Tutorial: Implementieren der Azure Industrial IoT-Referenzlösungsarchitektur
Hersteller möchten eine Industrial IoT-Gesamtlösung (Internet of Things, Internet der Dinge) auf globaler Ebene bereitstellen und alle ihre Produktionsstandorte mit dieser Lösung verbinden, um die Effizienz jedes einzelnen Produktionsstandorts zu steigern.
Diese gesteigerte Effizienz führt zu einer schnelleren Produktion und einem geringeren Energieverbrauch, was wiederum die Kosten für die produzierten Güter senkt und in den meisten Fällen gleichzeitig deren Qualität erhöht.
Die Lösung muss möglichst effizient sein und alle erforderlichen Anwendungsfälle wie Zustandsüberwachung, Berechnung der Gesamtanlageneffektivität (OEE, Overall Equipment Effectiveness), Vorhersagen und Anomalieerkennung ermöglichen. Anhand der Erkenntnisse, die aus diesen Anwendungsfällen gewonnen werden, können Sie dann eine digitale Feedbackschleife erstellen, die Optimierungen und andere Änderungen auf die Produktionsprozesse anwenden kann.
Interoperabilität ist der Schlüssel zum schnellen Rollout der Lösungsarchitektur. Die Verwendung offener Standards wie OPC UA trägt wesentlich zur Erreichung dieser Interoperabilität bei.
In diesem Tutorial erfahren Sie, wie Sie eine Industrial IoT-Lösung mithilfe von Azure-Diensten bereitstellen. Diese Lösung verwendet die Norm IEC 62541 der Open Platform Communications (OPC) Unified Architecture (UA) für alle Daten der operativen Technologie (OT).
Voraussetzungen
Für die Schritte in diesem Tutorial benötigen Sie ein Azure-Abonnement. Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Architektur der Referenzlösung
Die folgenden Diagramme zeigen die Architektur der Industrial IoT-Lösung:
Vereinfachte Architektur, die sowohl Azure- als auch Microsoft Fabric-Optionen zeigt:

Detaillierte Architektur mit der Azure-Option:

In der folgenden Tabelle werden die Komponenten beschrieben, die in dieser Lösung verwendet werden:
| Komponente | Beschreibung |
|---|---|
| Industrieanlagen | Eine Reihe simulierter OPC UA-fähiger Produktionslinien, die in Docker-Containern gehostet werden. |
| Azure IoT Einsatz | Azure IoT Einsatz ist eine einheitliche Datenebene für den Edge. Umfasst eine Reihe modularer, skalierbarer und hochverfügbarer Datendienste, die auf Kubernetes-Edgeclustern mit Azure Arc-Unterstützung ausgeführt werden. |
| Datengateway | Dieses Gateway verbindet Ihre lokalen Datenquellen (z. B. SAP) mit Azure Logic Apps in der Cloud. |
| Azure Event Hubs | Der Cloudnachrichtenbroker, der OPC UA-Pub/Sub-Nachrichten (Veröffentlichen/Abonnieren) von Edgegateways empfängt und speichert, bis sie von Abonnenten abgerufen werden. |
| Azure Data Explorer | Die Zeitreihendatenbank und der Front-End-Dashboarddienst für erweiterte Cloudanalysen, einschließlich integrierter Anomalieerkennung und Vorhersagen. |
| Azure Logic Apps | Azure Logic Apps ist eine Cloudplattform, auf der Sie automatisierte Workflows mit wenig bis keinem Code erstellen und ausführen können. |
| Azure Arc | Dieser Clouddienst wird verwendet, um den lokalen Kubernetes-Cluster am Edge zu verwalten. |
| Von Azure verwaltetes Grafana | Azure Managed Grafana ist eine Datenvisualisierungsplattform, die auf der Grafana-Software von Grafana Labs basiert. Grafana ist ein vollständig verwalteter Dienst, den Microsoft hostet und unterstützt. |
| Microsoft Power BI | Microsoft Power BI ist eine Sammlung von SaaS-Softwarediensten, Apps und Connectors, die zusammenarbeiten, um Ihre unabhängigen Datenquellen in kohärente, visuell ansprechende und interaktive Erkenntnisse zu verwandeln. |
| Microsoft Dynamics 365 Field Service | Microsoft Dynamics 365 Field Service ist eine schlüsselfertige SaaS-Lösung zum Verwalten von Field Service-Anforderungen. |
| UA Cloud Commander | Diese Open-Source-Referenzanwendung konvertiert Nachrichten, die an einen Message Queue Telemetry Transport (MQTT)- oder Kafka-Broker (möglicherweise in der Cloud) gesendet werden, in OPC UA-Client/Server-Anforderungen für einen verbundenen OPC UA-Server. Die Anwendung wird in einem Docker-Container ausgeführt. |
| UA Cloud-Aktion | Diese Open-Source-Referenz-Cloudanwendung fragt den Azure Data Explorer nach einem bestimmten Datenwert ab. Bei dem Datenwert handelt es sich um den Druck in einer der simulierten Produktionslinienmaschinen. UA Cloud Commander wird über Azure Event Hubs aufgerufen, wenn ein bestimmter Schwellenwert erreicht wird (4.000 mbar). UA Cloud Commander ruft dann über OPC UA die OpenPressureReliefValve-Methode auf der Maschine auf. |
| UA-Cloudbibliothek | Die UA-Cloudbibliothek ist ein Onlinespeicher von OPC UA-Informationsmodellen, der von der OPC Foundation gehostet wird. |
| UA Edge-Übersetzer | Diese Open-Source-Referenzanwendung für industrielle Konnektivität übersetzt geschützte Ressourcenschnittstellen in OPC UA. Die Lösung verwendet Web of Things (WoT)-Beschreibungen des World Wide Web Consortium (W3C) als Schema zur Beschreibung der industriellen Ressourcenschnittstelle. |
Hinweis
In einer realen Bereitstellung würde etwas so Kritisches wie das Öffnen eines Überdruckventils lokal vor Ort geschehen. In diesem Beispiel wird einfach veranschaulicht, wie die digitale Feedbackschleife eingerichtet werden kann.
Produktionsliniensimulation
Die Lösung umfasst eine aus mehreren Stationen bestehende Produktionsliniensimulation, die das OPC UA-Informationsmodell der Stationen sowie ein einfaches Manufacturing Execution System (MES) verwendet. Sowohl die Stationen als auch das MES werden zum Vereinfachen der Bereitstellung containerisiert.
Die Simulation ist so konfiguriert, dass sie zwei Produktionslinien enthält. Die Standardkonfiguration lautet:
| Produktionslinie | Ideale Zykluszeit (in Sekunden) |
|---|---|
| München | 6 |
| Seattle | 10 |
| Schichtname | Start | Ende |
|---|---|---|
| Morgenn | 07:00 | 14:00 |
| Nachmittags | 15:00 | 22:00 |
| Nacht | 23:00 | 06:00 |
Hinweis
Die Schichtzeiten werden in der lokalen Uhrzeit angegeben, genauer gesagt in der Zeitzone, die auf der VM, die diese Produktionsliniensimulation hostet, festgelegt ist.
Der OPC UA-Server der Station verwendet die folgenden OPC UA-Knoten-IDs für die Telemetrie in der Cloud:
- i = 379: Seriennummer des hergestellten Produkts
- i = 385: Anzahl der hergestellten Produkte
- i = 391: Anzahl der verworfenen Produkte
- i = 398: Ausführungszeit
- i = 399: Fehlerzeit
- i = 400: Status (0 = Station betriebsbereit, 1 = laufende Arbeiten, 2 = Arbeit erledigt und gültiges Teil hergestellt, 3 = Arbeit erledigt und Ausschuss hergestellt, 4 = Station im Fehlerzustand)
- i = 406: Energieverbrauch
- i = 412: ideale Zykluszeit
- i = 418: tatsächliche Zykluszeit
- i = 434: Druck
Digitale Feedbackschleife mit UA Cloud Commander und UA Cloud Action
Die Lösung verwendet eine digitale Feedbackschleife, um den Druck in einer simulierten Station zu verwalten. Um die Feedbackschleife zu implementieren, löst die Lösung auf einem der OPC UA-Server in der Simulation einen Befehl aus der Cloud aus. Der Trigger wird aktiviert, wenn simulierte Zeitreihendaten zum Druck einen bestimmten Schwellenwert erreichen. Sie können den Druck des Assemblycomputers im Azure Data Explorer-Dashboard sehen. Der Druck wird in regelmäßigen Abständen für die Produktionslinie Seattle freigegeben.
Installieren der Produktionsliniensimulation und Clouddienste
Wählen Sie die Schaltfläche Bereitstellen aus, um alle erforderlichen Ressourcen in Ihrem Azure-Abonnement bereitzustellen:
Beim Bereitstellungsprozess werden Sie zur Angabe eines Kennworts für die VM aufgefordert, die die Produktionsliniensimulation und die Edge-Infrastruktur hostet. Das Kennwort muss drei der folgenden Zeichentypen enthalten: ein Kleinbuchstabe, ein Großbuchstabe, eine Zahl und ein Sonderzeichen. Das Kennwort muss zwischen 12 und 72 Zeichen lang sein.
Hinweis
Um die Kosten zu reduzieren, erstellt die Bereitstellung jeweils eine einzelne Windows 11 Enterprise-VM für die Produktionsliniensimulation und die Edge-Infrastruktur. In einem Produktionsszenario ist die Produktionsliniensimulation nicht erforderlich, und als Basisbetriebssystem wird Windows IoT Enterprise Long Term Servicing Channel (LTSC) empfohlen.
Stellen Sie nach Abschluss der Bereitstellung mithilfe von Remotedesktopprotokoll (RDP) eine Verbindung mit der bereitgestellten Windows-VM her. Sie können die RDP-Datei im Azure-Portal auf der Seite für Ihre VM unter Verbinden herunterladen. Melden Sie sich mit den Anmeldeinformationen an, die Sie während der Bereitstellung angegeben haben, öffnen Sie eine Windows-Eingabeaufforderung, und verwenden Sie den folgenden Befehl, um das Windows-Subsystem für Linux (WSL) zu installieren:
wsl --install
Nachdem der Befehl ausgeführt wurde, starten Sie Ihre VM neu, und melden Sie sich erneut an. Eine Eingabeaufforderung beendet die WSL-Installation, und Sie werden aufgefordert, einen neuen Benutzernamen und ein neues Kennwort für WSL einzugeben. Verwenden Sie dann in WSL den folgenden Befehl, um K3S, eine einfache Kubernetes-Runtime, zu installieren:
curl -sfL https://get.k3s.io | sh
Ihre VM ist jetzt bereit, die Produktionsliniensimulation auszuführen.
Ausführen der Produktionsliniensimulation
Öffnen Sie auf der VM eine Windows-Eingabeaufforderung, geben Sie wsl ein, und drücken Sie die EINGABETASTE. Navigieren Sie zum Verzeichnis /mnt/c/ManufacturingOntologies-main/Tools/FactorySimulation und führen Sie das StartSimulation-Shellskript aus:
sudo ./StartSimulation.sh "<Your Event Hubs connection string>"
<Your Event Hubs connection string> ist die Verbindungszeichenfolge für Ihren Event Hubs-Namespace. Weitere Informationen finden Sie unter Abrufen einer Event Hubs-Verbindungszeichenfolge. Eine Verbindungszeichenfolge weist das folgende Format auf: Endpoint=sb://ontologies.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=abcdefgh=
Hinweis
Wenn die externe IP-Adresse für einen Kubernetes-Dienst als <pending> angezeigt wird, verwenden Sie den folgenden Befehl, um die externe IP-Adresse des traefik-Diensts zuzuweisen: sudo kubectl patch service <theService> -n <the service's namespace> -p '{"spec": {"type": "LoadBalancer", "externalIPs":["<the traefik external IP address>"]}}'.
Tipp
Um zu verhindern, dass WSL und K3s automatisch heruntergefahren werden, lassen Sie die WSL-Eingabeaufforderung geöffnet.
UA-Cloudbibliothek
Um OPC UA-Informationsmodelle direkt aus Azure Data Explorer zu lesen, können Sie die OPC UA-Knoten, die in einem OPC UA-Informationsmodell definiert sind, in eine Tabelle importieren. Sie können die importierten Informationen zum Nachschlagen weiterer Metadaten innerhalb von Abfragen verwenden.
Konfigurieren Sie zunächst eine Azure Data Explorer-Calloutrichtlinie für die UA-Cloudbibliothek, indem Sie die folgende Abfrage in Ihrem Azure Data Explorer-Cluster ausführen. Bevor Sie beginnen, stellen Sie sicher, dass Sie Mitglied der Rolle AllDatabasesAdmin im Cluster sind. Diese Rolle können Sie im Azure-Portal konfigurieren, indem Sie zur Seite Berechtigungen für Ihren Azure Data Explorer-Cluster navigieren.
.alter cluster policy callout @'[{"CalloutType": "webapi","CalloutUriRegex": "uacloudlibrary.opcfoundation.org","CanCall": true}]'
Führen Sie dann die folgende Azure Data Explorer-Abfrage im Azure-Portal aus. In der Abfrage gilt Folgendes:
- Ersetzen Sie
<INFORMATION_MODEL_IDENTIFIER_FROM_THE_UA_CLOUD_LIBRARY>durch die eindeutige ID des Informationsmodells, das Sie aus der UA-Cloudbibliothek importieren möchten. Sie finden diese ID in der URL der Seite des Informationsmodells in der UA-Cloudbibliothek. Die ID des in diesem Tutorial verwendeten Stationsknotensatzes ist z. B.1627266626. - Ersetzen Sie
<HASHED_CLOUD_LIBRARY_CREDENTIALS>durch einen Standardautorisierungsheader mit Ihren Anmeldeinformationen für die UA-Cloudbibliothek. Verwenden Sie Tools wie https://www.debugbear.com/basic-auth-header-generator, um den Hash zu generieren. Sie können auch den folgenden Bash-Befehl verwenden:echo -n 'username:password' | base64.
let uri='https://uacloudlibrary.opcfoundation.org/infomodel/download/<INFORMATION_MODEL_IDENTIFIER_FROM_THE_UA_CLOUD_LIBRARY>';
let headers=dynamic({'accept':'text/plain', 'Authorization':'Basic <HASHED_CLOUD_LIBRARY_CREDENTIALS>'});
evaluate http_request(uri, headers)
| project title = tostring(ResponseBody.['title']), contributor = tostring(ResponseBody.contributor.name), nodeset = parse_xml(tostring(ResponseBody.nodeset.nodesetXml))
| mv-expand UAVariable=nodeset.UANodeSet.UAVariable
| project-away nodeset
| extend NodeId = UAVariable.['@NodeId'], DisplayName = tostring(UAVariable.DisplayName.['#text']), BrowseName = tostring(UAVariable.['@BrowseName']), DataType = tostring(UAVariable.['@DataType'])
| project-away UAVariable
| take 10000
Um eine grafische Darstellung eines OPC UA-Informationsmodells anzuzeigen, können Sie das Tool Kusto.Explorer verwenden. Führen Sie die folgende Abfrage in Kusto.Explorer aus, um das Stationsmodell zu rendern. Um optimale Ergebnisse zu erzielen, ändern Sie die Option Layout in Grouped und die Option Labels in name:
let uri='https://uacloudlibrary.opcfoundation.org/infomodel/download/1627266626';
let headers=dynamic({'accept':'text/plain', 'Authorization':'Basic <HASHED_CLOUD_LIBRARY_CREDENTIALS>'});
let variables = evaluate http_request(uri, headers)
| project title = tostring(ResponseBody.['title']), contributor = tostring(ResponseBody.contributor.name), nodeset = parse_xml(tostring(ResponseBody.nodeset.nodesetXml))
| mv-expand UAVariable = nodeset.UANodeSet.UAVariable
| extend NodeId = UAVariable.['@NodeId'], ParentNodeId = UAVariable.['@ParentNodeId'], DisplayName = tostring(UAVariable['DisplayName']), DataType = tostring(UAVariable.['@DataType']), References = tostring(UAVariable.['References'])
| where References !contains "HasModellingRule"
| where DisplayName != "InputArguments"
| project-away nodeset, UAVariable, References;
let objects = evaluate http_request(uri, headers)
| project title = tostring(ResponseBody.['title']), contributor = tostring(ResponseBody.contributor.name), nodeset = parse_xml(tostring(ResponseBody.nodeset.nodesetXml))
| mv-expand UAObject = nodeset.UANodeSet.UAObject
| extend NodeId = UAObject.['@NodeId'], ParentNodeId = UAObject.['@ParentNodeId'], DisplayName = tostring(UAObject['DisplayName']), References = tostring(UAObject.['References'])
| where References !contains "HasModellingRule"
| project-away nodeset, UAObject, References;
let nodes = variables
| project source = tostring(NodeId), target = tostring(ParentNodeId), name = tostring(DisplayName)
| join kind=fullouter (objects
| project source = tostring(NodeId), target = tostring(ParentNodeId), name = tostring(DisplayName)) on source
| project source = coalesce(source, source1), target = coalesce(target, target1), name = coalesce(name, name1);
let edges = nodes;
edges
| make-graph source --> target with nodes on source

Bereitstellen von Azure IoT Einsatz am Edge (optional)
Standardmäßig sendet die Produktionsliniensimulation Daten direkt an den Daten-Hubendpunkt in Ihrem Event Hubs-Namespace.
Um diesen Prozess zu verwalten, können Sie stattdessen Azure IoT Einsatz am Edge verwenden. Azure IoT Einsatz ist eine einheitliche Datenebene für den Edge. Umfasst eine Reihe modularer, skalierbarer und hochverfügbarer Datendienste, die auf Kubernetes-Edgeclustern mit Azure Arc-Unterstützung ausgeführt werden.
Vergewissern Sie sich vor der Bereitstellung von Azure IoT Einsatz, dass Sie die Produktionsliniensimulation gestartet haben. Führen Sie dann die Schritte unter Azure IoT Einsatz: Bereitstellungsdetails aus.
Tipp
Sie können die VM und die K3S-Instanz verwenden, die Sie zuvor in diesem Tutorial bereitgestellt haben, um Azure IoT Einsatz bereitzustellen und auszuführen.
Konfigurieren Ihrer Azure IoT Einsatz-Bereitstellung
Sie können Ihre Azure IoT Einsatz-Bereitstellung mithilfe der Einsatz-Webbenutzeroberfläche konfigurieren. Fügen Sie die Ressourcenendpunkte, Ressourcen und Datenflüsse hinzu, um die Daten aus der Produktionsliniensimulation zu verarbeiten und an den Datenhub in Ihrem Event Hubs-Namespace weiterzuleiten.
Erstellen Sie in Ihrer Azure IoT Einsatz-Bereitstellung Ressourcenendpunkte, die Verbindungen mit den folgenden OPC UA-Servern in der Produktionssimulation definieren:
opc.tcp://assembly.munich/opc.tcp://test.munich/opc.tcp://packaging.munich/opc.tcp://assembly.seattle/opc.tcp://test.seattle/opc.tcp://packaging.seattle/
Anwendungsfälle: Zustandsüberwachung, OEE-Berechnung, Anomalieerkennung und Vorhersagen in Azure Data Explorer
Informationen zum Erstellen von No-Code-Dashboards für die Zustandsüberwachung, Ertrags- oder Wartungsvorhersagen oder die Anomalieerkennung finden Sie in der Dokumentation zu Azure Data Explorer. Es ist auch ein Beispieldashboard verfügbar, das Sie bereitstellen können. Weitere Informationen zum Bereitstellen eines Dashboards finden Sie unter Visualisieren von Daten mit Azure Data Explorer-Dashboards > So erstellen Sie ein neues Dashboard auf der Grundlage einer Datei. Nachdem Sie das Dashboard importiert haben, aktualisieren Sie seine Datenquelle. Geben Sie den HTTPS-Endpunkt Ihres Azure Data Explorer-Serverclusters in der oberen rechten Ecke des Dashboards an. Der HTTPS-Endpunkt sieht wie folgt aus: https://<ADXInstanceName>.<AzureRegion>.kusto.windows.net/.

Hinweis
Wenn Sie die Gesamtanlageneffektivität (OEE) für eine bestimmte Schicht anzeigen möchten, wählen Sie in der Dropdownliste Zeitbereich in der oberen linken Ecke des Azure Data Explorer-Dashboards die Option Benutzerdefinierter Zeitbereich aus, und geben Sie das Datum und die Uhrzeit für den Beginn und das Ende der gewünschten Schicht ein.
Rendern des integrierten Unified NameSpace (UNS) und ISA-95-Modellgraphen in Kusto Explorer
Diese Referenzlösung implementiert basierend auf den OPC UA-Metadaten, die an die Azure Data Explorer-Zeitreihendatenbank in der Cloud gesendet werden, einen einheitlichen Namespace (Unified Namespace, UNS). Zu diesen OPC UA-Metadaten gehört auch die ISA-95-Ressourcenhierarchie. Sie können den resultierende Graphen im Tool Kusto.Explorer visualisieren.
Fügen Sie Ihrer Azure Data Explorer-Instanz eine neue Verbindung hinzu, und führen Sie dann die folgende Abfrage in Kusto.Explorer aus:
let edges = opcua_metadata_lkv
| project source = DisplayName, target = Workcell
| join kind=fullouter (opcua_metadata_lkv
| project source = Workcell, target = Line) on source
| join kind=fullouter (opcua_metadata_lkv
| project source = Line, target = Area) on source
| join kind=fullouter (opcua_metadata_lkv
| project source = Area, target = Site) on source
| join kind=fullouter (opcua_metadata_lkv
| project source = Site, target = Enterprise) on source
| project source = coalesce(source, source1, source2, source3, source4), target = coalesce(target, target1, target2, target3, target4);
let nodes = opcua_metadata_lkv;
edges | make-graph source --> target with nodes on DisplayName
Um optimale Ergebnisse zu erzielen, ändern Sie die Option Layout in Grouped.

Verwenden von Azure Managed Grafana
Sie können Azure Managed Grafana auch verwenden, um für die in diesem Artikel beschriebene Lösung ein Dashboard in Azure zu erstellen. Sie können Grafana in der Fertigung zum Erstellen von Dashboards verwenden, die Echtzeitdaten anzeigen. Die folgenden Schritte zeigen, wie Sie Grafana in Azure aktivieren und ein Dashboard mit den simulierten Produktionsliniendaten aus Azure Data Explorer erstellen.
Aktivieren des Azure Managed Grafana-Diensts
Gehen Sie wie folgt vor, um einen Azure Managed Grafana-Dienst zu erstellen und ihn mit Berechtigungen für den Zugriff auf die Ontologiedatenbank zu konfigurieren:
Suchen Sie im Azure-Portal nach Grafana, und wählen Sie dann den Dienst Azure Managed Grafana aus.
Um den Dienst zu erstellen, geben Sie auf der Seite Grafana-Arbeitsbereich erstellen einen Namen für Ihre Instanz ein. Wählen Sie alle Standardoptionen aus.
Nachdem der Dienst erstellt wurde, vergewissern Sie sich, dass Ihre Grafana-Instanz über eine vom System verwaltete Identität verfügt, und navigieren Sie zum Blatt Identität Ihrer Azure Managed Grafana-Instanz im Azure-Portal. Wenn die systemseitig zugewiesene verwaltete Identität nicht aktiviert ist, holen Sie dies nach. Notieren Sie sich den Wert unter Objekt-ID (Prinzipal), da Sie ihn später benötigen.
Gehen Sie wie folgt vor, um der verwalteten Identität die Berechtigung zu erteilen, in Azure Data Explorer auf die Ontologiedatenbank zuzugreifen:
- Navigieren Sie in Ihrer Azure Data Explorer-Instanz im Azure-Portal zum Blatt Berechtigungen.
- Wählen Sie Hinzufügen > AllDatabasesViewer aus.
- Suchen Sie den Wert von Objekt-ID (Prinzipal), den Sie sich zuvor notiert hatten, und wählen Sie ihn aus.
Hinzufügen einer neuen Datenquelle in Grafana
Fügen Sie eine neue Datenquelle hinzu, die mit Azure Data Explorer verbunden werden soll. In diesem Beispiel verwenden Sie eine systemseitig zugewiesene verwaltete Identität, um eine Verbindung mit Azure Data Explorer herzustellen. Führen Sie die folgenden Schritte aus, um die Authentifizierung zu konfigurieren:
Führen Sie die folgenden Schritte aus, um die Datenquelle in Grafana hinzuzufügen:
Navigieren Sie zu der Endpunkt-URL Ihrer Grafana-Instanz. Die Endpunkt-URL finden Sie auf der Azure Managed Grafana-Seite Ihrer Instanz im Azure-Portal. Melden Sie sich dann bei Ihrer Grafana-Instanz an.
Wählen Sie im Grafana-Dashboard Connections > Datenquellen und dann Neue Datenquelle hinzufügen aus. Scrollen Sie nach unten, und wählen Sie Azure Data Explorer-Datenquelle aus.
Verwenden Sie Verwaltete Identität als Authentifizierungsmenü. Fügen Sie dann die URL Ihres Azure Data Explorer-Clusters hinzu. Sie finden die URL im Azure-Portal im Menü Ihrer Azure Data Explorer-Instanz unter URI.
Wählen Sie Speichern und testen aus, um die Datenquellenverbindung zu überprüfen.
Verwenden eines Beispieldashboards
Jetzt können Sie das Beispieldashboard importieren.
Laden Sie das Grafana-Beispieldashboard für die Fertigung herunter.
Navigieren Sie im Grafana-Menü zu Dashboards, und wählen Sie dann Neu > Importieren aus.
Wählen Sie JSON-Dashboarddatei hochladen und dann die Datei samplegrafanadashboard.json aus, die Sie zuvor heruntergeladen haben. Klicken Sie auf Importieren.
Wählen Sie im Panel OEE Station die Option Bearbeiten und dann die Azure Data Explorer-Datenquelle aus, die Sie zuvor eingerichtet haben. Wählen Sie dann im Abfragepanel KQL aus, und fügen Sie die folgende Abfrage hinzu:
print round (CalculateOEEForStation('${Station}', '${Location}', '${CycleTime}', '${__from:date:iso}', '${__to:date:iso}') * 100, 2). Wählen Sie Anwenden aus, um Ihre Änderungen zu übernehmen und zum Dashboard zurückzukehren.Wählen Sie im Panel OEE Line die Option Bearbeiten und dann die Azure Data Explorer-Datenquelle aus, die Sie zuvor eingerichtet haben. Wählen Sie dann im Abfragepanel KQL aus, und fügen Sie die folgende Abfrage hinzu:
print round(CalculateOEEForLine('${Location}', '${CycleTime}', '${__from:date:iso}', '${__to:date:iso}') * 100, 2). Wählen Sie Anwenden aus, um Ihre Änderungen zu übernehmen und zum Dashboard zurückzukehren.Wählen Sie im Panel Discarded products die Option Bearbeiten und dann die Azure Data Explorer-Datenquelle aus, die Sie zuvor eingerichtet haben. Wählen Sie dann im Abfragepanel KQL aus, und fügen Sie die folgende Abfrage hinzu:
opcua_metadata_lkv| where Name contains '${Station}'| where Name contains '${Location}'| join kind=inner (opcua_telemetry| where Name == "NumberOfDiscardedProducts"| where Timestamp > todatetime('${__from:date:iso}') and Timestamp < todatetime('${__to:date:iso}')) on DataSetWriterID| extend numProd = toint(Value)| summarize max(numProd). Wählen Sie Anwenden aus, um Ihre Änderungen zu übernehmen und zum Dashboard zurückzukehren.Wählen Sie im Panel Manufactured products die Option Bearbeiten und dann die Azure Data Explorer-Datenquelle aus, die Sie zuvor eingerichtet haben. Wählen Sie dann im Abfragepanel KQL aus, und fügen Sie die folgende Abfrage hinzu:
opcua_metadata_lkv| where Name contains '${Station}'| where Name contains '${Location}'| join kind=inner (opcua_telemetry| where Name == "NumberOfManufacturedProducts"| where Timestamp > todatetime('${__from:date:iso}') and Timestamp < todatetime('${__to:date:iso}')) on DataSetWriterID| extend numProd = toint(Value)| summarize max(numProd). Wählen Sie Anwenden aus, um Ihre Änderungen zu übernehmen und zum Dashboard zurückzukehren.Wählen Sie im Panel Energy Consumption die Option Bearbeiten und dann die Azure Data Explorer-Datenquelle aus, die Sie zuvor eingerichtet haben. Wählen Sie dann im Abfragepanel KQL aus, und fügen Sie die folgende Abfrage hinzu:
opcua_metadata_lkv| where Name contains '${Station}'| where Name contains '${Location}'| join kind=inner (opcua_telemetry | where Name == "Pressure" | where Timestamp > todatetime('${__from:date:iso}') and Timestamp < todatetime('${__to:date:iso}')) on DataSetWriterID| extend energy = todouble(Value)| summarize avg(energy)); print round(toscalar(averageEnergyConsumption) * 1000, 2). Wählen Sie Anwenden aus, um Ihre Änderungen zu übernehmen und zum Dashboard zurückzukehren.Wählen Sie im Panel Pressure die Option Bearbeiten und dann die Azure Data Explorer-Datenquelle aus, die Sie zuvor eingerichtet haben. Wählen Sie dann im Abfragepanel KQL aus, und fügen Sie die folgende Abfrage hinzu:
opcua_metadata_lkv| where Name contains '${Station}'| where Name contains '${Location}'| join kind=inner (opcua_telemetry | where Name == "Pressure" | where Timestamp > todatetime('${__from:date:iso}') and Timestamp < todatetime('${__to:date:iso}')) on DataSetWriterID| extend NodeValue = toint(Value)| project Timestamp1, NodeValue. Wählen Sie Anwenden aus, um Ihre Änderungen zu übernehmen und zum Dashboard zurückzukehren.
Konfigurieren von Warnungen
In Grafana können Sie auch Warnungen erstellen. In diesem Beispiel erstellen Sie eine niedrige OEE-Warnung für eine der Produktionslinien.
Navigieren Sie im Menü Grafana zu **Warnung >Warnungsregel.
Wählen Sie Neue Warnungsregel aus.
Geben Sie Ihrer Warnung einen Namen, und wählen Sie Azure Data Explorer als Datenquelle aus. Wählen Sie im Bereich Abfrage- und Warnungsbedingung definieren die Option KQL aus.
Geben Sie im Abfragefeld die folgende Abfrage ein. In diesem Beispiel wird die Produktionslinie in Seattle verwendet:
let oee = CalculateOEEForStation("assembly", "seattle", 10000, now(), now(-1h)); print round(oee * 100, 2)Wählen Sie Als Warnungsbedingung festlegen aus.
Scrollen Sie nach unten zum Abschnitt Ausdrücke. Löschen Sie den Ausdruck Verringern, denn er wird nicht benötigt.
Wählen Sie A als Eingabe für den Warnungsschwellenwert aus. Wählen Sie IST UNTER aus, und geben Sie 10 ein.
Scrollen Sie nach unten zum Abschnitt Auswertungsverhalten festlegen. Erstellen Sie einen neuen Ordner, um Ihre Warnungen zu speichern. Erstellen Sie eine neue Auswertungsgruppe, und geben Sie 2m an.
Wählen Sie oben rechts die Schaltfläche Regel speichern und beenden aus.
In Ihrer Warnungsübersicht können Sie jetzt sehen, dass eine Warnung ausgelöst wird, wenn Ihr OEE bei weniger als 10 liegt.
Verbinden der Referenzlösung mit Microsoft Power BI
Um die Referenzlösung mit Power BI verbinden zu können, benötigen Sie Zugriff auf ein Power BI-Abonnement.
Führen Sie die folgenden Schritte aus, um ein Power BI-Dashboard zu erstellen:
Installieren Sie die Power BI Desktop-App.
Melden Sie sich mit dem Benutzerkonto, das Zugriff auf das Power BI-Abonnement hat, bei der Power BI Desktop-App an.
Navigieren Sie im Azure-Portal zu Ihrer Azure Data Explorer-Datenbank namens „ontologies“, und fügen Sie einem Microsoft Entra ID-Benutzer, der nur Zugriff auf das Abonnement für Ihre bereitgestellte Instanz dieser Referenzlösung hat, Berechtigungen vom Typ Datenbankadministrator hinzu. Erstellen Sie bei Bedarf einen neuen Benutzer in Microsoft Entra ID.
Erstellen Sie in Power BI einen neuen Bericht, und wählen Sie Azure Data Explorer-Zeitreihendaten als Datenquelle aus: Daten abrufen > Azure > Azure Data Explorer (Kusto).
Geben Sie im Popupfenster den Azure Data Explorer-Endpunkt Ihres Clusters (
https://<your cluster name>.<location>.kusto.windows.net), den Datenbanknamen (ontologies) und die folgende Abfrage ein:let _startTime = ago(1h); let _endTime = now(); opcua_metadata_lkv | where Name contains "assembly" | where Name contains "munich" | join kind=inner (opcua_telemetry | where Name == "ActualCycleTime" | where Timestamp > _startTime and Timestamp < _endTime ) on DataSetWriterID | extend NodeValue = todouble(Value) | project Timestamp, NodeValueMelden Sie sich bei Azure Data Explorer mit dem Microsoft Entra ID-Benutzerkonto an, dem Sie zuvor Berechtigungen zum Zugriff auf die Azure Data Explorer-Datenbank erteilt haben.
Hinweis
Wenn die Spalte Zeitstempel für alle Zeilen denselben Wert enthält, ändern Sie die letzte Zeile der Abfrage wie folgt:
| project Timestamp1, NodeValue.Wählen Sie Laden aus. Diese Aktion wird die tatsächliche Zykluszeit der Montagestation der Produktionslinie „Munich“ für die letzte Stunde importiert.
Wählen Sie in
Table viewdie Spalte NodeValue aus, und wählen Sie Im Menüelement Zusammenfassungnicht zusammenfassen aus.Wechseln Sie zur
Report view.Wählen Sie unter Visualisierungen die Visualisierung mit Liniendiagramm aus.
Verschieben Sie unter Visualisierungen die
Timestampaus derData-Quelle in dieX-axis, wählen Sie sie aus, und wählen Sie Zeitstempel aus.Verschieben Sie unter Visualisierungen die
NodeValueaus derData-Quelle in dieY-axis, wählen Sie sie aus, und wählen Sie Median aus.Speichern Sie Ihren neuen Bericht.
Tipp
Verwenden Sie die gleiche Vorgehensweise, um Ihrem Bericht weitere Daten aus Azure Data Explorer hinzuzufügen.

Verbinden der Referenzlösung mit Microsoft Dynamics 365 Field Service
Diese Integration veranschaulicht die folgenden Szenarien:
- Laden Sie Ressourcen aus der Referenzlösung für Fertigungs-Ontologien in Dynamics 365 Field Service hoch.
- Erstellen Sie Warnungen in Dynamics 365 Field Service, wenn ein bestimmter Schwellenwert für Telemetriedaten der Referenzlösung für Fertigungs-Ontologien erreicht wird.
Die Integration verwendet Azure Logics Apps. Mit Logic Apps können Sie No-Code-Workflows verwenden, um unternehmenskritische Apps oder Dienste zu verbinden. In diesem Beispiel wird gezeigt, wie Sie Daten aus dem Azure Data Explorer abrufen und Aktionen in Dynamics 365 Field Service auslösen.
Wenn Sie noch kein Dynamics 365 Field Service-Kunde sind, aktivieren Sie eine 30-Tage-Testversion.
Tipp
Um zu vermeiden, dass die mandantenübergreifende Authentifizierung konfiguriert werden muss, verwenden Sie dieselbe Microsoft Entra-ID, die Sie zum Bereitstellen der Referenzlösung für Fertigungs-Ontologien verwendet haben.
Erstellen eines Azure Logik-App-Workflows zum Erstellen von Ressourcen in Dynamics 365 Field Service
So laden Sie Ressourcen aus der Referenzlösung für Fertigungs-Ontologien in Dynamics 365 Field Service hoch:
Wechseln Sie zum Azure-Portal, und erstellen Sie eine neue Logik-App-Ressource.
Weisen Sie den Azure Logik-Apps einen Namen zu, und platzieren Sie ihn in derselben Ressourcengruppe wie die Referenzlösung für Fertigungs-Ontologien.
Wählen Sie Workflows aus.
Geben Sie Ihrem Workflow einen Namen. Verwenden Sie für dieses Szenario den statusbehafteten Zustandstyp, da Ressourcen keine Datenflüsse sind.
Wählen Sie im Workflow-Designer die Option Trigger hinzufügen aus. Erstellen Sie einen Auslöser zum Wiederholen, der täglich ausgeführt werden soll. Sie können den Trigger so ändern, dass er häufiger auslöst.
Fügen Sie eine Aktion nach dem Wiederholungsauslöser hinzu. Suchen Sie in Aktion hinzufügen nach
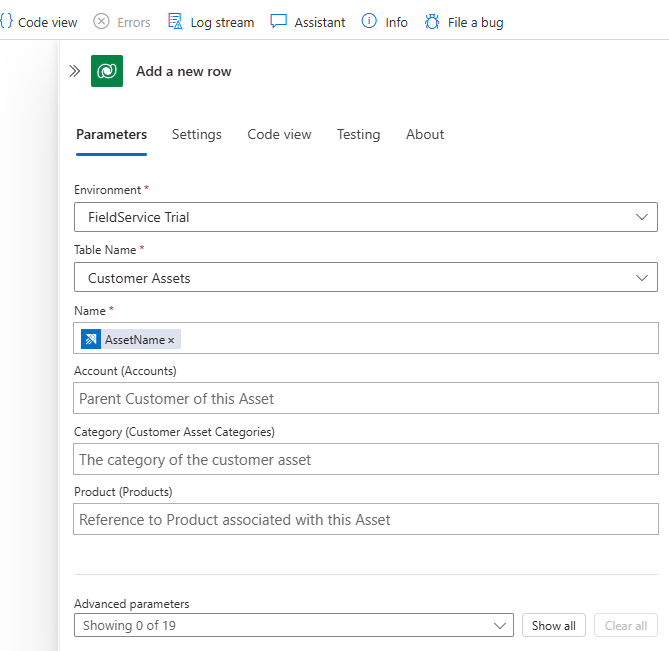
Azure Data Explorer, und wählen Sie den Befehl KQL-Abfrage ausführen aus. Belassen Sie die Standardauthentifizierung bei OAuth. Geben Sie Ihre Azure Data Explorer-Cluster-URL ein, undontologiesals den Datenbanknamen. In dieser Abfrage überprüfen Sie, welche Art von Ressourcen Sie haben. Verwenden Sie die folgende Abfrage, um Ressourcen aus der Referenzlösung für Fertigungs-Ontologien abzurufen:opcua_telemetry | join kind=inner ( opcua_metadata | distinct Name, DataSetWriterID | extend AssetList = split(Name, ';') | extend AssetName = tostring(AssetList[0]) ) on DataSetWriterID | project AssetName | summarize by AssetNameUm Ihre Bestandsdaten in Dynamics 365 Field Service zu übertragen, müssen Sie eine Verbindung mit Microsoft Dataverse herstellen. Suchen Sie in Aktion hinzufügen nach
Dataverse, und wählen Sie den Befehl Neue Zeile hinzufügen aus. Belassen Sie die Standardauthentifizierung bei OAuth. Stellen Sie eine Verbindung mit Ihrer Dynamics 365 Field Service-Instanz her, und verwenden Sie die folgende Konfiguration:- Wählen Sie im Feld TabellennameKundenressourcen aus
- Wählen Sie im Feld NameDaten aus einem vorherigen Schritt eingeben aus, und wählen Sie dann AssetName aus.
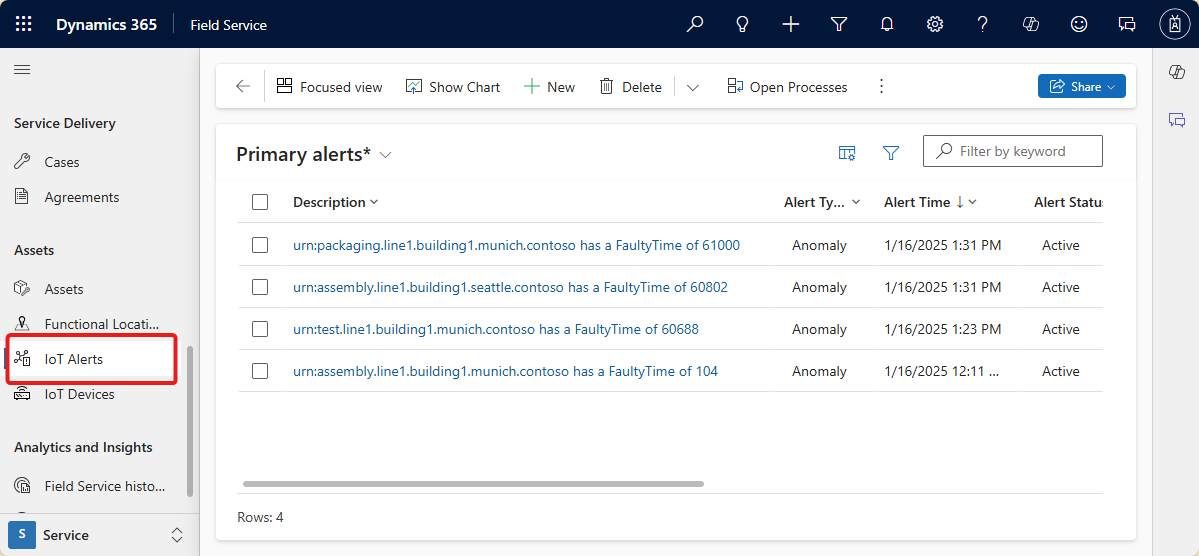
Speichern Sie Ihren Workflow, und führen Sie ihn aus. Sie können sehen, dass die neuen Ressourcen in Dynamics 365 Field Service erstellt werden:
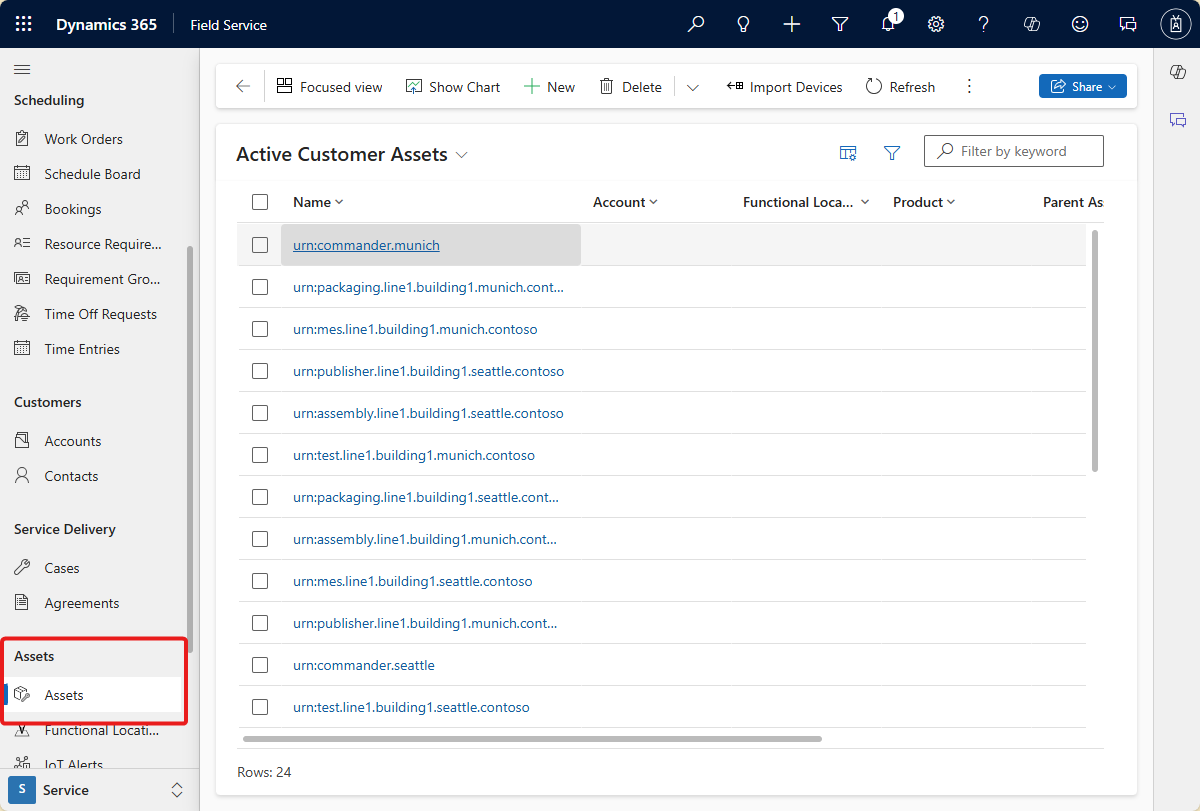
Erstellen eines Azure Logik-App-Workflows zum Erstellen von Warnungen in Dynamics 365 Field Service
Dieser Workflow erstellt Warnungen in Dynamics 365 Field Service, wenn die FaultyTime für ein Objekt in der Referenzlösung für Fertigungs-Ontologien einen Schwellenwert erreicht.
Um die Daten abzurufen, erstellen Sie eine Azure Data Explorer-Funktion. Führen Sie im Azure Data Explorer-Abfragebereich im Azure-Portal den folgenden Code aus, um eine
FaultyFieldAssets-Funktion in der Datenbank für Ontologien zu erstellen:.create-or-alter function FaultyFieldAssets() { let Lw_start = ago(3d); opcua_telemetry | where Name == 'FaultyTime' and Value > 0 and Timestamp between (Lw_start .. now()) | join kind=inner ( opcua_metadata | extend AssetList =split (Name, ';') | extend AssetName=AssetList[0] ) on DataSetWriterID | project AssetName, Name, Value, Timestamp}Erstellen Sie einen neuen zustandsbehafteten Workflow in Ihrer Logic App.
Erstellen Sie im Workflow-Designer einen Serienauslöser, der alle drei Minuten ausgeführt wird. Fügen Sie dann eine Aktion hinzu, und wählen Sie die Aktion zum Ausführen der KQL-Abfrage aus.
Geben Sie Ihre Azure Data Explorer Cluster-URL ein, und geben Sie dann Ontologien als Datenbanknamen ein, und verwenden Sie den Namen der
FaultyFieldAssets-Funktion als Abfrage.Um Ihre Bestandsdaten in Dynamics 365 Field Service zu übertragen, müssen Sie eine Verbindung mit Microsoft Dataverse herstellen. Suchen Sie in Aktion hinzufügen nach
Dataverse, und wählen Sie den Befehl Neue Zeile hinzufügen aus. Belassen Sie die Standardauthentifizierung bei OAuth. Stellen Sie eine Verbindung mit Ihrer Dynamics 365 Field Service-Instanz her, und verwenden Sie die folgende Konfiguration:- Wählen Sie im Feld TabellennameIoT-Benachrichtigungen aus
- Verwenden Sie im Feld BeschreibungEingeben der Daten aus einem vorherigen Schritt, um eine Nachricht zu erstellen "[AssetName] hat einen [Name] des [Value]". AssetName, Nameund Wert sind die Felder aus dem vorherigen Schritt.
- Wählen Sie im Feld WarnungszeitEingeben der Daten aus einem vorherigen Schritt, und wählen Sie dann Zeitstempel aus.
- Wählen Sie im Feld WarnungstypAnomalie aus.
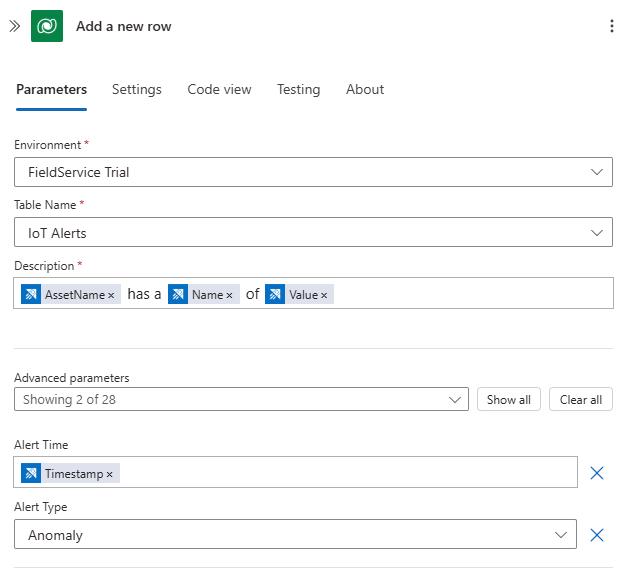
Führen Sie den Workflow aus und sehen Sie neue Warnungen, die in Ihrem Dynamics 365 Field Service IoT Alerts -Dashboard generiert werden: