Anzeigen von Trainingscode für ein automatisiertes ML-Modell
In diesem Artikel erfahren Sie, wie Sie den generierten Trainingscode aus jedem trainierten Modell für automatisiertes maschinelles Lernen anzeigen.
Mit der Codegenerierung für trainierte Modelle für automatisiertes maschinelles Lernen können Sie die folgenden Details anzeigen, die automatisierte ML verwendet, um das Modell für eine bestimmte Ausführung zu trainieren und zu erstellen.
- Vorabaufbereitung der Daten
- Algorithmusauswahl
- Merkmalserstellung
- Hyperparameter
Sie können ein beliebiges trainiertes Modell ür automatisiertes maschinelles Lernen (empfohlene oder untergeordnete Ausführung) auswählen und den generierten Python-Trainingscode anzeigen, mit dem das betreffende Modell erstellt wurde.
Mit dem Trainingscode des generierten Modells haben Sie folgende Möglichkeiten:
- Erfahren Sie, welchen Featurisierungsprozess und welche Hyperparameter der Modellalgorithmus verwendet.
- Nachverfolgen/Versionieren/Überwachen trainierter Modelle. Speichern Sie Code mit Versionsverwaltung, um nachzuverfolgen, welcher spezifische Trainingscode mit dem Modell verwendet wird, das für die Produktion bereitgestellt werden soll.
- Anpassen des Trainingscodes durch Ändern von Hyperparametern oder Anwenden Ihrer ML- und Algorithmusfertigkeiten/-erfahrungen und erneutes Trainieren eines neuen Modells mit Ihrem angepassten Code.
Im folgenden Diagramm wird veranschaulicht, dass Sie den Code für automatisierte ML-Experimente mit allen Aufgabentypen generieren können. Wählen Sie zunächst ein Modell aus. Nachdem Sie ein Modell ausgewählt haben, kopiert Azure Machine Learning die Codedateien, die zum Erstellen des Modells verwendet wurden, und zeigt sie im freigegebenen Ordner Ihres Notebooks an. Von hier aus können Sie den Code anzeigen und nach Bedarf anpassen.
Voraussetzungen
Ein Azure Machine Learning-Arbeitsbereich. Informationen zum Erstellen des Arbeitsbereichs finden Sie unter Schnellstart: So erstellen Sie Arbeitsbereichsressourcen, die Sie für die ersten Schritte mit Azure Machine Learning benötigen.
In diesem Artikel werden Grundkenntnisse in der Einrichtung eines Experiments mit automatisiertem maschinellem Lernen vorausgesetzt. Machen Sie sich anhand des Tutorials oder der Anleitung mit den wichtigsten Entwurfsmustern für automatisierte ML-Experimente vertraut.
Die automatische ML-Codegenerierung ist nur für Experimente verfügbar, die auf Remote-Azure Machine Learning-Computezielen ausgeführt werden. Die Codegenerierung wird für lokale Ausführungen nicht unterstützt.
Bei allen automatisierten ML-Ausführungen, die über Azure Machine Learning Studio, SDKv2 oder CLIv2 ausgelöst werden, ist die Codegenerierung aktiviert.
Abrufen von generiertem Code und Modellartefakten
Standardmäßig generiert jedes trainierte Modell für automatisiertes maschinelles Lernen seinen Trainingscode nach Abschluss des Trainings. Automated ML speichert diesen Code im outputs/generated_code des Experiments für dieses bestimmte Modell. Sie können sie auf der Azure Machine Learning Studio-Benutzeroberfläche auf der Registerkarte Ausgaben und Protokolle des ausgewählten Modells anzeigen.
script.py: Dies ist der Trainingscode des Modells, den Sie wahrscheinlich mit den Featurisierungsschritten, dem verwendeten spezifischen Algorithmus und den Hyperparametern analysieren möchten.
script_run_notebook.ipynb: Notebook mit Codebaustein zum Ausführen des Trainingscodes des Modells (script.py) im Azure Machine Learning-Compute über Azure Machine Learning SDKv2.
Nachdem das automatisierte ML-Training ausgeführt wurde, können Sie über die Azure Machine Learning Studio-Benutzeroberfläche auf die Dateien script.py und script_run_notebook.ipynb zugreifen.
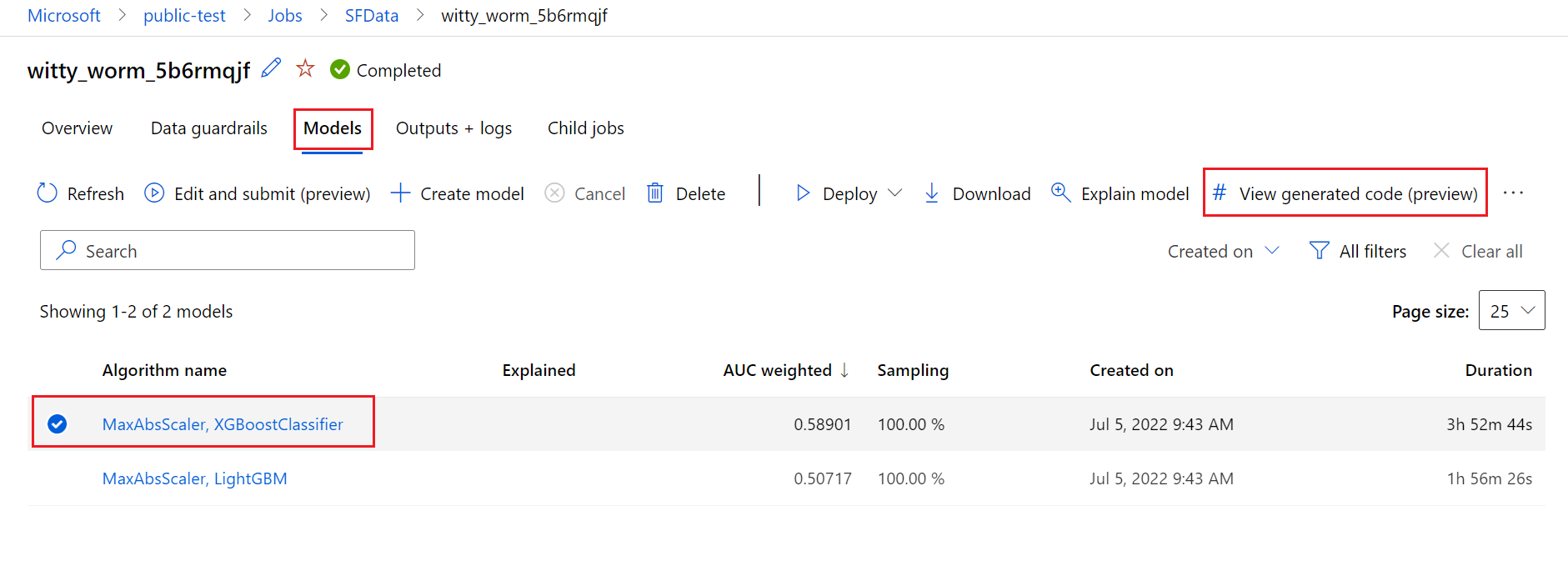
Navigieren Sie dazu zur Registerkarte Modelle der Seite der übergeordneten Ausführung des automatisierten ML-Experiments. Nachdem Sie eines der trainierten Modelle ausgewählt haben, können Sie auf die Schaltfläche Generierten Code anzeigen klicken. Diese Schaltfläche leitet Sie zur Portalerweiterung Notebooks weiter, wo Sie den generierten Code für das ausgewählte Modell anzeigen, bearbeiten und ausführen können.
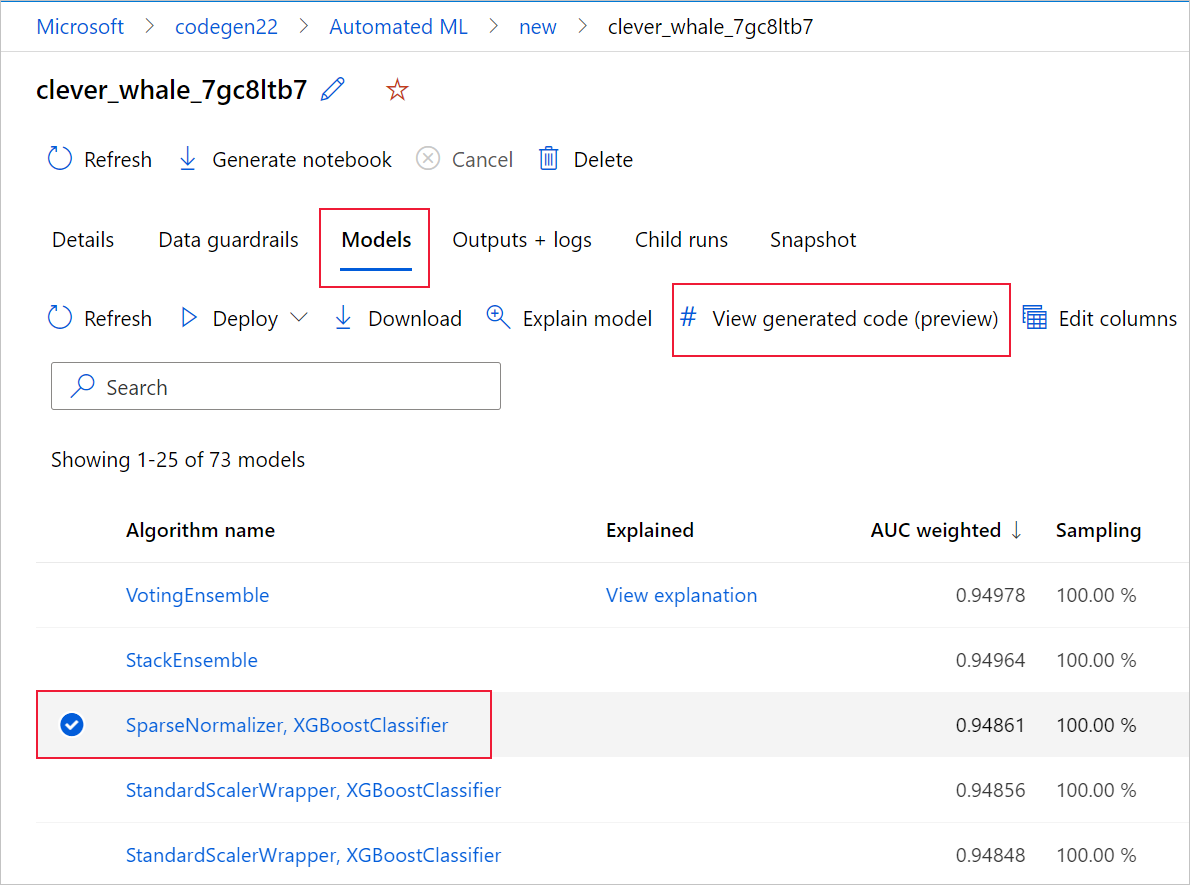
Sie können auch oben auf der Seite der untergeordneten Ausführung auf den generierten Code des Modells zugreifen, sobald Sie auf die Seite der untergeordneten Ausführung eines bestimmten Modells navigieren.
Wenn Sie das Python SDKv2 verwenden, können Sie auch die Dateien „script.py“ und „script_run_notebook.ipynb“ herunterladen, indem Sie die beste Ausführung über MLFlow abrufen und die resultierenden Artefakte herunterladen.
Begrenzungen
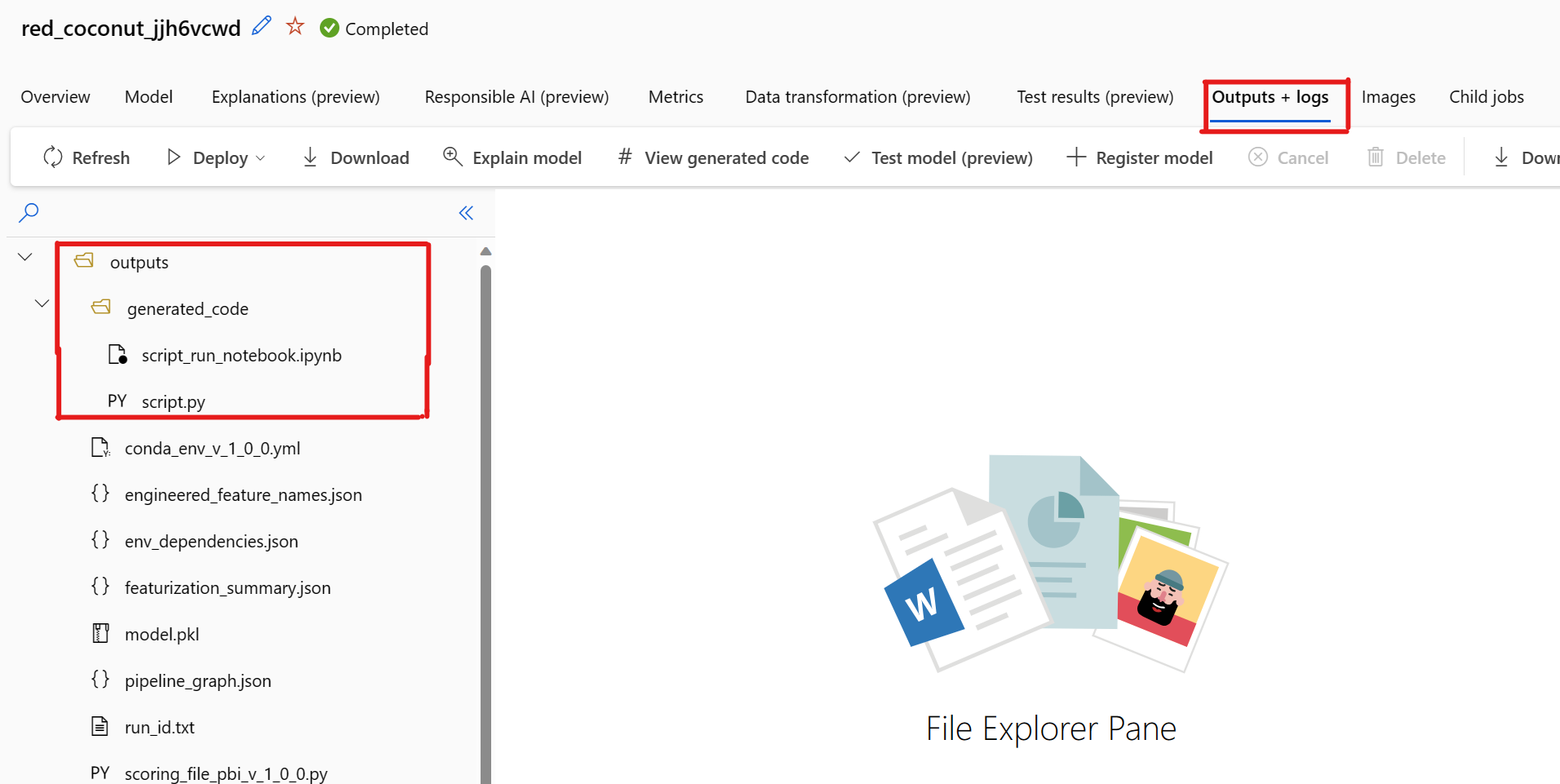
Es gibt ein bekanntes Problem beim Auswählen von Generierten Code anzeigen. Diese Aktion kann nicht zum Notebooks-Portal umgeleitet werden, wenn sich der Speicher hinter einem VNet befindet. Als Problemumgehung können Benutzer*innen die Dateien script.py und script_run_notebook.ipynb manuell herunterladen, indem sie zur Registerkarte Ausgaben + Protokolle im Ordner Ausgaben > generated_code navigieren. Diese Dateien können zur Ausführung oder Bearbeitung manuell in den Notebooks-Ordner hochgeladen werden. Folgen Sie diesem Link, um mehr über VNets in Azure Machine Learning zu erfahren.
script.py
Die Datei script.py enthält die Kernlogik, die zum Trainieren eines Modells mit den zuvor verwendeten Hyperparametern erforderlich ist. Der Trainingscode des Modells ist zwar für die Ausführung im Rahmen einer Azure Machine Learning-Skriptausführung vorgesehen, kann aber mit einigen Änderungen auch eigenständig in Ihrer eigenen lokalen Umgebung ausgeführt werden.
Das Skript lässt sich grob in mehrere Teile untergliedern: Laden von Daten, Datenaufbereitung, Datenfeaturisierung, Spezifikation von Präprozessor/Algorithmus und Training.
Laden von Daten
Die Funktion get_training_dataset() lädt das zuvor verwendete Dataset. Es wird davon ausgegangen, dass das Skript in einem Azure Machine Learning-Skript ausgeführt wird, das unter demselben Arbeitsbereich wie das ursprüngliche Experiment ausgeführt wird.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
Bei der Ausführung im Rahmen einer Skriptausführung ruft Run.get_context().experiment.workspace den richtigen Arbeitsbereich ab. Wenn dieses Skript jedoch in einem anderen Arbeitsbereich oder lokal ausgeführt wird, müssen Sie das Skript ändern, damit es den entsprechenden Arbeitsbereich explizit angibt.
Nachdem der Arbeitsbereich abgerufen wurde, wird das ursprüngliche Dataset anhand seiner ID abgerufen. Ein anderes Dataset mit genau derselben Struktur könnte auch über ID oder Name mit get_by_id() oder get_by_name() angegeben werden. Sie finden die ID später im Skript, in einem ähnlichen Abschnitt wie der folgende Code.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
Sie können auch die gesamte Funktion durch Ihren eigenen Mechanismus zum Laden von Daten ersetzen. Die einzigen Einschränkungen sind, dass der Rückgabewert ein Pandas-Datenrahmen sein muss und dass die Daten die gleiche Form wie im ursprünglichen Experiment aufweisen müssen.
Datenaufbereitungscode
Die Funktion prepare_data() bereinigt die Daten, teilt die Spalten der Feature- und Stichprobengewichtung auf und bereitet die Daten für die Verwendung im Training vor.
Diese Funktion kann je nach Typ des Datasets und des Typs der Experimentaufgabe variieren: Klassifizierung, Regression, Zeitreihenvorhersage, Images oder NLP-Aufgaben.
Das folgende Beispiel zeigt, dass im Allgemeinen der Datenrahmen aus dem Schritt „Laden der Daten“ übergeben wird. Die Beschriftungsspalte und die Stichprobengewichtungen, falls ursprünglich angegeben, werden extrahiert und die Zeilen, die NaN enthalten, werden aus den Eingabedaten entfernt.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Wenn Sie die Daten weiter aufbereiten möchten, können Sie dies in diesem Schritt tun, indem Sie Ihren benutzerdefinierten Datenaufbereitungscode hinzufügen.
Code für die Datenfeaturisierung
Die Funktion generate_data_transformation_config() gibt den Schritt der Featurisierung in der endgültigen Scikit-learn-Pipeline an. Die Featurebereitsteller aus dem ursprünglichen Experiment werden hier zusammen mit ihren Parametern reproduziert.
Mögliche Datentransformationen, die in dieser Funktion stattfinden können, können z. B. auf Imputern wie SimpleImputer() und CatImputer() oder Transformatoren wie StringCastTransformer() und LabelEncoderTransformer() basieren.
Im Folgenden wird ein Transformator des Typs StringCastTransformer() verwendet, mit dem eine Reihe von Spalten umgewandelt werden kann. In diesem Fall der durch column_names gekennzeichnete Satz.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Wenn Sie über viele Spalten verfügen, auf die dieselbe Featurisierung/Transformation angewendet werden muss (z. B. 50 Spalten in mehreren Spaltengruppen), werden diese Spalten durch Gruppierung nach Typ verarbeitet.
Beachten Sie im folgenden Beispiel, dass auf jede Gruppe ein eindeutiger Mapper angewendet wird. Dieser Mapper wird dann auf jede der Spalten dieser Gruppe angewendet.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Dieser Ansatz ermöglicht einen optimierten Code, da nicht für jede Spalte ein Codeblock des Transformators erforderlich ist, was besonders mühsam sein kann, wenn Ihr Dataset Dutzende oder Hunderte von Spalten enthält.
Bei Klassifizierungs- und Regressionsaufgaben wird [FeatureUnion] für Featurebereitsteller verwendet.
Für Zeitreihenvorhersagemodelle werden mehrere Zeitreihen-fähige Featurebereitsteller in einer Scikit-learn-Pipeline gesammelt und dann in TimeSeriesTransformer umschlossen.
Alle vom Benutzer bereitgestellten Features für Zeitreihenvorhersagemodelle werden vor den von der automatisierten ML bereitgestellten Features verwendet.
Präprozessorspezifikationscode
Die Funktion generate_preprocessor_config(), falls vorhanden, gibt einen Vorverarbeitungsschritt an, der nach der Featurisierung in der endgültigen Scikit-learn-Pipeline durchgeführt wird.
Normalerweise besteht dieser Vorverarbeitungsschritt nur aus der Standardisierung/Normalisierung der Daten, die mit sklearn.preprocessing erreicht wird.
Bei automatisiertem ML ist nur einen Vorverarbeitungsschritt für Nicht-Ensemble-Modelle für Klassifizierung und Regression vorgesehen.
Hier ist ein Beispiel für einen generierten Präprozessorcode:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Spezifikationscode für Algorithmen und Hyperparameter
Der Spezifikationscode für Algorithmen und Hyperparameter ist wahrscheinlich das, was viele ML-Experten am meisten interessiert.
Die generate_algorithm_config()-Funktion gibt den tatsächlichen Algorithmus und die Hyperparameter zum Trainieren des Modells als letzte Phase der endgültigen Scikit-learn-Pipeline an.
Im folgenden Beispiel wird ein XGBoostClassifier-Algorithmus mit spezifischen Hyperparametern verwendet.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
Der generierte Code verwendet in den meisten Fällen OSS-Pakete (Open-Source-Software) und -Klassen. Es gibt Instanzen, in denen Wrapperzwischenklassen verwendet werden, um komplexeren Code zu vereinfachen. So können z. B. XGBoost-Klassifizierer und andere häufig verwendete Bibliotheken wie LightGBM oder Scikit-learn-Algorithmen verwendet werden.
Als ML-Profi können Sie den Konfigurationscode dieses Algorithmus anpassen, indem Sie die Hyperparameter je nach Ihren Kenntnissen und Ihrer Erfahrung mit diesem Algorithmus und Ihrem speziellen ML-Problem optimieren.
Für Ensemblemodelle werden generate_preprocessor_config_N() (falls erforderlich) und generate_algorithm_config_N() für jeden Learner im Ensemblemodell definiert, wobei N die Position jedes Learners in der Liste des Ensemblemodells angibt. Für Stapelensemblemodelle wird der Meta-Learner generate_algorithm_config_meta() definiert.
End-to-End-Trainingscode
Die Codegenerierung gibt build_model_pipeline() und train_model() zum Definieren der Scikit-learn-Pipeline bzw. zum Aufrufen von fit() dafür aus.
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
Die Scikit-learn-Pipeline umfasst den Schritt der Featurisierung, einen Präprozessor (falls verwendet) und den Algorithmus oder das Modell.
Für Zeitreihenvorhersagemodelle wird die Scikit-learn-Pipeline von einem ForecastingPipelineWrapper umschlossen, der je nach angewandtem Algorithmus einige zusätzliche Logik für die ordnungsgemäße Verarbeitung von Zeitreihendaten enthält.
Für alle Aufgabentypen verwenden wir PipelineWithYTransformer in Fällen, in denen die Bezeichnungsspalte codiert werden muss.
Sobald Sie über die Scikit-Learn-Pipeline verfügen, müssen Sie nur noch die Methode fit() zum Trainieren des Modells aufrufen:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
Der Rückgabewert von train_model() ist das hinsichtlich der Eingabedaten angepasste/trainierte Modell.
Der Hauptcode, der alle vorherigen Funktionen ausführt, lautet wie folgt:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
Sobald Sie über das trainierte Modell verfügen, können Sie es zur Erstellung von Vorhersagen mit der Methode „predict()“ verwenden. Wenn es sich um ein Zeitreihenmodell handelt, verwenden Sie die Methode „forecast()“ für Vorhersagen.
y_pred = model.predict(X)
Schließlich wird das Modell serialisiert und als .pkl-Datei mit dem Namen „model.pkl“ gespeichert:
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
Das Notebook script_run_notebook.ipynb dient als einfache Möglichkeit, script.py in einem Azure Machine Learning-Compute auszuführen.
Dieses Notebook ähnelt den bestehenden Beispielnotebooks für automatisiertes maschinelles Lernen, es gibt jedoch einige wichtige Unterschiede, die in den folgenden Abschnitten erläutert werden.
Environment
Normalerweise wird die Trainingsumgebung für eine AutoML-Ausführung automatisch vom SDK festgelegt. Wenn jedoch ein benutzerdefiniertes Skript wie der generierte Code ausgeführt wird, steuert die automatisierte ML den Prozess nicht mehr, sodass die Umgebung angegeben werden muss, damit der Befehlsauftrag erfolgreich ausgeführt werden kann.
Bei der Codegenerierung wird nach Möglichkeit die Umgebung wiederverwendet, die bei dem ursprünglichen automatisierten ML-Experiment verwendet wurde. Dadurch wird sichergestellt, dass das Ausführen des Trainingsskripts nicht an fehlenden Abhängigkeiten scheitert. Ein weiterer Vorteil ist, dass das Docker-Image nicht neu erstellt werden muss, was Zeit und Computeressourcen spart.
Wenn Sie Änderungen an script.py vornehmen, die zusätzliche Abhängigkeiten erfordern, oder wenn Sie Ihre eigene Umgebung verwenden möchten, müssen Sie die Umgebung in der Datei script_run_notebook.ipynb entsprechend aktualisieren.
Übermitteln des Experiments
Da der generierte Code nicht mehr durch automatisiertes ML gesteuert wird, müssen Sie einen Command Job erstellen und ihm den generierten Code (script.py) bereitstellen, anstatt einen Auftrag für automatisiertes ML zu erstellen und zu übermitteln.
Das folgende Beispiel enthält die Parameter und regulären Abhängigkeiten, die zum Ausführen eines Befehlsauftrags erforderlich sind, z. B. Compute, Umgebung usw.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning studio
Nächste Schritte
- Lernen Sie, wie und wo Sie Modelle bereitstellen können.
- Weitere Informationen zum Aktivieren von Interpretierbarkeitsfeatures insbesondere in Experimenten mit automatisiertem ML finden Sie unter Interpretierbarkeit: Modellerklärungen beim automatisierten maschinellen Lernen (Vorschau).