erwartet Webdiensteingabe dasselbe Datenschema wie Automobilpreisdaten (Rohdaten), und die Zielvariablenspalte
priceist im Schema enthalten. Wenn Sie die Daten bewerten, sind Ihnen die Zielvariablenwerte jedoch nicht bekannt. In diesem Fall können Sie die Zielvariablenspalte in der Rückschlusspipeline mithilfe der Komponente Spalten im Dataset auswählen entfernen. Stellen Sie sicher, dass die Ausgabe von Spalten im Dataset auswählen, die die Zielvariablenspalte entfernt, mit demselben Port wie die Ausgabe der Komponente Webdiensteingabe verbunden ist.Wählen Sie Konfigurieren und Übermitteln aus, und verwenden Sie das gleiche Computeziel und Experiment wie im ersten Teil.
Falls dies der erste Auftrag ist, kann es bis zu 20 Minuten dauern, bis die Ausführung der Pipeline vollständig abgeschlossen ist. In den Standardcomputeeinstellungen ist eine minimale Knotengröße von 0 festgelegt. Das bedeutet, dass der Designer Ressourcen nach dem Leerlauf zuordnen muss. Wiederholte Pipelineaufträge nehmen weniger Zeit in Anspruch, da die Rechenressourcen bereits zugewiesen sind. Außerdem verwendet der Designer für jede Komponente zwischengespeicherte Ergebnisse, um die Effizienz weiter zu steigern.
Wechseln Sie zu den Auftragsdetails der Echtzeit-Rückschlusspipeline, indem Sie im linken Bereich Auftragsdetails auswählen.
Wählen Sie Bereitstellen auf der Auftragsdetailseite aus.
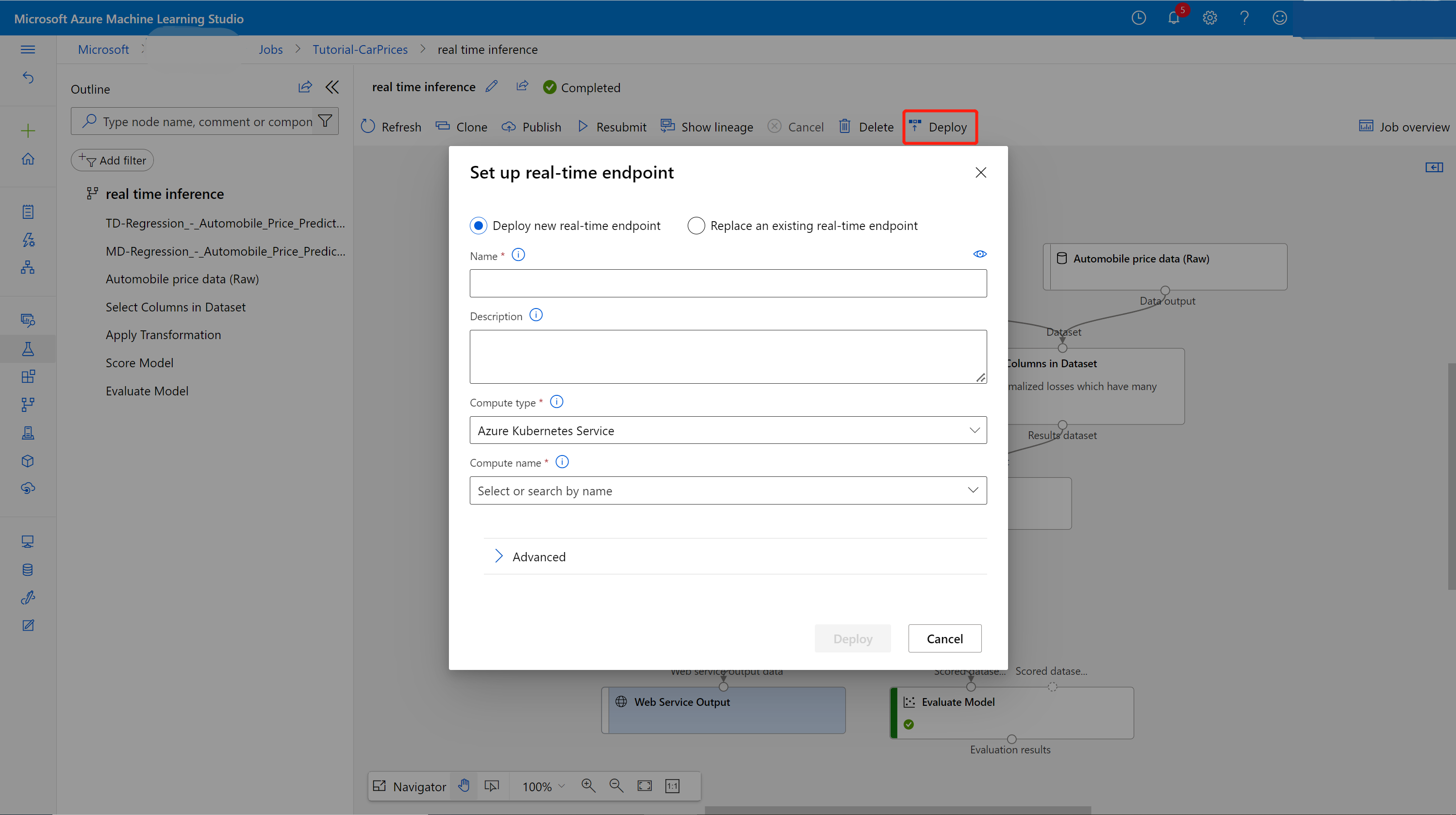


Erstellen eines Rückschlussclusters
Im angezeigten Dialogfeld können Sie auswählen, in welchen vorhandenen AKS-Clustern (Azure Kubernetes Service) Sie Ihr Modell bereitstellen möchten. Sollten Sie über keinen AKS-Cluster verfügen, gehen Sie wie folgt vor, um einen zu erstellen:
Wählen Sie im Dialogfeld die Option Compute aus, um zur Seite Compute zu gelangen.
Wählen Sie auf dem Navigationsmenüband Kubernetes-Cluster>+ Neu aus.
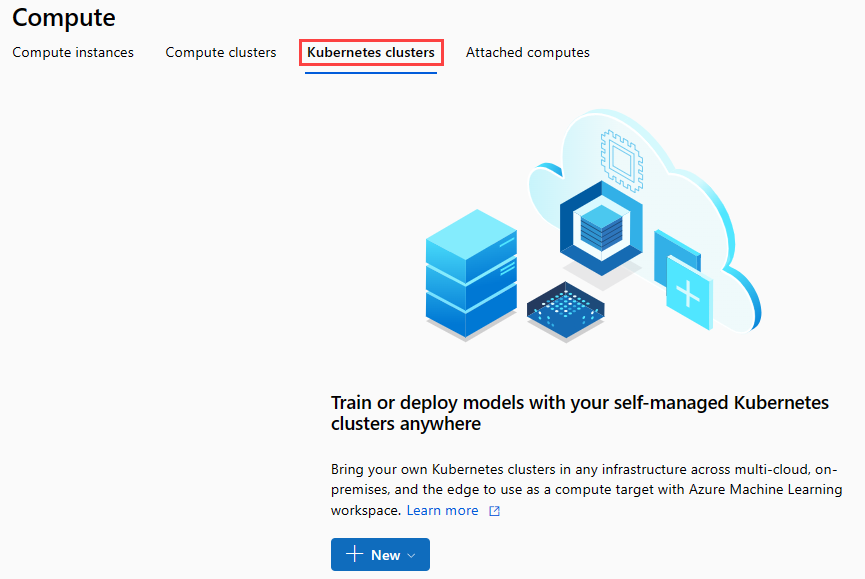
Konfigurieren Sie im Bereich des Rückschlussclusters einen neuen Kubernetes-Dienst.
Geben Sie unter Computename den Namen aks-compute ein.
Wählen Sie unter Region eine verfügbare Region in der Nähe aus.
Klicken Sie auf Erstellen.
Hinweis
Die Erstellung eines neuen AKS-Diensts dauert etwa 15 Minuten. Der Bereitstellungsstatus kann auf der Seite Rückschlusscluster überprüft werden.
Bereitstellen des Echtzeitendpunkts
Kehren Sie nach Abschluss der Bereitstellung des AKS-Diensts zur Echtzeit-Rückschlusspipeline zurück, um die Bereitstellung abzuschließen.
Wählen Sie über der Canvas die Option Bereitstellen aus.
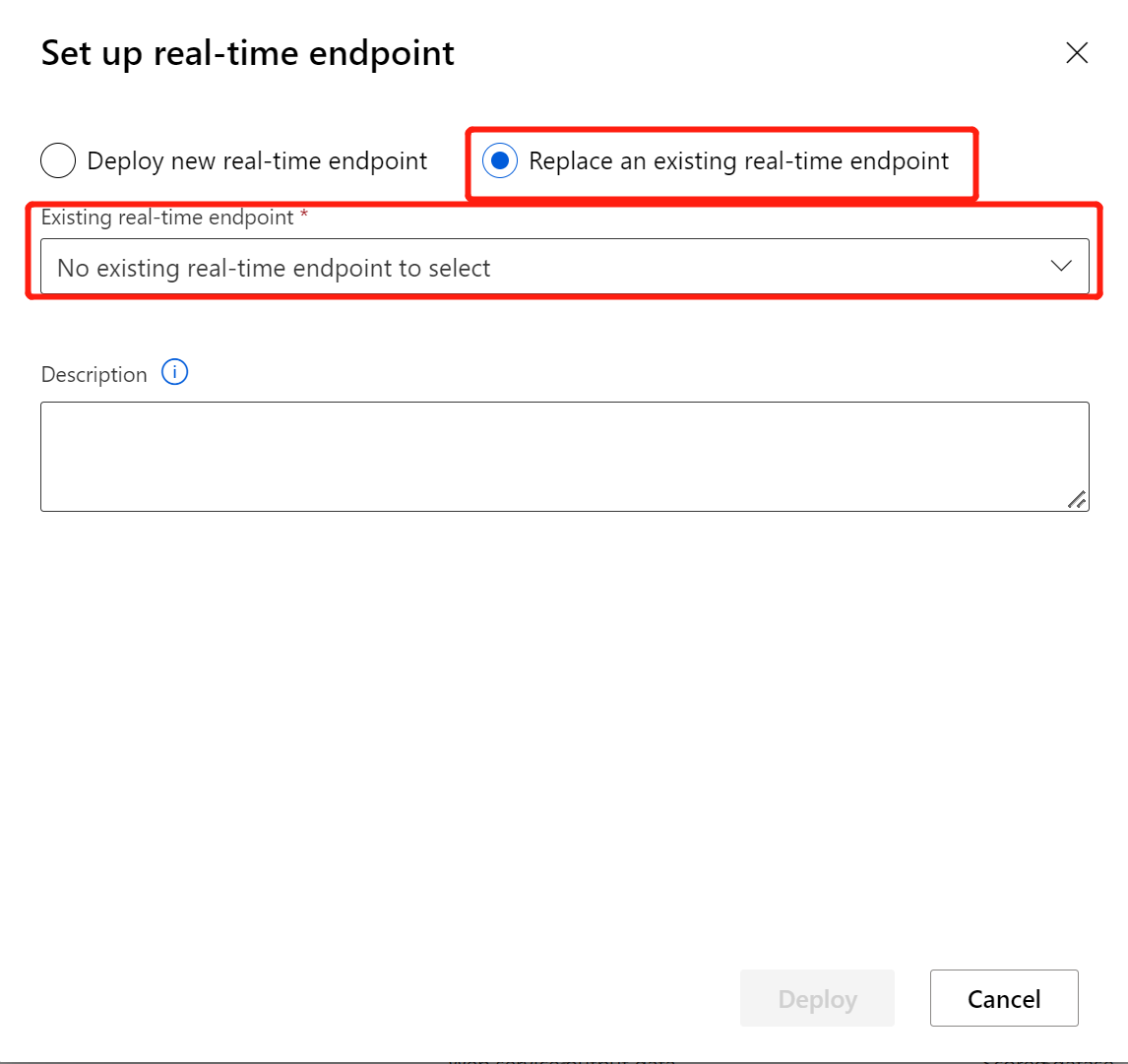
Wählen Sie Neuen Echtzeitendpunkt bereitstellen aus.
Wählen Sie den erstellten AKS-Cluster aus.
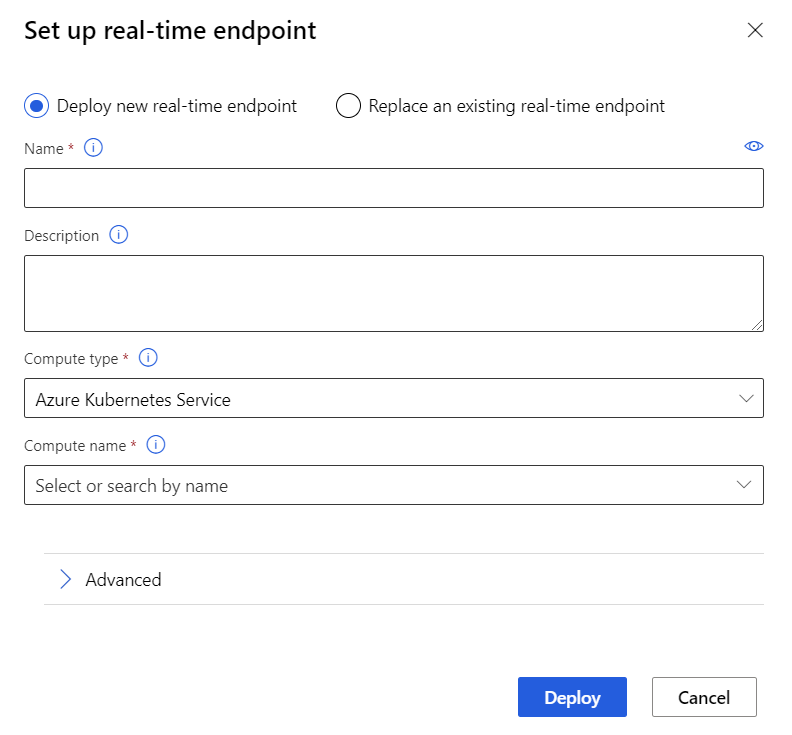
Sie können auch die Einstellung Erweitert für Ihren Echtzeitendpunkt ändern.
Einstellung „Erweitert“ BESCHREIBUNG Application Insights-Diagnose und -Datensammlung aktivieren Ermöglicht Azure Application Insights das Sammeln von Daten von den bereitgestellten Endpunkten.
Standardwert: falseZeitlimit für Bewertung Ein Timeout in Millisekunden, das für Bewertungsaufrufe an den Webdienst erzwungen werden soll
Standardwert: 60.000Automatische Skalierung aktiviert Ermöglicht die automatische Skalierung für den Webdienst.
Standardwert: trueMindestanzahl Replikate Die Mindestanzahl von Containern, die bei der automatischen Skalierung dieses Webdiensts verwendet werden sollen.
Standardwert: 1Maximale Anzahl Replikate Die maximale Anzahl von Containern, die bei der automatischen Skalierung dieses Webdiensts verwendet werden sollen.
Standardwert: 10Zielauslastung Die Zielauslastung (in Prozent), die von der automatischen Skalierung für diesen Webdienst beibehalten werden soll
Standardwert: 70Aktualisierungszeitraum Gibt an, wie oft (in Sekunden) die automatische Skalierung versucht, diesen Webdienst zu skalieren.
Standardwert: 1CPU-Reservekapazität Die Anzahl der CPU-Kerne, die für diesen Webdienst zuzuordnen sind.
Standardwert: 0,1Arbeitsspeicher-Reservekapazität Der Arbeitsspeicherumfang (in GB), der für diesen Webdienst zugeordnet werden soll.
Standardwert: 0,5Klicken Sie auf Bereitstellen.
Nach Abschluss der Bereitstellung wird eine Erfolgsmeldung im Benachrichtigungscenter angezeigt. Dies kann einige Minuten dauern.
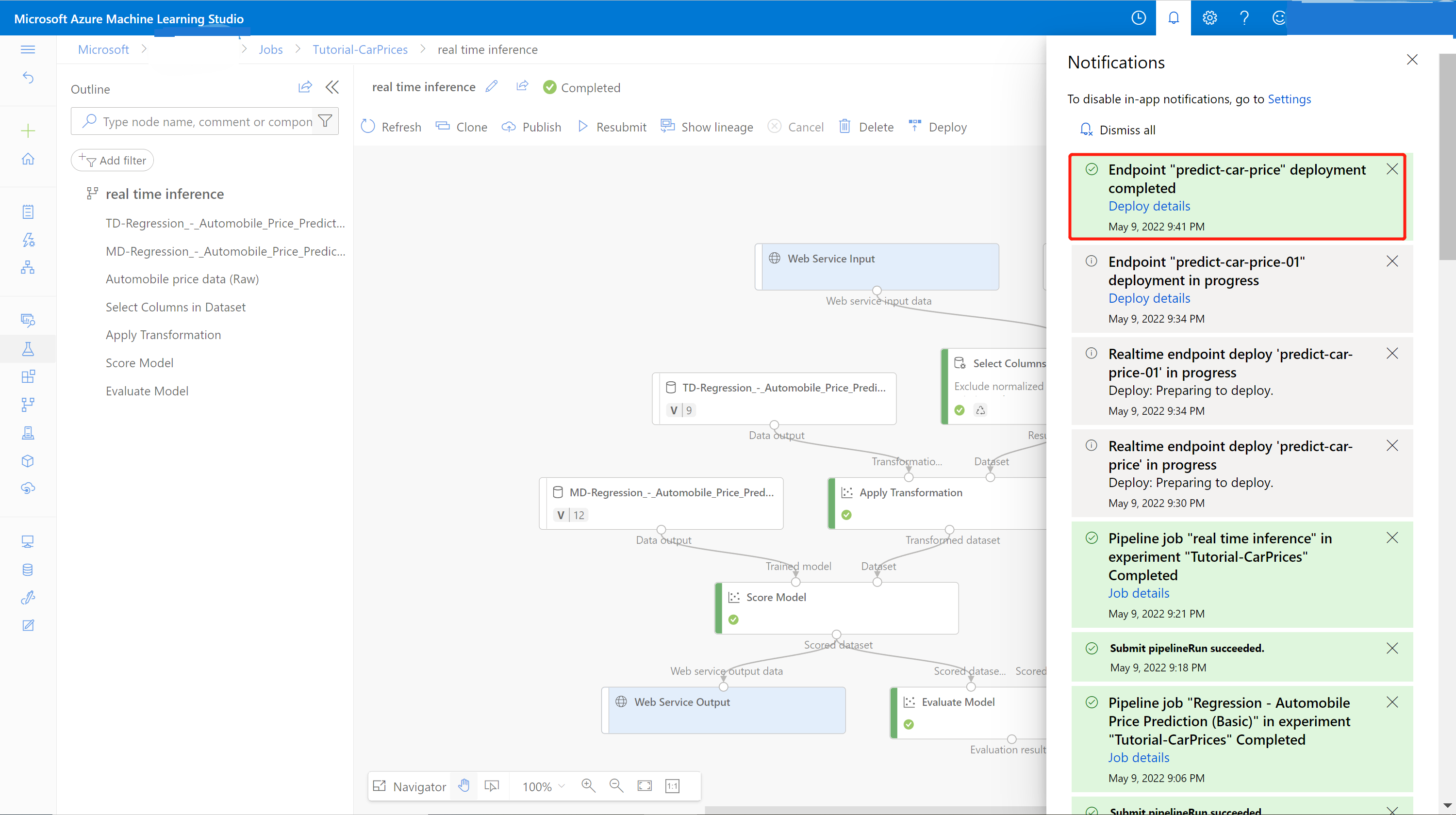

Tipp
Sie können auch eine Bereitstellung in Azure Container Instances ausführen, wenn Sie im Feld mit den Einstellungen für den Echtzeitendpunkt unter Computetyp die Option Azure Container Instance auswählen. Azure Container Instances wird für Tests oder für die Entwicklung verwendet. Verwenden Sie Azure Container Instances für CPU-basierte Workloads mit geringer Skalierung, die weniger als 48 GB Arbeitsspeicher erfordern.
Testen des Echtzeitendpunkts
Nach Abschluss der Bereitstellung können Sie Ihren Echtzeitendpunkt anzeigen, indem Sie zur Seite Endpunkte navigieren.
Wählen Sie auf der Seite Endpunkte den bereitgestellten Endpunkt aus.
Auf der Registerkarte Details werden weitere Informationen angezeigt, z. B. REST-URI, Swagger-Definition, Status und Tags.
Auf der Registerkarte Consume (Nutzen) finden Sie Beispielnutzungscode, Sicherheitsschlüssel und Optionen zum Festlegen der Authentifizierungsmethoden.
Auf der Registerkarte Bereitstellungsprotokolle finden Sie ausführliche Bereitstellungsprotokolle für den Echtzeitendpunkt.
Navigieren Sie zum Testen des Endpunkts zur Registerkarte Test. Hier können Sie Testdaten eingeben und Testen auswählen, um die Ausgabe des Endpunkts zu überprüfen.
Aktualisieren des Echtzeitendpunkts
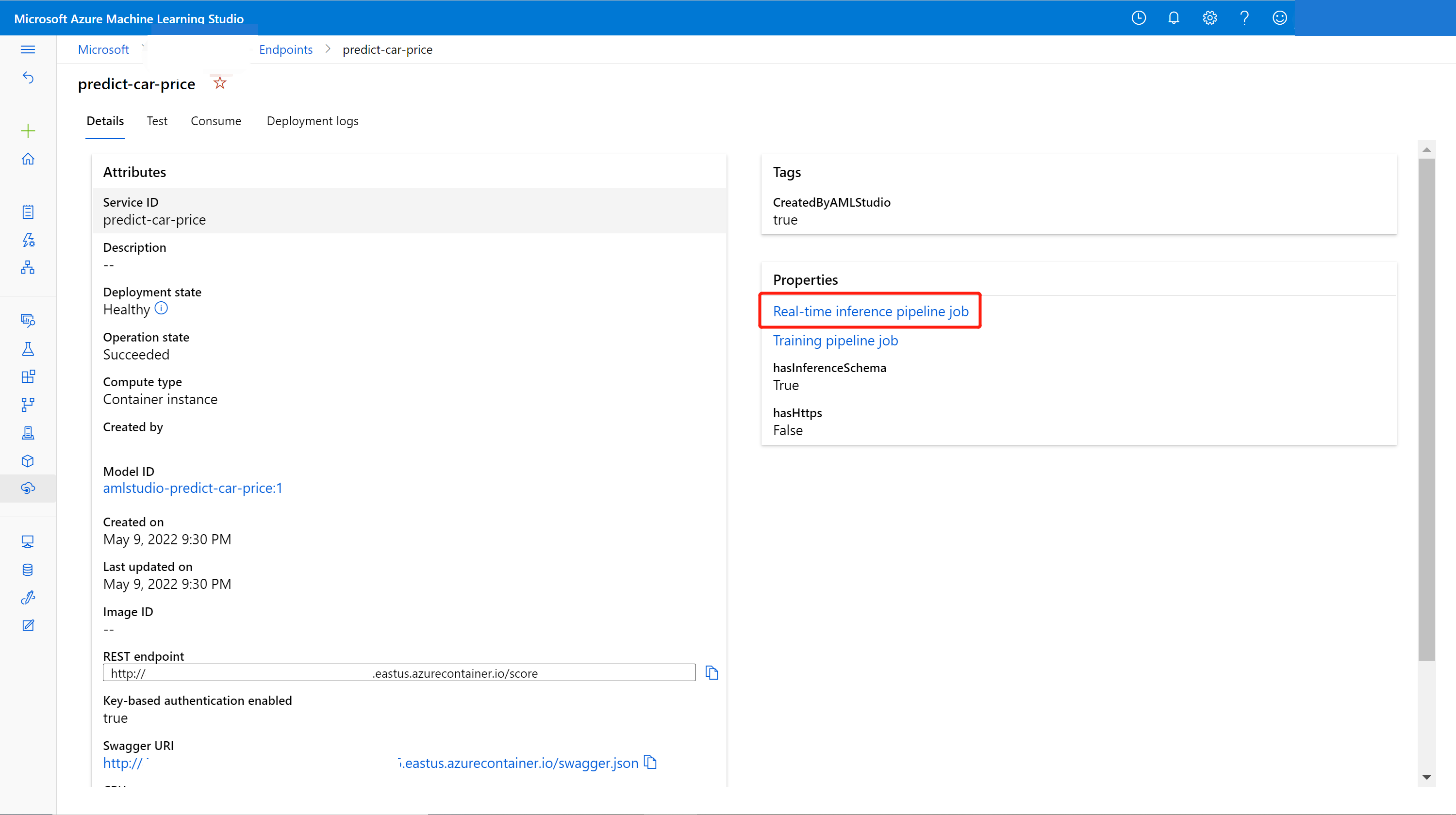
Sie können den Onlineendpunkt mit einem neuen, im Designer trainierten Modell aktualisieren. Suchen Sie auf der Detailseite des Onlineendpunkts nach Ihrem vorherigen Trainingspipeline- und Rückschlusspipelineauftrag.
Sie können Ihren Trainingspipelineentwurf auf der Designer-Homepage finden und ändern.
Sie können aber auch den Link des Trainingspipelineauftrags öffnen und ihn dann in einen neuen Pipelineentwurf klonen, um die Bearbeitung fortzusetzen.
Nachdem Sie die geänderte Trainingspipeline übermittelt haben, wechseln Sie zur Seite mit den Auftragsdetails.
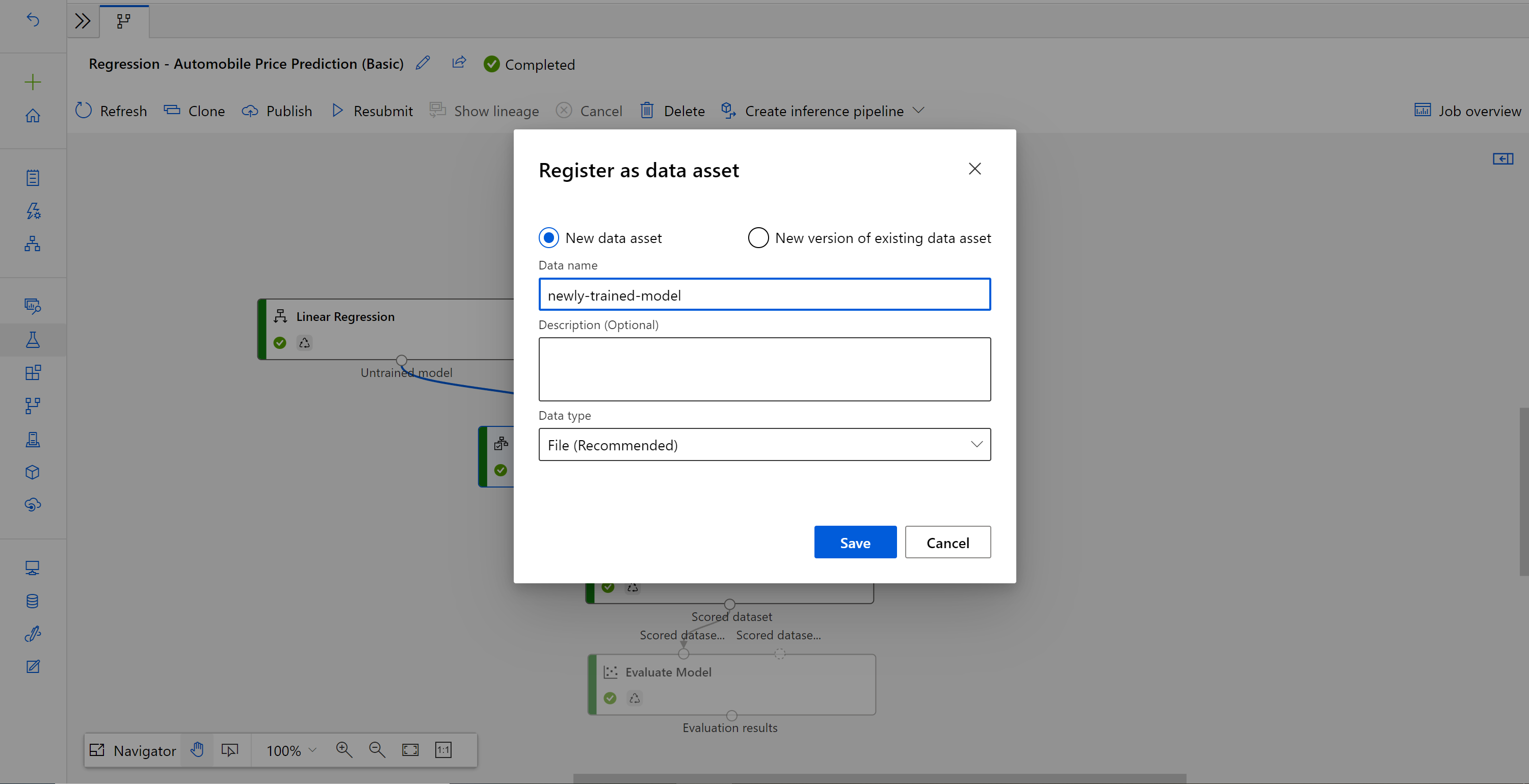
Wenn der Auftrag abgeschlossen ist, klicken Sie mit der rechten Maustaste auf Modell trainieren, und wählen Sie Daten registrieren aus.

Geben Sie den Namen ein, und wählen Sie den Typ Datei aus.
Nachdem das Dataset erfolgreich registriert wurde, öffnen Sie Ihren Rückschlusspipelineentwurf, oder klonen Sie den vorherigen Rückschlusspipelineauftrag in einen neuen Entwurf. Ersetzen Sie im Entwurf der Rückschlusspipeline das zuvor trainierte Modell, das als Knoten MD-XXXX mit der Komponente Modell bewerten verbunden ist, durch das neu registrierte Dataset.
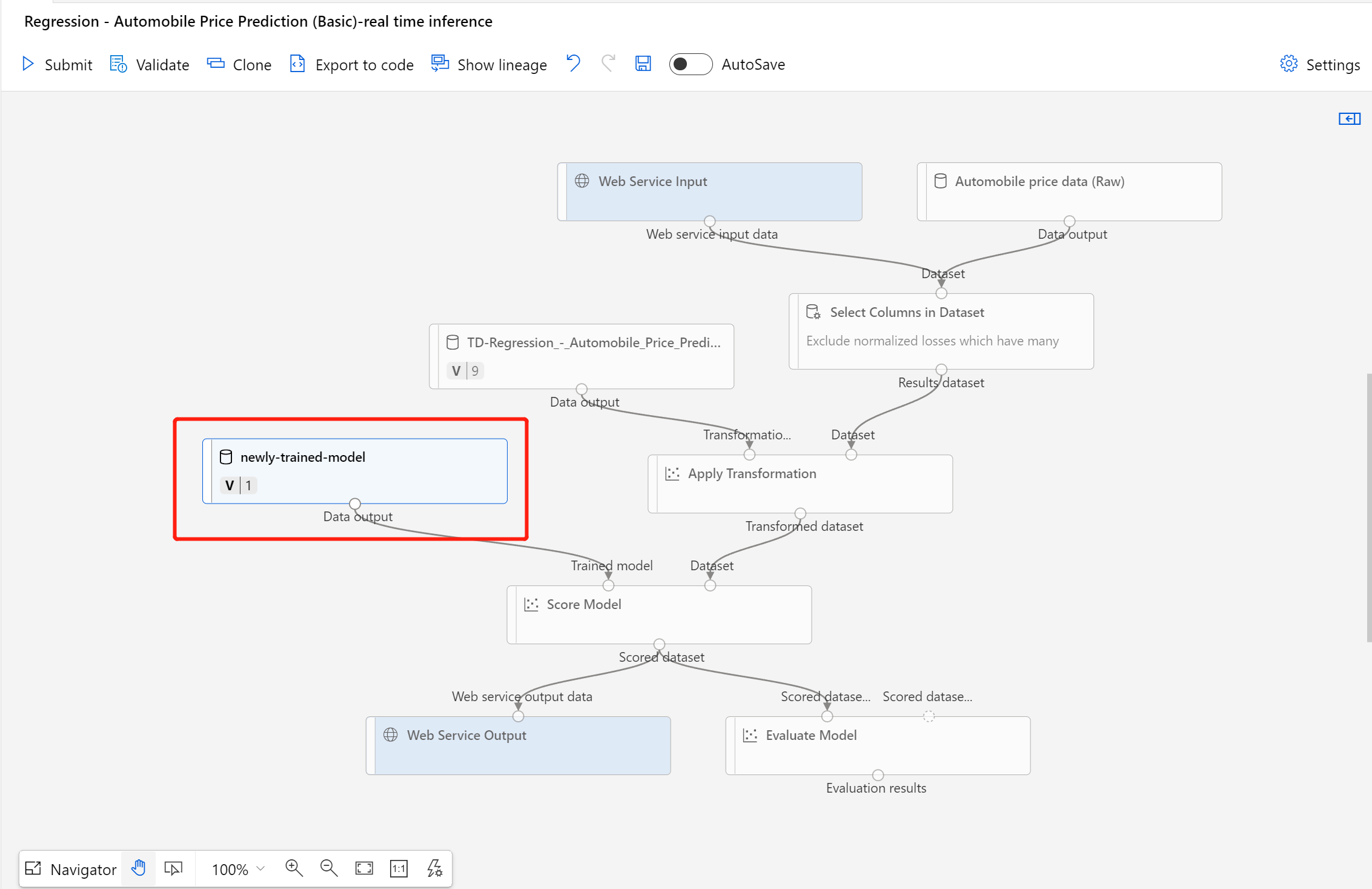
Wenn Sie den Teil der Datenvorverarbeitung in Ihrer Trainingspipeline aktualisieren müssen und diesen in die Rückschlusspipeline übernehmen möchten, ist die Verarbeitung ähnlich wie bei den obigen Schritten.
Sie müssen lediglich die Transformationsausgabe der Transformationskomponente als Dataset registrieren.
Ersetzen Sie anschließend die TD--Komponente in der Rückschlusspipeline manuell durch das registrierte Dataset.

Nachdem Sie Ihre Rückschlusspipeline mit dem neu trainierten Modell oder der Transformation geändert haben, übermitteln Sie sie. Wenn der Auftrag abgeschlossen ist, stellen Sie ihn auf dem bestehenden Onlineendpunkt, der zuvor bereitgestellt wurde.




Begrenzungen
Enthält Ihre Rückschlusspipeline die Komponente Daten importieren oder Daten exportieren, werden diese aufgrund der Datenspeicherzugriffsbeschränkung automatisch entfernt, wenn sie auf einem Echtzeitendpunkt bereitgestellt werden.
Wenn Sie Datasets in der Echtzeit-Rückschlusspipeline haben und sie auf einem Echtzeitendpunkt bereitstellen möchten, unterstützt dieser Fluss derzeit nur Datasets, die von Blob-Datenspeicher aus registriert sind. Wenn Sie Datasets aus anderen Typdatenspeichern verwenden möchten, können Sie Spalte auswählen verwenden, um eine Verbindung mit Ihrem anfänglichen Dataset mit den Einstellungen für die Auswahl aller Spalten herzustellen, die Ausgaben von Spalte auswählen als Dateidataset zu registrieren und dann das erste Dataset in der Echtzeit-Rückschlusspipeline durch dieses neu registrierte Dataset zu ersetzen.
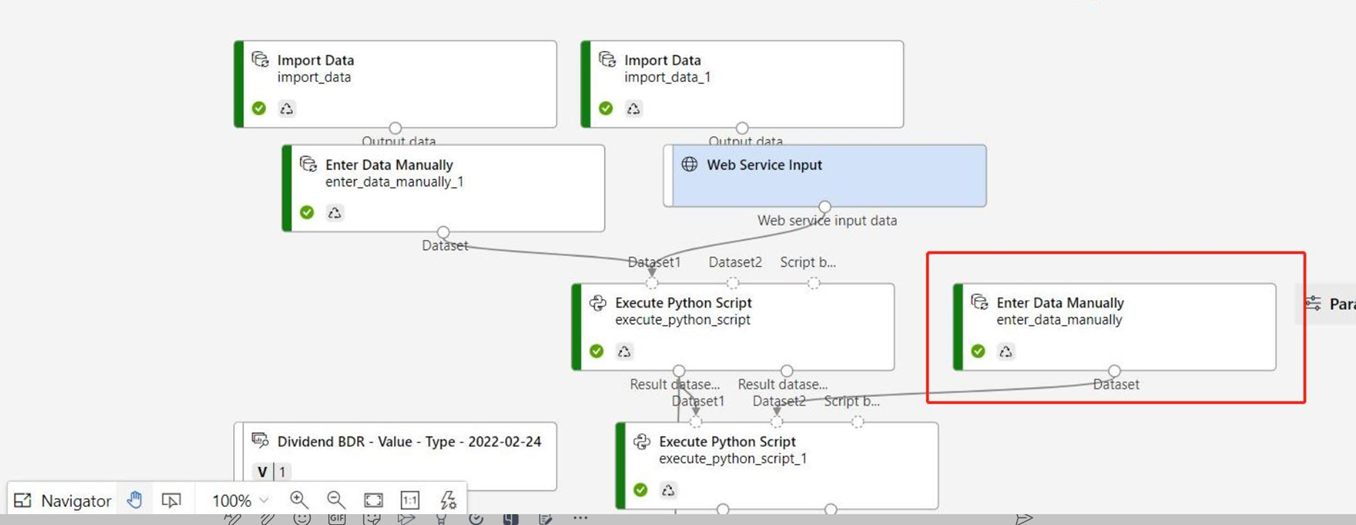
Wenn Ihr Rückschlussgraph die Komponente Daten manuell eingeben enthält, die nicht mit demselben Port wie die Komponente Webdiensteingabe verbunden ist, wird die Komponente Daten manuell eingeben während der HTTP-Aufrufverarbeitung nicht ausgeführt. Eine Problemumgehung ist, die Ausgaben dieser Komponente Daten manuell eingeben als Dataset zu registrieren und dann im Entwurf der Rückschlusspipeline die Komponente Daten manuell eingeben durch das registrierte Dataset zu ersetzen.

Bereinigen von Ressourcen
Wichtig
Sie können die von Ihnen bei der Vorbereitung erstellten Ressourcen auch in anderen Tutorials und Anleitungen für Azure Machine Learning verwenden.
Alles löschen
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie die gesamte Ressourcengruppe, damit Ihnen keine Kosten entstehen.
Wählen Sie im Azure-Portal links im Fenster Ressourcengruppen aus.
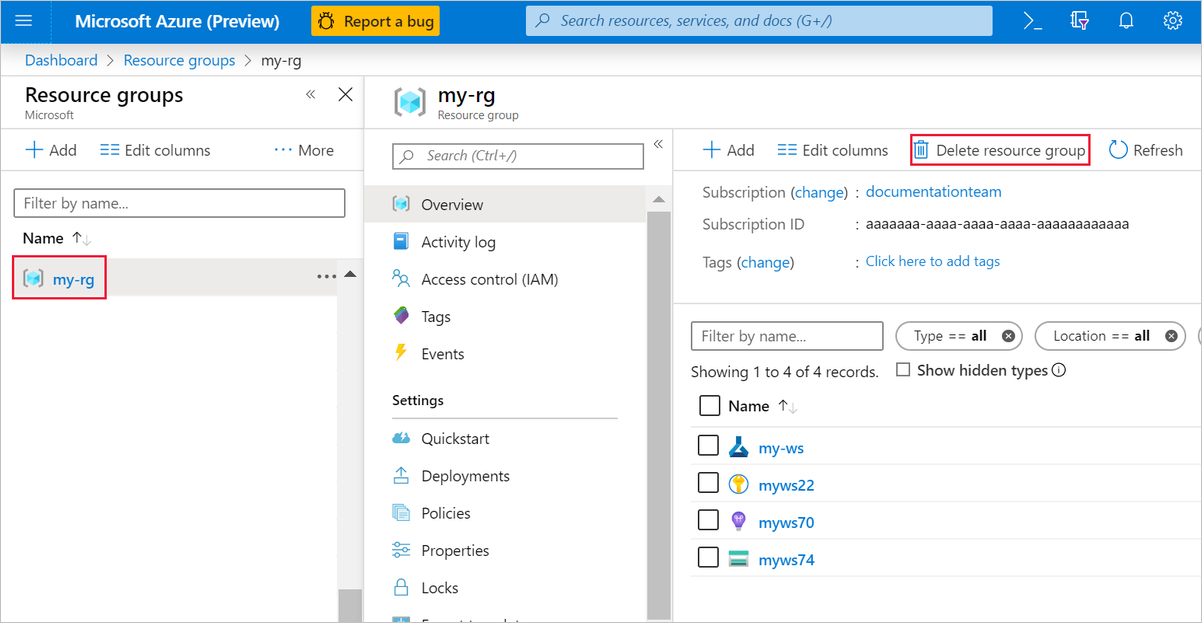
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Klicken Sie auf Ressourcengruppe löschen.
Durch das Löschen einer Ressourcengruppe werden auch alle im Designer erstellten Ressourcen gelöscht.
Löschen einzelner Objekte
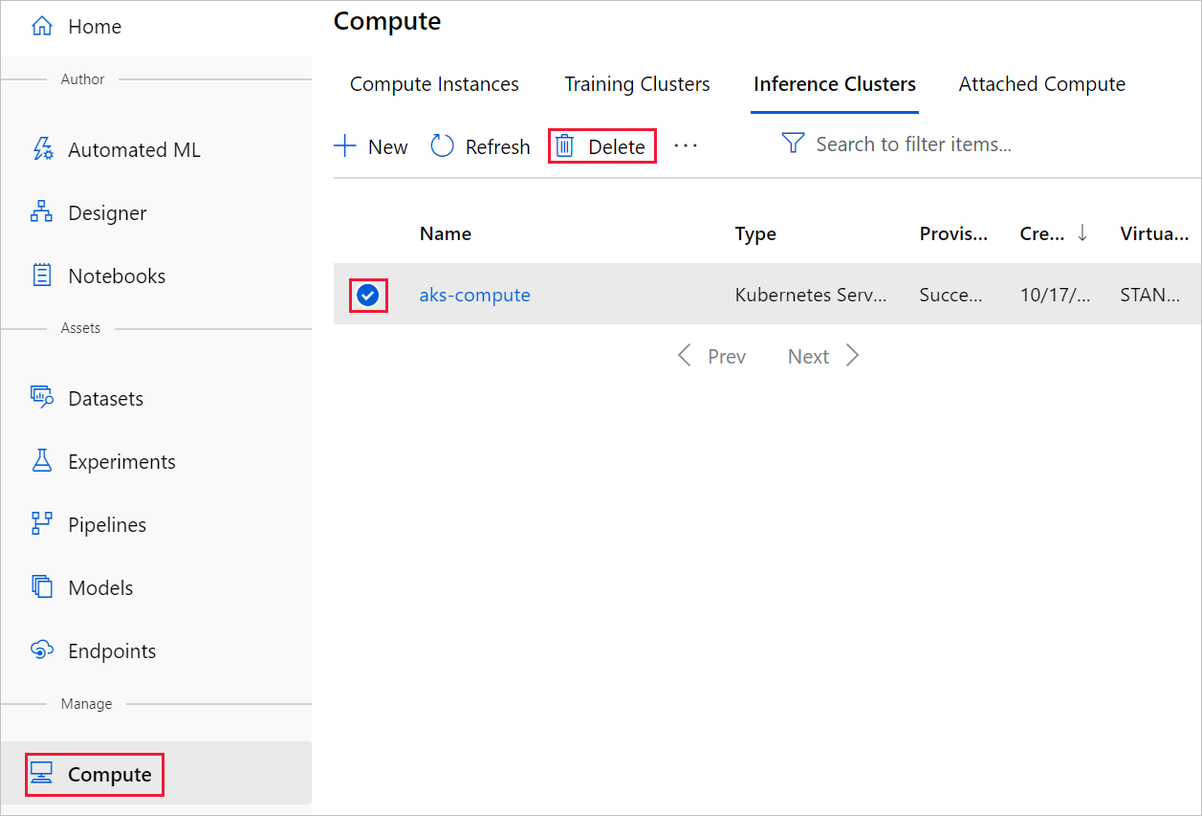
In dem Designer, in dem Sie Ihr Experiment erstellt haben, können Sie einzelne Ressourcen löschen, indem Sie erst die gewünschten Ressourcen und dann die Schaltfläche Löschen auswählen.
Das hier erstellte Computeziel wird automatisch auf null Knoten skaliert, wenn es nicht verwendet wird. Diese Aktion wird durchgeführt, um Gebühren zu minimieren. Wenn Sie das Computeziel löschen möchten, führen Sie die folgenden Schritte aus:
Die Registrierung von Datasets im Arbeitsbereich kann aufgehoben werden, indem Sie die einzelnen Datasets und anschließend Registrierung aufheben auswählen.
Zum Löschen eines Datasets wechseln Sie im Azure-Portal oder Azure Storage-Explorer zum Speicherkonto, und löschen Sie diese Ressourcen manuell.
Zugehöriger Inhalt
In diesem Tutorial haben Sie erfahren, wie Sie ein Machine Learning-Modell im Designer erstellen, bereitstellen und verwenden. Weitere Informationen zur Verwendung des Designers finden Sie in den folgenden Artikeln: