Zuverlässigkeit in Azure HDInsight
Dieser Artikel beschreibt die Zuverlässigkeitsunterstützung in Azure HDInsight und behandelt Verfügbarkeitszonen und regionsübergreifende Wiederherstellung und Geschäftskontinuität. Eine ausführlichere Übersicht über die Zuverlässigkeit in Azure finden Sie unter Azure-Zuverlässigkeit.
Unterstützung für Verfügbarkeitszonen
Verfügbarkeitszonen sind physisch getrennte Gruppen von Rechenzentren innerhalb einer Azure-Region. Wenn eine Zone ausfällt, erfolgt ein Failover der Dienste zu einer der verbleibenden Zonen.
Weitere Informationen zu Verfügbarkeitszonen in Azure finden Sie unter Was sind Verfügbarkeitszonen?
Azure HDInsight unterstützt eine zonale Bereitstellungskonfiguration. Azure HDInsight-Clusterknoten werden in einer einzelnen Zone platziert, die Sie in der gewählten Region auswählen. Ein zonales HDInsight-Cluster ist von Ausfällen in anderen Zonen isoliert. Wenn sich ein Ausfall jedoch auf die bestimmte Zone auswirkt, die für den HDInsight-Cluster ausgewählt wurde, ist der Cluster nicht verfügbar. Dieses Bereitstellungsmodell bietet eine kostengünstige Netzwerkkonnektivität mit geringer Latenz innerhalb des Clusters. Die Replizierung dieses Bereitstellungsmodells in mehrere Verfügbarkeitszonen kann ein höheres Maß an Verfügbarkeit zum Schutz vor Hardwareausfällen bieten.
Wichtig
Für Bereitstellungen, bei denen Benutzer keine bestimmte Zone angeben, sind Knotentypen nicht zonensicher, und es können während eines Ausfalls in einer Zone in dieser Region Ausfallzeiten auftreten.
Voraussetzungen
Verfügbarkeitszonen werden nur für Cluster unterstützt, die nach dem 15. Juni 2023 erstellt wurden. Die Einstellungen der Verfügbarkeitszone können nach dem Erstellen des Clusters nicht mehr aktualisiert werden. Außerdem können Sie einen bestehenden, nicht verfügbaren Zonencluster nicht aktualisieren, wenn Sie Verfügbarkeitszonen verwenden möchten.
Cluster müssen unter einem benutzerdefinierten VNet erstellt werden.
Sie müssen Ihre eigene SQL-DB für die Ambari-DB und den externen Metastore (wie den Hive-Metastore) bereitstellen, damit Sie diese DBs in derselben Verfügbarkeitszone konfigurieren können.
Ihre HDInsight-Cluster müssen mit der Verfügbarkeitszonenoption in einer der folgenden Regionen erstellt werden:
- Australien (Osten)
- Brasilien Süd
- Kanada, Mitte
- USA (Mitte)
- East US
- USA (Ost) 2
- Frankreich, Mitte
- Deutschland, Westen-Mitte
- Japan, Osten
- Korea, Mitte
- Nordeuropa
- Katar, Mitte
- Asien, Südosten
- USA Süd Mitte
- UK, Süden
- US Government, Virginia
- Europa, Westen
- USA, Westen 2
Erstellen eines HDInsight-Clusters mit Verfügbarkeitszone
Sie können die Azure Resource Manager (ARM)-Vorlage verwenden, um einen HDInsight-Cluster in einer bestimmten Verfügbarkeitszone zu starten.
Im Abschnitt „Ressourcen“ müssen Sie einen Abschnitt „Zonen“ hinzufügen und angeben, in welcher Verfügbarkeitszone dieser Cluster bereitgestellt werden soll.
"resources": [
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('cluster name')]",
"location": "East US 2",
"zones": [
"1"
],
}
]
Überprüfen von Knoten innerhalb einer Verfügbarkeitszone über Zonen hinweg
Wenn der HDInsight-Cluster fertig ist, können Sie den Standort überprüfen, um zu sehen, in welcher Verfügbarkeitszone er bereitgestellt wurde.

Abfrage der API-Antwort:
[
{
"location": "East US 2",
"zones": [
"1"
],
}
]
Skalieren des Clusters
Sie können einen HDInsight-Cluster mit mehr Workerknoten aufstocken. Die neu hinzugefügten Workerknoten werden in der gleichen Verfügbarkeitszone dieses Clusters platziert.
Migration der Verfügbarkeitszone
Azure HDInsight-Cluster unterstützen derzeit keine direkte Migration vorhandener Clusterinstanzen zur Unterstützung von Verfügbarkeitszonen. Allerdings können Sie Ihren Cluster neu erstellen und während der Clustererstellung eine andere Verfügbarkeitszone oder Region auswählen. Ein sekundärer Standbycluster in einer anderen Region und eine andere Verfügbarkeitszone können in Notfallwiederherstellungsszenarien verwendet werden.
Zonenausfall
Wenn eine Verfügbarkeitszone ausfällt:
- Sie können sich nicht mit ssh auf diesen Cluster einloggen.
- Sie können diesen Cluster nicht löschen, vergrößern oder verkleinern.
- Sie können keine Aufträge einreichen oder den Auftragsverlauf einsehen.
- Sie können weiterhin eine Anforderung zur Erstellung eines neuen Clusters in einer anderen Region stellen.
Regionsübergreifende Notfallwiederherstellung und Geschäftskontinuität
Bei der Notfallwiederherstellung (DR) geht es um die Wiederherstellung nach Ereignissen mit schwerwiegenden Auswirkungen, z. B. Naturkatastrophen oder fehlerhaften Bereitstellungen, die zu Downtime und Datenverlust führen. Unabhängig von der Ursache ist das beste Mittel gegen einen Notfall ein gut definierter und getesteter Notfallplan und ein Anwendungsdesign, die Notfallwiederherstellung aktiv unterstützt. Bevor Sie mit der Erstellung Ihres Notfallwiederherstellungsplans beginnen, lesen Sie die Empfehlungen zum Entwerfen einer Notfallwiederherstellungsstrategie.
Bei DR verwendet Microsoft das Modell der gemeinsamen Verantwortung. In einem Modell der gemeinsamen Verantwortung stellt Microsoft sicher, dass die grundlegenden Infrastruktur- und Plattformdienste verfügbar sind. Gleichzeitig replizieren viele Azure-Dienste nicht automatisch Daten oder greifen automatisch auf eine ausgefallene Region zurück, um eine regionsübergreifende Replikation in eine andere aktivierte Region durchzuführen. Für diese Dienste sind Sie dafür verantwortlich, einen Notfallwiederherstellungsplan zu erstellen, der für Ihre Workload geeignet ist. Die meisten Dienste, die auf Azure Platform as a Service (PaaS)-Angeboten laufen, bieten Funktionen und Anleitungen zur Unterstützung von Notfallwiederherstellung und Sie können dienstspezifische Funktionen zur Unterstützung einer schnellen Wiederherstellung nutzen, um Ihren Notfallwiederherstellungsplan zu entwickeln.
Azure HDInsight-Cluster sind von vielen Azure-Diensten wie Speicher, Datenbanken, Active Directory, Active Directory Domain Services, Netzwerkdiensten und Key Vault abhängig. Eine gut entworfene, hochverfügbare und fehlertolerante Analyseanwendung sollte mit ausreichend Redundanz entworfen werden, um regionalen oder lokalen Unterbrechungen bei einem oder mehreren dieser Dienste standzuhalten. Dieser Abschnitt bietet einen Überblick über bewährte Methoden, Verfügbarkeit bei einer einzelnen und mehreren Region und Optimierungsoptionen für die Geschäftskontinuitätsplanung.
Notfallwiederherstellung für mehrere Regionen
Für eine Verbesserung der Geschäftskontinuität mithilfe von regionsübergreifender Notfallwiederherstellung mit Hochverfügbarkeit sind komplexere und mit höheren Kosten verbundene Architekturstrukturen erforderlich. In den folgenden Tabellen werden einige technische Bereiche erläutert, die möglicherweise die Gesamtkosten erhöhen.
Kostenoptimierungen
| Fläche | Ursache für die hohen Kosten | Optimierungsstrategien |
|---|---|---|
| Datenspeicherung | Duplizieren von primären Daten/Tabellen in eine sekundäre Region | Replizieren Sie nur zusammengestellte Daten. |
| Ausgehende Daten | Ausgehende regionsübergreifende Datenübertragungen haben ihren Preis. Sehen Sie sich die Preisinformationen für Bandwidth an. | Replizieren Sie nur zusammengestellte Daten, um die Menge ausgehender Daten in den Regionen zu verringern. |
| Clustercomputeressourcen | Weitere HDInsight-Cluster in der sekundären Region | Verwenden Sie automatisierte Skripts zum Bereitstellen sekundärer Computeressourcen bei einem Ausfall der primären Region. Verwenden Sie automatische Skalierung, um die Größe der sekundären Cluster auf das Minimum zu beschränken. Verwenden Sie günstigere VM-SKUs. Erstellen Sie sekundäre Cluster in Regionen, in denen VM-SKUs möglicherweise ermäßigt sind. |
| Authentifizierung | Mehrbenutzerszenarios in der sekundären Region verursachen zusätzliche Azure Microsoft Entra Domain Services-Setups | Vermeiden Sie Mehrbenutzersetups in der sekundären Region. |
Komplexitätsoptimierungen
| Fläche | Ursache für die hohe Komplexität | Optimierungsstrategien |
|---|---|---|
| Lese- und Schreibmuster | Ein aktivierter Lese- und Schreibzugriff ist sowohl für die primäre als auch für die sekundäre Region erforderlich. | Entwerfen Sie die sekundäre Region als schreibgeschützte Region. |
| Keine RPO & RTO | Es wird gefordert, dass es zu keinem Datenverlust (RPO = 0) und keiner Downtime (RTO = 0) kommt. | Entwerfen Sie RPO und RTO so, dass Sie die Anzahl von Komponenten reduzieren, für die ein Failover erforderlich ist. Weitere Informationen zu RTO und RPO finden Sie unter Was sind Geschäftskontinuität, Hochverfügbarkeit und Notfallwiederherstellung? |
| Geschäftsfunktionalität | In der sekundären Region wird die vollständige Geschäftsfunktionalität der primären Region verlangt. | Überprüfen Sie, ob das absolute Minimum wichtiger Teile der Geschäftsfunktionalität in der sekundären Region ausreicht. |
| Konnektivität | Es wird gefordert, dass alle Upstream- und Downstreamsysteme in der primären Region auch eine Verbindung mit der sekundären Region herstellen. | Beschränken Sie die Konnektivität mit der sekundären Region auf das absolute Minimum. |
Berücksichtigen Sie beim Erstellen Ihres Notfallwiederherstellungsplans für mehrere Regionen die folgenden Empfehlungen:
Ermitteln Sie die minimale Geschäftsfunktionalität, die Sie bei einem Notfall benötigen und die Gründe dafür. Überprüfen Sie z. B., ob Sie Failoverfunktionen für die Datentransformationsebene (gelb) und die Datenbereitstellungsebene (blau) benötigen oder nur ein Failover für die Datenbereitstellungsebene erforderlich ist.
Segmentieren Sie Ihre Cluster basierend auf der Workload, dem Entwicklungslebenszyklus und der Abteilung. Eine höhere Anzahl von Clustern verringert die Wahrscheinlichkeit eines einzelnen großen Ausfalls, der sich auf mehrere verschiedene Geschäftsprozesse auswirkt.
Konfigurieren Sie Ihre sekundären Regionen als schreibgeschützt. Failoverregionen mit sowohl Lese- als auch Schreibfunktionen können zu komplexen Architekturen führen.
Vorübergehende Cluster sind bei einem Notfall einfacher zu verwalten. Entwerfen Sie Ihre Workloads so, dass die Cluster durchlaufen werden können und in den Clustern kein Status beibehalten wird.
Häufig können Workloads bei einem Notfall nicht abgeschlossen werden und müssen in der neuen Region neu gestartet werden. Entwerfen Sie Ihre Workloads so, dass sie idempotent sind.
Verwenden Sie bei der Clusterbereitstellung Automatisierung, und stellen Sie sicher, dass die Clusterkonfigurationseinstellungen so weit wie möglich im entsprechenden Skript enthalten sind, um bei einem Notfall eine schnelle und vollständig automatisierte Bereitstellung sicherzustellen.
Erkennung, Benachrichtigung und Verwaltung von Ausfällen
Verwenden Sie die Azure-Überwachungstools in HDInsight, um ungewöhnliches Verhalten im Cluster zu erkennen und entsprechende Warnmeldungen festzulegen. Sie können die vorkonfigurierten spezifischen Verwaltungslösungen für HDInsight-Cluster bereitstellen, die wichtige Leistungsmetriken für den jeweiligen Clustertyp erfassen. Weitere Informationen finden Sie unter Verwenden von Azure Monitor-Protokollen zum Überwachen von HDInsight-Clustern.
Abonnieren Sie Azure-Integritätswarnungen, um über Dienstprobleme, geplante Wartungen sowie Integritäts- und Sicherheitsempfehlungen für ein Abonnement, einen Dienst oder eine Region benachrichtigt zu werden. Integritätsbenachrichtigungen, die die Problemursache und eine feste ETA enthalten, helfen Ihnen bei der besseren Ausführung von Failovern und Failbacks. Weitere Informationen finden Sie in der Dokumentation zu Azure Service Health.
Notfallwiederherstellung für eine Region
Jede Komponente in einem einfachen HDInsight-System verfügt über eigene Fehlertoleranzmechanismen für einzelne Regionen. Beachten Sie, dass für eine Beeinträchtigung der Geschäftsfunktionalität nicht unbedingt ein Notfall eintreten muss. Dienstincidents in einem oder mehreren der folgenden Dienste in einer einzelnen Region können ebenfalls zu einem Verlust der erwarteten Geschäftsfunktionalität führen.
Compute (virtuelle Computer): Azure HDInsight-Cluster. HDInsight bietet eine SLA mit einer Verfügbarkeit von 99,9 %. HDInsight arbeitet mit vielen Diensten zusammen, die standardmäßig im Hochverfügbarkeitsmodus sind, um Hochverfügbarkeit in einer einzelnen Bereitstellung zu gewährleisten. Fehlertoleranzmechanismen in HDInsight werden sowohl von hochverfügbaren Diensten von Microsoft als auch solchen aus dem Apache-OSS-Ökosystem bereitgestellt.
Die folgenden Infrastrukturkomponenten sind für Hochverfügbarkeit konzipiert:
- Aktive Hauptknoten und Standbyhauptknoten
- Mehrere Gatewayknoten
- Drei Zookeeper-Quorumknoten
- Auf Fehler- und Updatedomänen verteilte Workerknoten
Die folgenden Dienste sind ebenfalls für Hochverfügbarkeit konzipiert:
- Apache Ambari-Server
- Anwendungszeitachsenserver für YARN
- Auftragsverlaufsserver für Hadoop MapReduce
- Apache Livy
- HDFS
- YARN Resource Manager
- HBase Master
Weitere Informationen finden Sie unter Von Azure HDInsight unterstützte Hochverfügbarkeitsdienste.
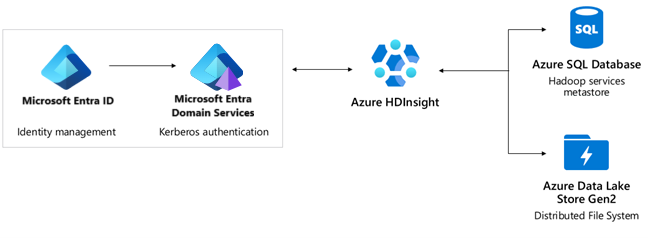
Metastore(s): Azure SQL-Datenbank. HDInsight verwendet Azure SQL-Datenbank als Metastore, der eine SLA mit einer Verfügbarkeit von 99,99 % bietet. Drei Replikate der Daten werden in einem Rechenzentrum mit synchroner Replikation beständig gespeichert. Bei Verlust eines Replikats wird nahtlos ein neues Replikat bereitgestellt. Aktive Georeplikation wird standardmäßig mit maximal vier Rechenzentren unterstützt. Bei einem Failover (manuell oder durch das Rechenzentrum) erhält das erste Replikat in der Hierarchie automatisch Lese- und Schreibfunktionen. Weitere Informationen finden Sie unter Übersicht über die Geschäftskontinuität mit Azure SQL-Datenbank.
Storage: Azure Data Lake Gen2 oder Blob Storage. Für HDInsight wird als zugrunde liegende Speicherebene Azure Data Lake Storage Gen2 empfohlen. Azure Storage, einschließlich Azure Data Lake Storage Gen2, bietet eine SLA mit einer Verfügbarkeit von 99,9 %. HDInsight verwendet den LRS-Dienst, bei dem drei Replikate der Daten beständig in einem Rechenzentrum gespeichert werden und die Replikation synchron erfolgt. Bei Verlust eines Replikats wird nahtlos ein neues Replikat bereitgestellt.
Authentifizierung: Microsoft Entra ID, Microsoft Entra-Domain Services, Enterprise-Sicherheitspaket.
- Microsoft Entra ID bietet eine SLA von 99,9 %. Active Directory ist ein globaler Dienst mit mehreren Ebenen interner Redundanz und automatischer Wiederherstellbarkeit. Informieren Sie sich darüber, wie Microsoft die Zuverlässigkeit von Microsoft Entra ID kontinuierlich verbessert.
- Microsoft Entra Domain Services bietet eine SLA von 99,9 %. Microsoft Entra Domain Services ist ein hochverfügbarer Dienst, der in Rechenzentren weltweit gehostet wird. Replikatgruppen sind eine Previewfunktion in Microsoft Entra Domain Services, die eine geografische Notfallwiederherstellung ermöglicht, wenn eine Azure-Region offline geht. Weitere Informationen finden Sie unter Konzepte und Features zu Replikatgruppen für Microsoft Entra Domain Services.
- Azure DNS bietet eine SLA mit einer Verfügbarkeit von 100 %. HDInsight verwendet Azure DNS an verschiedenen Stellen für die Auflösung von Domänennamen.
Optionale Dienste, z. B. Azure Key Vault und Azure Data Factory.