SAP HANA-Infrastrukturkonfigurationen und -Vorgänge in Azure
Dieses Dokument enthält Anleitungen für die Konfiguration der Azure-Infrastruktur und SAP HANA-Betriebssystemen, die auf nativen virtuellen Azure-Computern bereitgestellt werden. Das Dokument enthält auch Informationen zur Konfiguration für die horizontale SAP HANA-Skalierung für die M128s-VM-SKU. Dieses Dokument ist nicht als Ersatz für die SAP-Standarddokumentation gedacht, zu der folgende Inhalte gehören:
Voraussetzungen
Um dieses Handbuch zu verwenden, benötigen Sie grundlegende Kenntnisse der folgenden Azure-Komponenten:
Weiterführende Informationen zu SAP NetWeaver und zu anderen SAP-Komponenten in Azure finden Sie im Abschnitt SAP in Azure in der Azure-Dokumentation.
Grundlegende Überlegungen zum Setup
In den folgenden Abschnitten werden grundlegende Einrichtungsüberlegungen für die Bereitstellung von SAP HANA-Systemen auf virtuellen Azure-Computern beschrieben.
Herstellen von Verbindungen mit virtuellen Azure-Computern
Wie im Planungshandbuch für virtuelle Azure-Computer dokumentiert, gibt es zwei grundlegende Methoden zum Herstellen einer Verbindung mit virtuellen Azure-Computern:
- Herstellen einer Verbindung über das Internet und öffentliche Endpunkte auf einer Jump-VM oder auf dem virtuellen Computer, auf dem SAP HANA ausgeführt wird
- Herstellen einer Verbindung über eine VPN oder Azure ExpressRoute
Site-to-Site-Konnektivität über VPN oder ExpressRoute ist für Produktionsszenarien erforderlich. Dieser Typ von Verbindung ist auch für Nicht-Produktionsszenarien erforderlich, die in Produktionsszenarien übertragen, in denen SAP-Software verwendet wird. Die folgende Abbildung zeigt ein Beispiel zu standortübergreifender Konnektivität:
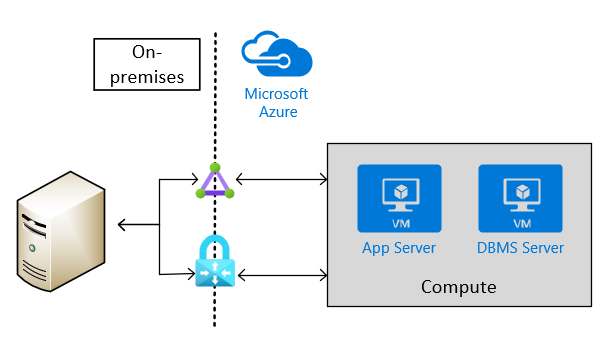
Auswählen der Arten von virtuellen Azure-Computern
SAP listet auf , welche Azure VM-Typen für Produktionsszenarien verwendet werden können. Für Nicht-Produktionsszenarien ist eine größere Auswahl von virtuellen Azure-Computern verfügbar.
Hinweis
Für Nicht-Produktionsszenarien sollten Sie die Arten von virtuellen Computern verwenden, die im SAP-Hinweis 1928533 aufgeführt sind. Überprüfen Sie zur Verwendung von Azure-VMs für Produktionsszenarien die von SAP veröffentlichte Liste zertifizierter IaaS-Plattformen auf für SAP HANA zertifizierte VMs.
Stellen Sie die virtuellen Computer in Azure bereit, indem Sie Folgendes verwenden:
- Das Azure-Portal
- Azure PowerShell-Cmdlets
- Die Azure-Befehlszeilenschnittstelle
Wichtig
Um M208xx_v2-VMs verwenden zu können, müssen Sie Ihr Linux-Image sorgfältig auswählen. Weitere Informationen finden Sie unter Arbeitsspeicheroptimierte VM-Größen.
Speicherkonfiguration für SAP HANA
Informationen zu den mit SAP HANA verwendeten Speicherkonfigurationen und -typen finden Sie im Dokument SAP HANA Azure virtual machine storage configurations (SAP HANA: Speicherkonfigurationen für virtuelle Azure-Computer).
Einrichten von virtuellen Azure-Netzwerken
Wenn Sie Site-to-Site-Konnektivität mit Azure über VPN oder ExpressRoute haben, müssen Sie mindestens ein virtuelles Azure-Netzwerk haben, das über ein virtuelles Gateway mit der VPN- oder ExpressRoute-Verbindung verbunden ist. Bei einfachen Bereitstellungen kann das virtuelle Gateway in einem Subnetz des virtuellen Azure-Netzwerks (VNet) bereitgestellt werden, das auch die SAP HANA-Instanzen hostet. Um SAP HANA zu installieren, erstellen Sie zwei weitere Subnetze innerhalb des virtuellen Azure-Netzwerks. In einem Subnetz werden die virtuellen Computer gehostet, auf denen die SAP HANA-Instanzen ausgeführt werden. Im anderen Subnetz werden virtuelle Jumpbox- oder Verwaltungscomputer ausgeführt, auf denen SAP HANA Studio, andere Verwaltungssoftware oder Ihre Anwendungssoftware gehostet wird.
Wichtig
Aus Funktionalitätsgründen und – was noch wichtiger ist – aus Leistungsgründen wird die Konfiguration von virtuellen Azure-Netzwerkgeräten im Kommunikationspfad zwischen der SAP-Anwendung und der DBMS-Schicht eines SAP NetWeaver-, Hybris- oder S/4HANA-basierten SAP-Systems nicht unterstützt. Die Kommunikation zwischen der SAP-Anwendungsschicht und der DBMS-Schicht muss direkt erfolgen. Die Einschränkung gilt nicht für Azure ASG und NSG-Regeln, solange diese ASG- und NSG-Regeln eine direkte Kommunikation ermöglichen. Weitere Szenarien, in denen virtuelle Netzwerkgeräte nicht unterstützt werden, betreffen Kommunikationspfade zwischen virtuellen Azure-Computern, die Linux Pacemaker-Clusterknoten und SBD-Geräte darstellen. Dies ist unter Hochverfügbarkeit für SAP NetWeaver auf Azure-VMs auf dem SUSE Linux Enterprise Server for SAP Applications beschrieben. Ein weiterer Fall sind Kommunikationspfade zwischen virtuellen Azure-Computern und Windows Server SOFS, die wie unter Gruppieren einer SAP ASCS/SCS-Instanz in einem Windows-Failovercluster per Dateifreigabe in Azure beschrieben eingerichtet wurden. Mit virtuellen Netzwerkgeräten in Kommunikationspfaden kann die Netzwerklatenz zwischen zwei Kommunikationspartnern auf einfache Weise verdoppelt werden. Außerdem kann der Durchsatz in kritischen Pfaden zwischen der SAP-Anwendungsschicht und der DBMS-Schicht eingeschränkt werden. In einigen Kundenszenarien kann es aufgrund von virtuellen Netzwerkgeräten für Pacemaker Linux-Cluster zu Ausfällen kommen, bei denen die Kommunikation zwischen den Linux Pacemaker-Clusterknoten und dem SBD-Gerät über ein virtuelles Netzwerkgerät erfolgen muss.
Wichtig
Ein weiteres NICHT unterstütztes Design ist die Aufteilung der SAP-Anwendungsschicht und der DBMS-Schicht in verschiedene virtuelle Azure-Netzwerke, für die kein Peering konfiguriert ist. Es wird empfohlen, die SAP-Anwendungsschicht und die DBMS-Schicht durch Subnetze innerhalb eines virtuellen Azure-Netzwerks zu trennen, statt verschiedene virtuelle Azure-Netzwerke zu verwenden. Wenn Sie sich dafür entscheiden, der Empfehlung nicht zu folgen und stattdessen die beiden Schichten in verschiedene virtuelle Netzwerke aufzuteilen, muss für die beiden virtuellen Netzwerke ein Peering konfiguriert sein. Beachten Sie, dass für den Netzwerkdatenverkehr zwischen zwei virtuellen Azure-Netzwerken mit Peering Übertragungskosten anfallen. Durch das riesige Datenvolumen im Terabytebereich, das zwischen der SAP-Anwendungsschicht und der DBMS-Schicht ausgetauscht wird, können erhebliche Kosten anfallen, wenn die SAP-Anwendungsschicht und die DBMS-Schicht in zwei virtuellen Azure-Netzwerken voneinander getrennt werden.
Wenn Sie Jumpbox- oder Verwaltungs-VMs in einem separaten Subnetz bereitgestellt haben, können Sie mehrere virtuelle Netzwerkschnittstellenkarten (vNICs) für den virtuellen HANA-Computer definieren, wobei jede vNIC einem anderen Subnetz zugewiesen ist. Mit der Möglichkeit, mehrere vNICs zu haben, können Sie bei Bedarf eine Trennung des Netzwerkdatenverkehrs einrichten. Beispielsweise kann der Client-Datenverkehr über die primäre vNIC und der Verwaltungsdatenverkehr über eine zweite vNIC weitergeleitet werden.
Sie weisen auch statische private IP-Adressen zu, die für beide virtuellen NICs bereitgestellt werden.
Hinweis
Sie sollten einzelnen virtuellen Netzwerkkarten statische IP-Adressen über Azure-Tools zuweisen. Virtuellen Netzwerkkarten sollten nicht innerhalb des Gastbetriebssystems statische IP-Adressen zugewiesen werden. Einige Azure-Dienste wie der Azure Backup-Dienst basieren darauf, dass mindestens die primäre virtuelle Netzwerkkarte auf DHCP festgelegt ist und nicht auf statische IP-Adressen. Weitere Informationen finden Sie auch im Dokument zur Problembehandlung bei der Sicherung virtueller Azure-Computer. Wenn Sie einer VM mehrere statische IP-Adressen zuweisen müssen, müssen Sie ihr auch mehrere virtuelle Netzwerkkarten zuweisen.
Für dauerhafte Bereitstellungen müssen Sie jedoch eine virtuelle Rechenzentrums-Netzwerkarchitektur in Azure erstellen. Bei dieser Architektur empfiehlt sich die Trennung des Azure-VNet-Gateway, das sich mit dem lokalen Netzwerk verbindet, in ein separates Azure VNet. Dieses separate VNet sollte den gesamten Datenverkehr hosten, der entweder ins lokale Netzwerk oder ins Internet geleitet wird. Dieser Ansatz ermöglicht es Ihnen, Software zur Überprüfung und Protokollierung des Datenverkehrs, der in das virtuelle Rechenzentrum in Azure einfließt, in diesem separaten Hub-VNet bereitzustellen. Sie haben also ein VNet, das sämtliche Software und Konfigurationen bezüglich des ein- und ausgehenden Datenverkehrs zu Ihrer Azure-Bereitstellung hostet.
Die Artikel Virtuelles Rechenzentrum in Microsoft Azure: Eine Netzwerkperspektive und Virtuelles Azure-Rechenzentrum und die Steuerungsebene für Unternehmen enthalten weitere Informationen zum virtuellen Rechenzentrumsansatz und dem dazugehörigen Azure-VNet-Design.
Hinweis
Für den Datenverkehr zwischen dem VNet-Hub und dem Spoke-VNet mit Azure-VNet-Peering fallen zusätzliche Kosten an. Basierend auf diesen Kosten müssen Sie möglicherweise Kompromisse zwischen dem Betrieb eines strengen Hub-Spoke-Netzwerkdesigns und dem Betrieb mehrerer Azure-ExpressRoute-Gateways eingehen, die Sie mit „Spokes“ verbinden, um VNet-Peering zu umgehen. Für Azure-ExpressRoute-Gateways fallen jedoch ebenfalls zusätzliche Kosten an. Darüber hinaus können zusätzliche Kosten für Software von Drittanbietern anfallen, die Sie für die Protokollierung, Überprüfung und Überwachung des Datenverkehrs verwenden. Abhängig von den Kosten für den Datenaustausch über VNet-Peering auf der einen Seite und den Kosten, die durch zusätzliche Azure-ExpressRoute-Gateways und zusätzliche Softwarelizenzen entstehen, auf der anderen, können Sie sich für eine Mikrosegmentierung innerhalb eines VNet entscheiden, indem Sie Subnetze als Isolationseinheit anstelle von VNets verwenden.
Einen Überblick über die verschiedenen Methoden zum Zuweisen von IP-Adressen finden Sie unter IP-Adresstypen und Zuordnungsmethoden in Azure.
Für VMs mit SAP HANA sollten Sie mit zugewiesenen statischen IP-Adressen arbeiten. Der Grund ist, dass einige Konfigurationsattribute für HANA IP-Adressen referenzieren.
Azure-Netzwerksicherheitsgruppen (NSGs) werden verwendet, um Datenverkehr zu leiten, der an die SAP HANA-Instanz oder die Jumpbox weitergeleitet wird. Die Netzwerksicherheitsgruppen und Anwendungssicherheitsgruppen sind mit dem SAP HANA-Subnetz und dem Verwaltungssubnetz verknüpft.
Um SAP HANA in Azure ohne Site-to-Site-Verbindung bereitzustellen, müssen Sie die SAP HANA-Instanz dennoch vor dem öffentlichen Internet schützen und hinter einem Weiterleitungsproxy verstecken. In diesem einfachen Szenario werden für die Bereitstellung in Azure integrierte DNS-Dienste verwendet, um Hostnamen aufzulösen. In einer komplexeren Bereitstellung, in der öffentlich zugängliche IP-Adressen verwendet werden, sind die in Azure integrierten DNS-Dienste besonders wichtig. Verwenden Sie Azure-NSGs und Azure-NVAs, um das Routing vom Internet in Ihre Azure-VNet-Architektur in Azure zu steuern und zu überwachen. Die folgende Abbildung zeigt ein allgemeines Schema für die Bereitstellung von SAP HANA ohne eine Site-to-Site-Verbindung in einer Hub-Spoke-VNet-Architektur:
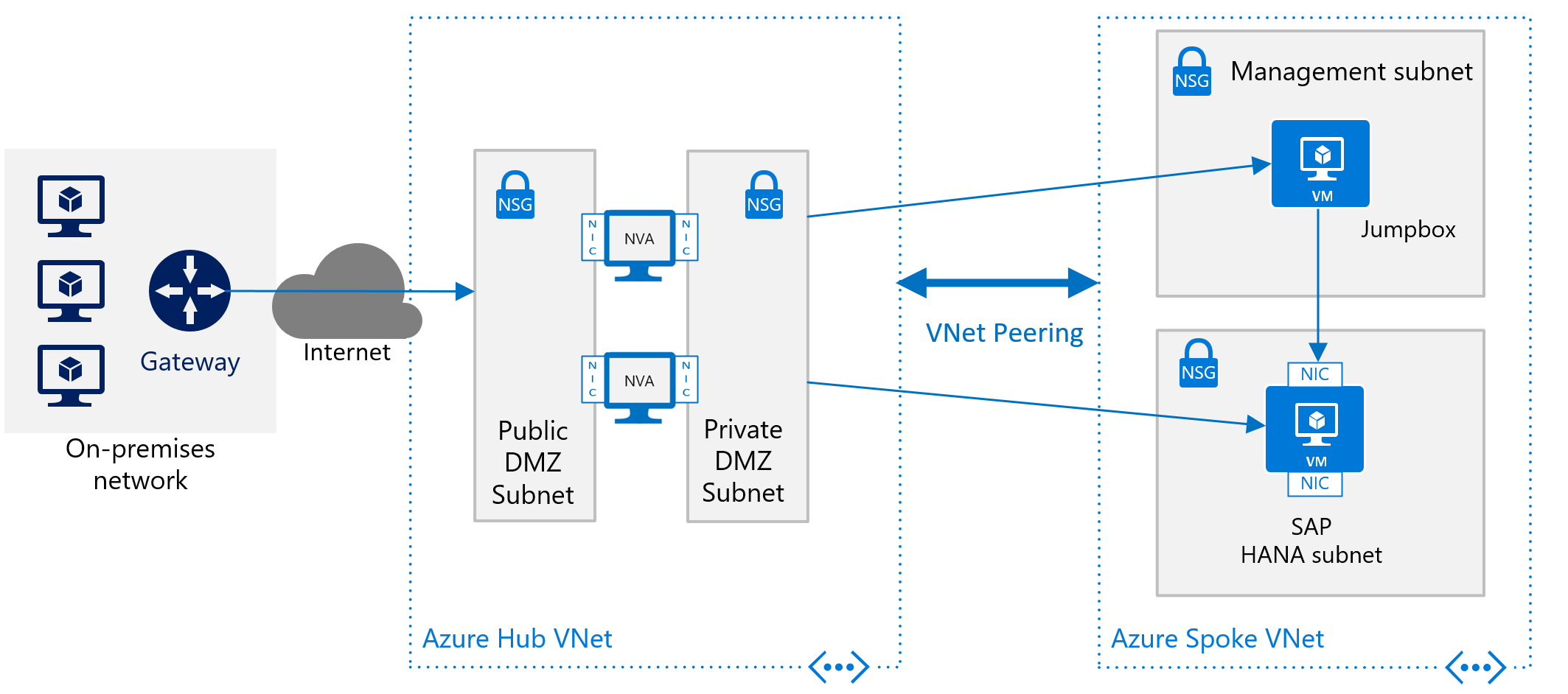
Eine weitere Beschreibung zur Verwendung von Azure-NVAs zum Steuern und Überwachen des Zugriffs aus dem Internet ohne die Hub-and-Spoke-VNet-Architektur finden Sie im Artikel Bereitstellen hochverfügbarer virtueller Netzwerkgeräte.
Optionen für die Zeitquelle auf Azure-VMs
SAP HANA erfordert zuverlässige und genaue Zeitinformationen, um optimal zu funktionieren. Normalerweise verwendeten Azure-VMs, die auf Azure-Hypervisor ausgeführt werden, nur die Hyper-V-TSC-Seite als Standardzeitquelle. Technologische Fortschritte bei Hardware, Hostbetriebssystem und Linux-Gastbetriebssystem-Kerneln ermöglichten es, den invarianten Zeitstempelindikator als Zeitquelle für einige Azure-VM-SKUs bereitzustellen.
Die Hyper-V-TSC-Seite (hyperv_clocksource_tsc_page) wird auf allen Azure-VMs als Zeitquelle unterstützt.
Wenn die zugrunde liegende Hardware, Hypervisor und die Linux-Gastbetriebssystem-Kernel den invarianten Zeitstempelindikator unterstützen, wird tsc als verfügbare und unterstützte Zeitquelle im Gastbetriebssystem auf Azure-VMs angeboten.
Konfigurieren der Azure-Infrastruktur für die horizontale SAP HANA-Skalierung
Überprüfen Sie das SAP HANA-Hardwareverzeichnis, um die Azure-VM-Typen zu ermitteln, die für horizontales Hochskalieren (OLAP oder S/4HANA) zertifiziert sind. Ein Häkchen in der Spalte „Clustering“ weist auf Unterstützung für horizontale Skalierung hin. Der Anwendungstyp gibt an, ob horizontales Hochskalieren von OLAP oder S/4HANA unterstützt wird. Einzelheiten zu den für horizontale Skalierung zertifizierten Knoten finden Sie im Eintrag für eine bestimmte VM-SKU, die im SAP HANA-Hardwareverzeichnis aufgeführt ist.
Informationen zu den Betriebssystem-Mindestversionen für die Bereitstellung von Konfigurationen mit horizontaler Skalierung finden Sie in den Details der Einträge in der jeweiligen VM-SKU, die im SAP HANA-Hardwareverzeichnis aufgeführt wird. Bei einer OLAP-Konfiguration für horizontale Skalierung mit n Knoten fungiert ein Knoten als primärer Knoten. Die anderen Knoten bis zum Grenzwert der Zertifizierung fungieren als Workerknoten. Zusätzliche Standbyknoten tragen nicht zur Anzahl der zertifizierten Knoten bei.
Hinweis
Azure-VM-Bereitstellungen mit horizontaler Skalierung von SAP HANA mit Standbyknoten sind nur mithilfe des Azure NetApp Files-Speichers möglich. Kein anderer für SAP HANA zertifizierter Azure-Speicher ermöglicht die Konfiguration von SAP HANA-Standbyknoten.
Für „/hana/shared“ wird die Verwendung von Azure NetApp Files oder Azure Files empfohlen.
Ein typisches grundlegendes Design für einen einzelnen Knoten in einer Konfiguration für die horizontale Skalierung mit /hana/shared, das in Azure NetApp Files bereitgestellt wird, sieht wie folgt aus:
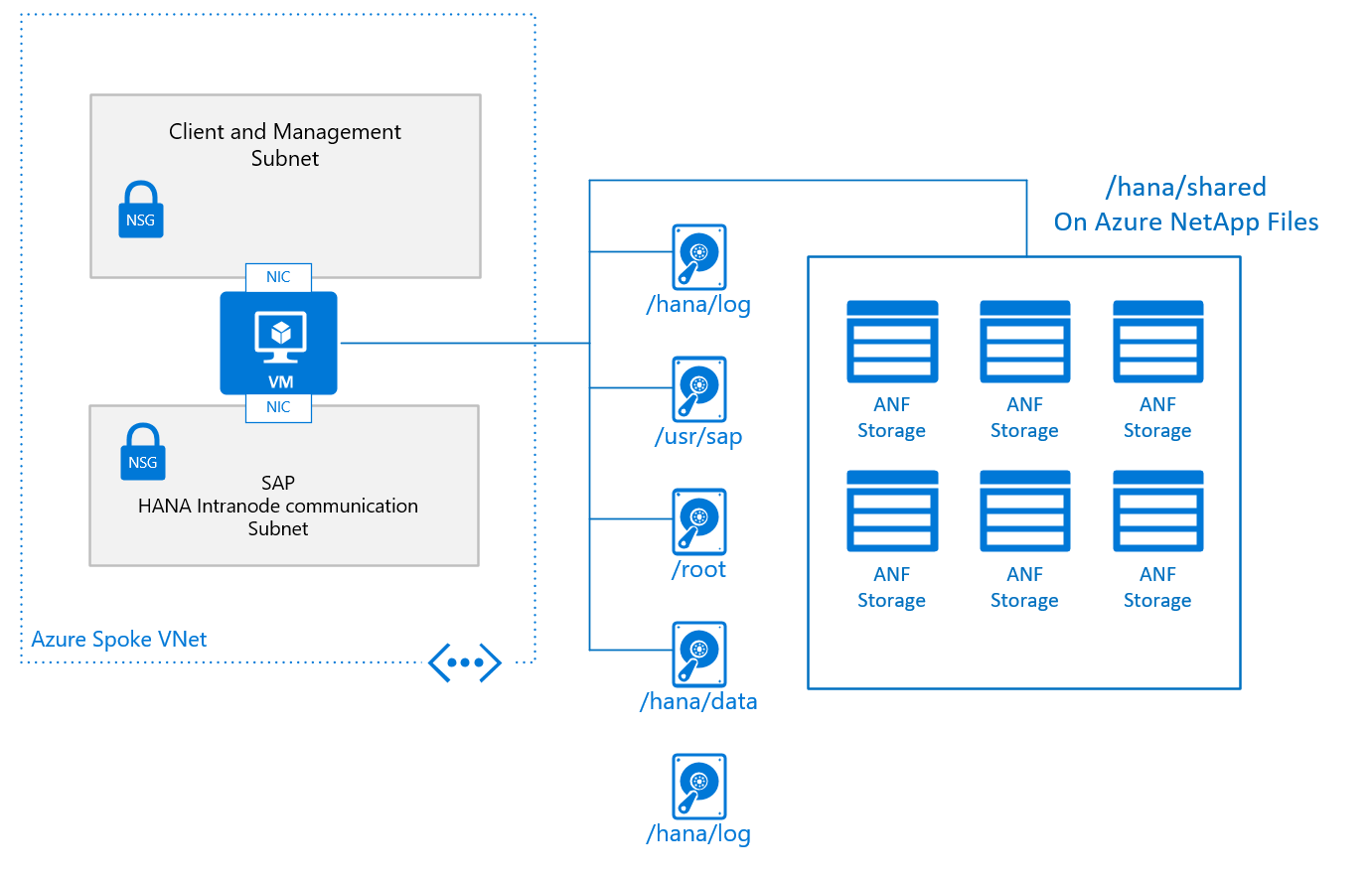
Die grundlegende Konfiguration von einem VM-Knoten für die horizontale SAP HANA-Skalierung sieht wie folgt aus:
- Für /hana/shared verwenden Sie den nativen NFS-Dienst, der über Azure NetApp Files oder Azure Files bereitgestellt wird.
- Alle anderen Datenträgervolumes werden nicht für die verschiedenen Knoten freigegeben und basieren nicht auf NFS. Installationskonfigurationen und Schritte für HANA-Installationen mit horizontaler Skalierung mit nicht freigegebenen /hana/data- und /hana/log-Volumes finden Sie im weiteren Verlauf dieses Dokuments. Informationen zu für HANA zertifiziertem Speicher, der verwendet werden kann, finden Sie im Artikel SAP HANA: Speicherkonfigurationen für virtuelle Azure-Computer.
Informationen zum Anpassen der Größe der Volumes oder Datenträger finden Sie im Dokument SAP HANA: TDI-Speicheranforderungen. Es enthält Angaben zur erforderlichen Größe abhängig von der Anzahl der Workerknoten. Das Dokument enthält eine Formel, die Sie anwenden müssen, um die erforderliche Kapazität des Volumes zu erhalten.
Die anderen Designkriterien, die in der Grafik der Einzelknotenkonfiguration für eine SAP HANA-VM mit horizontaler Skalierung dargestellt werden, beziehen sich auf das VNET (besser gesagt: die Subnetzkonfiguration). SAP empfiehlt dringend eine Trennung des client-/anwendungsbezogenen Datenverkehrs von der Kommunikation zwischen den HANA-Knoten. Wie in der Grafik dargestellt, können Sie dafür zwei verschiedene VNICs an die VM anfügen. Beide NICs befinden sich in unterschiedlichen Subnetzen und haben zwei verschiedene IP-Adressen. Anschließend steuern Sie den Datenverkehr mit Routingregeln über NSGs oder benutzerdefinierte Routen.
Vor allem in Azure gibt es keine Möglichkeiten und Methoden, um die Dienstqualität und Kontingente für bestimmte vNICs durchzusetzen. Daher bietet die Trennung der client- und anwendungsseitigen Kommunikation und der Kommunikation zwischen Knoten keine Möglichkeit, einen der beiden Datenverkehrsströme zu priorisieren. Stattdessen bleibt die Trennung eine Sicherheitsmaßnahme beim Abschirmen der knotenübergreifenden Kommunikation bei horizontalen Skalierungen.
Hinweis
SAP empfiehlt, den Netzwerkverkehr auf der Client-/Anwendungsseite und den knotenübergreifenden Datenverkehr zu trennen, wie in diesem Dokument beschrieben. Daher wird die Implementierung einer Architektur empfohlen, wie sie in den letzten Grafiken dargestellt wird. Wenden Sie sich auch an Ihr Sicherheits- und Complianceteam, um Anforderungen zu ermitteln, die von der Empfehlung abweichen.
Aus Netzwerksicht sieht die minimal erforderliche Netzwerkarchitektur so aus:
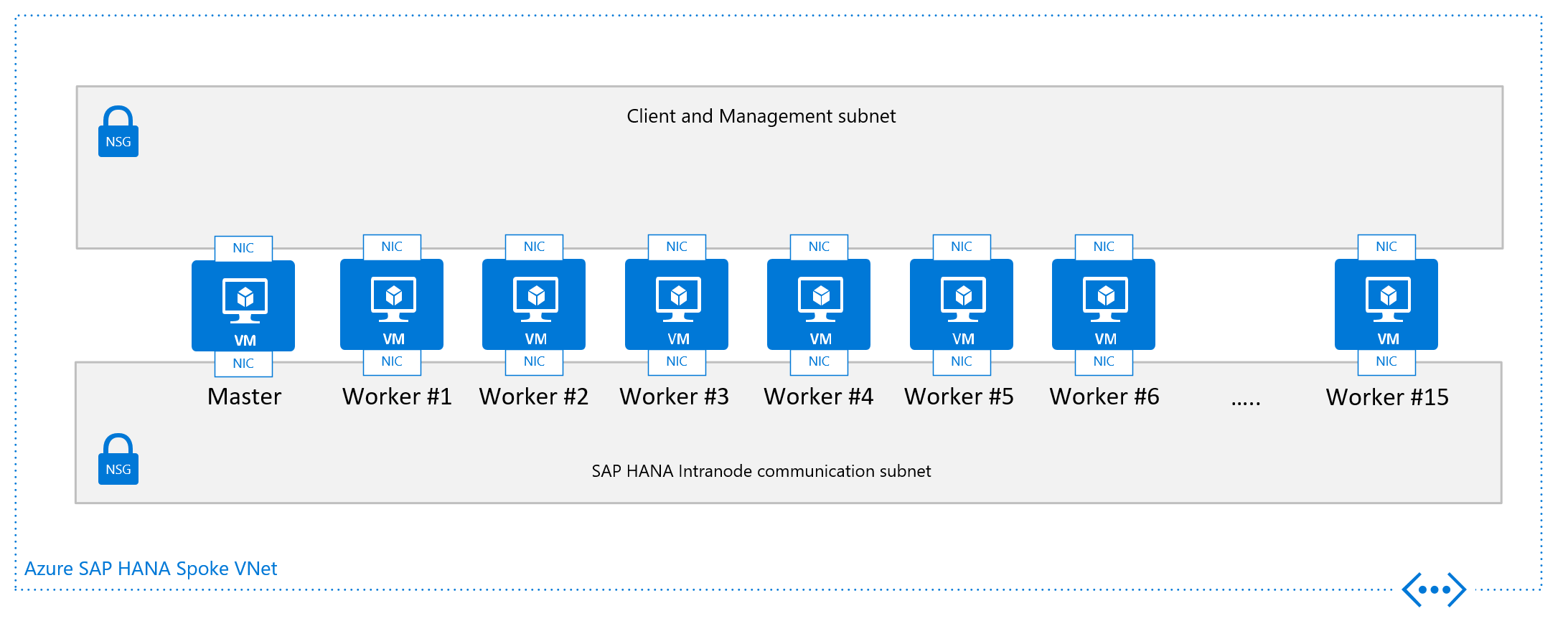
Installieren der horizontalen SAP HANA-Skalierung in Azure
Zum Installieren einer horizontalen SAP-Konfiguration führen Sie die folgenden Schritte aus:
- Bereitstellen einer neuen Azure-VNET-Architektur oder Anpassen einer bestehenden
- Bereitstellen der neuen VMs mit Azure Managed Storage Premium, Ultra Disk-Volumes und/oder NFS-Volumes auf der Grundlage von ANF
-
- Anpassen des Netzwerkroutings, um beispielsweise sicherzustellen, dass die knotenübergreifende Kommunikation zwischen virtuellen Computer nicht durch NVAs geleitet wird.
- Installieren des primären SAP HANA-Knotens
- Anpassen der Konfigurationsparameter des primären SAP HANA-Knotens
- Fortsetzen der Installation der SAP HANA-Workerknoten
Installation von SAP HANA mit horizontaler Skalierung
Wenn Ihre Azure VM-Infrastruktur bereitgestellt ist und alle anderen Vorbereitungen getroffen sind, müssen Sie die horizontale SAP HANA-Skalierung in diesen Schritten installieren:
- Installieren des primären SAP HANA-Knotens gemäß der SAP-Dokumentation
- Wenn Sie Azure Premium Storage oder Ultra Disk Storage mit nicht gemeinsam genutzten Datenträgern von
/hana/dataund/hana/logverwenden, fügen Sie den Parameterbasepath_shared = nozur Dateiglobal.inihinzu. Durch diesen Parameter kann SAP HANA mit horizontaler Skalierung ausgeführt werden, ohne die Volumes/hana/dataund/hana/logzwischen den Knoten freizugeben. Details finden Sie im SAP-Hinweis #2080991. Wenn Sie NFS-Volumes auf der Grundlage von ANF für /hana/data und /hana/log verwenden, müssen Sie diese Änderung nicht vornehmen. - Starten Sie die SAP HANA-Instanz neu, nachdem Sie den Parameter in der Datei „global.ini“ geändert haben.
- Fügen Sie weitere Workerknoten hinzu. Weitere Informationen finden Sie unter Hinzufügen von Hosts mit der Befehlszeilenschnittstelle. Geben Sie während oder nach der Installation das interne Netzwerk für die knotenübergreifende SAP HANA-Kommunikation an, z.B. das lokale hdblcm. Eine detaillierte Dokumentation finden Sie in SAP-Hinweis 2183363.
Informationen zum Einrichten eines SAP HANA-Systems für horizontale Skalierung mit einem Standbyknoten finden Sie in den Anweisungen zur SUSE Linux-Bereitstellung oder den Anweisungen zur Red Hat-Bereitstellung.
SAP HANA Dynamic Tiering 2.0 für Azure-VMs
Zusätzlich zu den SAP HANA-Zertifizierungen für virtuelle Azure-Computer der M-Serie wird SAP HANA Dynamic Tiering 2.0 auch in Microsoft Azure unterstützt. Weitere Informationen finden Sie in den Links zur Dokumentation zu DT 2.0. Es gibt keinen Unterschied beim Installieren oder Betreiben des Produkts. Sie können beispielsweise das SAP HANA-Cockpit in einer Azure-VM installieren. Es gibt jedoch für die offizielle Unterstützung auf Azure einige obligatorische Anforderungen, wie im folgenden Abschnitt beschrieben. In diesem Artikel wird die Abkürzung „DT 2.0“ anstelle des vollständigen Namens „Dynamic Tiering 2.0“ verwendet.
SAP HANA Dynamic Tiering 2.0 wird von SAP BW oder S4HANA nicht unterstützt. Hauptanwendungsfälle sind derzeit native HANA-Anwendungen.
Übersicht
Die folgende Abbildung stellt eine Übersicht der DT 2.0-Unterstützung in Microsoft Azure dar. Um der offiziellen Zertifizierung gerecht zu werden, muss eine Reihe von Anforderungen erfüllt werden:
- DT 2.0 muss auf einer dedizierten Azure-VM installiert sein. Eine Ausführung auf der gleichen VM, auf der SAP HANA ausgeführt wird, ist nicht möglich.
- SAP HANA- und DT 2.0-VMs müssen in demselben Azure-VNET bereitgestellt werden.
- Die SAP HANA- und DT 2.0-VMs müssen mit aktiviertem beschleunigtem Azure-Netzwerkbetrieb bereitgestellt werden.
- Der Speichertyp für die DT 2.0-VMs muss Azure Storage Premium sein.
- Mehrere Azure-Datenträger müssen der DT 2.0-VM angefügt werden.
- Ein Software-RAID/Stripesetvolume mit übergreifendem Azure-Datenträger-Striping muss erstellt werden (per LVM oder mdadm).
Weitere Details werden in den folgenden Abschnitten ausführlicher erläutert.
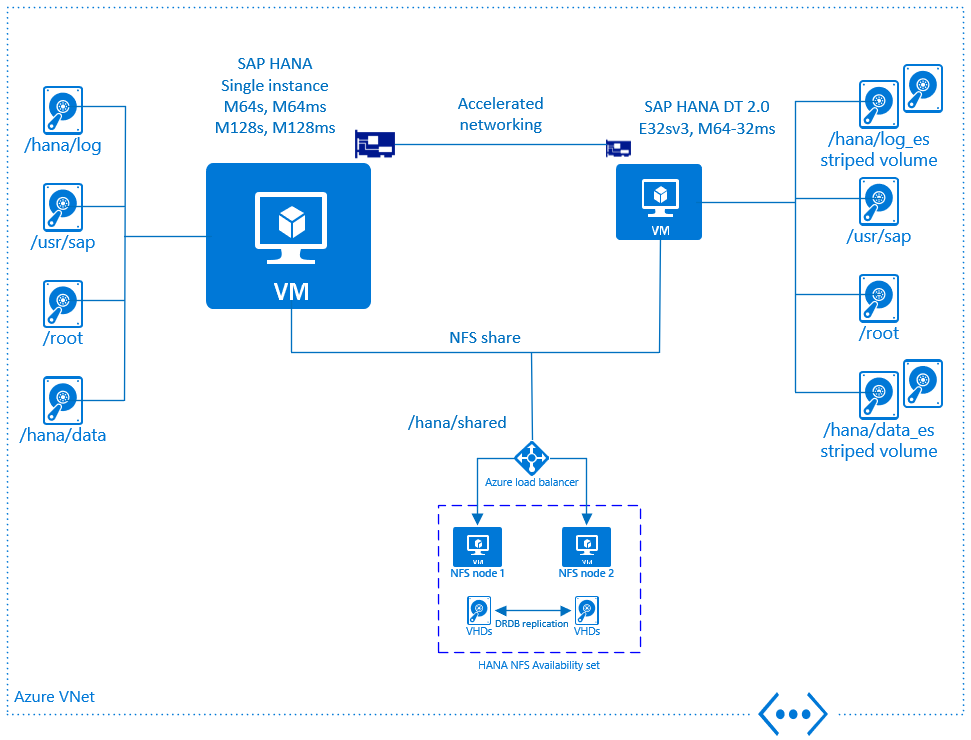
Dedizierte Azure-VM für SAP HANA DT 2.0
In Azure IaaS wird DT 2.0 nur auf einem dedizierten virtuellen Computer unterstützt. Es ist nicht zulässig, DT 2.0 auf der gleichen Azure-VM auszuführen, auf der die HANA-Instanz ausgeführt wird. Zu Beginn können zwei VM-Typen zum Ausführen von SAP HANA DT 2.0 verwendet werden:
- M64-32ms
- E32sv3
Weitere Informationen zur Beschreibung des VM-Typs finden Sie unter Azure-VM-Größen – Arbeitsspeicher.
Unter Berücksichtigung der Grundidee von DT 2.0 – Auslagern „warmer“ Daten, um Kosten zu sparen – ist es sinnvoll, entsprechende VM-Größen zu verwenden. Es gibt keine strenge Regel bezüglich möglicher Kombinationen. Dies hängt von der spezifischen Kundenworkload ab.
Empfohlene Konfigurationen:
| SAP HANA-VM-Typ | DT 2.0-VM-Typ |
|---|---|
| M128ms | M64-32ms |
| M128s | M64-32ms |
| M64ms | E32sv3 |
| M64s | E32sv3 |
Alle Kombinationen aus SAP HANA-zertifizierten VMs der M-Serie und unterstützten DT 2.0-VMs („M64-32ms“ und „E32sv3“) sind möglich.
Azure-Netzwerke und SAP HANA DT 2.0
Die Installation von DT 2.0 auf einem dedizierten virtuellen Computer erfordert einen Netzwerkdurchsatz von mindestens 10 Gb zwischen der DT-2.0- und der SAP HANA-VM. Aus diesem Grund müssen Sie alle virtuellen Computer im gleichen Azure-VNET platzieren und den beschleunigten Azure-Netzwerkbetrieb aktivieren.
Weitere Informationen zum beschleunigten Azure-Netzwerkbetrieb finden Sie unter Erstellen eines virtuellen Linux-Computers mit beschleunigtem Netzwerkbetrieb mithilfe der Azure CLI.
VM-Speicher für SAP HANA DT 2.0
Laut bewährten DT 2.0-Methoden sollte der Datenträger-E/A-Durchsatz pro physischem Kern mindestens 50 MB/s betragen.
Die Spezifikation für die beiden für DT 2.0 unterstützten Azure-VM-Typen gibt den maximalen Datenträger-E/A-Durchsatz für den virtuellen Computer wie folgt an:
- E32sv3: 768 MB/s (nicht zwischengespeichert), also ein Verhältnis von 48 MB/s pro physischem Kern
- M64-32ms: 1000 MB/s (nicht zwischengespeichert), also ein Verhältnis von 62,5 MB/s pro physischem Kern
Der DT 2.0-VM müssen mehrere Azure-Datenträger angefügt und ein Software-RAID (Striping) muss auf Betriebssystemebene erstellt werden, um den maximalen Datenträgerdurchsatz pro virtuellem Computer zu erzielen. Ein einzelner Azure-Datenträger kann nicht genügend Durchsatz bereitstellen, um die VM-Obergrenze in dieser Hinsicht zu erreichen. Azure Storage Premium ist zur Ausführung von DT 2.0 obligatorisch.
- Details zu den verfügbaren Azure-Datenträgertypen finden Sie auf der Seite Auswählen eines Datenträgertyps für virtuelle IaaS-Computer – verwaltete Datenträger.
- Details zum Erstellen von Software-RAID über mdadm finden Sie auf der Seite Konfigurieren von Software-RAID unter Linux.
- Ausführliche Informationen zum Konfigurieren von LVM zum Erstellen eines Stripesetvolumes für maximalen Durchsatz finden Sie auf der Seite Konfigurieren von LVM auf einem virtuellen Linux-Computer in Azure.
Je nach den Größenanforderungen stehen Ihnen verschiedene Optionen zum Erreichen des maximalen Durchsatzes eines virtuellen Computers zur Verfügung. Hier sind die möglichen Datenvolumedatenträger-Konfigurationen zum Erreichen der Obergrenze des VM-Durchsatzes für jeden DT 2.0-VM-Typ aufgeführt. Die VM E32sv3 sollte als Einstieg für kleinere Workloads angesehen werden. Falls sich herausstellen sollte, dass sie nicht schnell genug ist, muss sie möglicherweise durch die VM M64-32ms ersetzt werden. Weil die VM M64-32ms über viel Arbeitsspeicher verfügt, erreicht die E/A-Last möglicherweise insbesondere bei leseintensiven Workloads nicht das Limit. Aus diesem Grund können abhängig von der kundenspezifischen Workload weniger Datenträger im Stripeset ausreichend sein. Aus Sicherheitsgründen wurden jedoch die folgenden Datenträgerkonfigurationen ausgewählt, um den maximalen Durchsatz zu gewährleisten:
| VM-SKU | Datentr.-Konfig. 1 | Datentr.-Konfig. 2 | Datentr.-Konfig. 3 | Datentr.-Konfig. 4 | Datentr.-Konfig. 5 |
|---|---|---|---|---|---|
| M64-32ms | 4 × P50 -> 16 TB | 4 × P40 -> 8 TB | 5 × P30 -> 5 TB | 7 × P20 -> 3,5 TB | 8 × P15 -> 2 TB |
| E32sv3 | 3 × P50 -> 12 TB | 3 × P40 -> 6 TB | 4 × P30 -> 4 TB | 5 × P20 -> 2,5 TB | 6 × P15 -> 1,5 TB |
Vor allem bei leseintensiven Workloads könnte die Aktivierung des Azure-Hostcaches mit Schreibschutz – wie für die Datenvolumes von Datenbanksoftware empfohlen – die E/A-Leistung steigern. Für das Transaktionsprotokoll hingegen darf der Azure-Hostdatenträger-Cache nicht aktiviert sein.
In Bezug auf die Größe des Protokollvolumes werden 15% der Datengröße heuristisch betrachtet als Ausgangspunkt empfohlen. Zum Erstellen des Protokollvolumes sind abhängig von Kosten und Durchsatzanforderungen verschiedene Azure-Datenträgertypen geeignet. Das Protokollvolume erfordert einen hohen E/A-Durchsatz.
Bei Verwendung des VM-Typs „M64-32ms“ muss Schreibbeschleunigung aktiviert werden. Mit der Azure-Schreibbeschleunigung wird eine optimale Datenträgerschreiblatenz für das Transaktionsprotokoll erzielt (nur für die M-Serie verfügbar). Es sind einige Punkte wie die maximale Anzahl von Datenträgern pro VM-Typ zu berücksichtigen. Ausführliche Informationen zur Schreibbeschleunigung finden Sie auf der Seite Aktivieren der Schreibbeschleunigung.
Im Anschluss folgen einige Beispiele für die Dimensionierung des Protokollvolumes:
| Datenvolumegröße und Datentr.-Typ | Protokollvolume und Datentr.-Typ-Konfig. 1 | Protokollvolume und Datentr.-Typ-Konfig. 2 |
|---|---|---|
| 4 × P50 -> 16 TB | 5 × P20 -> 2,5 TB | 3 x P30 -> 3 TB |
| 6 × P15 -> 1,5 TB | 4 x P6 -> 256 GB | 1 x P15 -> 256 GB |
Wie für SAP HANA beim horizontalen Hochskalieren muss das Verzeichnis „/hana/shared“ von der SAP HANA-VM und der DT 2.0-VM gemeinsam genutzt werden. Die gleiche Architektur wie für das horizontale Hochskalieren von SAP HANA unter Einsatz dedizierter VMs, die als hochverfügbare NFS-Server fungieren, wird empfohlen. Um ein freigegebenes Sicherungsvolume zu gewährleisten, kann der identische Entwurf verwendet werden. Aber der Kunde entscheidet, ob Hochverfügbarkeit erforderlich ist, oder ob es ausreicht, einfach einen dedizierten virtuellen Computer zu verwenden, dessen Speicherkapazität ausreicht, als Sicherungsserver zu fungieren.
Links zur DT 2.0-Dokumentation
- SAP HANA Dynamic Tiering: Installation and Update Guide (Installations- und Aktualisierungshandbuch)
- Official SAP HANA Dynamic Tiering tutorials and resources (Offizielle Tutorials und Ressourcen)
- SAP HANA dynamic tiering – delivering on low TCO warm data management, with impressive performance (Management „warmer“ Daten zu niedrigen TCO mit eindrucksvoller Leistung)
- SAP HANA 2.0 SPS 02 dynamic tiering enhancements (Verbesserungen)
Vorgänge für die Bereitstellung von SAP HANA auf virtuellen Azure Computern
In den folgenden Abschnitten werden einige der Vorgänge beschrieben, die auszuführen sind, um SAP HANA-Systeme auf virtuellen Azure-Computern bereitzustellen.
Sicherungs- und Wiederherstellungsvorgänge auf virtuellen Azure-Computern
In den folgenden Dokumenten ist beschrieben, wie Sie Ihre SAP HANA-Bereitstellung sichern und wiederherstellen:
- Übersicht über SAP HANA-Sicherungen
- SAP HANA-Sicherungen auf Dateiebene
- Benchmark von SAP HANA-Speichermomentaufnahmen
Starten und Neustarten von virtuellen Computern, die SAP HANA enthalten
Ein markantes Merkmal der öffentlichen Azure-Cloud ist, dass Ihnen Gebühren nur für die Datenverarbeitungsminuten berechnet werden. Wenn Sie beispielsweise einen virtuellen Computer herunterfahren, auf dem SAP HANA ausgeführt wird, werden Ihnen nur die Speicherkosten für diese Zeit in Rechnung gestellt. Ein weiteres Merkmal ist verfügbar, wenn Sie in Ihrer Erstbereitstellung statische IP-Adressen für Ihre virtuellen Computer angeben. Wenn Sie einen virtuellen Computer neu starten, auf dem SAP HANA ausgeführt wird, wird der virtuelle Computer mit seinen vorherigen IP-Adressen neu gestartet.
Verwenden von SAPRouter für SAP-Remoteunterstützung
Wenn Sie eine Standort-zu-Standort-Verbindung zwischen Ihren lokalen Standorten und Azure haben, und wenn Sie SAP-Komponenten ausführen, wird SAProuter wahrscheinlich bereits ausgeführt. In diesem Fall führen Sie die folgenden Schritte für Remoteunterstützung aus:
- Übernehmen der privaten und der statischen IP-Adresse des virtuellen Computers, auf dem SAP HANA gehostet wird, in die SAProuter-Konfiguration
- Konfigurieren der NSG des Subnetzes, in dem der virtuelle HANA-Computer gehostet wird, für Zulassen von Datenverkehr über den TCP/IP-Port 3299
Wenn Sie eine Verbindung mit Azure über das Internet herstellen und keinen SAP-Router für den virtuellen Computer mit SAP HANA haben, müssen Sie die Komponente installieren. Installieren Sie SAProuter auf einem separaten virtuellen Computer im Verwaltungssubnetz. Die folgende Abbildung zeigt ein allgemeines Schema für die Bereitstellung von SAP HANA ohne eine Standort-zu-Standort-Verbindung und mit SAProuter:
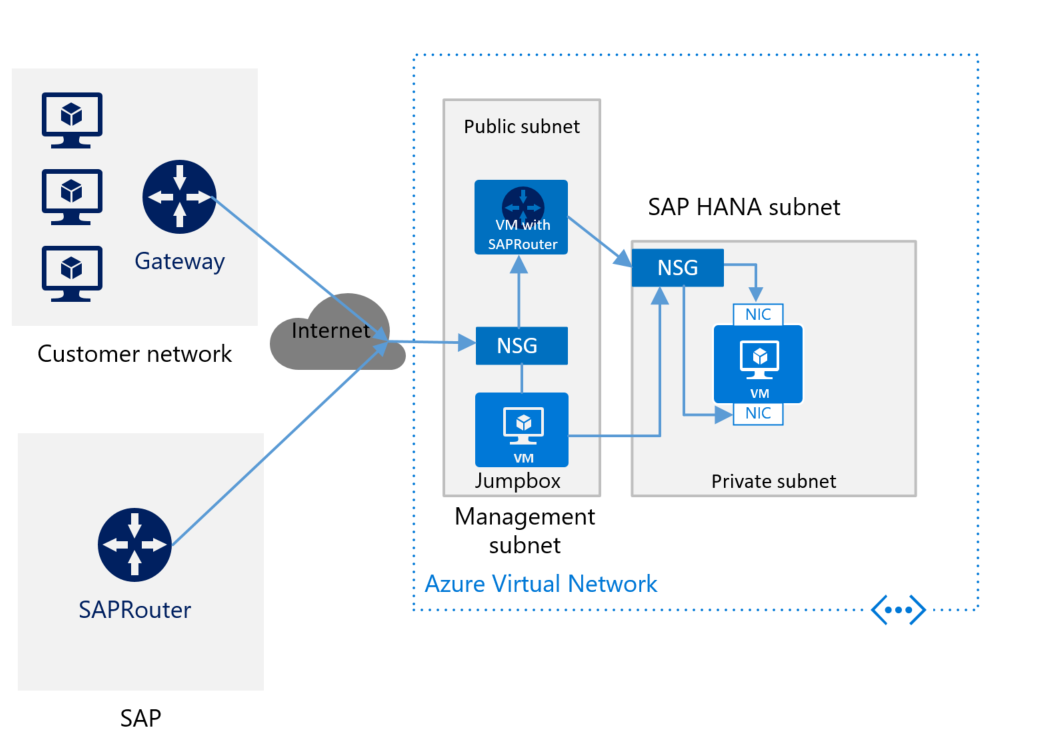
Installieren Sie SAProuter unbedingt auf einem separaten virtuellen Computer und nicht auf Ihrer Jumpbox-VM. Der separate virtuelle Computer muss eine statische IP-Adresse haben. Um die Verbindung Ihres SAProuters mit dem SAProuter herzustellen, der von SAP gehostet wird, wenden Sie sich an SAP, um eine IP-Adresse zu erhalten. (Der SAProuter, der von SAP gehostet wird, ist das Gegenstück zu der SAProuter-Instanz, die Sie auf Ihrem virtuellen Computer installieren.) Verwenden Sie die IP-Adresse von SAP, um Ihre SAProuter-Instanz zu konfigurieren. In den Konfigurationseinstellungen ist der TCP-Port 3299 der einzige erforderliche Port.
Weitere Informationen zum Einrichten und Verwalten von Verbindungen zur Remoteunterstützung über SAProuter finden Sie in der SAP-Dokumentation.
Hochverfügbarkeit mit SAP HANA auf nativen virtuellen Azure-Computern
Wenn Sie mit SUSE Linux Enterprise Server oder Red Hat arbeiten, können Sie einen Pacemaker-Cluster mit Fencinggeräten einrichten. Sie können die Geräte verwenden, um eine SAP HANA-Konfiguration einzurichten, in der synchrone Replikation mit HANA-Systemreplikation und automatischem Failover verwendet wird. Weitere Informationen finden Sie im Abschnitt „Nächste Schritte“.
Nächste Schritte
Machen Sie sich mit den aufgeführten Artikeln vertraut.
- SAP HANA: Speicherkonfigurationen für virtuelle Azure-Computer
- Bereitstellen eines Systems für horizontale SAP HANA-Skalierung mit Standbyknoten auf Azure-VMs mithilfe von Azure NetApp Files auf SUSE Linux Enterprise Server
- Bereitstellen eines Systems für horizontale SAP HANA-Skalierung mit Standbyknoten auf Azure-VMs mithilfe von Azure NetApp Files auf Red Hat Enterprise Linux
- Bereitstellen eines horizontal skalierten SAP HANA-Systems mit HSR und Pacemaker in virtuellen Azure-Computern unter SUSE Linux Enterprise Server
- Bereitstellen eines horizontal skalierten SAP HANA-Systems mit HSR und Pacemaker in virtuellen Azure-Computern unter Red Hat Enterprise Linux
- Hochverfügbarkeit von SAP HANA auf Azure-VMs unter SUSE Linux Enterprise Server
- Hochverfügbarkeit von SAP HANA auf Azure-VMs unter Red Hat Enterprise Linux