Erstellen einer Volltextabfrage in Azure KI-Suche
Falls Sie eine Abfrage für die Volltextsuche erstellen, enthält dieser Artikel Schritte zum Einrichten der Anforderung. Außerdem wird eine Abfragestruktur vorgestellt und erklärt, wie sich Feldattribute und linguistische Analysetools auf die Abfrageergebnisse auswirken können.
Voraussetzungen
Ein Suchindex mit Zeichenfolgefeldern, die das Attribut durchsuchbar aufweisen.
Leseberechtigungen für den Suchindex. Fügen Sie für den Lesezugriff einen Abfrage-API-Schlüssel in die Anforderung ein, oder erteilen Sie dem Aufrufer die Suchindexdatenleser-Berechtigungen.
Beispiel für eine Volltextabfrageanforderung
In Azure KI Search ist eine Abfrage eine schreibgeschützte Anforderung für die Docs-Auflistung eines einzelnen Suchindexes mit Parametern, die sowohl die Abfrageausführung als auch die Form der Zurückführung der Antwort informieren.
Eine Volltextabfrage wird in einem search Parameter angegeben und besteht aus Begriffen, in Anführungszeichen eingeschlossenen Phrasen und Operatoren. Andere Parameter geben der Anforderung weitere Definition.
Der folgende Search POST REST-API-Aufruf veranschaulicht eine Abfrage mit den erwähnten Parametern.
POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "NY +view",
"queryType": "simple",
"searchMode": "all",
"searchFields": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"select": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"top": 10,
"count": true
}
Wesentliche Punkte
searchgibt die Übereinstimmungskriterien an – in der Regel ganze Ausdrücke oder Begriffe, mit oder ohne Operatoren. Jedes im Indexschema als durchsuchbar (searchable) attributierte Feld ist ein Kandidat für diesen Parameter.queryTypelegt den Parser fest: einfach, voll. Der standardmäßige einfache Abfrageparser ist optimal für die Volltextsuche. Der vollständige Lucene-Abfrageparser ist für erweiterte Abfragekonstrukte wie reguläre Ausdrücke, Näherungssuche, Fuzzy- und Wildcard-Suche vorgesehen. Dieser Parameter kann für die semantische Bewertung auch auf semantisch festgelegt werden, um die erweiterte semantischen Modellierung der Abfrageantwort zu ermöglichen.searchModegibt an, ob Übereinstimmungen auf allen Kriterien (begünstigt Präzision) oder beliebigen Kriterien (begünstigt Abruf) im Ausdruck basieren. Die Standardeinstellung ist beliebig. Wenn Sie mit einer vermehrten Verwendung boolescher Operatoren rechnen – was in Indizes mit großen Textblöcken (ein Inhaltsfelde oder lange Beschreibungen) wahrscheinlicher ist –, stellen Sie sicher, dass Sie Abfragen mit dem ParametersearchMode=Any|Alltesten, um die Auswirkung dieser Einstellung auf eine boolesche Suche auszuwerten.searchFieldsschränkt die Abfrageausführung auf bestimmte durchsuchbare Felder ein. Während der Entwicklung ist es hilfreich, dieselbe Feldliste für „select“ und „search“ zu verwenden. Andernfalls könnte eine Entsprechung auf Feldwerten basieren, die in den Ergebnissen nicht angezeigt werden, sodass ungewiss ist, warum das Dokument zurückgegeben wurde.
Zum Formen der Antwort werden folgende Parameter verwendet:
selectgibt an, welche Felder in der Antwort zurückgegeben werden sollen. Nur die im Index als abrufbar (retrievable) markierten Felder können in einer SELECT-Anweisung verwendet werden.topgibt die angegebene Anzahl der am besten übereinstimmenden Dokumente zurück. In diesem Beispiel werden nur 10 Treffer zurückgegeben. Sie können „Zurück zum Seitenanfang“ und „Überspringen“ verwenden (nicht dargestellt), um die Ergebnisse seitenweise auszugeben.countgibt Aufschluss darüber, wie viele Dokumente im gesamten Index insgesamt übereinstimmen. Diese Zahl kann größer als die Zahl der zurückgegebenen Dokumente sein.orderbywird verwendet, wenn Sie die Ergebnisse nach einem Wert sortieren möchten, etwa nach einer Bewertung oder einem Standort. Andernfalls ist das Standardverhalten, das Relevanzergebnis zur Bewertung von Ergebnissen zu verwenden. Ein Feld muss per Attribut als sortierbar gekennzeichnet sein, damit es sich für diesen Parameter eignet.
Auswählen eines Clients
Für frühe Entwicklungs- und Proof of Concept-Tests starten Sie mit dem Azure-Portal oder einem REST-Client. Diese Ansätze sind interaktiv, nützlich für gezielte Tests und helfen Ihnen, die Auswirkungen verschiedener Eigenschaften zu bewerten, ohne Code schreiben zu müssen.
Verwenden Sie zum Aufrufen der Suche aus einer App die Azure.Document.Search-Clientbibliotheken in den Azure-SDKs für .NET, Java, JavaScript und Python.
Wenn Sie im Azure-Portal einen Index öffnen, können Sie den Suchexplorer zusammen mit der JSON-Indexdefinition auf parallelen Registerkarten nutzen, um einfacher auf Feldattribute zugreifen zu können. Überprüfen Sie die Tabelle Felder, um zu sehen, welche durchsuchbar, sortierbar, filterbar und facettierbar beim Testen von Abfragen sind.
Melden Sie sich beim Azure-Portal an, und finden Sie Ihren Suchdienst.
Wählen Sie in Ihrem Dienst Indizes und dann einen Index aus.
Ein Index wird in der Registerkarte Such-Explorer geöffnet, sodass Sie sofort abfragen können. Wechseln Sie zur JSON-Ansicht , um die Abfragesyntax anzugeben.
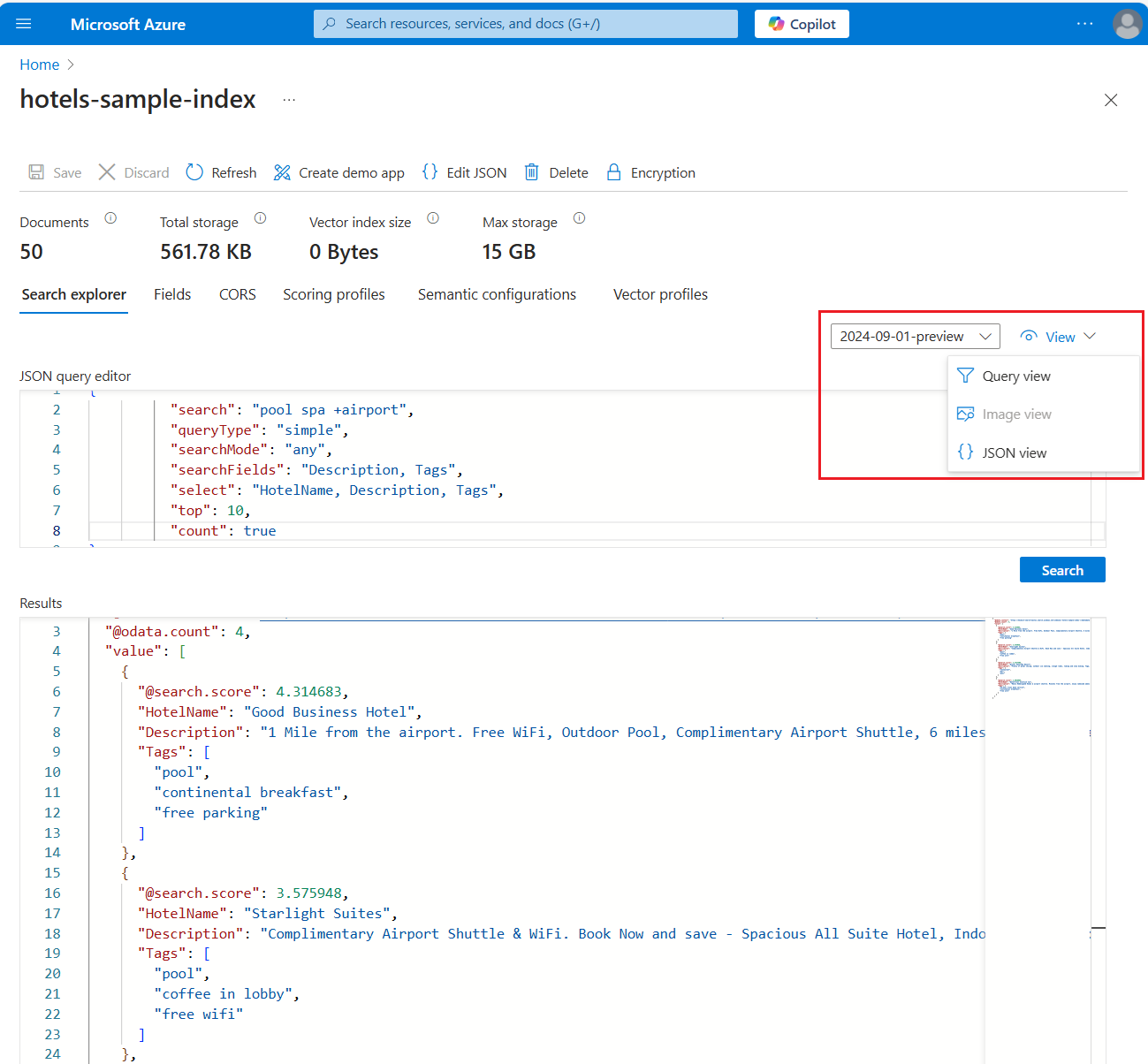
Hier ist ein Volltext-Suchabfrageausdruck, der für den Hotels-Beispielindex funktioniert:
{ "search": "pool spa +airport", "queryType": "simple", "searchMode": "any", "searchFields": "Description, Tags", "select": "HotelName, Description, Tags", "top": 10, "count": true }Der folgende Screenshot veranschaulicht die Abfrage und Antwort:
Auswählen eines Abfragetyps: Einfach | vollständig
Wenn Ihre Abfrage eine Volltextsuche ist, wird ein Abfrageparser verwendet, um jeden Text zu verarbeiten, der als Suchbegriffe und -Ausdrücke übergeben wird. Azure KI Search bietet zwei Abfrageparser.
Der einfache Parser versteht die einfache Abfragesyntax. Dieser Parser wird standardmäßig verwendet, da er bei Abfragen von Freiformtext eine hohe Geschwindigkeit und Effizienz bietet. Die Syntax unterstützt gängige Suchoperatoren (UND, ODER, NICHT) für die Suche nach Begriffen und Ausdrücken und die Präfix (
*)-Suche, (wie insea*für „Seattle“ und „Seaside“). Ganz allgemein wird empfohlen, zuerst den einfachen Parser auszuprobieren und nur dann zum vollständigen Parser zu wechseln, wenn Anwendungsanforderungen leistungsfähigere Abfragen erfordern.Die vollständige Lucene-Abfragesyntax, die beim Hinzufügen von
queryType=fullzur Anforderung aktiviert wird, basiert auf dem Apache Lucene-Parser.
Vollständige Syntax und einfache Syntax stimmen darin überein, dass beide dieselben Präfix- und booleschen Vorgänge unterstützen, aber die vollständigen Syntax stellt mehr Operatoren zur Verfügung. In der vollständigen Syntax gibt es mehr Operatoren für boolesche Ausdrücke und mehr Operatoren für erweiterte Abfragen, wie z. B. die Fuzzysuche, die Platzhaltersuche, die Näherungssuche und reguläre Ausdrücke.
Auswählen der Abfragemethoden
Die Suche ist im Grunde genommen ein vom Benutzer gesteuerter Vorgang, bei dem Begriffe oder Ausdrücke aus einem Suchfeld oder von Klickereignissen auf einer Seite gesammelt werden. In der folgenden Tabelle werden die Verfahren zusammengefasst, mit denen Sie Benutzereingaben erfassen können. Außerdem sind die erwarteten Suchvorgänge aufgeführt.
| Eingabe | Erfahrung |
|---|---|
| Suche | Benutzer geben die Begriffe oder Ausdrücke (mit oder ohne Operatoren) in ein Suchfeld ein und wählen Suchen aus, um die Anforderung zu senden. Die Suche kann mit Filtern für dieselbe Anforderung, jedoch nicht mit AutoVervollständigen oder Vorschlägen verwendet werden. |
| AutoVervollständigen | Benutzer geben einige Zeichen ein, und nach der Eingabe jedes neuen Zeichens werden Abfragen initiiert. Die Antwort ist eine vollständige Zeichenfolge aus dem Index. Wenn die bereitgestellte Zeichenfolge gültig ist, wählen die Benutzer Suchen aus, um diese Abfrage an den Dienst zu senden. |
| Vorschläge | Wie beim AutoVervollständigen werden während der Eingabe einiger Zeichen durch Benutzer inkrementelle Abfragen generiert. Die Antwort ist eine Dropdownliste mit übereinstimmenden Dokumenten, die in der Regel durch einige eindeutige oder beschreibende Felder dargestellt werden. Wenn eine der Auswahlen gültig ist, wählen die Benutzer ein aus, und das übereinstimmende Dokument wird zurückgegeben. |
| Facettennavigation | Auf einer Seite werden klickbare Navigationslinks oder „Brotkrümel“ (Breadcrumbs) angezeigt, die den Suchbereich eingrenzen. Die Struktur der Facettennavigationsstruktur wird dynamisch basierend auf einer anfänglichen Abfrage gebildet. Mit search=* wird z. B. eine Facettennavigationsstruktur aufgefüllt, die alle möglichen Kategorien umfasst. Die Struktur bei einer Facettennavigation wird aus einer Abfrageantwort erstellt, sie dient aber auch zum Ausdrücken der nächsten Abfrage. In der REST-API-Referenz ist facets als Abfrageparameter eines Vorgangs „Dokumente suchen“ dokumentiert, er kann jedoch auch ohne den search-Parameter verwendet werden. |
| Filtermethode | Mithilfe von Filtern können Sie die Ergebnisse von Facetten eingrenzen. Sie können auch einen Filter im Hintergrund der Seite implementieren, um die Seite z. B. mit sprachspezifischen Feldern zu initialisieren. In der REST-API-Referenz ist $filter als Abfrageparameter eines Vorgangs „Dokumente suchen“ dokumentiert, er kann jedoch auch ohne den search-Parameter verwendet werden. |
Auswirkungen von Feldattributen auf Abfragen
Wenn Sie mit Abfragetypen und -komposition vertraut sind, erinnern Sie sich möglicherweise daran, dass die Parameter in der Abfrageanforderung von Feldattributen in einem Index abhängen. Beispielsweise können nur Felder, die als durchsuchbar und abrufbar gekennzeichnet sind, in Abfragen und Suchergebnissen verwendet werden. Wenn Sie die Parameter search, filter und orderby in Ihrer Anforderung festlegen, sollten Sie Attribute überprüfen, um unerwartete Ergebnisse zu vermeiden.
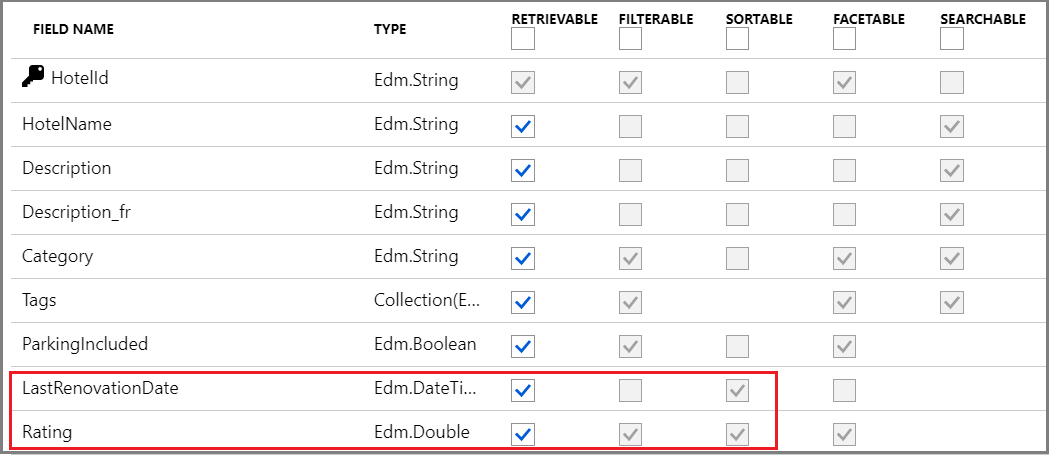
Im folgenden Screenshot des Hotel-Beispielindexes sind nur die letzten beiden Felder LastRenovationDate und Rating sortierbar, eine Voraussetzung für die Verwendung in einer Nur-"$orderby"-Klausel.
Informationen zu Feldattributdefinitionen finden Sie unter Index erstellen (REST-API).
Auswirkungen von Token auf Abfragen
Während der Indizierung verwendet die Suchmaschine ein Textanalysetool für Zeichenfolgen, um die Wahrscheinlichkeit zu maximieren, zur Abfragezeit Übereinstimmungen zu finden. Zeichenfolgen sind mindestens kleingeschrieben. Sie können aber abhängig vom Analysetool auch eine Lemmatisierung und Stoppwortentfernung durchlaufen. Größere Zeichenfolgen oder zusammengesetzte Wörter werden in der Regel an Leerzeichen, Bindestrichen oder Gedankenstrichen aufgeteilt und als separate Token indiziert.
Der entscheidende Punkt ist, dass das, was Sie denken, was Ihr Index enthält, und das, was er tatsächlich enthält, unterschiedlich sein können. Wenn Ihre Abfragen nicht die erwarteten Ergebnisse zurückgeben, können Sie die vom Analysetool erstellten Token mit Text analysieren (REST-API) überprüfen. Weitere Informationen zur Tokenisierung und zu den Auswirkungen auf Abfragen finden Sie unter Suche nach Teilbegriffen und Mustern mit Sonderzeichen.
Zugehöriger Inhalt
Nachdem Sie nun ein besseres Verständnis von der Funktionsweise von Abfrageanforderungen haben, können Sie in den folgenden Schnellstarts praktische Erfahrungen sammeln.