Gestalten von Suchergebnissen oder Ändern der Zusammensetzung der Suchergebnisse in der Azure KI-Suche
In diesem Artikel wird die Zusammensetzung von Suchergebnissen erklärt und wie Sie Suchergebnisse so gestalten können, dass sie Ihren Szenarien entsprechen. Die Suchergebnisse werden in einer Abfrageantwort zurückgegeben. Die Struktur einer Antwort wird durch Parameter in der Abfrage selbst bestimmt. Diese Parameter umfassen:
- Anzahl der gefundenen Übereinstimmungen im Index (
count) - Anzahl der in der Antwort zurückgegebenen Übereinstimmungen (standardmäßig 50, konfigurierbar über
top) oder pro Seite (skipundtop) - Eine Suchbewertung für jedes Ergebnis, das für die Bewertung verwendet wird (
@search.score) - Felder, die in den Suchergebnissen enthalten sind (
select) - Sortierlogik (
orderby) - Hervorhebung von Begriffen innerhalb eines Ergebnisses (Abgleich entweder des gesamten Ausdrucks oder eines Teils des Ausdrucks im Text)
- Optionale Elemente aus dem semantischer Sortierer (
answersobencaptionsfür jede Übereinstimmung)
Suchergebnisse können Felder auf oberster Ebene enthalten, aber der Großteil der Antwort besteht aus übereinstimmenden Dokumenten in einem Array.
Clients und APIs zum Definieren der Abfrageantwort
Sie können die folgenden Clients verwenden, um eine Abfrageantwort zu konfigurieren:
- Such-Explorer im Azure-Portal, mit JSON-Ansicht, so dass Sie jeden unterstützten Parameter angeben können
- Dokumente – POST (REST-APIs)
- SearchClient.Search Method (Azure SDK für .NET)
- SearchClient.Search Method (Azure SDK für Python)
- SearchClient.Search Method (Azure für JavaScript)
- SearchClient.Search Method (Azure für Java)
Ergebniszusammensetzung
Ergebnisse sind meist tabellarisch und bestehen aus Feldern, die entweder alle Felder vom Typ retrievable enthalten oder auf die in den select-Parametern angegebenen Felder beschränkt sind. Zeilen sind die übereinstimmenden Dokumente, in der Regel in der Reihenfolge ihrer Relevanz, es sei denn, Ihre Abfragelogik schließt eine Relevanzeinstufung aus.
Sie können auswählen, welche Felder in Suchergebnissen enthalten sind. Ein Suchdokument kann zwar eine Vielzahl an Feldern haben, werden in der Regel jedoch nur wenige zur Darstellung der einzelnen Dokumente in den Ergebnissen benötigt. Fügen Sie bei einer Abfrageanforderung select=<field list> an, um anzugeben, welche retrievable-Felder in der Antwort erscheinen sollen.
Wählen Sie Felder aus, die die Unterschiede zwischen Dokumenten zeigen und so genügend Informationen liefern, um Benutzer zu einer Antwort durch Klicken einzuladen. Auf einer E-Commerce-Website kann dies ein Produktname, eine Beschreibung, eine Marke, eine Farbe, eine Größe, ein Preis oder eine Bewertung sein. Bei dem integrierten Beispiel „hotels-sample-index“ können dies die „select“-Felder im folgenden Beispiel sein:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Tipps zu unerwarteten Ergebnissen
Manchmal entspricht die Abfrageausgabe nicht Ihren Erwartungen. Beispielsweise bemerken Sie möglicherweise, dass einige Ergebnisse anscheinend Duplikate sind, oder ein Ergebnis, das in der Nähe des oberen Rands angezeigt werden sollte, in den Ergebnissen niedriger positioniert wird. Wenn die Abfrageergebnisse nicht wie erwartet ausfallen, können Sie es mit diesen Änderungen der Abfragen versuchen, um zu ermitteln, ob sich die Ergebnisqualität verbessert:
Ändern Sie
searchMode=any(Standard) insearchMode=all, damit Übereinstimmungen mit allen Kriterien erforderlich sind, nicht nur mit einem oder mehreren Kriterien. Dies gilt besonders, wenn die Abfrage boolesche Operatoren enthält.Experimentieren Sie mit verschiedenen lexikalischen oder benutzerdefinierten Analysetools, um festzustellen, ob sich das Abfrageergebnis ändert. Das Standardanalysetool unterbricht Wörter mit Bindestrichen und reduziert die Wörter auf ihre Stammformen. Dadurch wird die Stabilität einer Abfrageantwort in der Regel verbessert. Wenn Sie jedoch Bindestriche beibehalten müssen oder wenn die Zeichenfolgen Sonderzeichen enthalten, müssen Sie eventuell benutzerdefinierte Analysetools konfigurieren, um sicherzustellen, dass der Index Token im richtigen Format enthält. Weitere Informationen finden Sie unter Suche nach Teilausdrücken und Mustern mit Sonderzeichen (Bindestriche, Platzhalter, reguläre Ausdrücke, Muster).
Zählen von Übereinstimmungen
Der Parameter count gibt die Anzahl der Dokumente im Index zurück, die als Übereinstimmung für die Abfrage betrachtet werden. Um die Anzahl zurückzugeben, fügen Sie der Abfrageanforderung count=true hinzu. Es gibt keinen vom Suchdienst vorgegebenen Höchstwert. Abhängig von Ihrer Abfrage und dem Inhalt Ihrer Dokumente kann die Anzahl alle im Index enthaltenen Dokumente umfassen.
Die Anzahl ist genau, wenn der Index stabil ist. Wenn das System Dokumente aktiv hinzufügt, aktualisiert oder löscht, wird eine ungefähre Anzahl angegeben. Nicht vollständig indizierte Dokumente werden dabei ausgeschlossen.
Die Anzahl wird nicht durch Routinewartungen oder andere Workloads im Suchdienst beeinflusst. Wenn Sie jedoch über mehrere Partitionen und ein einzelnes Replikat verfügen, können kurzfristige Schwankungen bei der Dokumentzählung (mehrere Minuten) auftreten, da die Partitionen neu gestartet werden.
Tipp
Zum Überprüfen von Indizierungsvorgängen können Sie sich vergewissern, dass der Index die erwartete Anzahl von Dokumenten enthält, indem Sie einer leeren search=*-Suchabfrage count=true hinzufügen. Das Ergebnis ist die vollständige Anzahl von Dokumenten in Ihrem Index.
Beim Testen der Abfragesyntax können Sie mithilfe von count=true schnell feststellen, ob Ihre Änderungen mehr oder weniger Ergebnisse zurückgeben. Dieses Feedback kann hilfreich sein.
Anzahl von Ergebnissen in der Antwort
Die Azure KI-Suche verwendet serverseitiges Paging, um zu verhindern, dass Abfragen zu viele Dokumente auf einmal abrufen. Abfrageparameter, die die Anzahl der Ergebnisse in einer Antwort bestimmen, sind top und skip.
top bezieht sich auf die Anzahl der Suchergebnisse auf einer Seite.
skip ist ein Intervall von top und teilt der Suchmaschine mit, wie viele Ergebnisse übersprungen werden sollen, bevor der nächste Satz festgelegt wird.
Die Standardseitengröße ist 50. Die maximale Seitengröße ist 1,000. Wenn Sie einen Wert angeben, der größer als 1.000 ist und mehr als 1.000 Ergebnisse in Ihrem Index gefunden werden, werden nur die ersten 1.000 Ergebnisse zurückgegeben. Wenn die Anzahl der Übereinstimmungen die Seitengröße überschreitet, enthält die Antwort Informationen zum Abrufen der nächsten Seite mit Ergebnissen. Zum Beispiel:
"@odata.nextLink": "https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01"
Die besten Treffer werden anhand der Suchergebnisse ermittelt, vorausgesetzt, es handelt sich um eine Volltextsuche oder eine semantische Suche. Andernfalls sind die Top-Treffer eine willkürliche Reihenfolge für exakte Suchanfragen (wobei ein einheitliches @search.score=1.0 eine willkürliche Bewertung anzeigt).
Legen Sie top fest, um den Standardwert von 50 außer Kraft zu setzen. Wenn Sie eine Hybridabfrage verwenden, können Sie in neueren Vorschau-APIs maxTextRecallSize angeben, um bis zu 10.000 Dokumente zurückzugeben.
Um das Paging aller in einer Ergebnismenge zurückgegebenen Dokumente zu steuern, verwenden Sie top und skip zusammen. Diese Abfrage gibt den ersten Satz von 15 übereinstimmenden Dokumenten sowie die Gesamtzahl der Übereinstimmungen zurück.
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 0
}
Diese Abfrage gibt den zweiten Satz zurück, wobei die ersten 15 übersprungen werden, um die nächsten 15 (16 bis 30) zu erhalten:
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 15
}
Es ist nicht sicher, dass die Ergebnisse von paginierten Abfragen stabil sind, wenn sich der zugrunde liegende Index ändert. Beim Paging ändert sich der Wert von skip für die einzelnen Seiten. Dabei sind die einzelnen Abfragen jedoch unabhängig und werden für die aktuelle Ansicht der Daten ausgeführt, die im Index zur Abfragezeit vorhanden sind. (Das bedeutet, es gibt kein Zwischenspeichern bzw. keine Momentaufnahmen der Ergebnisse wie etwa bei universellen Datenbanken.)
Mit dem folgenden Beispiel werden möglicherweise Duplikate zurückgegeben. Stellen Sie sich einen Index mit vier Dokumenten vor:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Stellen Sie sich nun vor, es sollen immer je zwei Ergebnisse nach Bewertung sortiert zurückgegeben werden. Sie würden die folgende Abfrage ausführen, um die erste Seite mit Ergebnissen abzurufen: $top=2&$skip=0&$orderby=rating desc. Damit werden die folgenden Ergebnisse erzeugt:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
Stellen Sie sich nun vor, dass bei dem Dienst zwischen den Abfragen { "id": "5", "rating": 4 } als fünftes Dokument in den Index aufgenommen wird. Kurze Zeit später führen Sie eine Abfrage aus, um die zweite Seite abzurufen: $top=2&$skip=2&$orderby=rating desc. Damit werden die folgenden Ergebnisse abgerufen:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Wie Sie sehen, wurde Dokument 2 zweimal abgerufen. Der Grund dafür ist, dass das neue Dokument 5 einen größeren Wert für die Bewertung aufweist, sodass es in der Reihenfolge vor Dokument 2 kommt und daher auf der ersten Seite landet. Dieses Verhalten ist zwar möglicherweise unerwartet, jedoch typisch für das Verhalten eines Suchmoduls.
Kachelverwaltung durch eine große Anzahl von Ergebnissen
Eine alternative Methode für das Paging ist die Verwendung einer Sortierreihenfolge und eines Bereichsfilters als Workaround für skip.
Bei diesem Workaround werden Sortierung und Filter auf ein Dokument-ID-Feld oder ein anderes Feld angewendet, das für jedes Dokument eindeutig ist. Das eindeutige Feld muss filterable und sortable Zuordnung im Suchindex aufweisen.
Führen Sie eine Abfrage aus, um eine ganze Seite sortierter Ergebnisse zurückzugeben.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Wählen Sie das letzte Ergebnis aus, das von der Suchabfrage zurückgegeben wird. Im Folgenden finden Sie ein Beispielresultset mit nur einem ID-Wert.
{ "id": "50" }Verwenden Sie diesen ID-Wert in einer Bereichsabfrage, um die nächste Seite mit Ergebnissen abzurufen. Dieses ID-Feld sollte eindeutige Werte enthalten, da andernfalls die Paginierung doppelte Ergebnisse enthalten kann.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }Der Seitenumbruch endet, wenn die Abfrage null Ergebnisse zurückgibt.
Hinweis
Die Attribute filterable und sortable können nur aktiviert werden, wenn ein Feld erstmalig zu einem Index hinzugefügt wird, sie können nicht für ein vorhandenes Feld aktiviert werden.
Reihenfolge von Ergebnissen
In einer Volltextsuchabfrage können die Ergebnisse wie folgt priorisiert werden:
- eine Suchbewertung
- eine semantische Reranker-Bewertung
- eine Sortierreihenfolge für ein
sortable-Feld
Sie können auch alle Übereinstimmungen in bestimmten Feldern erhöhen, indem Sie ein Bewertungsprofil hinzufügen.
Nach Suchbewertung sortieren
Bei Volltextsuchanfragen werden die Ergebnisse automatisch mit Hilfe eines BM25-Algorithmus nach einem Suchergebnis eingestuft, das auf der Häufigkeit von Begriffen, der Dokumentlänge und der durchschnittlichen Dokumentlänge berechnet wird.
Der Bereich @search.score ist entweder ungebunden oder 0 bis (aber nicht einschließlich) 1,00 für ältere Dienste.
Für beide Algorithmen steht eine Suchbewertung vom Typ @search.score mit dem Wert „1,00“ für ein nicht bewertetes oder unsortiertes Resultset, bei dem die Bewertung von 1,0 für alle Ergebnisse gleich ist. Nicht bewertete Ergebnisse kommen vor, wenn es sich um eine Fuzzysuche, um eine Abfrage mit Platzhaltern oder regulären Ausdrücken oder um eine leere Suche (search=*) handelt. Falls Sie eine Rangfolgestruktur für nicht bewertete Ergebnisse auferlegen müssen, könnte ein orderby Ausdruck dieses Ziel erreichen.
Sortieren nach der semantischen Neubewertung
Wenn Sie den semantischen Sortierer verwenden, bestimmt @search.rerankerScore die Sortierreihenfolge Ihrer Ergebnisse.
Der Bereich @search.rerankerScore geht von 1 bis 4,00, wobei eine höhere Bewertung eine stärkere semantische Übereinstimmung angibt.
Sortieren mit orderby
Wenn eine konsistente Reihenfolge eine Anforderung der Anwendung ist, können Sie explizit einen orderby Ausdruck in einem Feld definieren. Nur Felder, die als „sortierbar“ indiziert sind, können zum Sortieren von Ergebnissen verwendet werden.
In orderby werden häufig Felder wie Bewertung, Datum und Standort verwendet. Für die Filterung nach Standort muss zusätzlich zum Feldnamen auch die geo.distance()Funktion aufgerufen werden.
Numerische Felder (Edm.Double, Edm.Int32, Edm.Int64) werden in numerischer Reihenfolge sortiert (z. B. 1, 2, 10, 11, 20).
Zeichenfolgenfelder (Unterfelder Edm.String, Edm.ComplexType) werden je nach Sprache entweder in ASCII-Sortierreihenfolge oder Unicode-Sortierreihenfolge sortiert.
Numerische Inhalte in Zeichenfolgenfeldern werden alphabetisch sortiert (1, 10, 11, 2, 20).
Zeichenfolgen in Großbuchstaben werden vor Kleinbuchstaben sortiert (APFEL, Apfel, BANANE, Banane, apfel, banane) sortiert. Sie können einen Textnormalisierer zuweisen, um den Text vor dem Sortieren zu verarbeiten und dieses Verhalten zu ändern. Die Verwendung des klein geschriebenen Tokenizers in einem Feld hat keine Auswirkungen auf das Sortierverhalten, da Azure KI-Suche nach einer nicht analysierten Kopie des Felds sortiert.
Zeichenfolgen, die mit diakritischen Zeichen beginnen (Äpfel, Öffnen, Üben), werden zuletzt angezeigt.
Verbessern der Relevanz mithilfe eines Bewertungsprofils
Ein weiterer Ansatz für eine konsistente Reihenfolge ist die Verwendung eines benutzerdefinierten Bewertungsprofils. Mit Bewertungsprofilen haben Sie mehr Kontrolle über die Bewertung von Elementen in Suchergebnissen und können in bestimmten Feldern gefundene Übereinstimmungen aufwerten. Mithilfe der zusätzlichen Bewertungslogik können geringfügige Unterschiede zwischen Replikaten außer Kraft gesetzt werden, da die Suchbewertungen für die einzelnen Dokumente weiter auseinander liegen. Für diesen Ansatz wird der Rangfolgenalgorithmus empfohlen.
Treffermarkierung
Die Treffermarkierung bezieht sich auf die Textformatierung (wie Fett- oder Gelbmarkierung), die auf Treffer in einem Ergebnis angewendet werden, sodass die Übereinstimmungen leicht zu erkennen sind. Die Markierung eignet sich für längere Inhaltsfelder, z. B. ein Beschreibungsfeld, bei denen die Übereinstimmung nicht sofort ersichtlich ist.
Beachten Sie, dass Hervorhebung auf einzelne Ausdrücke angewendet wird. Es gibt keine Hervorhebungsfunktion für den Inhalt eines gesamten Felds. Wenn Sie einen Ausdruck hervorheben möchten, müssen Sie die übereinstimmenden Begriffe (oder Ausdrücke) in einer in Anführungszeichen eingeschlossenen Abfragezeichenfolge angeben. Diese Technik wird weiter unten in diesem Abschnitt beschrieben.
Anweisungen zur Treffermarkierung werden in der Abfrageanforderung bereitgestellt. Bei Abfragen, die eine Abfrageerweiterung in der Engine auslösen, wie z. B. Fuzzy- und Platzhaltersuche, wird die Treffermarkierung nur begrenzt unterstützt.
Anforderungen für die Trefferhervorhebung
- Felder müssen
Edm.StringoderCollection(Edm.String)sein - Die Felder müssen das Attribut
searchableaufweisen
Angeben der Hervorhebung in der Anforderung
Fügen Sie für die Rückgabe hervorgehobener Begriffe den Hervorhebungsparameter in die Abfrageanforderung ein. Der Parameter wird auf eine durch Kommas getrennte Liste von Feldern festgelegt.
Standardmäßig ist die Formatmarkierung <em>, aber Sie können das Tag mithilfe der Parameter highlightPreTag und highlightPostTag überschreiben. Ihr Clientcode verarbeitet die Antwort (z. B. das Anwenden einer fett formatierten Schriftart oder eines gelben Hintergrunds).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
Azure KI Search gibt standardmäßig bis zu fünf Markierungen pro Feld zurück. Sie können die Anzahl anpassen, indem Sie einen Bindestrich gefolgt von einer ganzen Zahl anfügen.
"highlight": "description-10" gibt beispielsweise bis zu 10 hervorgehobene Begriffe zu übereinstimmenden Inhalten im Beschreibungsfeld zurück.
Hervorgehobene Ergebnisse
Wenn der Abfrage Hervorhebungen hinzugefügt werden, enthält die Antwort ein @search.highlights für jedes Ergebnis, damit Ihr Anwendungscode diese Struktur als Ziel verwenden kann. Die Liste der für „highlight“ angegebenen Felder ist in der Antwort enthalten.
Bei einer Schlüsselwortsuche wird jeder Begriff unabhängig überprüft. Eine Abfrage für „göttliche Geheimnisse“ gibt Übereinstimmungen für jedes Dokument zurück, das einen der beiden Begriffe enthält.
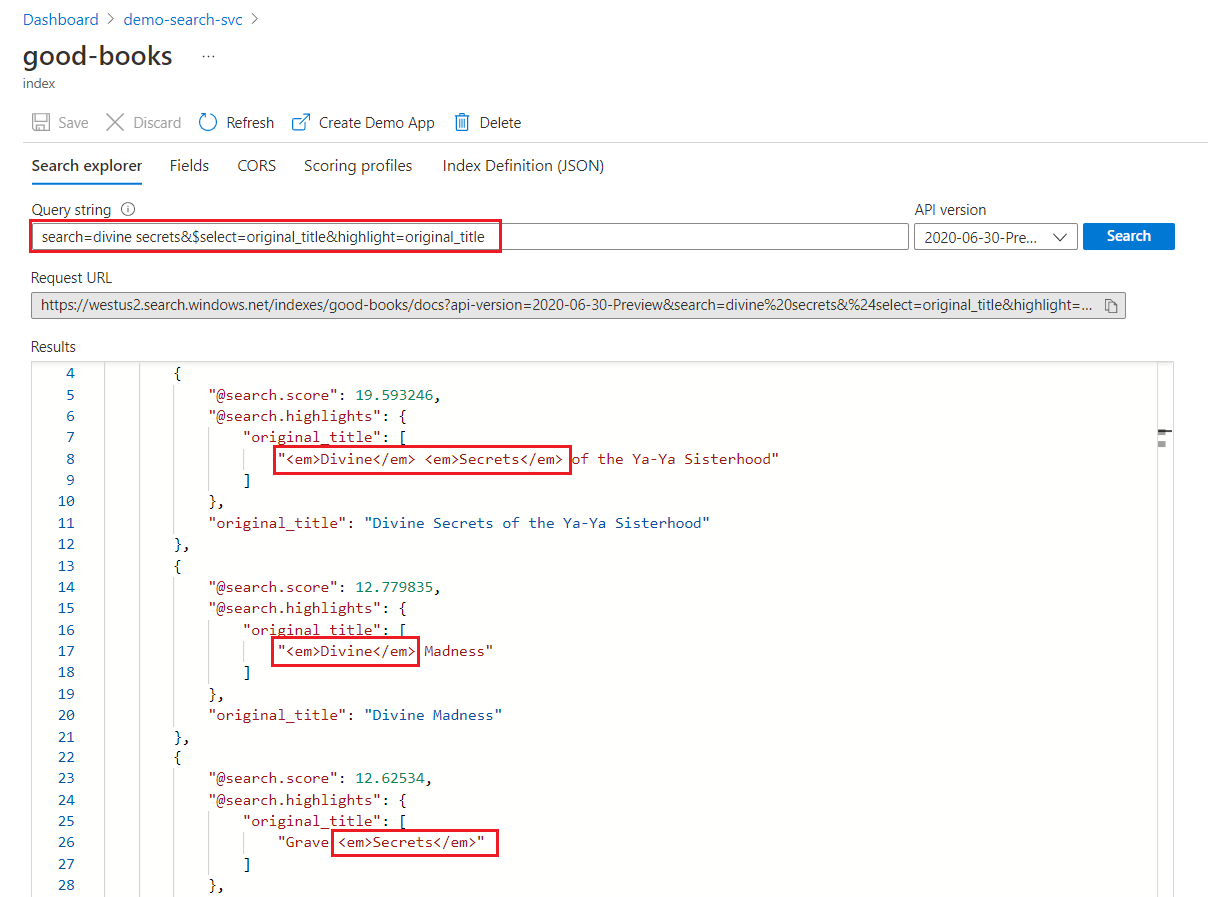
Hervorhebung bei der Schlüsselwortsuche
Innerhalb eines hervorgehobenen Felds wird die Formatierung auf ganze Begriffe angewendet. Bei einer Übereinstimmung mit „Die göttlichen Geheimnisse der Ya-Ya-Schwestern“ wird die Formatierung beispielsweise auf jeden einzelnen Begriff angewandt, auch wenn sie aufeinanderfolgen.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Hervorhebung bei der Ausdruckssuche
Die Formatierung ganzer Begriffe gilt auch für eine Ausdruckssuche, bei der mehrere Begriffe in doppelte Anführungszeichen eingeschlossen werden. Das folgende Beispiel zeigt die gleiche Abfrage, mit dem Unterschied, dass die „göttliche Geheimnisse“ als in Anführungszeichen eingeschlossener Ausdruck übergeben wird (einige REST-Clients erfordern, dass Sie für die inneren Anführungszeichen einen umgekehrten Schrägstrich \" als Escapezeichen verwenden):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Da die Kriterien jetzt beide Begriffe enthalten, wird nur eine Übereinstimmung im Suchindex gefunden. Die Antwort auf die Abfrage oben sieht wie folgt aus:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Ausdruckshervorhebung in älteren Diensten
Bei Suchdiensten, die vor dem 15. Juli 2020 erstellt wurden, unterscheidet sich die Hervorhebung für Ausdrucksabfragen.
In den folgenden Beispielen wird von einer Abfragezeichenfolge ausgegangen, die den in Anführungszeichen eingeschlossenen Ausdruck „Super Bowl“ enthält. Vor Juli 2020 wird jeder Begriff im Ausdruck hervorgehoben:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
Für Suchdienste, die nach dem Juli 2020 erstellt wurden, werden in @search.highlights nur Ausdrücke zurückgegeben, die mit der gesamten Ausdrucksabfrage übereinstimmen:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Nächste Schritte
Wenn Sie schnell eine Suchseite für Ihren Client erstellen möchten, probieren Sie die folgenden Optionen aus:
Mit Demo-App erstellen im Azure-Portal können Sie eine HTML-Seite mit einer Suchleiste, einer Facettennavigation und einem Vorschauminiaturbereich erstellen, wenn Sie Bilder haben.
Hinzufügen der Suche zu einer ASP.NET Core (MVC) App ist ein Tutorial und Codebeispiel, mit dem Sie einen funktionierenden Client erstellen können.
Hinzufügen von Suchfunktionen zu Web-Apps ist ein C#-Tutorial und -Codebeispiel, in dem React-JavaScript-Bibliotheken für die Benutzererfahrung verwendet werden. Die App wird mithilfe von Azure Static Web Apps bereitgestellt und implementiert Paginierung.