Führen Sie die sichere Bereitstellung neuer Anwendungen für Echtzeitrückschlüsse durch.
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie in der Produktion eine neue Version eines Machine Learning-Modells bereitstellen können, ohne dass es zu Unterbrechungen kommt. Sie verwenden die Blau-Grün-Bereitstellungsstrategie (auch sichere Rolloutstrategie genannt), um eine neue Version eines Webdiensts in der Produktion einzuführen. Mit dieser Strategie können Sie Ihre neue Version des Webdiensts für eine kleine Teilmenge von Benutzern oder Anforderungen bereitstellen, bevor Sie sie vollständig einführen.
In diesem Artikel wird davon ausgegangen, dass Sie Onlineendpunkte verwenden, d. h. Endpunkte, die für Onlinerückschlüsse (in Echtzeit) verwendet werden. Es gibt zwei Arten von Onlineendpunkten: Verwaltete Onlineendpunkte und Kubernetes-Onlineendpunkte. Weitere Informationen zu Endpunkten und den Unterschieden zwischen verwalteten Onlineendpunkten und Kubernetes-Onlineendpunkten finden Sie unter Was sind Azure Machine Learning-Endpunkte?.
Im Hauptbeispiel in diesem Artikel werden verwaltete Online-Endpunkte für die Bereitstellung verwendet. Wenn Sie stattdessen Kubernetes-Endpunkte verwenden möchten, lesen Sie die Hinweise in diesem Dokument im Zusammenhang mit der Diskussion über verwaltete Onlineendpunkte.
In diesem Artikel lernen Sie Folgendes:
- Definieren eines Onlineendpunkts mit einer Bereitstellung namens „Blau“, um Version 1 eines Modells bereitzustellen
- Skalieren der Blau-Bereitstellung, damit mehr Anforderungen verarbeitet werden können
- Bereitstellen der Version 2 des Modells (als „Grün“-Bereitstellung bezeichnet) für den Endpunkt bereit, jedoch ohne Senden von Livedatenverkehr an die Bereitstellung
- Isoliertes Testen der Bereitstellung „green“
- Spiegeln eines Prozentsatzes des Livedatenverkehrs an die Grün-Bereitstellung, um sie zu überprüfen
- Senden eines geringen Prozentsatzes des Livedatenverkehrs an die Grün-Bereitstellung
- Senden des gesamten Livedatenverkehrs an die Grün-Bereitstellung
- Löschen der nun nicht mehr genutzten ersten Bereitstellung „blue“
Voraussetzungen
Stellen Sie vor dem Ausführen der Schritte in diesem Artikel sicher, dass Sie über die folgenden erforderlichen Komponenten verfügen:
Die Azure CLI und die
ml-Erweiterung der Azure CLI. Weitere Informationen finden Sie unter Installieren, Einrichten und Verwenden der CLI (v2).Wichtig
In den CLI-Beispielen in diesem Artikel wird davon ausgegangen, dass Sie die Bash-Shell (oder eine kompatible Shell) verwenden, beispielsweise über ein Linux-System oder ein Windows-Subsystem für Linux.
Ein Azure Machine Learning-Arbeitsbereich. Sofern noch nicht vorhanden, führen Sie die Schritte im Abschnitt Installieren, Einrichten und Verwenden der CLI (v2) aus, um einen Arbeitsbereich zu erstellen.
Die rollenbasierte Zugriffssteuerung in Azure (Azure RBAC) wird verwendet, um Zugriff auf Vorgänge in Azure Machine Learning zu gewähren. Um die Schritte in diesem Artikel auszuführen, muss Ihr Benutzerkonto der Rolle Besitzer oder Mitwirkender für den Azure Machine Learning-Arbeitsbereich bzw. einer benutzerdefinierte Rolle zugewiesen werden, die
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*zulässt. Weitere Informationen finden Sie unter Zugriff auf einen Azure Machine Learning-Arbeitsbereich verwalten.(Optional) Zur lokalen Bereitstellung müssen Sie die Docker-Engine auf Ihrem lokalen Computer installieren. Diese Option wird dringend empfohlen, um das Debuggen von Problemen zu vereinfachen.
Vorbereiten Ihres Systems
Festlegen von Umgebungsvariablen
Wenn Sie die Standardeinstellungen für die Azure-Befehlszeilenschnittstelle noch nicht festgelegt haben, speichern Sie Ihre Standardeinstellungen. Um zu vermeiden, dass Sie die Werte für Ihr Abonnement, Ihren Arbeitsbereich und Ihre Ressourcengruppe mehrfach eingeben müssen, führen Sie den folgenden Code aus:
az account set --subscription <subscription id>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Klonen des Beispielrepositorys
Klonen Sie zunächst das Beispielrepository (azureml-examples), um diesem Artikel zu folgen. Wechseln Sie dann zum Verzeichnis cli/ des Repositorys:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
cd cli
Tipp
Verwenden Sie --depth 1, um nur den letzten Commit in das Repository zu klonen. Dadurch wird die Zeit zum Abschließen des Vorgangs reduziert.
Die in diesem Tutorial verwendeten Befehle befinden sich in der Datei deploy-safe-rollout-online-endpoints.sh im Verzeichnis cli, und die YAML-Konfigurationsdateien finden Sie im Unterverzeichnis endpoints/online/managed/sample/.
Hinweis
Die YAML-Konfigurationsdateien für Kubernetes-Onlineendpunkte befinden sich im Unterverzeichnis endpoints/online/kubernetes/.
Definieren des Endpunkts und der Bereitstellung
Onlineendpunkte sind Endpunkte, die für Onlinerückschlüsse (in Echtzeit) verwendet werden. Onlineendpunkte enthalten Bereitstellungen, die bereit sind, Daten von Clients zu empfangen und Antworten in Echtzeit zurückzusenden.
Definieren eines Endpunkts
In der folgenden Tabelle sind wichtige Attribute aufgeführt, die beim Definieren eines Endpunkts angegeben werden müssen.
| attribute | Beschreibung |
|---|---|
| Name | Erforderlich. Name des Endpunkts. Er muss in der Azure-Region eindeutig sein. Weitere Informationen zu den Benennungsregeln finden Sie unter Endpunktgrenzwerte. |
| Authentifizierungsmodus | Die Authentifizierungsmethode für den Endpunkt Wählen Sie zwischen schlüsselbasierter Authentifizierung (key) und tokenbasierter Azure Machine Learning-Authentifizierung (aml_token). Ein Schlüssel läuft nicht ab, ein Token dagegen schon. Weitere Informationen zur Authentifizierung finden Sie unter Authentifizieren bei einem Onlineendpunkt. |
| BESCHREIBUNG | Eine Beschreibung des Endpunkts |
| Tags | Wörterbuch der Tags für den Endpunkt |
| Verkehr | Regeln zur bereitstellungsübergreifenden Weiterleitung von Datenverkehr. Der Datenverkehr wird als Wörterbuch mit Schlüssel-Wert-Paaren dargestellt, bei denen der Schlüssel den Bereitstellungsnamen und der Wert den Prozentsatz des Datenverkehrs für die entsprechende Bereitstellung darstellt. Der Datenverkehr kann erst festgelegt werden, wenn die Bereitstellungen unter einem Endpunkt erstellt wurden. Außerdem können Sie den Datenverkehr für einen Onlineendpunkt aktualisieren, nachdem die Bereitstellungen erstellt wurden. Weitere Informationen zur Verwendung von gespiegeltem Datenverkehr finden Sie unter Zuordnen eines geringen Prozentsatzes des Livedatenverkehrs zur neuen Bereitstellung. |
| Spiegeln des Datenverkehrs | Prozentsatz des Livedatenverkehrs, der in eine Bereitstellung gespiegelt werden soll. Weitere Informationen zur Verwendung von gespiegeltem Datenverkehr finden Sie unter Testen der Bereitstellung mit gespiegeltem Datenverkehr. |
Eine vollständige Liste der Attribute, die Sie beim Erstellen eines Endpunkts angeben können, finden Sie unter CLI (v2): YAML-Schema für Onlineendpunkt bzw. unter ManagedOnlineEndpoint Class (Klasse „ManagedOnlineEndpoint“).
Definieren einer Bereitstellung
Eine Einrichtung ist ein Satz von Ressourcen, die für das Hosting des Modells erforderlich sind, das die eigentliche Inferenz durchführt. In der folgenden Tabelle werden Schlüsselattribute beschrieben, die beim Definieren einer Bereitstellung angegeben werden müssen.
| attribute | Beschreibung |
|---|---|
| Name | Erforderlich. Name der Bereitstellung |
| Endpunktname | Erforderlich. Name des Endpunkts, unter dem die Bereitstellung erstellt werden soll. |
| Modell | Das für die Bereitstellung zu verwendende Modell. Dieser Wert kann entweder ein Verweis auf ein vorhandenes versioniertes Modell im Arbeitsbereich oder eine Inline-Modellspezifikation sein. In diesem Beispiel verwenden wir ein scikit-learn-Modell, das Regressionen durchführt. |
| Codepfad | Der Pfad zu dem Verzeichnis in der lokalen Entwicklungsumgebung, das den gesamten Python-Quellcode für die Bewertung des Modells enthält. Sie können geschachtelte Verzeichnisse und Pakete verwenden. |
| „Scoring script“ (Bewertungsskript) | Python-Code, der das Modell für eine bestimmte Eingabeanforderung ausführt. Dieser Wert kann der relative Pfad zur Bewertungsdatei im Quellcodeverzeichnis sein. Das Bewertungsskript empfängt an einen bereitgestellten Webdienst übermittelte Daten und übergibt sie an das Modell. Anschließend führt das Skript das Modell aus und gibt dessen Antwort an den Client zurück. Das Bewertungsskript ist modellspezifisch und muss die Daten verstehen, die das Modell als Eingabe erwartet und als Ausgabe zurückgibt. In diesem Beispiel wird die Datei score.py verwendet. Dieser Python-Code muss über eine init()- und eine run()-Funktion verfügen. Die Funktion init() wird aufgerufen, nachdem das Modell erstellt oder aktualisiert wurde. (Sie kann verwendet werden, um das Modell z. B. im Arbeitsspeicher zwischenzuspeichern.) Die Funktion run() wird bei jedem Aufruf des Endpunkts aufgerufen, um die tatsächliche Bewertung und Vorhersage auszuführen. |
| Umgebung | Erforderlich. Die Umgebung zum Hosten des Modells und des Codes. Dieser Wert kann entweder ein Verweis auf eine vorhandene versionierte Umgebung im Arbeitsbereich oder eine Inline-Umgebungsspezifikation sein. Die Umgebung kann ein Docker-Image mit Conda-Abhängigkeiten, ein Dockerfile oder eine registrierte Umgebung sein. |
| Instanztyp | Erforderlich. Die VM-Größe, die für die Bereitstellung verwendet werden soll. Eine Liste der unterstützten Größen finden Sie unter SKU-Liste für verwaltete Onlineendpunkte. |
| Anzahl von Instanzen | Erforderlich. Die Anzahl der Instanzen, die für die Bereitstellung verwendet werden sollen. Richten Sie den Wert nach der zu erwartenden Workload. Für Hochverfügbarkeit empfiehlt es sich, den Wert mindestens auf 3 festzulegen. Wir reservieren zusätzliche 20 % für die Durchführung von Upgrades. Weitere Informationen finden Sie unter Grenzwerte für Onlineendpunkte. |
Eine vollständige Liste der Attribute, die Sie beim Erstellen einer Bereitstellung angeben können, finden Sie unter CLI (v2) verwaltete Onlinebereitstellung: YAML-Schema bzw. unter ManagedOnlineDeployment Class (Klasse „ManagedOnlineDeployment“).
Erstellen eines Onlineendpunkts
Legen Sie zunächst den Namen des Endpunkts fest, und konfigurieren Sie ihn. In diesem Artikel wird die Datei endpoints/online/managed/sample/endpoint.yml verwendet, um den Endpunkt zu konfigurieren. Der folgende Codeschnipsel zeigt den Inhalt der Datei:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
Die Referenz für das YAML-Endpunktformat wird in der folgenden Tabelle beschrieben. Eine Anleitung zum Angeben dieser Attribute finden Sie in der YAML-Referenz für Onlineendpunkte. Informationen zu Grenzwerten im Zusammenhang mit verwalteten Onlineendpunkten finden Sie unter Grenzwerte für Onlineendpunkte.
| Schlüssel | BESCHREIBUNG |
|---|---|
$schema |
(Optional) Das YAML-Schema. Sie können das Schema aus dem vorherigen Codeschnipsel in einem Browser anzeigen, um sich alle verfügbaren Optionen in der YAML-Datei anzusehen. |
name |
Der Name des Endpunkts. |
auth_mode |
Verwenden Sie key für schlüsselbasierte Authentifizierung. Verwenden Sie aml_token für die tokenbasierte Azure Machine Learning-Authentifizierung. Verwenden Sie den Befehl az ml online-endpoint get-credentials, um das neueste Token abzurufen. |
So erstellen Sie einen Onlineendpunkt:
Legen Sie den Namen des Endpunkts fest:
Führen Sie für Unix diesen Befehl aus (ersetzen Sie
YOUR_ENDPOINT_NAMEdurch einen eindeutigen Namen):export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Wichtig
Endpunktnamen müssen innerhalb einer Azure-Region eindeutig sein. In der Azure-Region „
westus2“ kann es z. B. nur einen Endpunkt namensmy-endpointgeben.Erstellen Sie den Endpunkt in der Cloud:
Führen Sie den folgenden Code aus, um die Datei
endpoint.ymlzum Konfigurieren des Endpunkts zu verwenden:az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Erstellen der Bereitstellung „blau“
In diesem Artikel verwenden Sie die Datei endpoints/online/managed/sample/blue-deployment.yml verwendet, um die wichtigsten Aspekte der Bereitstellung zu konfigurieren. Der folgende Codeschnipsel zeigt den Inhalt der Datei:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Führen Sie den folgenden Befehl aus, um für Ihren Endpunkt eine Bereitstellung namens blue zu erstellen und sie mithilfe der Datei blue-deployment.yml zu konfigurieren:
az ml online-deployment create --name blue --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml --all-traffic
Wichtig
Das Flag --all-traffic im Befehl az ml online-deployment create ordnet den gesamten Endpunktdatenverkehr der neu erstellten blauen Bereitstellung zu.
In der Datei blue-deployment.yaml wird inline path (von wo aus Dateien hochgeladen werden sollen) angegeben. Die CLI lädt die Dateien automatisch hoch und registriert das Modell und die Umgebung. Als bewährte Methode für die Produktion sollten Sie das Modell und die Umgebung registrieren und den registrierten Namen sowie die Version im YAML-Code separat angeben. Verwenden Sie das Format model: azureml:my-model:1 oder environment: azureml:my-env:1.
Zur Registrierung können Sie die YAML-Definitionen von model und environment in separate YAML-Dateien extrahieren und die Befehle az ml model create und az ml environment create verwenden. Führen Sie az ml model create -h und az ml environment create -h aus, um mehr über diese Befehle zu erfahren.
Weitere Informationen zum Registrieren Ihres Modells als Ressource finden Sie unter Registrieren Ihres Modells als Ressource in Machine Learning mithilfe der CLI. Weitere Informationen zum Erstellen einer Umgebung finden Sie im Artikel Verwalten von Azure Machine Learning-Umgebungen mit der CLI und dem SDK (v2).





Überprüfen der vorhandenen Bereitstellung
Eine Möglichkeit, Ihre vorhandene Bereitstellung zu bestätigen, besteht darin, Ihren Endpunkt aufzurufen, damit er Ihr Modell für eine bestimmte Eingabeanforderung bewerten kann. Wenn Sie Ihren Endpunkt über die CLI oder das Python SDK aufrufen, können Sie den Namen der Bereitstellung angeben, die den eingehenden Datenverkehr empfängt.
Hinweis
Anders als die CLI oder das Python SDK erfordert Azure Machine Learning Studio, dass Sie eine Bereitstellung angeben, wenn Sie einen Endpunkt aufrufen.
Aufrufen eines Endpunkts mit dem Bereitstellungsnamen
Wenn Sie den Endpunkt mit dem Namen der Bereitstellung aufrufen, die Datenverkehr empfängt, leitet Azure Machine Learning den Datenverkehr des Endpunkts direkt an die angegebene Bereitstellung weiter und gibt deren Ausgabe zurück. Sie können die Option --deployment-namefür CLI v2 oder die Option deployment_namefür SDK v2 verwenden, um die Bereitstellung anzugeben.
Aufrufen eines Endpunkts ohne Angabe der Bereitstellung
Wenn Sie den Endpunkt aufrufen, ohne die Bereitstellung anzugeben, die Datenverkehr empfangen soll, leitet Azure Machine Learning den eingehenden Datenverkehr des Endpunkts basierend auf den Einstellungen für die Datenverkehrssteuerung an die Bereitstellungen im Endpunkt weiter.
Die Einstellungen für die Datenverkehrssteuerung ordnen jeder Bereitstellung im Endpunkt bestimmte Prozentsätze des eingehenden Datenverkehrs zu. Wenn Ihre Datenverkehrsregeln beispielsweise angeben, dass eine bestimmte Bereitstellung in Ihrem Endpunkt 40 % der Zeit eingehenden Datenverkehr empfängt, leitet Azure Machine Learning 40 % des Datenverkehrs des Endpunkts an diese Bereitstellung weiter.
Sie können den Status Ihres vorhandenen Endpunkts und Ihrer Bereitstellung anzeigen, indem Sie Folgendes ausführen:
az ml online-endpoint show --name $ENDPOINT_NAME
az ml online-deployment show --name blue --endpoint $ENDPOINT_NAME
Es sollten der Endpunkt mit $ENDPOINT_NAME und eine Bereitstellung mit dem Namen blue angezeigt werden.
Testen des Endpunkts mit Beispieldaten
Der Endpunkt kann mithilfe des Befehls invoke aufgerufen werden. Wir senden eine Beispielanforderung mithilfe einer JSON-Datei.
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json


Skalieren Ihrer vorhandenen Bereitstellung zur Verarbeitung einer größeren Menge an Datenverkehr
In der unter Bereitstellen und Bewerten eines Machine Learning-Modells mit einem Onlineendpunkt beschriebenen Bereitstellung legen Sie den instance_count in der YAML-Bereitstellungsdatei auf den Wert 1 fest. Sie können mit dem update-Befehl aufskalieren:
az ml online-deployment update --name blue --endpoint-name $ENDPOINT_NAME --set instance_count=2
Hinweis
Beachten Sie, dass im oben genannten Befehl --set verwendet wird, um die Bereitstellungskonfiguration zu überschreiben. Alternativ können Sie die YAML-Datei aktualisieren und mithilfe der Eingabe --file als Eingabe an den Befehl update übergeben.

Bereitstellen eines neuen Modells, ohne vorerst Datenverkehr zu senden
Erstellen Sie eine neue Bereitstellung mit dem Namen green:
az ml online-deployment create --name green --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/green-deployment.yml
Da green nicht explizit Datenverkehr zugeordnet wurde, ist null Datenverkehr zugeordnet. Sie können dies mithilfe dieses Befehls überprüfen:
az ml online-endpoint show -n $ENDPOINT_NAME --query traffic
Testen der neuen Bereitstellung
Obwohl green 0% des Datenverkehrs zugeordnet ist, können Sie sie direkt aufrufen, indem Sie den --deployment-Namen angeben:
az ml online-endpoint invoke --name $ENDPOINT_NAME --deployment-name green --request-file endpoints/online/model-2/sample-request.json
Falls Sie einen REST-Client verwenden möchten, um die Bereitstellung ohne Verwendung von Datenverkehrsregeln direkt aufzurufen, müssen Sie den folgenden HTTP-Header festlegen: azureml-model-deployment: <deployment-name>. Der folgende Codeausschnitt verwendet curl, um die Bereitstellung direkt aufzurufen. Der Codeausschnitt sollte in UNIX/WSL-Umgebungen funktionieren:
# get the scoring uri
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
# use curl to invoke the endpoint
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --header "azureml-model-deployment: green" --data @endpoints/online/model-2/sample-request.json


Testen der Bereitstellung mit gespiegeltem Datenverkehr
Nachdem Sie die grüne Bereitstellung (green) getestet haben, können Sie einen Prozentsatz des Livedatenverkehrs spiegeln (bzw. kopieren). Die Datenverkehrsspiegelung (auch Shadowing genannt) ändert nichts an den Ergebnissen, die an Clients zurückgegeben werden. Anforderungen gehen immer noch zu 100 Prozent an die blaue Bereitstellung (blue). Der gespiegelte Prozentsatz des Datenverkehrs wird kopiert und an die grüne Bereitstellung (green) übermittelt, damit Sie Statistiken und Protokolle sammeln können, ohne Ihre Clients zu beeinträchtigen. Die Spiegelung ist nützlich, wenn Sie eine neue Bereitstellung validieren möchten, ohne die Clients zu beeinträchtigen. So können Sie die Spiegelung beispielsweise verwenden, um zu prüfen, ob die Wartezeit innerhalb akzeptabler Grenzen liegt, oder um sich zu vergewissern, dass keine HTTP-Fehler vorliegen. Das Testen der neuen Bereitstellung mit der Spiegelung von Datenverkehr wird auch als Schattentests bezeichnet. Die Bereitstellung, die den gespiegelten Datenverkehr erhält – in diesem Fall die grüne Bereitstellung (green) –, kann auch als Schattenbereitstellung bezeichnet werden.
Für die Spiegelung gelten die folgenden Einschränkungen:
- Die Spiegelung wird für die CLI (v2) ab Version 2.4.0 und für das Python SDK (v2) ab Version 1.0.0 unterstützt. Wenn Sie eine ältere Version der CLI bzw. des SDK verwenden, um einen Endpunkt zu aktualisieren, geht die Einstellung für gespiegelten Datenverkehr verloren.
- Die Spiegelung wird derzeit nicht für Kubernetes-Onlineendpunkte unterstützt.
- Datenverkehr kann nur an eine einzelne Bereitstellung an einem Endpunkt gespiegelt werden.
- Maximal können 50 Prozent des Datenverkehrs gespiegelt werden. Dieser Grenzwert dient dazu, die Auswirkungen auf das Bandbreitenkontingent für Ihren Endpunkt (Standardwert: 5 MBit/s) zu reduzieren. Ihre Endpunktbandbreite wird gedrosselt, wenn Sie das zugeordnete Kontingent überschreiten. Informationen zur Überwachung von Endpunkten finden Sie unter Überwachen verwalteter Onlineendpunkte.
Beachten Sie außerdem das folgende Verhalten:
- Eine Bereitstellung kann so konfiguriert werden, dass nur Livedatenverkehr oder nur gespiegelter Datenverkehr empfangen wird, aber nicht beides.
- Wenn Sie einen Endpunkt aufrufen, können Sie den Namen einer seiner Bereitstellungen (auch einer Schattenbereitstellung) angeben, um die Vorhersage zurückzugeben.
- Wenn Sie einen Endpunkt mit dem Namen der Bereitstellung aufrufen, die eingehenden Datenverkehr empfängt, spiegelt Azure Machine Learning den Datenverkehr nicht an die Schattenbereitstellung. Azure Machine Learning spiegelt Datenverkehr an die Schattenbereitstellung auf der Grundlage von Datenverkehr, der an den Endpunkt gesendet wird, wenn Sie keine Bereitstellung angeben.
Legen Sie nun fest, dass die grüne Bereitstellung zehn Prozent des gespiegelten Datenverkehrs erhalten soll. Clients erhalten weiterhin nur Vorhersagen auf der Grundlage der blauen Bereitstellung.
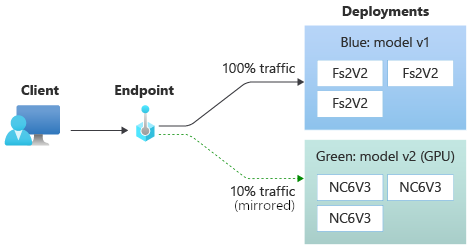
Der folgende Befehl spiegelt 10 % des Datenverkehrs an die green-Bereitstellung:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=10"
Sie können gespiegelten Datenverkehr testen, indem Sie den Endpunkt mehrmals aufrufen, ohne eine Bereitstellung anzugeben, die den eingehenden Datenverkehr empfängt:
for i in {1..20} ; do
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
done
Sie können sich anhand der Protokolle der Bereitstellung vergewissern, dass ein bestimmter Prozentsatz des Datenverkehrs an die green-Bereitstellung gesendet wurde:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Nach dem Test können Sie den gespiegelten Datenverkehr auf Null festlegen, um die Spiegelung zu deaktivieren:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=0"



Zuordnen eines geringen Prozentsatzes des Livedatenverkehrs zur neuen Bereitstellung
Nachdem Sie Ihre green-Bereitstellung getestet haben, weisen Sie ihr einen kleinen Prozentsatz des Datenverkehrs zu:
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=90 green=10"
Tipp
Der Gesamtprozentsatz des Datenverkehrs muss entweder null Prozent (Datenverkehr deaktivieren) oder 100 Prozent (Datenverkehr aktivieren) ergeben.
Ihre grüne Bereitstellung (green) erhält jetzt zehn Prozent des gesamten Livedatenverkehrs. Clients erhalten Vorhersagen sowohl von der blauen Bereitstellung (blue) als auch von der grünen Bereitstellung (green).
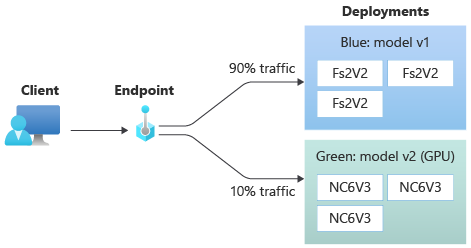
Senden des gesamten Datenverkehrs an Ihre neue Bereitstellung
Wenn Sie mit der green-Bereitstellung zufrieden sind, können Sie den gesamten Datenverkehr auf sie umstellen.
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=0 green=100"
Entfernen der alten Bereitstellung
Führen Sie die folgenden Schritte aus, um eine einzelne Bereitstellung von einem verwalteten Onlineendpunkt zu löschen. Das Löschen einer einzelnen Bereitstellung hat Auswirkungen auf die anderen Bereitstellungen des verwalteten Onlineendpunkts:
az ml online-deployment delete --name blue --endpoint $ENDPOINT_NAME --yes --no-wait
Löschen des Endpunkts und der Bereitstellung
Wenn Sie den Endpunkt und die Bereitstellung nicht verwenden, sollten Sie sie löschen. Wenn Sie den Endpunkt löschen, werden auch alle zugrunde liegenden Bereitstellungen gelöscht.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Zugehöriger Inhalt
- Erkunden von Onlineendpunktbeispielen
- Bereitstellen von Modellen mit REST
- Verwenden von Netzwerkisolation mit verwalteten Onlineendpunkten
- Zugreifen auf Azure-Ressourcen mit einem Onlineendpunkt und einer verwalteten Identität
- Überwachen verwalteter Onlineendpunkte
- Verwalten und Erhöhen der Kontingente für Ressourcen mit Azure Machine Learning
- Anzeigen der Kosten für einen verwalteten Azure Machine Learning-Onlineendpunkt
- SKU-Liste für verwaltete Onlineendpunkte
- Problembehandlung bei der Bereitstellung und Bewertung von Onlineendpunkten
- YAML-Referenz zu Onlineendpunkten