Architekturen zur Geschäftskontinuität von Azure HDInsight
Dieser Artikel enthält einige Beispiele für Architekturen zur Geschäftskontinuität, die Sie für Azure HDInsight in Betracht ziehen könnten. Die Duldung eingeschränkter Funktionalität während eines Notfalls stellt eine Geschäftsentscheidung dar, die sich von Anwendung zu Anwendung unterscheidet. Bei einigen Anwendungen kann es akzeptabel sein, wenn sie für einen Zeitraum nicht verfügbar oder nur teilweise mit eingeschränkter Funktionalität oder verzögerter Verarbeitung verfügbar sind. Bei anderen Anwendungen könnte jegliche Einschränkung der Funktionalität inakzeptabel sein.
Hinweis
Die in diesem Artikel vorgestellten Architekturen sind in keiner Weise als umfassend zu betrachten. Sie sollten Ihre eigenen, individuellen Architekturen entwerfen, sobald Sie objektive Entscheidungen hinsichtlich der erwarteten Geschäftskontinuität, der betrieblichen Komplexität und der Betriebskosten getroffen haben.
Apache Hive und Interactive Query
Version 2 von Hive Replication wird für die Geschäftskontinuität in HDInsight Hive- und Interactive Query-Clustern empfohlen. Die persistenten Abschnitte eines eigenständigen Hive-Clusters, die repliziert werden müssen, sind die Speicherebene und der Hive-Metastore. Hive-Cluster in einem Mehrbenutzerszenario mit Enterprise-Sicherheitspaket benötigen Microsoft Entra Domain Services und den Ranger-Metastore.
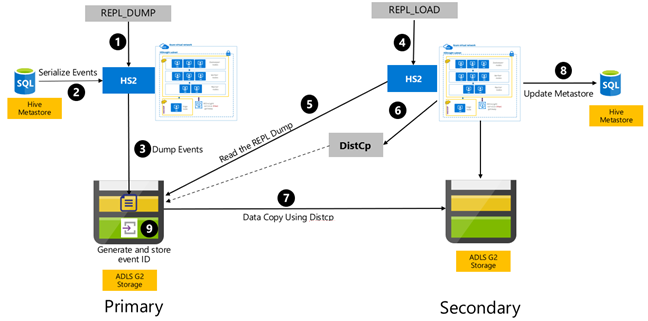
Die ereignisbasierte Hive-Replikation wird zwischen den primären und sekundären Clustern konfiguriert. Diese besteht aus zwei verschiedenen Phasen, dem Bootstrapping und den inkrementellen Ausführungen:
Durch Bootstrapping wird das gesamte Hive-Warehouse einschließlich der Hive-Metastore-Informationen vom primären zum sekundären Cluster repliziert.
Inkrementelle Ausführungen werden auf dem primären Cluster automatisiert, und die während der inkrementellen Ausführungen erzeugten Ereignisse werden auf dem sekundären Cluster wiedergegeben. Der sekundäre Cluster zieht mit den aus dem primären Cluster generierten Ereignissen gleich und stellt so sicher, dass der sekundäre Cluster nach der Ausführung der Replikation mit den Ereignissen des primären Clusters konsistent ist.
Der sekundäre Cluster wird nur zum Zeitpunkt der Replikation benötigt, um verteilte Kopien auszuführen, DistCp, aber der Speicher und die Metastores müssen persistent sein. Sie könnten sich dafür entscheiden, einen mit Skripts erstellten sekundären Cluster bei Bedarf vor der Replikation zu starten, das Replikationsskript darauf auszuführen und ihn dann nach erfolgreicher Replikation zu beenden.
Der sekundäre Cluster ist normalerweise schreibgeschützt. Sie können den sekundären Cluster für Lese- und Schreibvorgänge konfigurieren, aber dies erhöht die Komplexität zusätzlich, da die Änderungen vom sekundären Cluster auf den primären Cluster repliziert werden müssen.
Ereignisbasierte Replikation von Hive – RPO und RTO
RPO: Der Datenverlust ist auf das letzte erfolgreiche inkrementelle Replikationsereignis vom primären zum sekundären Cluster beschränkt.
RTO: Die Zeit zwischen dem Ausfall und der Wiederaufnahme der Upstream- und Downstreamtransaktionen mit dem sekundären Cluster.
Architekturen von Apache Hive und Interactive Query
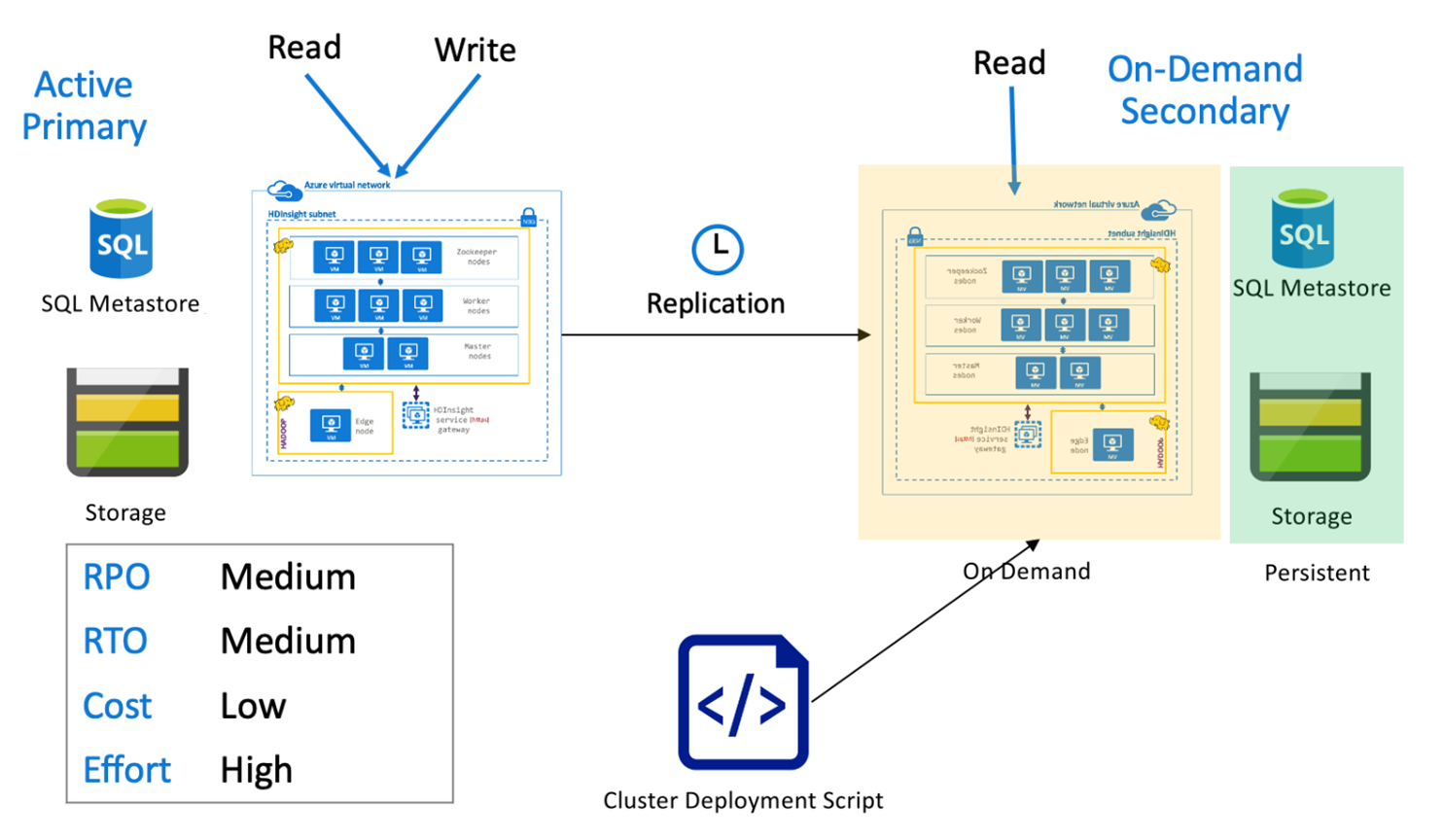
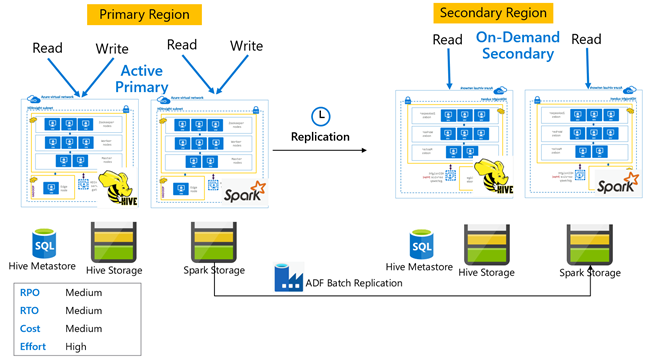
Hive-Architektur mit aktivem primären Cluster und sekundärem On-Demand-Cluster
In einer Architektur mit aktivem primären Cluster mit sekundärem On-Demand-Cluster schreiben Anwendungen in die aktive primäre Region, während in der sekundären Region während des normalen Betriebs kein Cluster bereitgestellt wird. SQL Metastore und Storage in der sekundären Region sind persistent, während der HDInsight-Cluster durch Skripts erstellt und nur bei Bedarf bereitgestellt wird, bevor die geplante Hive-Replikation ausgeführt wird.
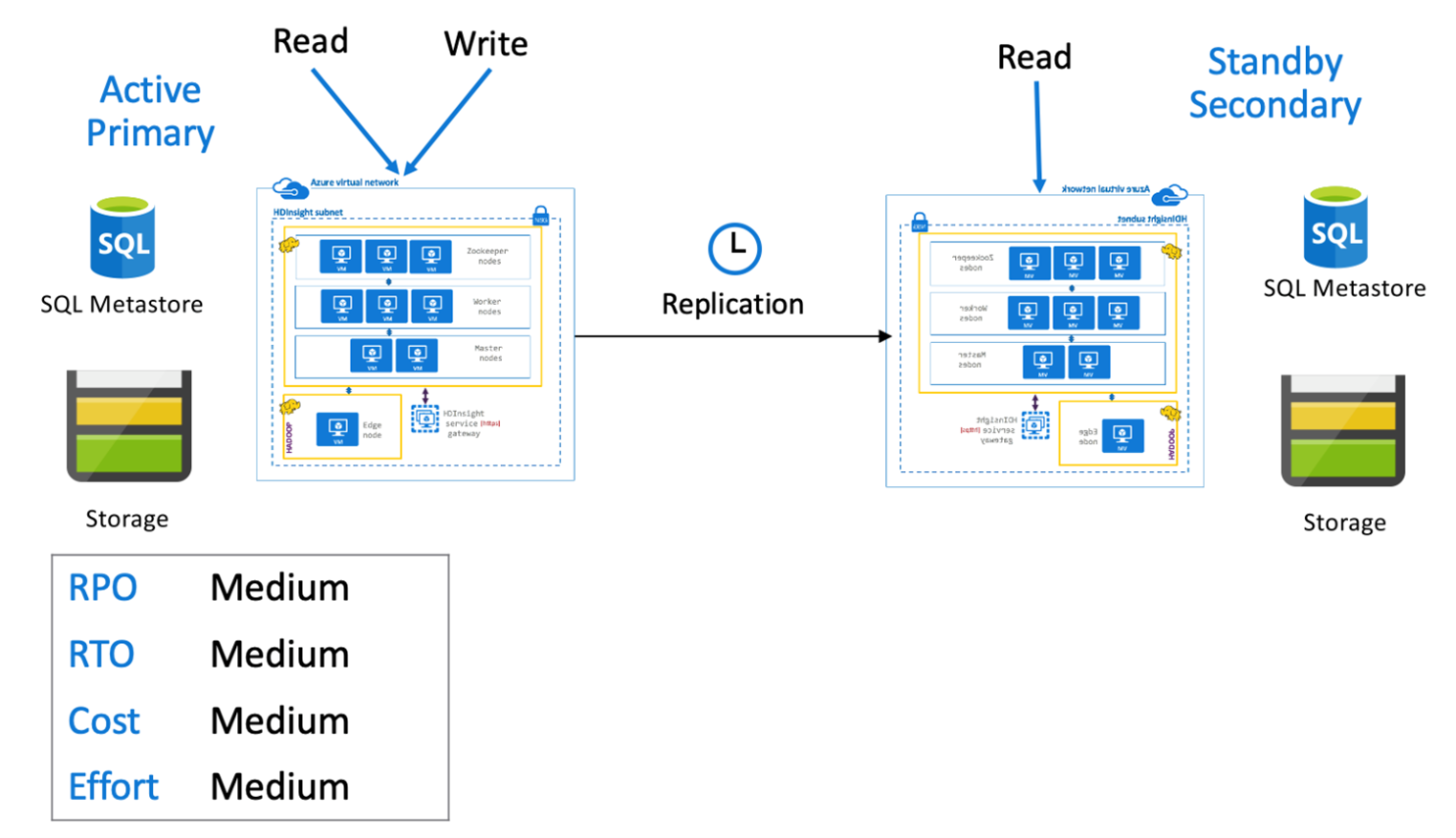
Hive-Architektur mit aktivem primären Cluster und sekundärem Standbycluster
In einer Architektur mit aktivem primären Cluster und sekundärem Standbycluster schreiben Anwendungen in die aktive primäre Region, während ein herunterskalierter sekundärer Standbycluster im schreibgeschützten Modus während des normalen Betriebs ausgeführt wird. Während des normalen Betriebs könnten Sie regionsspezifische Lesevorgänge auf sekundäre Cluster auslagern.
Weitere Informationen zu Hive Replication sowie Codebeispiele finden Sie unter Verwenden von Apache Hive Replication in Azure HDInsight-Clustern.
Apache Spark
Spark-Workloads können eine Hive-Komponente umfassen oder auch nicht. Damit Spark SQL-Workloads Daten aus Hive lesen und schreiben können, nutzen HDInsight Spark-Cluster benutzerdefinierte Hive-Metastores von Hive/Interactive Query-Clustern in derselben Region gemeinsam. In solchen Szenarien muss die regionsübergreifende Replikation von Spark-Workloads auch mit der Replikation von Hive-Metastores und -Speichern einhergehen. Die Failoverszenarien in diesem Abschnitt gelten für beide:
- Spark SQL für ACID-Tabellen unter Verwendung des HWC-Setups (Hive Warehouse Connector), die einen HDInsight Interactive Query-Cluster verwenden.
- Spark SQL-Workload für Nicht-ACID-Tabellen, die einen HDInsight Hadoop-Cluster verwenden.
Für Szenarien, in denen Spark im eigenständigen Modus arbeitet, müssen kuratierte Daten und gespeicherte Spark Jars (für Livy-Aufträge) mithilfe des DistCP von Azure Data Factory regelmäßig von der primären Region in die sekundäre Region repliziert werden.
Es wird empfohlen, Spark-Notebooks und -Bibliotheken mithilfe von Versionskontrollsystemen zu speichern, damit sie problemlos auf primären oder sekundären Clustern bereitgestellt werden können. Stellen Sie sicher, dass auf Notebooks basierte und nicht auf Notebooks basierte Lösungen so vorbereitet sind, dass sie die richtigen Datenbereitstellungen in den primären oder sekundären Arbeitsbereich laden können.
Wenn es kundenspezifische Bibliotheken gibt, die über das hinausgehen, was HDInsight nativ anbietet, müssen diese nachverfolgt und periodisch in den sekundären Standbycluster geladen werden.
Apache Spark-Replikation – RPO und RTO
RPO: Der Datenverlust ist auf die letzte erfolgreiche inkrementelle Replikation (Spark und Hive) vom primären zum sekundären Cluster beschränkt.
RTO: Die Zeit zwischen dem Ausfall und der Wiederaufnahme der Upstream- und Downstreamtransaktionen mit dem sekundären Cluster.
Apache Spark-Architekturen
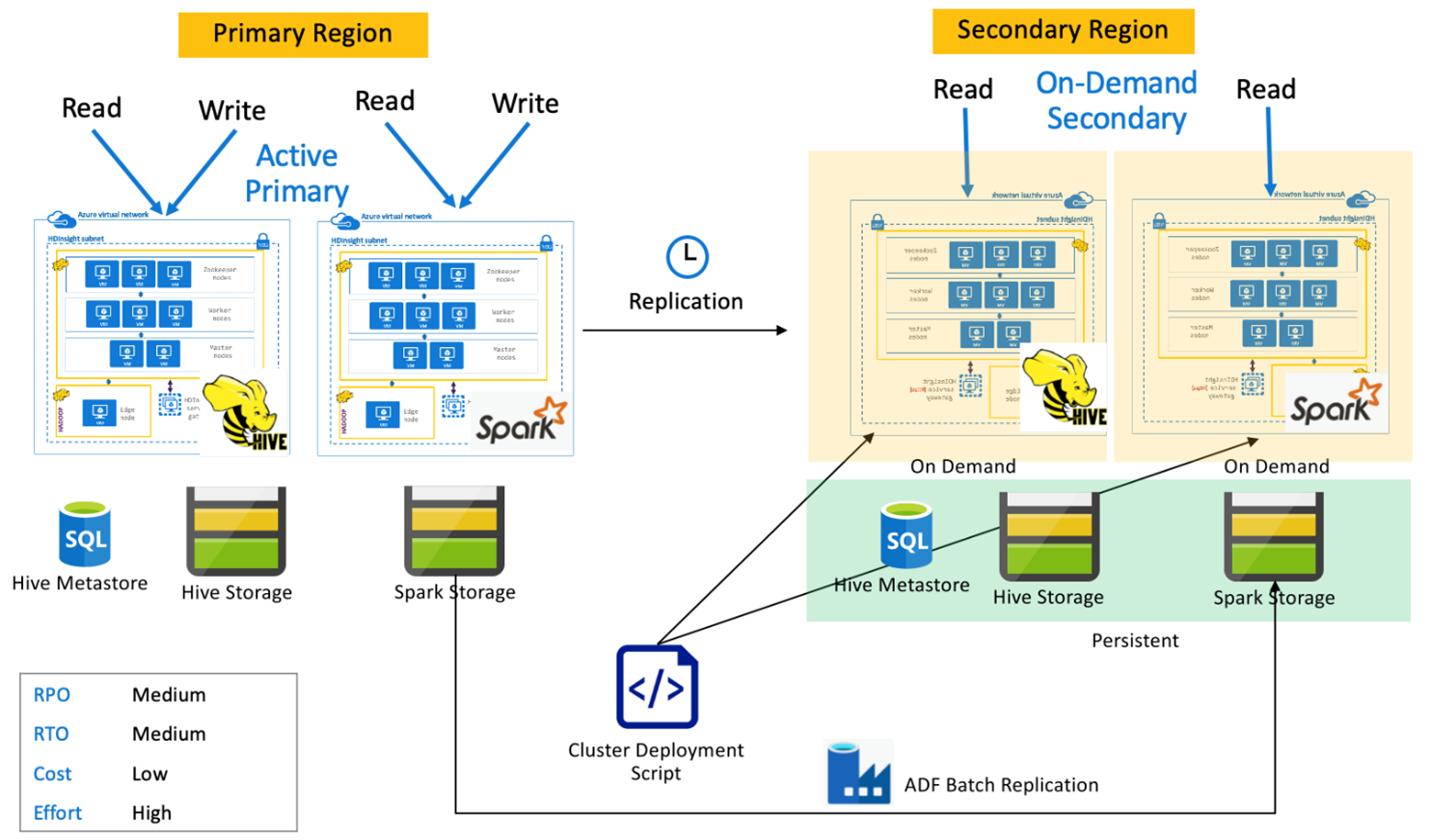
Spark-Architektur mit aktivem primären Cluster und sekundärem On-Demand-Cluster
Anwendungen lesen von und schreiben auf Spark- und Hive-Cluster in der primären Region, während in der sekundären Region während des normalen Betriebs keine Cluster bereitgestellt werden. SQL Metastore, Hive-Speicher und Spark-Speicher sind in der sekundären Region persistent. Die Spark- und Hive-Cluster werden nach Bedarf per Skript erstellt und bereitgestellt. Die Hive-Replikation dient zur Replikation von Hive-Speichern und Hive-Metastores, während das DistCP von Azure Data Factory zum Kopieren von eigenständigen Spark-Speichern verwendet werden kann. Hive-Cluster müssen aufgrund der Abhängigkeit „DistCp-Compute“ vor jeder Hive-Replikationsausführung bereitgestellt werden.
Spark-Architektur mit aktivem primären Cluster und sekundärem Standbycluster
Anwendungen lesen von und schreiben auf Spark- und Hive-Cluster in der primären Region, während herunterskalierte Hive- und Spark-Standbycluster im schreibgeschützten Modus während des normalen Betriebs in der sekundären Region ausgeführt werden. Während des normalen Betriebs könnten Sie regionsspezifische Hive- und Spark-Lesevorgänge auf sekundäre Cluster auslagern.
Apache HBase
HBase Export und HBase Replication sind gängige Methoden, um Geschäftskontinuität zwischen HDInsight HBase-Clustern zu ermöglichen.
HBase Export ist ein Batchreplikationsprozess, der das HBase Export-Hilfsprogramm verwendet, um Tabellen aus dem primären HBase-Cluster in den darunter liegenden Azure Data Lake Storage Gen2-Speicher zu exportieren. Die exportierten Daten können dann aus dem sekundären HBase-Cluster abgerufen und in Tabellen importiert werden, die im sekundären Cluster bereits vorhanden sein müssen. Während HBase Export eine Granularität auf Tabellenebene bietet, steuert die Engine für die Exportautomatisierung in inkrementellen Aktualisierungssituationen den Bereich der inkrementellen Zeilen, die bei jeder Ausführung berücksichtigt werden sollen. Weitere Informationen finden Sie unter HDInsight HBase-Sicherung und -Replikation.
HBase Replication verwendet die Replikation nahezu in Echtzeit zwischen HBase-Clustern auf vollständig automatisierte Weise. Die Replikation erfolgt auf Tabellenebene. Es können entweder alle oder bestimmte Tabellen für die Replikation ausgewählt werden. HBase Replication ist letztendlich konsistent, was bedeutet, dass kürzlich vorgenommene Änderungen an einer Tabelle in der primären Region möglicherweise nicht allen sekundären Regionen sofort zur Verfügung stehen. Es wird garantiert, dass die sekundären Regionen schließlich mit den primären Regionen in Einklang gebracht werden. HBase Replication kann zwischen zwei oder mehreren HDInsight HBase-Clustern eingerichtet werden, wenn Folgendes zugrifft:
- Primärer und sekundärer Cluster befinden sich in demselben virtuellen Netzwerk.
- Primärer und sekundärer Cluster befinden sich in unterschiedlichen virtuellen Netzwerken mit Peering in derselben Region.
- Primärer und sekundärer Cluster befinden sich in unterschiedlichen virtuellen Netzwerken mit Peering in verschiedenen Regionen.
Weitere Informationen finden Sie unter Einrichten der Apache HBase-Clusterreplikation in virtuellen Azure-Netzwerken.
Es gibt noch einige andere Möglichkeiten, Sicherungen von HBase-Clustern zu erstellen, z. B. Kopieren des HBase-Ordners, Kopieren von Tabellen und Momentaufnahmen.
HBase – RPO und RTO
HBase Export
- RPO: Der Datenverlust ist auf den letzten erfolgreichen inkrementellen Batchimport durch den sekundären Cluster vom primären Cluster beschränkt.
- RTO: Die Zeit zwischen dem Ausfall des primären Clusters und der Wiederaufnahme der E/A-Vorgänge auf dem sekundären Cluster.
HBase Replication
- RPO: Der Datenverlust ist auf die letzte WalEdit-Lieferung beschränkt, die auf dem sekundären Cluster empfangen wurde.
- RTO: Die Zeit zwischen dem Ausfall des primären Clusters und der Wiederaufnahme der E/A-Vorgänge auf dem sekundären Cluster.
HBase-Architekturen
Es gibt drei Modi, um HBase Replication einzurichten: „Leader-Follower“, „Leader-Leader“ und „Zyklisch“.
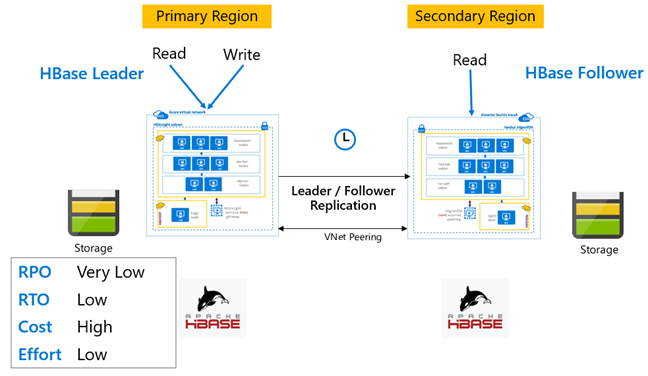
HBase-Replikation: Leader-Follower-Modell
Bei dieser regionsübergreifenden Einrichtung erfolgt die Replikation unidirektional von der primären in die sekundäre Region. Für die unidirektionale Replikation können entweder alle oder bestimmte Tabellen auf dem primären Cluster identifiziert werden. Während des normalen Betriebs kann der sekundäre Cluster dazu verwendet werden, Leseanforderungen in seiner eigenen Region zu bearbeiten.
Der sekundäre Cluster dient als normaler HBase-Cluster, der seine eigenen Tabellen hosten und Lese- und Schreibvorgänge von regionalen Anwendungen bearbeiten kann. Schreibvorgänge für die replizierten Tabellen oder Tabellen, die vom sekundären Cluster stammen, werden jedoch nicht auf den primären Cluster zurückrepliziert.
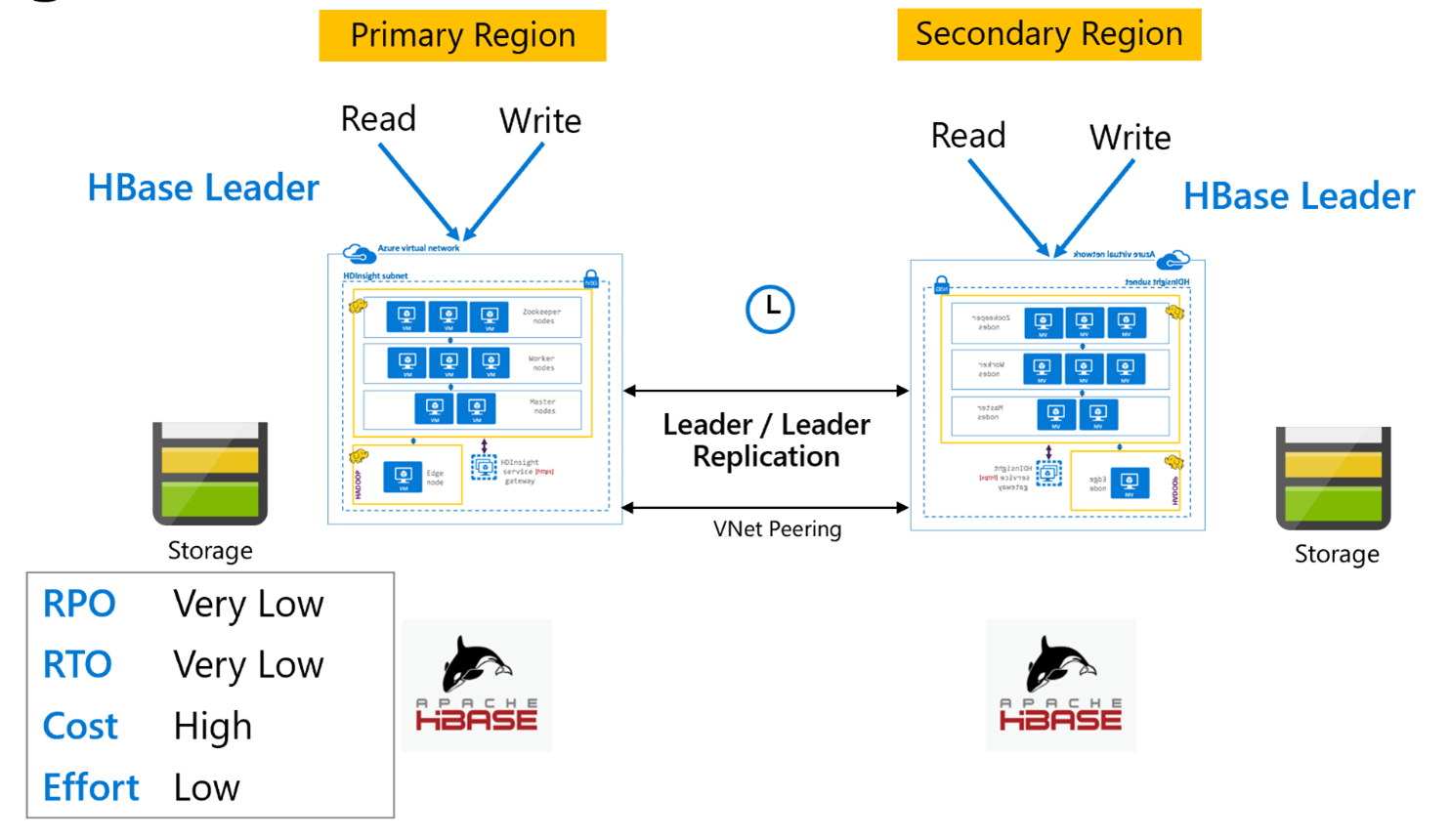
HBase-Replikation: Leader-Modell
Diese bereichsübergreifende Einrichtung ist der unidirektionalen Einrichtung sehr ähnlich, mit der Ausnahme, dass die Replikation bidirektional zwischen der primären und der sekundären Bereich erfolgt. Anwendungen können beide Cluster im Lese-/Schreibmodus verwenden, und Aktualisierungen werden asynchron zwischen ihnen vorgenommen.
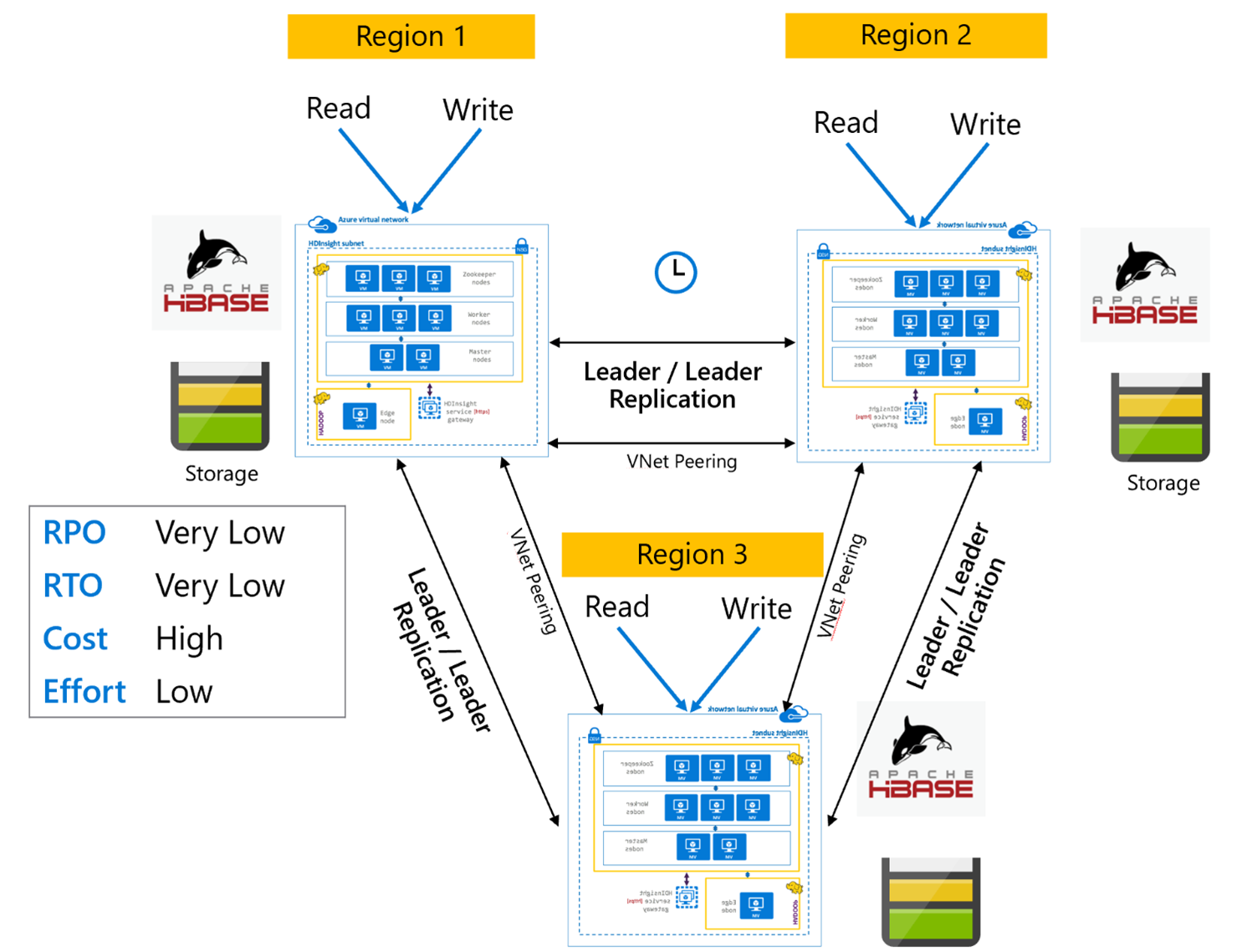
HBase Replication: „Mehrere Regionen“ oder „Zyklisch“
Das Replikationsmodell „Mehrere Regionen/Zyklisch“ ist eine Erweiterung von HBase Replication und könnte dazu verwendet werden, eine global redundante HBase-Architektur mit mehreren Anwendungen zu erstellen, die von regionsspezifischen HBase-Clustern lesen und auf diese schreiben. Die Cluster können je nach Geschäftsanforderungen in verschiedenen Kombinationen aus Leader/Leader oder Leader/Follower eingerichtet werden.
Apache Kafka
Um eine regionenübergreifende Verfügbarkeit zu ermöglichen, unterstützt HDInsight 4.0 Kafka MirrorMaker, mit dessen Hilfe ein sekundäres Replikat des primären Kafka-Clusters in einer anderen Region verwaltet werden kann. MirrorMaker fungiert als allgemeines Verbraucher-Erzeuger-Paar, verbraucht aus einem bestimmten Thema im primären Cluster und erzeugt für ein gleichnamiges Thema im sekundären Cluster. Die clusterübergreifende Replikation für die Notfallwiederherstellung mit Hochverfügbarkeit mithilfe von MirrorMaker setzt voraus, dass Erzeuger und Verbraucher einen Failover auf den Replikatcluster ausführen müssen. Weitere Informationen finden Sie unter Verwenden von MirrorMaker zum Replizieren von Apache Kafka-Themen mit Kafka in HDInsight.
Abhängig von der Lebensdauer des Themas beim Start der Replikation kann die MirrorMaker-Themenreplikation zu unterschiedlichen Offsets zwischen Quell- und Replikatthemen führen. HDInsight Kafka-Cluster unterstützen auch die Replikation von Themenpartitionen, die ein Hochverfügbarkeitsfeature auf der Ebene der einzelnen Cluster ist.
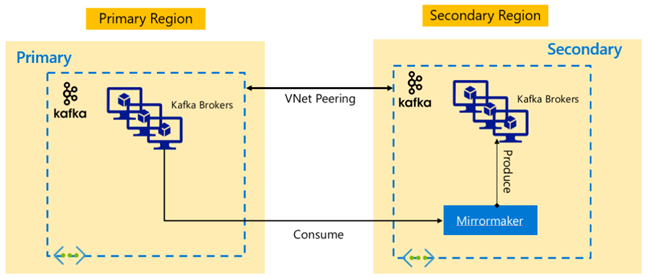
Apache Kafka-Architekturen
Kafka-Replikation: Aktiv – Passiv
Die Aktiv-Passiv-Einrichtung ermöglicht eine asynchrone unidirektionale Spiegelung von „Aktiv“ zu „Passiv“. Erzeuger und Verbraucher müssen sich der Existenz eines Aktiv- und Passiv-Clusters bewusst und bereit sein, einen Failover zu „Passiv“ durchzuführen, falls „Aktiv“ ausfällt. Im Folgenden sind einige Vor- und Nachteile der Aktiv-Passiv-Einrichtung aufgeführt.
Vorteile:
- Die Netzwerklatenz zwischen den Clustern hat keinen Einfluss auf die Leistung des aktiven Clusters.
- Einfachheit der unidirektionalen Replikation.
Nachteile:
- Der passive Cluster bleibt möglicherweise unzureichend ausgelastet.
- Entwurfskomplexität bei der Einbeziehung des Failoverbewusstseins bei Erzeugern und Verbrauchern von Anwendungen.
- Möglicher Datenverlust bei Ausfall des aktiven Clusters.
- Letztliche Konsistenz zwischen den Themen bei aktiven und passiven Clustern.
- Failbacks zum primären Cluster können zu einer Nachrichteninkonsistenz bei Themen führen.
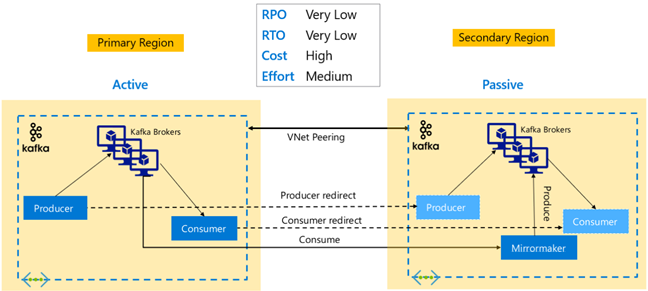
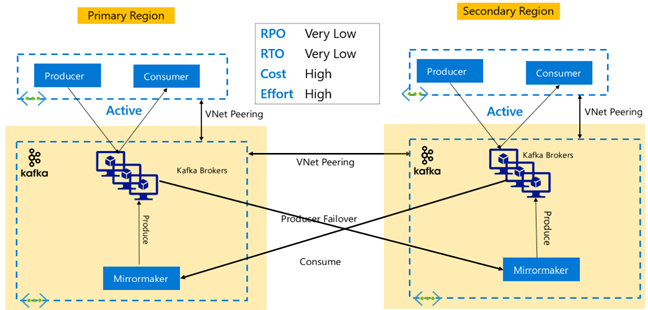
Kafka-Replikation: Aktiv – Aktiv
Die Aktiv-Aktiv-Einrichtung umfasst zwei regional getrennte HDInsight Kafka-Cluster im VNet mit Peering mit bidirektionaler asynchroner Replikation mit MirrorMaker. Bei diesem Entwurf werden Nachrichten, die von den Verbrauchern in der primären Region konsumiert werden, auch den Verbrauchern in der sekundären Region zur Verfügung gestellt und umgekehrt. Im Folgenden sind einige Vor- und Nachteile der Aktiv-Aktiv-Einrichtung aufgeführt.
Vorteile:
- Aufgrund des duplizierten Zustands sind Failover und Failback einfacher durchzuführen.
Nachteile:
- Einrichtung, Verwaltung und Überwachung sind komplexer als bei „Aktiv-Passiv“.
- Das Problem der kreisförmigen Replikation muss behandelt werden.
- Die bidirektionale Replikation führt zu höheren regionalen Kosten für die Datenausgabe.
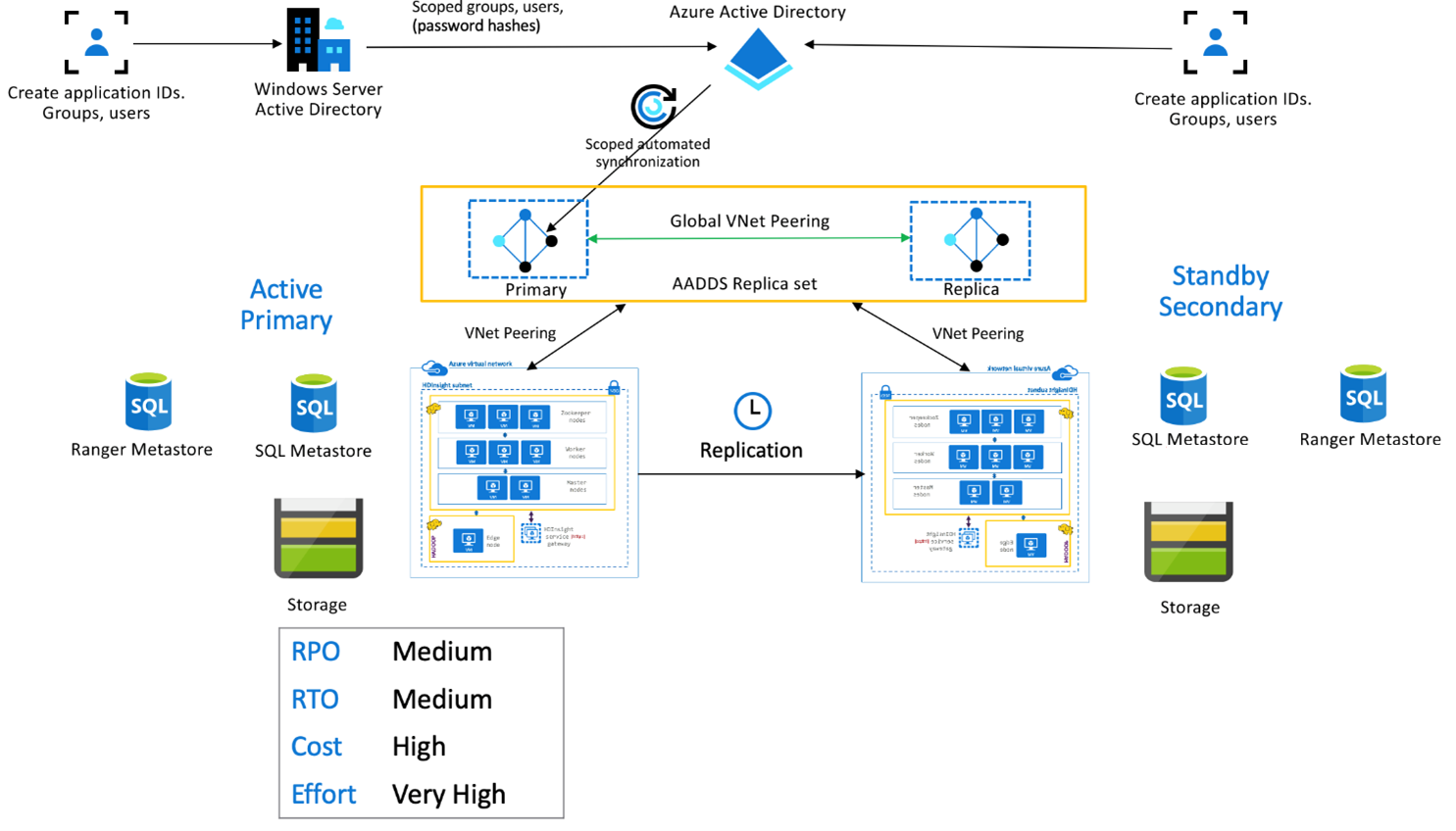
HDInsight: Enterprise-Sicherheitspaket
Diese Einrichtung wird verwendet, um Mehrbenutzerfunktionen sowohl in der primären als auch in der sekundären Region sowie Microsoft Entra Domain Services-Replikatgruppen zu ermöglichen, um sicherzustellen, dass sich Benutzer bei beiden Clustern authentifizieren können. Während des normalen Betriebs müssen in der sekundären Region Ranger-Richtlinien eingerichtet werden, um sicherzustellen, dass die Benutzer auf Lesevorgänge beschränkt sind. Die nachstehende Architektur erläutert, wie eine ESP-fähige Hive-Einrichtung mit aktivem primären Cluster und sekundärem Standbycluster aussehen könnte.
Ranger-Metastore-Replikation:
Der Ranger-Metastore wird verwendet, um Ranger-Richtlinien zur Steuerung der Datenautorisierung dauerhaft zu speichern und zu bedienen. Es wird empfohlen, unabhängige Ranger-Richtlinien in der primären und sekundären Region beizubehalten und die sekundäre Region als Lesereplikat zu erhalten.
Wenn die Anforderung darin besteht, die Ranger-Richtlinien zwischen primärer und sekundärer Bereich synchron zu halten, verwenden Sie Ranger Import/Export, um Ranger-Richtlinien periodisch zu sichern und aus dem primären in den sekundären Bereich zu importieren.
Das Replizieren von Ranger-Richtlinien zwischen primärer und sekundärer Region kann dazu führen, dass die sekundäre Region für Schreibvorgänge aktiviert wird, was zu unbeabsichtigten Schreibvorgängen in der sekundären Region und somit zu Dateninkonsistenzen führen kann.
Nächste Schritte
Weitere Informationen zu den in diesem Artikel erörterten Themen finden Sie unter: