Bereitstellen von Machine Learning-Modellen für Azure
GILT FÜR: Azure CLI-ML-Erweiterungv1Python SDK azureml v1
Azure CLI-ML-Erweiterungv1Python SDK azureml v1
Es wird beschrieben, wie Sie Ihr Machine Learning- oder Deep Learning-Modell als Webdienst in der Azure-Cloud bereitstellen.
Hinweis
Azure Machine Learning-Endpunkte (v2) bieten eine verbesserte, einfachere Bereitstellungserfahrung. Endpunkte unterstützen Szenarien mit Echtzeit- und Batchrückschluss. Endpunkte verfügen über eine einheitliche Schnittstelle zum übergreifenden Aufrufen und Verwalten von Modellbereitstellungen für alle Computetypen. Siehe Was sind Azure Machine Learning-Endpunkte?.
Workflow zum Bereitstellen eines Modells
Der Workflow ist unabhängig vom Bereitstellungsort Ihres Modells sehr ähnlich:
- Registrieren des Modells.
- Vorbereiten eines Einstiegsskripts.
- Vorbereiten einer Rückschlusskonfiguration.
- Lokales Bereitstellen des Modells, um sicherzustellen, dass alles funktioniert.
- Auswählen eines Computeziels
- Stellen Sie das Modell in der Cloud bereit.
- Testen des resultierenden Webdiensts
Weitere Informationen zu den Konzepten, die für den Workflow zur Bereitstellung von Machine Learning-Modellen gelten, finden Sie unter Verwalten, Bereitstellen und Überwachen von Modellen mit Azure Machine Learning.
Voraussetzungen
GILT FÜR:Azure CLI-ML-Erweiterung v1
Wichtig
Einige Azure CLI-Befehle in diesem Artikel verwenden die Erweiterung azure-cli-ml oder v1 für Azure Machine Learning. Der Support für die v1-Erweiterung endet am 30. September 2025. Sie können die v1-Erweiterung bis zu diesem Datum installieren und verwenden.
Es wird empfohlen, vor dem 30. September 2025 zur ml- oder v2-Erweiterung zu wechseln. Weitere Informationen zur v2-Erweiterung finden Sie unter Was sind die Azure Machine Learning CLI und das Python SDK v2?.
- Ein Azure Machine Learning-Arbeitsbereich. Weitere Informationen finden Sie unter Erstellen eines Arbeitsbereichs.
- Ein Modell. In den Beispielen in diesem Artikel wird ein vortrainiertes Modell verwendet.
- Ein Computer, auf dem Docker ausgeführt werden kann, z. B. eine Compute-Instanz.
Herstellen einer Verbindung mit Ihrem Arbeitsbereich
GILT FÜR:Azure CLI-ML-Erweiterung v1
Verwenden Sie die folgenden Befehle, um die Arbeitsbereiche anzuzeigen, auf die Sie Zugriff haben:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Registrieren des Modells
Eine typische Situation für einen bereitgestellten Machine Learning-Dienst ist, dass Sie die folgenden Komponenten benötigen:
- Ressourcen, die das spezifische Modell darstellen, das bereitgestellt werden soll (z. B. eine PyTorch-Modelldatei)
- Code, den Sie in dem Dienst ausführen möchten, der das Modell für eine bestimmte Eingabe ausführt.
Mit Azure Machine Learning erlaubt es Ihnen, die Bereitstellung in zwei separate Komponenten zu unterteilen, damit Sie denselben Code beibehalten, aber lediglich das Modell aktualisieren können. Wir definieren den Mechanismus, mit dem Sie ein Modell getrennt von Ihrem Code hochladen, als „Registrieren des Modells“.
Wenn Sie ein Modell registrieren, laden wir das Modell in die Cloud hoch (im Standardspeicherkonto Ihres Arbeitsbereichs) und binden es dann auf derselben Compute-Instanz ein, auf der Ihr Webdienst ausgeführt wird.
Die folgenden Beispiele veranschaulichen das Registrieren eines Modells.
Wichtig
Sie sollten nur Modelle verwenden, die Sie erstellt oder von einer vertrauenswürdigen Quelle erhalten haben. Sie sollten serialisierte Modelle als Code behandeln, weil in einer Reihe von gängigen Formaten Sicherheitsrisiken ermittelt wurden. Außerdem sind Modelle möglicherweise mit böswilligen Absichten trainiert worden, um verzerrte oder ungenaue Ausgaben bereitzustellen.
GILT FÜR:Azure CLI-ML-Erweiterung v1
Mit den folgenden Befehle laden Sie ein Modell herunter und registrieren es dann bei Ihrem Azure Machine Learning-Arbeitsbereich:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Legen Sie -p auf den Pfad eines Ordners oder einer Datei fest, den bzw. die Sie registrieren möchten.
Weitere Informationen zu az ml model register finden Sie in der Referenzdokumentation.
Registrieren eines Modells aus einem Azure Machine Learning-Trainingsauftrag
Wenn Sie ein Modell registrieren müssen, das zuvor über einen Azure Machine Learning-Trainingsauftrag erstellt wurde, können Sie das Experiment, die Ausführung und den Pfad zum Modell angeben:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
Der --asset-path-Parameter verweist auf den Cloudspeicherort des Modells. In diesem Beispiel wird der Pfad einer einzelnen Datei verwendet. Um mehrere Dateien in die Modellregistrierung aufzunehmen, legen Sie --asset-path auf den Pfad eines Ordners fest, der die Dateien enthält.
Weitere Informationen zu az ml model register finden Sie in der Referenzdokumentation.
Hinweis
Sie können ein Modell auch von einer lokalen Datei aus über das Portal der Arbeitsbereichs-Benutzeroberfläche registrieren.
Derzeit gibt es zwei Optionen zum Hochladen einer lokalen Modelldatei auf der Benutzeroberfläche:
- Aus lokalen Dateien, wodurch ein v2-Modell registriert wird.
- Aus lokalen Dateien (basierend auf Framework), wodurch ein v1-Modell registriert wird.
Beachten Sie, dass nur Modelle, die über den Eingang Aus lokalen Dateien (basierend auf Framework) registriert werden (als v1-Modelle bezeichnet), als Webdienste mit SDKv1/CLIv1 bereitgestellt werden können.
Definieren eines Dummyeinstiegsskripts
Das Eingangsskript empfängt an einen bereitgestellten Webdienst übermittelte Daten und übergibt sie an das Modell. Anschließend wird die Antwort des Modells an den Client zurückgegeben. Das Skript ist auf Ihr Modell zugeschnitten. Im Einstiegsskript muss die Struktur der vom Modell erwarteten und zurückgegebenen Daten bekannt sein.
Sie müssen die folgenden beiden Schritte in Ihrem Eingabeskript ausführen:
- Laden des Modells (mit einer Funktion namens
init()) - Ausführen des Modells für Eingabedaten (mit einer Funktion namens
run())
Verwenden Sie für die erste Bereitstellung ein Dummyeinstiegsskript, das die empfangenen Daten ausgibt.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Speichern Sie diese Datei als echo_score.py in einem Verzeichnis mit dem Namen source_dir. Dieses Platzhalterskript gibt die Daten zurück, die Sie an das Skript senden, sodass es das Modell nicht verwendet. Es ist jedoch nützlich, um zu testen, ob das Bewertungsskript ausgeführt wird.
Definieren einer Rückschlusskonfiguration
Eine Rückschlusskonfiguration beschreibt den Docker-Container und die Dateien, die beim Initialisieren Ihres Webdiensts verwendet werden sollen. Alle Dateien in Ihrem Quellverzeichnis, einschließlich Unterverzeichnissen, werden gezippt und in die Cloud hochgeladen, wenn Sie Ihren Webdienst bereitstellen.
Die unten gezeigte Rückschlusskonfiguration gibt an, dass die Machine Learning-Bereitstellung die Datei echo_score.py im ./source_dir Verzeichnis verwendet, um eingehende Anforderungen zu verarbeiten, und dass das Docker-Image mit den in derproject_environment-Umgebung angegebenen Python-Paketen verwendet wird.
Sie können alle zusammengestellten Azure Machine Learning-Rückschlussumgebungen als Docker-Basisimage verwenden, wenn Sie Ihre Projektumgebung erstellen. Wir installieren darauf die erforderlichen Abhängigkeiten und speichern das resultierende Docker-Image in dem Repository, das Ihrem Arbeitsbereich zugeordnet ist.
Hinweis
Beim Hochladen des Rückschlussquellverzeichnisses von Azure Machine Learning wird .gitignore oder .amlignore nicht beachtet.
GILT FÜR:Azure CLI-ML-Erweiterung v1
Eine Konfiguration für minimalen Rückschluss kann wie folgt geschrieben werden:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Speichern Sie die Datei mit dem Namen dummyinferenceconfig.json.
In diesem Artikel finden Sie eine ausführliche Erörterung von Rückschlusskonfigurationen.
Definieren einer Bereitstellungskonfiguration
Eine Bereitstellungskonfiguration gibt die Menge an Arbeitsspeicher und die Anzahl von Kernen an, die Ihr Webdienst für die Ausführung benötigt. Außerdem enthält sie Konfigurationsdetails für den zugrunde liegenden Webdienst. Mit einer Bereitstellungskonfiguration können Sie beispielsweise angeben, dass Ihr Dienst 2 GB Arbeitsspeicher, 2 CPU-Kerne sowie 1 GPU-Kern benötigt und dass Sie die automatische Skalierung aktivieren möchten.
Die für eine Bereitstellungskonfiguration verfügbaren Optionen unterscheiden sich je nach dem von Ihnen ausgewählten Computeziel. In einer lokalen Bereitstellung können Sie nur angeben, an welchem Port Ihr Webdienst bedient wird.
GILT FÜR:Azure CLI-ML-Erweiterung v1
Die Einträge im Dokument deploymentconfig.json werden den Parametern für LocalWebservice.deploy_configuration zugeordnet. In der folgenden Tabelle wird die Zuordnung zwischen den Entitäten im JSON-Dokument und den Parametern für die Methode beschrieben:
| JSON-Entität | Methodenparameter | Beschreibung |
|---|---|---|
computeType |
Nicht verfügbar | Das Computeziel. Für lokale Ziele ist der Wert local erforderlich. |
port |
port |
Der lokale Port, auf dem der HTTP-Endpunkt des Diensts verfügbar gemacht werden soll. |
Dieser JSON-Code ist ein Beispiel für eine Bereitstellungskonfiguration für die Verwendung mit der CLI:
{
"computeType": "local",
"port": 32267
}
Speichern Sie diese JSON-Datei unter dem Namen deploymentconfig.json.
Weitere Informationen finden Sie unter Bereitstellungsschema.
Bereitstellen Ihres Machine Learning-Modells
Sie können Ihr Modell jetzt bereitstellen.
GILT FÜR:Azure CLI-ML-Erweiterung v1
Ersetzen Sie bidaf_onnx:1 mit den Namen Ihres Modells und dessen Versionsnummer.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Aufrufen Ihres Modells
Lassen Sie uns überprüfen, ob Ihr Echomodell erfolgreich bereitgestellt wurde. Sie sollten in der Lage sein, eine einfache Liveanforderung sowie eine Bewertungsanforderung zu senden:
GILT FÜR:Azure CLI-ML-Erweiterung v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Definieren eines Einstiegsskripts
Jetzt ist es an der Zeit, Ihr Modell tatsächlich zu laden. Ändern Sie zunächst Ihr Einstiegsskript:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Speichern Sie diese Datei als score.py in source_dir.
Beachten Sie die Verwendung der Umgebungsvariablen AZUREML_MODEL_DIR, um Ihr registriertes Modell aufzufinden. Sie haben nun einige pip-Pakete hinzugefügt.
GILT FÜR:Azure CLI-ML-Erweiterung v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Speichern Sie diese Datei als inferenceconfig.json.
Erneutes Bereitstellen und Aufrufen Ihres Diensts
Stellen Sie Ihren Dienst erneut bereit:
GILT FÜR:Azure CLI-ML-Erweiterung v1
Ersetzen Sie bidaf_onnx:1 mit den Namen Ihres Modells und dessen Versionsnummer.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Stellen Sie anschließend sicher, dass Sie eine Post-Anforderung an den Dienst senden können:
GILT FÜR:Azure CLI-ML-Erweiterung v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Auswählen eines Computeziels
Das Computeziel, das Sie zum Hosten Ihres Modells verwenden, wirkt sich auf die Kosten und Verfügbarkeit des bereitgestellten Endpunkts aus. Verwenden Sie die folgende Tabelle, um ein geeignetes Computeziel auszuwählen:
| Computeziel | Syntaxelemente | GPU-Unterstützung | BESCHREIBUNG |
|---|---|---|---|
| Lokaler Webdienst | Testen/Debuggen | Für eingeschränkte Tests und Problembehandlung verwenden. Die Hardwarebeschleunigung hängt von der Verwendung von Bibliotheken im lokalen System ab. | |
| Azure Machine Learning Kubernetes | Echtzeitrückschluss | Ja | Führen Sie Rückschlussworkloads in der Cloud aus. |
| Azure Container Instances | Echtzeitrückschluss Nur empfohlen für Entwicklungs-/Testzwecke. |
Für CPU-lastige Workloads im kleinen Maßstab verwenden, die weniger als 48 GB Arbeitsspeicher erfordern. Sie müssen keinen Cluster verwalten. Nur geeignet für Modelle unter 1 GB. Wird im Designer unterstützt. |
Hinweis
Bei der Auswahl einer Cluster-SKU müssen Sie zuerst hochskalieren und dann aufskalieren. Beginnen Sie mit einem Computer, der über 150 % des für Ihr Modell erforderlichen RAM verfügt, erstellen Sie ein Profil für das Ergebnis, und suchen Sie nach einem Computer mit der benötigten Leistung. Nachdem Sie sich damit vertraut gemacht haben, erhöhen Sie die Anzahl der Computer, um Ihren Anforderungen an gleichzeitige Rückschlüsse zu genügen.
Hinweis
Azure Machine Learning-Endpunkte (v2) bieten eine verbesserte, einfachere Bereitstellungserfahrung. Endpunkte unterstützen Szenarien mit Echtzeit- und Batchrückschluss. Endpunkte verfügen über eine einheitliche Schnittstelle zum übergreifenden Aufrufen und Verwalten von Modellbereitstellungen für alle Computetypen. Siehe Was sind Azure Machine Learning-Endpunkte?.
Bereitstellen in der Cloud
Nachdem Sie bestätigt haben, dass Ihr Dienst lokal funktioniert, und ein Remotecomputeziel ausgewählt haben, sind Sie zum Bereitstellen in der Cloud bereit.
Ändern Sie ihre Bereitstellungskonfiguration so, dass sie dem ausgewählten Computeziel entspricht, in diesem Fall Azure Container Instances:
GILT FÜR:Azure CLI-ML-Erweiterung v1
Die für eine Bereitstellungskonfiguration verfügbaren Optionen unterscheiden sich je nach dem von Ihnen ausgewählten Computeziel.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Speichern Sie diese Datei als re-deploymentconfig.json.
Weitere Informationen finden Sie dieser Referenz.
Stellen Sie Ihren Dienst erneut bereit:
GILT FÜR:Azure CLI-ML-Erweiterung v1
Ersetzen Sie bidaf_onnx:1 mit den Namen Ihres Modells und dessen Versionsnummer.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Verwenden Sie zum Anzeigen der Dienstprotokolle den folgenden Befehl:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Aufrufen Ihres Remotewebdiensts
Wenn Sie eine Remotebereitstellung durchführen, haben Sie möglicherweise die Schlüsselauthentifizierung aktiviert. Das folgende Beispiel zeigt, wie Sie Ihren Dienstschlüssel mit Python abrufen, um eine Rückschlussanforderung zu senden.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Weitere Beispielclients in anderen Sprachen finden Sie im Artikel Clientanwendungen zum Verwenden von Webdiensten.
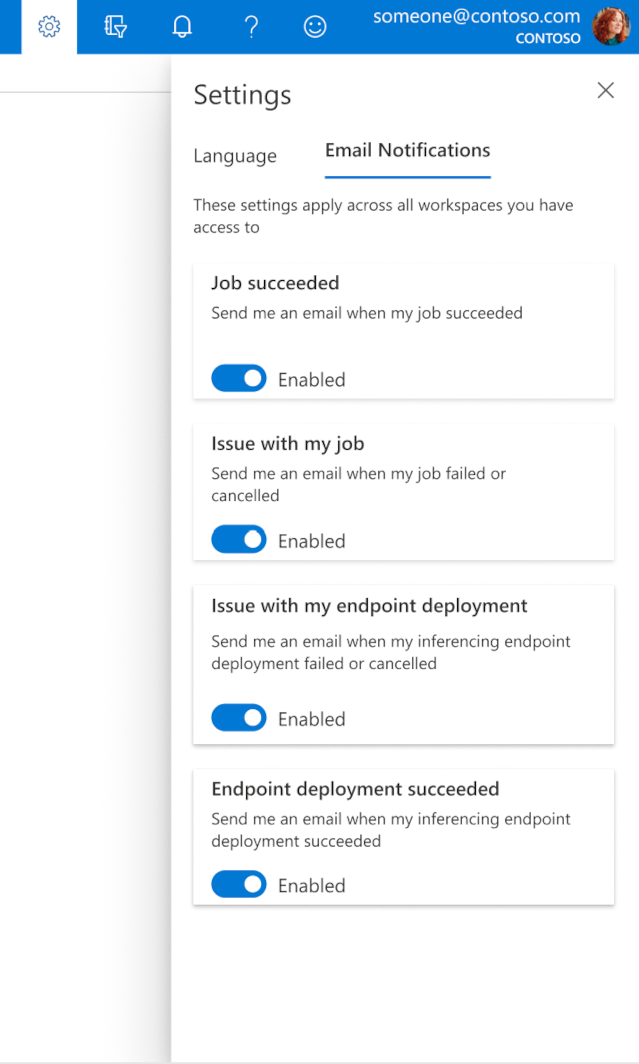
Konfigurieren von E-Mails in Studio
Um E-Mails zu empfangen, wenn Ihr Auftrag, Onlineendpunkt oder Batchendpunkt abgeschlossen ist oder ein Problem (ein Fehler oder Abbruch) auftritt, führen Sie die folgenden Schritte durch:
- Wechseln Sie in Azure ML Studio zu den Einstellungen, indem Sie das Zahnradsymbol auswählen.
- Wählen Sie die Registerkarte E-Mail-Benachrichtigungen aus.
- Schalten Sie die Umschaltfläche um, um E-Mail-Benachrichtigungen für ein bestimmtes Ereignis zu aktivieren oder deaktivieren.
Grundlegendes zum Dienstzustand
Während der Modellimplementierung kann es vorkommen, dass sich der Dienstzustand während der vollständigen Bereitstellung ändert.
In der folgenden Tabelle werden die verschiedenen Dienstzustände beschrieben:
| Webservice-Zustand | BESCHREIBUNG | Endgültiger Zustand? |
|---|---|---|
| Im Übergang | Der Dienst wird gerade bereitgestellt. | Nein |
| Fehlerhaft | Der Dienst wurde bereitgestellt, ist aber zurzeit nicht erreichbar. | Nein |
| Nicht planbar | Der Dienst kann derzeit aufgrund fehlender Ressourcen nicht bereitgestellt werden. | Nein |
| Fehler | Der Dienst konnte aufgrund eines Fehlers oder Absturzes nicht bereitgestellt werden. | Ja |
| Healthy | Der Dienst ist fehlerfrei und der Endpunkt ist verfügbar. | Ja |
Tipp
Bei der Bereitstellung werden Docker-Images für Computeziele aus Azure Container Registry (ACR) erstellt und geladen. Standardmäßig erstellt Azure Machine Learning eine ACR-Instanz mit der Dienstebene Basic. Wenn Sie die ACR-Instanz für Ihren Arbeitsbereich auf einen der Tarife „Standard“ oder „Premium“ umstellen, kann dies die Zeit zum Erstellen und Bereitstellen von Images auf Ihren Computezielen verringern. Weitere Informationen finden Sie unter Azure Container Registry-Tarife.
Hinweis
Wenn Sie ein Modell in Azure Kubernetes Service (AKS) bereitstellen, empfehlen wir Ihnen, Azure Monitor für diesen Cluster zu aktivieren. Dadurch können Sie die Gesamtintegrität des Clusters sowie die Ressourcennutzung besser nachvollziehen. Folgende Ressourcen sind unter Umständen ebenfalls hilfreich:
- Überprüfung auf Resource Health-Ereignisse, die sich auf Ihren AKS-Cluster auswirken (Vorschau)
- Übersicht über die Azure Kubernetes Service-Diagnose (Vorschau)
Wenn Sie versuchen, ein Modell in einem fehlerhaften oder überladenen Cluster bereitzustellen, ist davon auszugehen, dass Probleme auftreten. Sollten Sie Hilfe bei der Behandlung von AKS-Clusterproblemen benötigen, wenden Sie sich an den Support.
Löschen von Ressourcen
GILT FÜR:Azure CLI-ML-Erweiterung v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Um einen bereitgestellten Webdienst zu löschen, verwenden Sie az ml service delete <name of webservice>.
Um ein registriertes Modell aus Ihrem Arbeitsbereich zu löschen, verwenden Sie az ml model delete <model id>.
Erfahren Sie mehr über das Löschen eines Webdiensts und das Löschen eines Modells.
Nächste Schritte
- Problembehandlung bei einer fehlerhaften Bereitstellung
- Aktualisieren des Webdiensts
- Bereitstellung mit nur einem Klick für Ausführungen zum automatisierten maschinellen Lernen in Azure Machine Learning Studio
- Verwenden von TLS zum Absichern eines Webdiensts mit Azure Machine Learning
- Überwachen Ihrer Azure Machine Learning-Modelle mit Application Insights
- Erstellen von Ereigniswarnungen und Triggern für Modellbereitstellungen