Übermitteln von Spark-Aufträgen in Azure Machine Learning
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure Machine Learning unterstützt die Übermittlung eigenständiger Aufträge für maschinelles Lernen (Machine Learning, ML) und die Erstellung von Machine Learning-Pipelines, die mehrere Machine Learning-Workflowschritte umfassen. Azure Machine Learning übernimmt sowohl die Erstellung von eigenständigen Spark-Aufträgen als auch die Erstellung wiederverwendbarer Spark-Komponenten, die von Azure Machine Learning-Pipelines verwendet werden können. In diesem Artikel erfahren Sie, wie Sie Spark-Aufträge mit den folgenden Tools übermitteln:
- Benutzeroberfläche von Azure Machine Learning Studio
- Azure Machine Learning-CLI
- Azure Machine Learning SDK
Für weitere Informationen zu Apache Spark in Azure Machine Learning-Konzepten besuchen Sie diese Ressource.
Voraussetzungen
GILT FÜR Azure CLI-ML-Erweiterung v2 (aktuell)
- Ein Azure-Abonnement: Sollten Sie über kein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Ein Azure Machine Learning-Arbeitsbereich. Weitere Informationen finden Sie unter Erstellen von Arbeitsbereichsressourcen.
- Erstellen Sie eine Azure Machine Learning-Compute-Instanz.
- Installieren Sie die Azure Machine Learning-CLI (Command Line Interface, Befehlszeilenschnittstelle).
- (Optional:) Ein angefügter Synapse Spark-Pool im Azure Machine Learning-Arbeitsbereich
Hinweis
- Weitere Informationen zum Ressourcenzugriff bei der Verwendung von serverlosem Azure Machine Learning-Spark-Computing und eines angefügten Synapse Spark-Pools finden Sie unter Sicherstellen des Ressourcenzugriffs für Spark-Aufträge.
- Azure Machine Learning bietet einen freigegebenen Kontingentpool, über den alle Benutzer auf das Computekontingent zugreifen können, um Tests für einen begrenzten Zeitraum durchzuführen. Wenn Sie die serverlose Spark-Computing verwenden, können Sie mit Azure Machine Learning für kurze Zeit auf dieses freigegebene Kontingent zugreifen.
Anfügen einer benutzerseitig zugewiesenen verwalteten Identität mithilfe von CLI v2
- Erstellen Sie eine YAML-Datei, die die benutzerseitig zugewiesene verwaltete Identität definiert, die an den Arbeitsbereich angefügt werden soll:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - Verwenden Sie die YAML-Datei im
az ml workspace update-Befehl mit dem--file-Parameter, um die vom Benutzer zugewiesene verwaltete Identität anzufügen:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Anfügen einer benutzerseitig zugewiesenen verwalteten Identität mithilfe von ARMClient
- Installieren Sie
ARMClient, ein einfaches Befehlszeilentool, das die Azure Resource Manager-API aufruft. - Erstellen Sie eine JSON-Datei, die die benutzerseitig zugewiesene verwaltete Identität definiert, die an den Arbeitsbereich angefügt werden soll:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Führen Sie den folgenden Befehl an der PowerShell-Eingabeaufforderung oder der Eingabeaufforderung aus, um die vom Benutzer zugewiesene verwaltete Identität an den Arbeitsbereich anzufügen.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Hinweis
- Um eine erfolgreiche Ausführung des Spark-Auftrags sicherzustellen, weisen Sie der Identität, die für den Spark-Auftrag verwendet wird, die Rollen Mitwirkender und Mitwirkender für Speicherblobdaten für das Azure-Speicherkonto zu, das für die Dateneingabe und -ausgabe verwendet wird.
- Der öffentliche Netzwerkzugriff muss im Azure Synapse-Arbeitsbereich aktiviert sein, um eine erfolgreiche Ausführung des Spark-Auftrags mithilfe eines angefügten Synapse Spark-Pools sicherzustellen.
- Wenn in einem Azure Synapse-Arbeitsbereich, dem ein verwaltetes virtuelles Netzwerk zugeordnet ist, ein angefügter Synapse Spark-Pool auf einen Synapse Spark-Pool verweist, sollten Sie einen verwalteten privaten Endpunkt für das Speicherkonto konfigurieren, um den Zugriff auf die Daten sicherzustellen.
- Serverlose Spark-Computevorgänge unterstützen ein verwaltetes virtuelles Netzwerk für Azure Machine Learning. Wenn ein verwaltetes Netzwerk für die serverlose Spark-Compute-Instanz bereitgestellt wird, sollten auch die entsprechenden privaten Endpunkte für das Speicherkonto bereitgestellt werden, um den Datenzugriff sicherzustellen.
Übermitteln eines eigenständigen Spark-Auftrags
Nachdem Sie die erforderlichen Änderungen für die Parametrisierung des Python-Skripts vorgenommen haben, können Sie ein mit interaktivem Data Wrangling entwickeltes Python-Skript verwenden, um einen Batchauftrag zum Verarbeiten größerer Datenmengen übermitteln. Sie können einen Data Wrangling-Batchauftrag als eigenständigen Spark-Auftrag übermitteln.
Ein Spark-Auftrag erfordert ein Python-Skript, das Argumente akzeptiert. Sie können den Python-Code ändern, der ursprünglich durch interaktives Data Wrangling entwickelt wurde, um dieses Skript zu erstellen. Ein Python-Beispielskript wird hier gezeigt.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Hinweis
Dieses Python-Codebeispiel verwendet pyspark.pandas. Dies wird nur von der Spark-Laufzeitversion 3.2 oder höher unterstützt.
Dieses Skript akzeptiert zwei Argumente, die den Pfad der Eingabedaten bzw. des Ausgabeordners übergeben:
--titanic_data--wrangled_data
GILT FÜR Azure CLI-ML-Erweiterung v2 (aktuell)
Um einen Auftrag zu erstellen, können Sie einen eigenständigen Spark-Auftrag als YAML-Spezifikationsdatei definieren, die Sie im Befehl az ml job create mit dem Parameter --file verwenden können. Definieren Sie diese Eigenschaften in der YAML-Datei:
YAML-Eigenschaften in der Spark-Auftragsspezifikation
type– festgelegt aufspark.code– definiert den Speicherort des Ordners, der Quellcode und Skripte für diesen Job enthält.entry– definiert den Einstiegspunkt für den Auftrag. Es sollte eine der folgenden Eigenschaften abdecken:file– definiert den Namen des Python-Skripts, das als Einstiegspunkt für den Auftrag dient.class_name– definiert den Namen der Klasse, die als Einstiegspunkt für den Auftrag dient.
py_files– definiert eine Liste von den Dateien.zip,.egg, oder.py, die für die erfolgreiche Ausführung des Auftrags inPYTHONPATHplatziert werden sollen. Diese Eigenschaft ist optional.jars– definiert eine Liste der Dateien.jar, die für die erfolgreiche Ausführung des Auftrags in den Spark-Treiber und den ExecutorCLASSPATHeingeschlossen werden sollen. Diese Eigenschaft ist optional.files– definiert eine Liste der Dateien, die für die erfolgreiche Auftragsausführung in das Arbeitsverzeichnis jedes Executors kopiert werden sollen. Diese Eigenschaft ist optional.archives– definiert eine Liste der Archive, die für die erfolgreiche Auftragsausführung in das Arbeitsverzeichnis jedes Executors extrahiert werden sollen. Diese Eigenschaft ist optional.conf– definiert die folgenden Spark-Treiber- und Executor-Eigenschaften:spark.driver.cores: die Anzahl der Kerne für den Spark-Treiber.spark.driver.memory: zugewiesener Arbeitsspeicher für den Spark-Treiber in Gigabyte (GB).spark.executor.cores: die Anzahl der Kerne für den Spark-Treiber.spark.executor.memory: die Speicherbelegung für den Spark-Executor in Gigabyte (GB).spark.dynamicAllocation.enabled– gibt an, ob Executors dynamisch als WertTrueoderFalsezugeordnet werden sollen.- Wenn die dynamische Zuordnung von Executors aktiviert ist, definieren Sie die folgenden Eigenschaften:
spark.dynamicAllocation.minExecutors– die Mindestanzahl von Spark-Executors-Instanzen für die dynamische Zuordnung.spark.dynamicAllocation.maxExecutors– die maximale Anzahl von Spark-Executors-Instanzen für die dynamische Zuordnung.
- Wenn die dynamische Zuordnung von Executors deaktiviert ist, definieren Sie diese Eigenschaft:
spark.executor.instances– die Anzahl der Spark-Executor-Instanzen.
environment– eine Azure Machine Learning-Umgebung zum Ausführen des Auftrags.args– die Befehlszeilenargumente, die an das Python-Skript des Auftragseinstiegspunkts übergeben werden sollten. Ein Beispiel finden Sie in der hier angegebenen YAML-Spezifikationsdatei.resources– diese Eigenschaft definiert die Ressourcen, die von einer serverlosen Spark-Computeversion (Vorschau) von Azure Machine Learning verwendet werden sollen. Es verfügt über folgende Eigenschaften:instance_type– der Compute-Instanztyp, der für den Spark-Pool verwendet werden soll. Folgende Instanztypen werden derzeit unterstützt:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version– definiert die Spark-Runtimeversion. Die folgenden Spark-Runtimeversionen werden derzeit unterstützt:3.33.4Wichtig
Azure Synapse-Runtime für Apache Spark: Ankündigungen
- Azure Synapse Runtime for Apache Spark 3.3:
- EOLA-Ankündigungsdatum: 12. Juli 2024
- Datum für Supportende: 31. März 2025. Nach diesem Datum wird die Runtime deaktiviert.
- Wenn Sie weiterhin Support erhalten und von optimaler Leistung profitieren möchten, empfehlen wir die Migration zu Apache Spark 3.4.
- Azure Synapse Runtime for Apache Spark 3.3:
Dies ist eine YAML-Beispieldatei:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute– diese Eigenschaft definiert den Namen eines angefügten Synapse Spark-Pools, wie in diesem Beispiel gezeigt:compute: mysparkpoolinputs– diese Eigenschaft definiert Eingaben für den Spark-Auftrag. Eingaben für einen Spark-Auftrag können entweder ein Literalwert oder gespeicherte Daten in einer Datei oder einem Ordner sein.- Ein Literalwert kann eine Zahl, ein boolescher Wert oder eine Zeichenfolge sein. Einige Beispiele sind hier dargestellt:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Gespeicherte Daten in einer Datei oder einem Ordner sollten mithilfe der folgenden Eigenschaften definiert werden:
type– legen Sie diese Eigenschaft für Eingabedaten, die in einer Datei oder einem Ordner enthalten sind, aufuri_fileoderuri_folderfest.path– der URI der Eingabedaten, z. B.azureml://,abfss://oderwasbs://.mode– legen Sie diese Eigenschaft aufdirectfest. Dieses Beispiel zeigt die Definition einer Auftragseingabe, die als$${inputs.titanic_data}}bezeichnet werden kann:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Ein Literalwert kann eine Zahl, ein boolescher Wert oder eine Zeichenfolge sein. Einige Beispiele sind hier dargestellt:
outputs– diese Eigenschaft definiert die Spark-Auftragsausgaben. Ausgaben für einen Spark-Auftrag können in eine Datei oder einen Ordnerspeicherort geschrieben werden, der mit den folgenden drei Eigenschaften definiert wird:type– Sie können diese Eigenschaft aufuri_fileoderuri_folderfestlegen, um Ausgabedaten in eine Datei bzw. einen Ordner zu schreiben.path– diese Eigenschaft definiert den Ausgabespeicherort-URI, z. B.azureml://,abfss://oderwasbs://.mode– legen Sie diese Eigenschaft aufdirectfest. Dieses Beispiel zeigt die Definition einer Auftragsausgabe, die als${{outputs.wrangled_data}}bezeichnet werden kann:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity– diese optionale Eigenschaft definiert die Identität, die zum Übermitteln dieses Auftrags verwendet wird. Es kann Werteuser_identityundmanagedaufweisen. Wenn die YAML-Spezifikation keine Identität definiert, verwendet der Spark-Auftrag die Standardidentität.
Eigenständiger Spark-Auftrag
Diese YAML-Beispielspezifikation zeigt einen eigenständigen Spark-Auftrag. Sie verwendet eine serverlose Spark-Computeversion von Azure Machine Learning:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Hinweis
Wenn Sie einen angefügten Synapse Spark-Pool verwenden möchten, definieren Sie im zuvor gezeigten Beispiel einer YAML-Spezifikationsdatei die Eigenschaft compute anstelle der Eigenschaft resources.
Sie können die zuvor gezeigten YAML-Dateien wie hier dargestellt im Befehl az ml job create mit dem Parameter --file verwenden, um einen eigenständigen Spark-Auftrag zu erstellen:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Sie können den obigen Befehl an folgenden Stellen ausführen:
- Terminal einer Azure Machine Learning-Compute-Instanz
- In einem Visual Studio Code-Terminal, das mit einer Azure Machine Learning-Compute-Instanz verbunden ist.
- Auf Ihrem lokalen Computer mit installierter Azure Machine Learning CLI
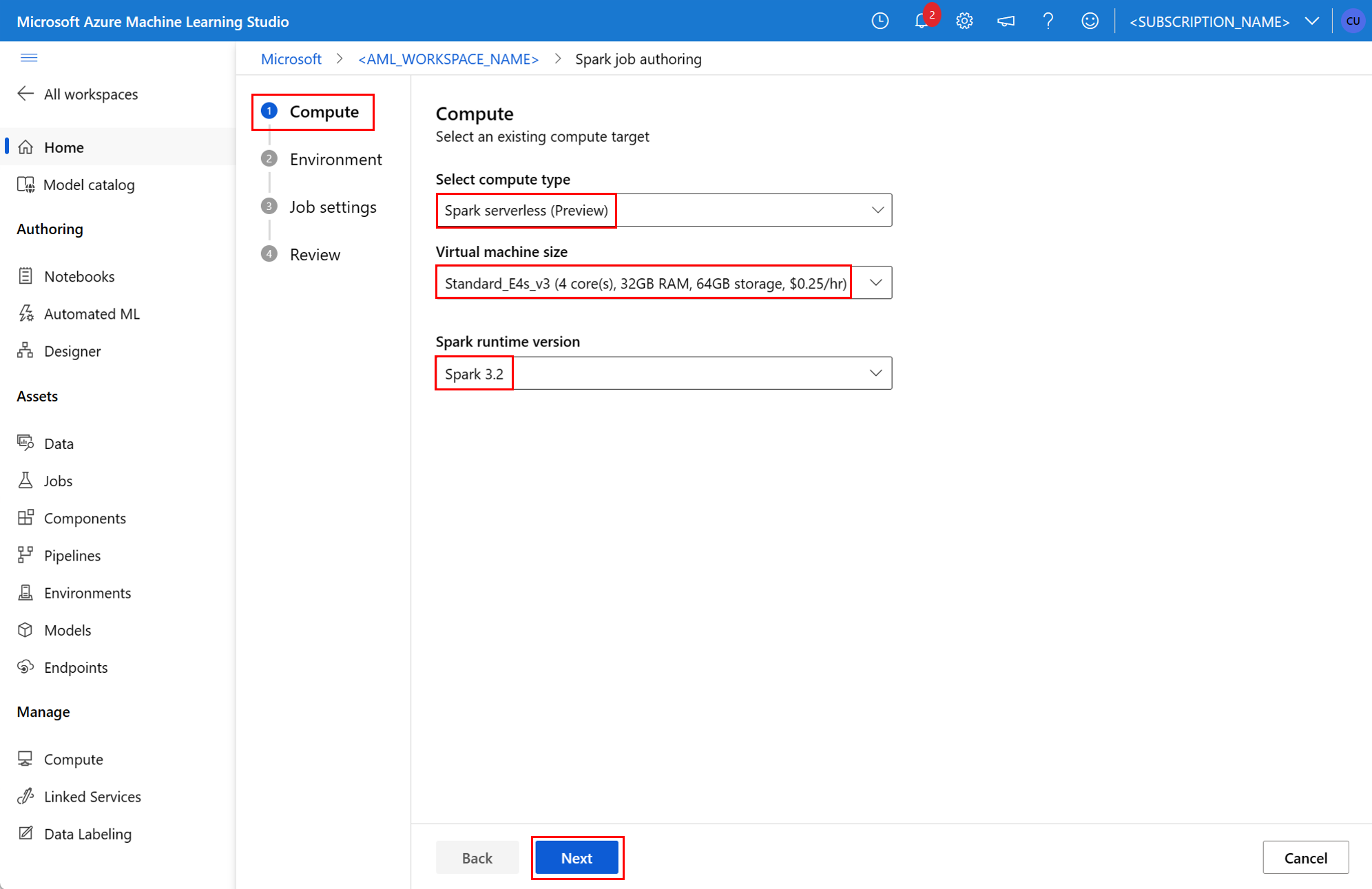
Spark-Komponente in einem Pipelineauftrag
Eine Spark-Komponente bietet die Flexibilität, dieselbe Komponente in mehreren Azure Machine Learning-Pipelines als Pipelineschritt zu verwenden.
GILT FÜR Azure CLI-ML-Erweiterung v2 (aktuell)
Die YAML-Syntax für eine Spark-Komponente ähnelt in den meisten Fällen der YAML-Syntax für die Spark-Auftragsspezifikation. Diese Eigenschaften werden in der YAML-Spezifikation der Spark-Komponente unterschiedlich definiert:
name– der Name der Spark-Komponente.version– die Version der Spark-Komponente.display_name– der Name der Spark-Komponente, die auf der Benutzeroberfläche und an anderer Stelle angezeigt werden soll.description– die Beschreibung der Spark-Komponente.inputs: Diese Eigenschaft ähnelt derinputs-Eigenschaft, die in der YAML-Syntax für die Spark-Auftragsspezifikation beschrieben wird, mit der Ausnahme, dass sie diepath-Eigenschaft nicht definiert. Dieser Codeausschnitt zeigt ein Beispiel für die Spark-Komponenteneigenschaftinputs:inputs: titanic_data: type: uri_file mode: directoutputs: Diese Eigenschaft ähnelt deroutputs-Eigenschaft, die in der YAML-Syntax für die Spark-Auftragsspezifikation beschrieben wird, mit der Ausnahme, dass sie diepath-Eigenschaft nicht definiert. Dieser Codeausschnitt zeigt ein Beispiel für die Spark-Komponenteneigenschaftoutputs:outputs: wrangled_data: type: uri_folder mode: direct
Hinweis
Eine Spark-Komponente definiert nicht die Eigenschaften identity, compute oder resources. Diese Eigenschaften sind in der YAML-Spezifikationsdatei der Pipeline definiert.
Diese YAML-Spezifikationsdatei enthält ein Beispiel für eine Spark-Komponente:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Sie können die in der obigen YAML-Spezifikationsdatei definierte Spark-Komponente in einem Azure Machine Learning-Pipelineauftrag verwenden. Weitere Informationen zur YAML-Syntax, die einen Pipelineauftrag definiert, finden Sie unter YAML-Schema für Pipelineaufträge. Dieses Beispiel zeigt eine YAML-Spezifikationsdatei für einen Pipelineauftrag mit einer Spark-Komponente und einer serverlosen Spark-Computeversion von Azure Machine Learning:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Hinweis
Wenn Sie einen angefügten Synapse Spark-Pool verwenden möchten, definieren Sie im oben gezeigten Beispiel einer YAML-Spezifikationsdatei die Eigenschaft compute anstelle der Eigenschaft resources.
Sie können die obige YAML-Spezifikationsdatei wie hier gezeigt im Befehl az ml job create mit dem Parameter --file verwenden, um einen Pipelineauftrag zu erstellen:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Sie können den obigen Befehl an folgenden Stellen ausführen:
- das Terminal einer Azure Machine Learning-Compute-Instanz.
- In einem Visual Studio Code-Terminal, das mit einer Azure Machine Learning-Compute-Instanz verbunden ist.
- Auf Ihrem lokalen Computer mit installierter Azure Machine Learning CLI
Problembehandlung bei Spark-Aufträgen
Um Probleme mit einem Spark-Auftrag zu behandeln, können Sie auf die Protokolle zugreifen, die für diesen Auftrag in Azure Machine Learning Studio generiert wurden. So zeigen Sie die Protokolle für einen Spark-Auftrag an
- Navigieren Sie im linken Bereich auf der Azure Machine Learning Studio-Benutzeroberfläche zu Aufträge.
- Wählen Sie die Registerkarte Alle Aufträge aus.
- Wählen Sie den Wert Anzeigename für den Auftrag aus.
- Wählen Sie auf der Auftragsdetailseite die Registerkarte Ausgabe + Protokolle aus.
- Erweitern Sie im Datei-Explorer den Ordner logs, und erweitern Sie dann den Ordner azureml.
- Sie können auf die Spark-Auftragsprotokolle in den Ordnern driver und library manager zugreifen.
Hinweis
Um Probleme mit Spark-Aufträgen zu behandeln, die während des interaktiven Data Wrangling in einer Notebooksitzung erstellt wurden, wählen Sie Auftragsdetails in der oberen rechten Ecke der Notebook-Benutzeroberfläche aus. Ein Spark-Auftrag aus einer interaktiven Notebooksitzung wird unter dem Experimentnamen notebook-runs erstellt.