Bereitstellen eines Modells als ein Onlineendpunkt
GILT FÜR:  Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
Erfahren Sie, wie Sie mit dem Azure Machine Learning Python SDK v2 ein Modell auf einem Onlineendpunkt bereitstellen.
In diesem Tutorial stellen Sie ein Modell bereit und verwenden ein Modell, das die Wahrscheinlichkeit eines Kundenverzugs bei einer Kreditkartenzahlung vorhersagt.
Auszuführende Schritte:
- Registrieren Ihres Modells
- Erstellen eines Endpunkts und einer ersten Bereitstellung
- Bereitstellen einer Testausführung
- Manuelles Senden von Testdaten an die Bereitstellung
- Abrufen von Details zur Bereitstellung
- Erstellen einer zweiten Bereitstellung
- Manuelles Skalieren der zweiten Bereitstellung
- Aktualisieren der Zuordnung des Produktionsdatenverkehrs zwischen beiden Bereitstellungen
- Abrufen von Details zur zweiten Bereitstellung
- Rollout der neuen Bereitstellung und Löschen der ersten Bereitstellung
Dieses Video zeigt Ihnen, wie Sie mit Azure Machine Learning Studio loslegen, um den Schritten des Tutorials folgen zu können. Das Video zeigt, wie Sie ein Notebook erstellen, eine Computeinstanz erstellen und das Notebook klonen. Die Schritte sind in den folgenden Abschnitten beschrieben.
Voraussetzungen
-
Für die Verwendung von Azure Machine Learning benötigen Sie einen Arbeitsbereich. Wenn Sie noch keinen haben, schließen Sie Erstellen von Ressourcen, die Sie für die ersten Schritte benötigen ab, um einen Arbeitsbereich zu erstellen, und mehr über dessen Verwendung zu erfahren.
Wichtig
Wenn Ihr Azure Machine Learning-Arbeitsbereich mit einem verwalteten virtuellen Netzwerk konfiguriert ist, müssen Sie möglicherweise Ausgangsregeln hinzufügen, um den Zugriff auf die öffentlichen Python-Paketrepositorys zu ermöglichen. Weitere Informationen finden Sie unter Szenario: Zugreifen auf öffentliche Machine Learning-Pakete.
-
Melden Sie sich bei Studio an, und wählen Sie Ihren Arbeitsbereich aus, falls dieser noch nicht geöffnet ist.
-
Öffnen oder erstellen Sie ein neues Notebook in Ihrem Arbeitsbereich:
- Wenn Sie Code in Zellen kopieren und einfügen möchten, erstellen Sie ein neues Notebook.
- Alternativ öffnen Sie im Abschnitt Beispiele in Studio die Datei tutorials/get-started-notebooks/deploy-model.ipynb. Wählen Sie dann Klonen aus, um das Notebook zu Ihren Dateien hinzuzufügen. Informationen zum Suchen nach Beispielnotebooks finden Sie unter Lernen aus Beispielnotebooks.
Zeigen Sie Ihr VM-Kontingent an, und vergewissern Sie sich, dass genügend Kapazität für die Erstellung von Onlinebereitstellungen verfügbar ist. Für dieses Tutorial benötigen Sie mindestens 8 Kerne des Typs
STANDARD_DS3_v2und 12 Kerne des TypsSTANDARD_F4s_v2. Informationen zum Anzeigen der VM-Kontingentnutzung und zum Beantragen von Kontingenterhöhungen finden Sie unter Verwalten von Ressourcenkontingenten.
Festlegen des Kernels und Öffnen in Visual Studio Code (VS Code)
Erstellen Sie auf der oberen Leiste über Ihrem geöffneten Notizbuch eine Compute-Instanz, falls Sie noch keine besitzen.

Wenn die Compute-Instanz beendet wurde, wählen Sie Compute starten aus, und warten Sie, bis sie ausgeführt wird.

Warten Sie, bis die Compute-Instanz ausgeführt wird. Vergewissern Sie sich dann, dass sich rechts oben der Kernel
Python 3.10 - SDK v2befindet. Falls nicht, verwenden Sie die Dropdownliste, um diesen Kernel auszuwählen.
Falls dieser Kernel nicht angezeigt wird, überprüfen Sie, ob Ihre Compute-Instanz ausgeführt wird. Falls ja, wählen Sie rechts oben im Notebook die Schaltfläche Aktualisieren aus.
Wenn Sie ein Banner mit dem Hinweis sehen, dass Sie authentifiziert werden müssen, wählen Sie Authentifizieren aus.
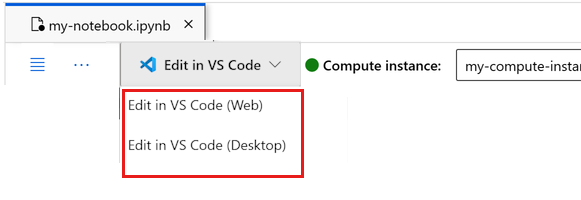
Sie können das Notebook hier ausführen oder es in VS Code öffnen, um eine vollständig integrierte Entwicklungsumgebung (Integrated Development Environment, IDE) mit der Leistungsfähigkeit von Azure Machine Learning-Ressourcen nutzen zu können. Wählen Sie In VS Code öffnen und dann unter „In VS Code bearbeiten“ entweder die Option „Web“ oder „Desktop“ aus. Wenn Sie den VS Code-Editor auf diese Weise starten, wird er an Ihre Compute-Instanz, den Kernel und das Dateisystem des Arbeitsbereichs angefügt.




Wichtig
Der Rest dieses Tutorials enthält Zellen des Tutorial-Notebooks. Kopieren Sie diese und fügen sie in Ihr neues Notebook ein, oder wechseln Sie jetzt zum Notebook, wenn Sie es geklont haben.
Hinweis
- Für Serverless Spark Compute ist
Python 3.10 - SDK v2standardmäßig nicht installiert. Wir empfehlen, dass Benutzer eine Compute-Instanz erstellen und auswählen, bevor Sie mit dem Tutorial fortfahren.
Erstellen eines Handles für den Arbeitsbereich
Bevor Sie sich genauer mit dem Code befassen, benötigen Sie eine Möglichkeit, um auf Ihren Arbeitsbereich zu verweisen. Erstellen Sie ml_client ein Handle für den Arbeitsbereich, und verwenden Sie die ml_client zum Verwalten von Ressourcen und Aufträgen.
Geben Sie in der nächsten Zelle Ihre Abonnement-ID, den Namen der Ressourcengruppe und den Namen des Arbeitsbereichs ein. So finden Sie diese Werte:
- Wählen Sie auf der oben rechts angezeigten Azure Machine Learning Studio-Symbolleiste den Namen Ihres Arbeitsbereichs aus.
- Kopieren Sie den Wert für Arbeitsbereich, Ressourcengruppe und Abonnement-ID in den Code.
- Sie müssen einen Wert kopieren, den Bereich schließen und einfügen und den Vorgang dann für den nächsten wiederholen.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Hinweis
Beim Erstellen von MLClient wird keine Verbindung mit dem Arbeitsbereich hergestellt. Die Clientinitialisierung erfolgt verzögert, d. h., es wird abgewartet, bis das erste Mal ein Aufruf erforderlich ist (dies geschieht in der nächsten Codezelle).
Registrieren des Modells
Wenn Sie das vorherige Trainingstutorial Trainieren eines Modells bereits abgeschlossen haben, haben Sie im Rahmen des Trainingsskripts bereits ein MLflow-Modell registriert und können zum nächsten Abschnitt übergehen.
Wenn Sie das Trainingstutorial noch nicht bearbeitet haben, müssen Sie das Modell registrieren. Es wird empfohlen, Ihr Modell vor der Bereitstellung zu registrieren.
Der folgende Code gibt die path Inline an (wo Dateien hochgeladen werden sollen). Wenn Sie den Ordner mit den Tutorials geklont haben, dann führen Sie den folgenden Code ohne Änderungen aus. Laden Sie andernfalls die Dateien und Metadaten für das Modell aus dem Ordner credit_defaults_model herunter. Speichern Sie die heruntergeladenen Dateien auf Ihrem Computer in einer lokalen Version des Ordners credit_defaults_model, und aktualisieren Sie den Pfad im folgenden Code so, dass er auf den Speicherort der heruntergeladenen Dateien verweist.
Das SDK lädt die Dateien automatisch hoch und registriert das Modell.
Weitere Informationen zum Registrieren Ihres Modells als Ressource finden Sie unter Registrieren Ihres Modells als Ressource in Machine Learning mithilfe des SDK.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Bestätigen der Modellregistrierung
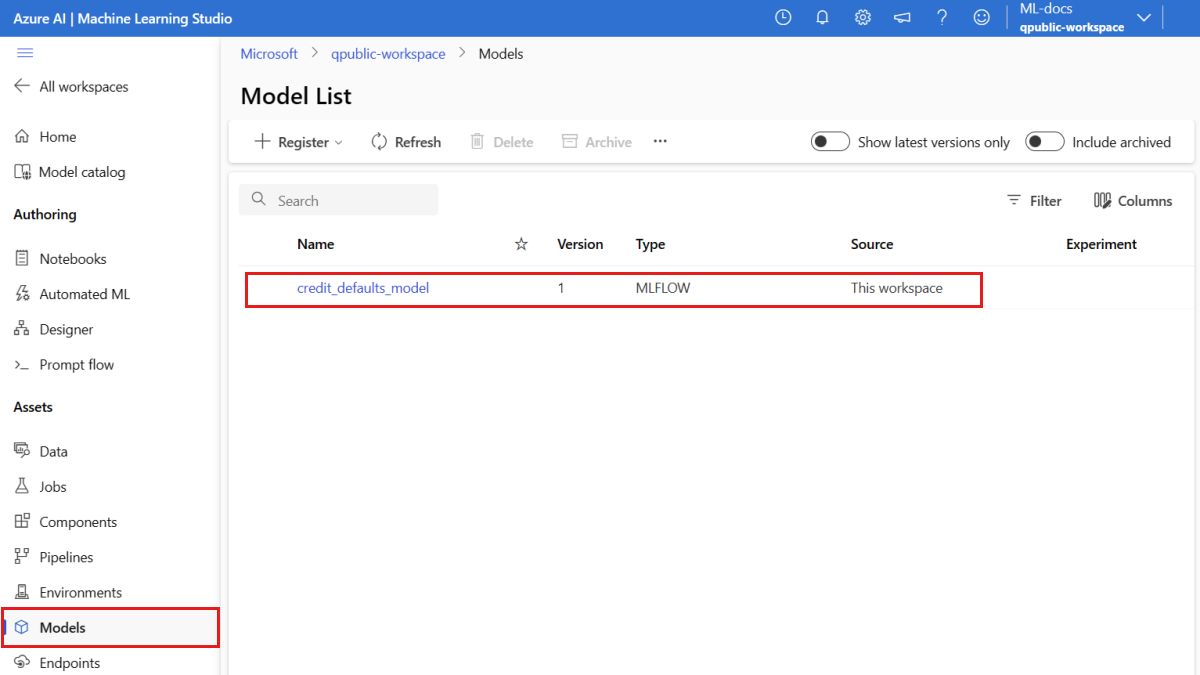
Sie können die Seite Modelle in Azure Machine Learning Studio aufrufen, um die aktuelle Version des registrierten Modells zu ermitteln.
Alternativ ruft der folgende Code die neueste Versionsnummer für Sie ab.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Nachdem Sie nun über ein registriertes Modell verfügen, können Sie einen Endpunkt und eine Bereitstellung erstellen. Im nächsten Abschnitt gehen wir kurz auf einige wichtige Details zu diesen Themen ein.
Endpunkte und Bereitstellungen
Nachdem Sie ein Machine Learning-Modell trainiert haben, müssen Sie es bereitstellen, damit andere es zum Rückschließen verwenden können. Zu diesem Zweck können Sie mit Azure Machine Learning Endpunkte erstellen und diesen Bereitstellungen hinzufügen.
Ein Endpunkt ist in diesem Zusammenhang ein HTTPS-Pfad, der eine Schnittstelle für Clients bietet, um Anforderungen (Eingabedaten) an ein trainiertes Modell zu senden und die Rückschlussergebnisse (Bewertungen) vom Modell zu empfangen. Ein Endpunkt bietet Folgendes:
- Authentifizierung mit einer auf Schlüssel oder Token basierenden Authentifizierung
- TLS- bzw. SSL-Terminierung
- Stabilen Bewertungs-URI (endpoint-name.region.inference.ml.azure.com)
Eine Einrichtung ist ein Satz von Ressourcen, die für das Hosting des Modells erforderlich sind, das die eigentliche Inferenz durchführt.
Ein einzelner Endpunkt kann mehrere Bereitstellungen enthalten. Endpunkte und Bereitstellungen sind unabhängige Azure Resource Manager-Ressourcen, die im Azure-Portal angezeigt werden.
Mit Azure Machine Learning können Sie Onlineendpunkte für Echtzeitrückschlüsse zu Kundendaten und Batchendpunkte für Rückschlüsse zu großen Datenmengen über einen bestimmten Zeitraum implementieren.
In diesem Tutorial werden Sie durch die Schritte zur Implementierung eines verwalteten Onlineendpunkts geführt. Verwaltete Onlineendpunkte nutzen leistungsstarke CPU- und GPU-Computer in Azure, die skalierbar sind und vollständig verwaltet werden. Auf diese Weise müssen Sie sich nicht um die Einrichtung und Verwaltung der zugrunde liegenden Bereitstellungsinfrastruktur kümmern.
Erstellen eines Onlineendpunkts
Da Sie nun über ein registriertes Modell verfügen, ist es an der Zeit, Ihren Onlineendpunkt zu erstellen. Der Endpunktname muss innerhalb der Azure-Region eindeutig sein. Im Rahmen dieses Tutorials erstellen Sie einen eindeutigen Namen mit einem universell eindeutigen Bezeichner (UUID). Weitere Informationen zu den Benennungsregeln für Endpunkte finden Sie unter Endpunktgrenzwerte.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Zunächst definieren Sie den Endpunkt mithilfe der ManagedOnlineEndpoint-Klasse.
Tipp
auth_mode: Verwenden Siekeyfür die schlüsselbasierte Authentifizierung. Verwenden Sieaml_tokenfür die tokenbasierte Azure Machine Learning-Authentifizierung. Einkeyläuft nicht ab, dafür aberaml_token. Weitere Informationen zur Authentifizierung finden Sie unter Authentifizieren von Clients bei einem Onlineendpunkt.Optional können Sie eine Beschreibung und Tags zu Ihrem Endpunkt hinzufügen.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
Mithilfe des zuvor erstellten MLClient erstellen Sie jetzt den Endpunkt im Arbeitsbereich. Dieser Befehl startet die Endpunkterstellung und gibt eine Bestätigungsantwort zurück, während die Endpunkterstellung fortgesetzt wird.
Hinweis
Die Erstellung des Endpunkts nimmt etwa 2 Minuten in Anspruch.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Wenn Sie den Endpunkt erstellt haben, können Sie ihn wie folgt abrufen:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Grundlegendes zu Onlinebereitstellungen
Zu den wichtigsten Aspekten einer Bereitstellung gehören folgende:
-
name– Name der Bereitstellung -
endpoint_name: Name des Endpunkts, der die Bereitstellung enthalten wird. -
model– Das für die Bereitstellung zu verwendende Modell. Dieser Wert kann entweder ein Verweis auf ein vorhandenes versioniertes Modell im Arbeitsbereich oder eine Inline-Modellspezifikation sein. -
environment: Die Umgebung, die für die Bereitstellung (oder zum Ausführen des Modells) verwendet werden soll. Dieser Wert kann entweder ein Verweis auf eine vorhandene versionierte Umgebung im Arbeitsbereich oder eine Inline-Umgebungsspezifikation sein. Die Umgebung kann ein Docker-Image mit Conda-Abhängigkeiten oder ein Dockerfile sein. -
code_configuration: Die Konfiguration für den Quellcode und das Bewertungsskript.-
path: Der Pfad zum Quellcodeverzeichnis für die Bewertung des Modells. -
scoring_script: Der relative Pfad zur Bewertungsdatei im Quellcodeverzeichnis. Dieses Skript führt das Modell für eine bestimmte Eingabeanforderung aus. Ein Beispiel für ein Bewertungsskript finden Sie unter Grundlegendes zum Bewertungsskript im Artikel „Bereitstellen eines ML-Modells mit einem Onlineendpunkt“.
-
-
instance_type– Die VM-Größe, die für die Bereitstellung verwendet werden soll. Eine Liste der unterstützten Größen finden Sie unter SKU-Liste für verwaltete Onlineendpunkte. -
instance_count: Die Anzahl der Instanzen, die für die Bereitstellung verwendet werden sollen.
Bereitstellung mit einem MLflow-Modell
Azure Machine Learning unterstützt die No-Code-Bereitstellung von Modellen, die mit MLflow erstellt und protokolliert wurden. Das bedeutet, dass Sie bei der Modellbereitstellung kein Bewertungsskript oder eine Umgebung bereitstellen müssen, da Bewertungsskript und Umgebung beim Training eines MLflow-Modells automatisch generiert werden. Wenn Sie jedoch ein benutzerdefiniertes Modell verwenden, müssen Sie die Umgebung und das Bewertungsskript während der Bereitstellung angeben.
Wichtig
Wenn Sie Modelle normalerweise mithilfe von Bewertungsskripts und benutzerdefinierten Umgebungen bereitstellen und die gleiche Funktionalität mit MLflow-Modellen erreichen möchten, empfehlen wir Ihnen die Lektüre von Richtlinien für die Bereitstellung von MLflow-Modellen.
Bereitstellen des Modells für den Endpunkt
Sie erstellen zunächst eine einzelne Bereitstellung, die 100 % des eingehenden Datenverkehrs verarbeitet. Wählen Sie einen willkürlichen Farbnamen (blue) für die Bereitstellung aus. Verwenden Sie die ManagedOnlineDeployment-Klasse, um die Bereitstellung für den Endpunkt zu erstellen.
Hinweis
Sie müssen weder eine Umgebung noch ein Bewertungsskript angeben, da das bereitzustellende Modell ein MLflow-Modell ist.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
Mithilfe des zuvor erstellten MLClient erstellen wir nun die Bereitstellung im Arbeitsbereich. Dieser Befehl startet die Bereitstellungserstellung und gibt eine Bestätigungsantwort zurück, während die Bereitstellungserstellung fortgesetzt wird.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Überprüfen des Status des Endpunkts
Sie können den Status des Endpunkts überprüfen, um zu überprüfen, ob das Modell fehlerfrei bereitgestellt wurde:
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Testen des Endpunkts mit Beispieldaten
Nachdem das Modell auf dem Endpunkt bereitgestellt wurde, können Sie es nun für Rückschlüsse nutzen. Erstellen Sie zunächst eine Beispielanforderungsdatei, die dem Design folgt, das in der Ausführungsmethode im Bewertungsskript zu finden ist.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
Erstellen Sie nun die Datei im Verzeichnis „deploy“. In der folgenden Code-Zelle wird die Datei mithilfe von des IPython Magic-Befehls in das Verzeichnis geschrieben, das Sie gerade erstellt haben.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
Mithilfe des zuvor erstellten MLClient erhalten wir einen Handle für den Endpunkt. Sie können den Endpunkt mithilfe des invoke-Befehls mit den folgenden Parametern aufrufen:
-
endpoint_name– Name des Endpunkts -
request_file– Datei mit Anforderungsdaten -
deployment_name– Name der spezifischen Bereitstellung, die in einem Endpunkt getestet werden soll
Testen Sie die Bereitstellung „blue“ mit den Beispieldaten.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Abrufen von Protokollen zur Bereitstellung
Überprüfen Sie die Protokolle, um festzustellen, ob der Endpunkt/die Bereitstellung erfolgreich aufgerufen wurde. Wenn Fehler auftreten, lesen Sie die Problembehandlung bei der Bereitstellung von Onlineendpunkten.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Erstellen einer zweiten Bereitstellung
Stellen Sie das Modell als zweite Bereitstellung mit dem Namen green bereit. In der Praxis können Sie mehrere Bereitstellungen erstellen und deren Leistung vergleichen. Diese Bereitstellungen könnten unterschiedliche Versionen desselben Modells, ein anderes Modell oder eine leistungsfähigere Compute-Instanz verwenden.
In diesem Beispiel verwenden Sie dieselbe Modellversion mit einer leistungsfähigeren Compute-Instanz, die möglicherweise die Leistung verbessert.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Skalieren der Bereitstellung zur Verarbeitung von mehr Datenverkehr
Mithilfe des zuvor erstellten MLClient können Sie ein Handle für die green-Bereitstellung erhalten. Sie können sie dann skalieren, indem Sie die instance_count erhöhen oder mindern.
Im folgenden Code vergrößern Sie die VM-Instanz manuell. Es ist jedoch auch möglich, Onlineendpunkte automatisch zu skalieren. Die automatische Skalierung führt automatisch die richtige Menge an Ressourcen aus, um die Last für Ihre Anwendung zu bewältigen. Verwaltete Onlineendpunkte unterstützen die automatische Skalierung durch die Integration in die Funktion für die automatische Skalierung vom Azure Monitor. Informationen zum Konfigurieren der automatischen Skalierung finden Sie unter Automatisches Skalieren von Onlineendpunkten.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Aktualisieren der Datenverkehrszuordnung für Bereitstellungen
Sie können den Produktionsverkehr auf verschiedene Bereitstellungen aufteilen. Möglicherweise möchten Sie die green-Bereitstellung ebenso wie die blue-Bereitstellung zunächst anhand von Beispieldaten testen. Nachdem Sie Ihre Bereitstellung „green“ getestet haben, weisen Sie ihr einen kleinen Prozentsatz des Datenverkehrs zu.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Testen Sie die Zuordnung des Datenverkehrs, indem Sie den Endpunkt mehrmals aufrufen:
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Zeigen Sie die Protokolle der green-Bereitstellung an, um zu überprüfen, ob es eingehende Anforderungen gab und das Modell erfolgreich bewertet wurde.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Verwenden von Metriken mithilfe von Azure Monitor
Sie können in Studio über die Links auf der Seite Details für einen Endpunkt verschiedene Metriken (Anzahl der Anforderungen, Anforderungslatenz, Netzwerkbyte, CPU-/GPU-/Datenträger-/Arbeitsspeicherauslastung und mehr) für einen Onlineendpunkt und dessen Bereitstellungen anzeigen. Wenn Sie diesen Links folgen, gelangen Sie zur Metrikseite im Azure-Portal für den Endpunkt oder die Bereitstellung.

Wenn Sie die Metriken für den Onlineendpunkt öffnen, können Sie die Seite so einrichten, dass Metriken wie beispielsweise die durchschnittliche Anforderungslatenz angezeigt werden (siehe folgende Abbildung).

Weitere Informationen zum Anzeigen von Metriken zu Onlineendpunkten finden Sie unter Überwachen von Onlineendpunkten.
Senden des gesamten Datenverkehrs an die neue Bereitstellung
Wenn Sie mit der green-Bereitstellung zufrieden sind, können Sie den gesamten Datenverkehr auf sie umstellen.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Entfernen der alten Bereitstellung
Entfernen Sie die alte Bereitstellung („blue“):
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Bereinigen von Ressourcen
Wenn Sie den Endpunkt und die Bereitstellung nach Abschluss dieses Tutorials nicht mehr benötigen, sollten Sie sie löschen.
Hinweis
Der vollständige Löschvorgang dauert ungefähr 20 Minuten.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Alles löschen
Verwenden Sie diese Schritte, um Ihren Azure Machine Learning-Arbeitsbereich und alle Computeressourcen zu löschen.
Wichtig
Die von Ihnen erstellten Ressourcen können ggf. auch in anderen Azure Machine Learning-Tutorials und -Anleitungen verwendet werden.
Wenn Sie die erstellten Ressourcen nicht mehr benötigen, löschen Sie diese, damit Ihnen keine Kosten entstehen:
Geben Sie im Azure-Portal den Suchbegriff Ressourcengruppen in das Suchfeld ein, und wählen Sie in den Ergebnissen die entsprechende Option aus.
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie auf der Seite Übersicht die Option Ressourcengruppe löschen aus.
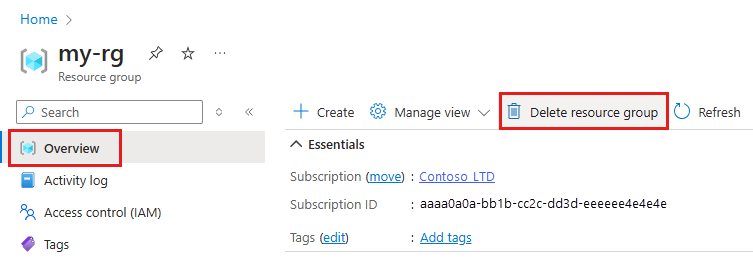
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.