Optimieren von Apache Hive mit Apache Ambari in Azure HDInsight
Apache Ambari ist eine Webbenutzeroberfläche zum Verwalten und Überwachen von HDInsight-Clustern. Eine Einführung in die Ambari-Webbenutzeroberfläche finden Sie unter Verwalten von HDInsight-Clustern mithilfe der Apache Ambari-Webbenutzeroberfläche.
In den folgenden Abschnitten werden die Konfigurationsoptionen zur Optimierung der Apache Hive-Gesamtleistung beschrieben.
- Wählen Sie zum Ändern der Hive-Konfigurationsparameter in der Randleiste „Dienste“ die Option Hive.
- Navigieren Sie zur Registerkarte Configs (Konfigurationen).
Festlegen des Hive-Ausführungsmoduls
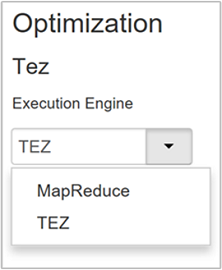
Hive verfügt über zwei Ausführungsmodule: Apache Hadoop MapReduce und Apache TEZ. Tez ist schneller als MapReduce. Für HDInsight Linux-Cluster wird Tez als Standardausführungsmodul verwendet. Gehen Sie wie folgt vor, um das Ausführungsmodul zu ändern:
Geben Sie auf der Hive-Registerkarte Configs (Konfigurationen) im Feld „Filter“ den Text execution engine (Ausführungsmodul) ein.
Der Standardwert der Eigenschaft Optimization (Optimierung) lautet Tez.
Optimieren von Zuordnungen
Hadoop versucht, eine einzelne Datei in mehrere Dateien aufzuteilen (Mapping) und die sich ergebenden Dateien parallel zu verarbeiten. Die Anzahl von Zuordnungen (Mappers) richtet sich nach der Anzahl von Unterteilungen. Die Anzahl von Unterteilungen für das Ausführungsmodul Tez basiert auf den folgenden beiden Konfigurationsparametern:
tez.grouping.min-size: Unterer Grenzwert für die Größe einer gruppierten Teilung, wobei der Standardwert 16 MB (16.777.216 Byte) lautet.tez.grouping.max-size: Oberer Grenzwert für die Größe einer gruppierten Teilung, wobei der Standardwert 1 GB (1.073.741.824 Byte) lautet.
Die Leitlinie für Leistung lautet: Verringern Sie diese beiden Parameter, um die Wartezeit zu verkürzen, und erhöhen Sie sie, um den Durchsatz zu erhöhen.
Wenn Sie beispielsweise vier Mapper-Tasks für eine Datengröße von 128 MB festlegen möchten, legen Sie für beide Parameter jeweils 32 MB fest (33.554.432 Byte).
Navigieren Sie zum Ändern der Grenzwertparameter zur Registerkarte Configs (Konfigurationen) des Tez-Diensts. Erweitern Sie den Bereich Allgemein, und suchen Sie nach den Parametern
tez.grouping.max-sizeundtez.grouping.min-size.Legen Sie für beide Parameter 33.554.432 Byte (32 MB) fest.

Diese Änderungen wirken sich auf alle Tez-Aufträge im gesamten Server aus. Wählen Sie die entsprechenden Parameterwerte aus, um ein optimales Ergebnis zu erhalten.
Optimieren von Reducern
Apache ORC und Snappy bieten jeweils eine hohe Leistung. Standardmäßig verfügt Hive unter Umständen über eine zu geringe Zahl von Reducern, sodass sich Engpässe ergeben.
Angenommen, die Eingabedatengröße beträgt bei Ihnen 50 GB. Diese Daten haben im ORC-Format mit Snappy-Komprimierung eine Größe von 1 GB. Hive schätzt die Anzahl der erforderlichen Reducer wie folgt: (Anzahl der Byte-Eingaben in Mappern/hive.exec.reducers.bytes.per.reducer).
Mit den Standardeinstellungen ergeben sich für dieses Beispiel vier Reducer.
Mit dem Parameter hive.exec.reducers.bytes.per.reducer wird die Anzahl von Byte angegeben, die pro Reducer verarbeitet werden. Der Standardwert beträgt 64 MB. Wenn Sie diesen Wert verringern, erhöht sich die Parallelität und ggf. auch die Leistung. Wenn Sie einen zu niedrigen Wert wählen, können auch zu viele Reducer erzeugt werden, was sich negativ auf die Leistung auswirken kann. Dieser Parameter basiert auf Ihren jeweiligen Datenanforderungen, Komprimierungseinstellungen und anderen Umgebungsfaktoren.
Navigieren Sie zum Ändern des Parameters zur Hive-Registerkarte Configs (Konfigurationen), und suchen Sie auf der Seite mit den Einstellungen nach dem Parameter Data per Reducer (Daten pro Reducer).
Wählen Sie Bearbeiten, um den Wert in 128 MB (134.217.728 Byte) zu ändern, und drücken Sie anschließend die EINGABETASTE, um dies zu speichern.
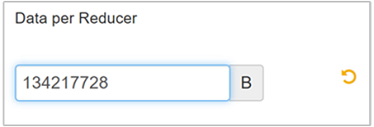
Bei einer Eingabegröße von 1.024 MB mit 128 MB Daten pro Reducer ergeben sich acht Reducer (1024/128).
Ein falscher Wert für den Parameter Data per Reducer (Daten pro Reducer) kann zu einer hohen Zahl von Reducern führen, was sich negativ auf die Abfrageleistung auswirkt. Legen Sie
hive.exec.reducers.maxauf einen geeigneten Wert fest, um die maximale Anzahl von Reducern zu begrenzen. Der Standardwert ist 1009.
Aktivieren der parallelen Ausführung
Eine Hive-Abfrage wird in einer oder mehreren Stufen ausgeführt. Wenn die unabhängigen Stufen parallel ausgeführt werden können, wird die Abfrageleistung verbessert.
Navigieren Sie zum Aktivieren der parallelen Abfragenausführung zur Hive-Registerkarte Configs (Konfigurationen), und suchen Sie nach der Eigenschaft
hive.exec.parallel. Der Standardwert ist „FALSE“. Ändern Sie den Wert in „true“, und drücken Sie anschließend die EINGABETASTE, um den Wert zu speichern.Ändern Sie die Eigenschaft
hive.exec.parallel.thread.number, um die Anzahl von Aufträgen zu begrenzen, die parallel ausgeführt werden. Der Standardwert ist 8.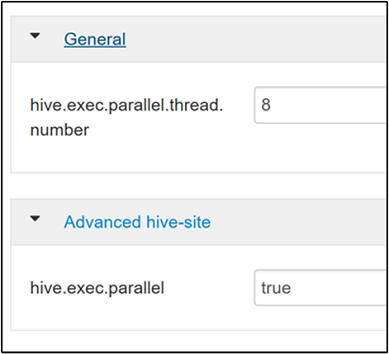
Aktivieren der Vektorisierung
Hive verarbeitet Daten zeilenweise. Bei der Vektorisierung wird Hive angewiesen, Daten in Blöcken von 1.024 Zeilen zu verarbeiten, anstatt jede Zeile einzeln. Die Vektorisierung gilt nur für das ORC-Dateiformat.
Navigieren Sie zum Aktivieren einer vektorisierten Abfrageausführung zur Hive-Registerkarte Configs (Konfigurationen), und suchen Sie nach dem Parameter
hive.vectorized.execution.enabled. Der Standardwert lautet für Hive 0.13.0 oder höher „true“.Legen Sie den Parameter
hive.vectorized.execution.reduce.enabledauf „true“ fest, um die vektorisierte Ausführung für die Reducerseite der Abfrage zu aktivieren. Der Standardwert ist „FALSE“.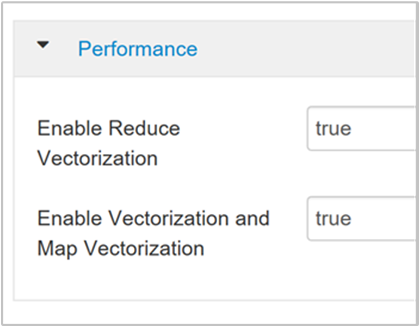
Aktivieren der kostenbasierten Optimierung
Standardmäßig wird für Hive eine Gruppe von Regeln befolgt, um einen optimalen Plan für die Abfrageausführung zu ermitteln. Die kostenbasierte Optimierung (Cost-based optimization, CBO) wertet mehrere Pläne aus, um eine Abfrage auszuführen. Jedem Plan werden Kosten zugewiesen. Anschließend wird der kostengünstigste Plan zum Ausführen einer Abfrage ermittelt.
Navigieren Sie zum Aktivieren der CBO zu Hive>Configs>Settings („Hive“ > „Konfigurationen“ > „Einstellungen“), suchen Sie nach Enable Cost Based Optimizer (Kostenbasierte Optimierung aktivieren), und schalten Sie dann die Umschaltfläche auf On (Ein) um.

Mit den folgenden zusätzlichen Konfigurationsparametern wird die Hive-Abfrageleistung erhöht, wenn CBO aktiviert ist:
hive.compute.query.using.statsBei der Einstellung „true“ nutzt Hive Statistiken, die im eigenen Metastore enthalten sind, um einfache Abfragen wie
count(*)zu beantworten.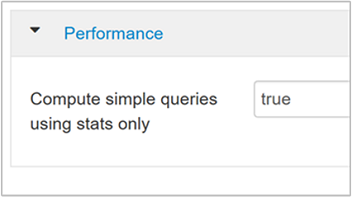
hive.stats.fetch.column.statsSpaltenstatistiken werden erstellt, wenn CBO aktiviert ist. Hive verwendet Spaltenstatistiken, die im Metastore gespeichert sind, um Abfragen zu optimieren. Das Abrufen von Spaltenstatistiken dauert für die einzelnen Spalten länger, wenn sehr viele Spalten vorhanden sind. Bei der Einstellung „false“ wird das Abrufen von Spaltenstatistiken aus dem Metastore deaktiviert.
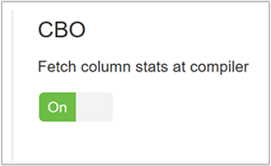
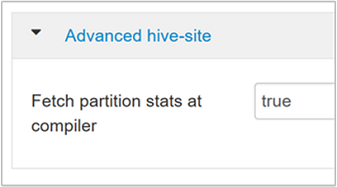
hive.stats.fetch.partition.statsEinfache Partitionsstatistiken, z.B. die Anzahl von Zeilen, Datengröße und Dateigröße, werden im Metastore gespeichert. Bei Festlegen auf TRUE werden die Partitionsstatistiken aus dem Metastore abgerufen. Falls FALSE wird die Dateigröße aus dem Dateisystem abgerufen. Die Anzahl von Zeilen wird aus dem Zeilenschema abgerufen.
Weitere Informationen finden Sie im Blogbeitrag zur kostenbasierten Hive-Optimierung im Blog zu Analytics in Azure.
Aktivieren der Zwischenkomprimierung
Für Mapper-Tasks werden Zwischendateien erstellt, die von den Reducer-Tasks verwendet werden. Bei der Zwischenkomprimierung wird die Größe der Zwischendatei reduziert.
Für Hadoop-Aufträge kommt es normalerweise zu E/A-Engpässen. Durch die Komprimierung der Daten können die E/A-Vorgänge und die gesamte Netzwerkübertragung beschleunigt werden.
Die verfügbaren Komprimierungstypen sind:
| Format | Tool | Algorithmus | Dateierweiterung | Teilbar? |
|---|---|---|---|---|
| GZip | GZip | VERKLEINERN | .gz |
Nein |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Ja |
| LZO | Lzop |
LZO | .lzo |
Ja, wenn indiziert |
| Snappy | – | Snappy | Snappy | Nein |
Hier gilt die folgende allgemeine Regel: Es ist wichtig, dass die Komprimierungsmethode teilbar ist, da andernfalls nur wenige Mapper erstellt werden. Wenn es sich bei den Eingabedaten um Text handelt, ist bzip2 die beste Option. Für das ORC-Format ist Snappy die schnellste Komprimierungsoption.
Navigieren Sie zum Aktivieren der Zwischenkomprimierung zur Hive-Registerkarte Configs (Konfigurationen), und legen Sie den Parameter
hive.exec.compress.intermediateauf „true“ fest. Der Standardwert ist „FALSE“.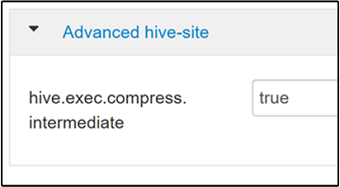
Hinweis
Wählen Sie zum Komprimieren von Zwischendateien auch dann einen Komprimierungscodec mit geringeren CPU-Kosten aus, wenn der Codec nicht über eine hohe Komprimierungsausgabe verfügt.
Fügen Sie zum Festlegen des Codecs für die Zwischenkomprimierung die benutzerdefinierte Eigenschaft
mapred.map.output.compression.codecder Dateihive-site.xmlodermapred-site.xmlhinzu.Gehen Sie wie folgt vor, um eine benutzerdefinierte Einstellung hinzuzufügen:
a. Navigieren Sie zu Hive>Configs>Advanced>Custom hive-site („Hive“ > „Erweitert“ > „Benutzerdefinierte Hive-Site“).
b. Wählen Sie unten im Bereich „Custom hive-site“ (Benutzerdefinierte Hive-Site) die Option Add Property (Eigenschaft hinzufügen) aus.
c. Geben Sie im Fenster „Add Property“ (Eigenschaft hinzufügen)
mapred.map.output.compression.codecals Schlüssel undorg.apache.hadoop.io.compress.SnappyCodecals Wert ein.d. Wählen Sie Hinzufügen aus.
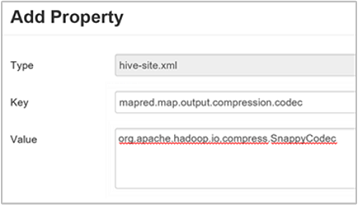
Bei dieser Einstellung wird die Zwischendatei per Snappy-Komprimierung verkleinert. Nach dem Hinzufügen der Eigenschaft wird sie im Bereich „Custom hive-site“ (Benutzerdefinierte Hive-Site) angezeigt.
Hinweis
Mit dieser Prozedur wird die Datei
$HADOOP_HOME/conf/hive-site.xmlgeändert.
Komprimieren der endgültigen Ausgabe
Die endgültige Hive-Ausgabe kann auch komprimiert werden.
Navigieren Sie zum Komprimieren der endgültigen Hive-Ausgabe zur Hive-Registerkarte Configs (Konfigurationen), und legen Sie den Parameter
hive.exec.compress.outputauf „true“ fest. Der Standardwert ist „FALSE“.Fügen Sie zum Auswählen des Codecs für die Ausgabekomprimierung die benutzerdefinierte Eigenschaft
mapred.output.compression.codecdem Bereich „Custom hive-site“ (Benutzerdefinierte Hive-Site) hinzu, wie in Schritt 3 des vorherigen Abschnitts beschrieben.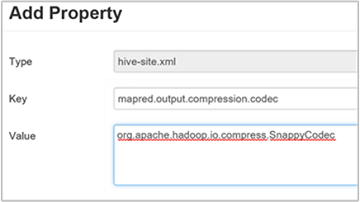
Aktivieren der spekulativen Ausführung
Bei der spekulativen Ausführung wird eine bestimmte Anzahl von doppelten Tasks gestartet, um den langsamsten Task-Tracker zu erkennen und in eine Sperrliste einzutragen. Durch Optimierung von einzelnen Taskergebnissen wird dabei gleichzeitig die allgemeine Auftragsausführung verbessert.
Die spekulative Ausführung sollte für MapReduce-Aufträge mit großen Eingabemengen und langer Ausführungsdauer nicht aktiviert werden.
Navigieren Sie zum Aktivieren der spekulativen Ausführung zur Hive-Registerkarte Configs (Konfigurationen), und legen Sie den Parameter
hive.mapred.reduce.tasks.speculative.executionauf „true“ fest. Der Standardwert ist „FALSE“.
Optimieren von dynamischen Partitionen
Hive ermöglicht die Erstellung von dynamischen Partitionen, wenn Datensätze in eine Tabelle eingefügt werden, ohne dass jede Partition einzeln vordefiniert werden muss. Diese Möglichkeit ist ein leistungsstarkes Feature. Sie kann jedoch zur Erstellung einer großen Anzahl von Partitionen führen. Auch eine große Anzahl von Dateien für jede Partition wird erstellt.
Damit Hive dynamische Partitionen nutzen kann, sollte der Wert des Parameters
hive.exec.dynamic.partitionauf „true“ (Standardeinstellung) festgelegt werden.Ändern Sie den Modus für dynamische Partitionen in strict. Im Modus „strict“ muss mindestens eine Partition statisch sein. Diese Einstellung verhindert, dass Abfragen ohne Partitionsfilter in der WHERE-Klausel enthalten sind. Mit strict werden also Abfragen verhindert, bei denen alle Partitionen gescannt werden. Navigieren Sie zur Hive-Registerkarte Configs (Konfigurationen), und legen Sie
hive.exec.dynamic.partition.modeauf strict fest. Der Standardwert lautet nonstrict.Ändern Sie den Parameter
hive.exec.max.dynamic.partitions, um die Anzahl von zu erstellenden dynamischen Partitionen zu begrenzen. Der Standardwert lautet 5000.Ändern Sie
hive.exec.max.dynamic.partitions.pernode, um die Gesamtzahl von dynamischen Partitionen pro Knoten zu begrenzen. Der Standardwert lautet 2000.
Aktivieren des lokalen Modus
Im lokalen Modus kann Hive alle Aufgaben eines Auftrags auf einem einzelnen Computer ausführen. Manchmal ist diese Ausführung auch in einem einzelnen Prozess möglich. Diese Einstellung verbessert die Abfrageleistung, wenn die Eingabedaten klein sind. Außerdem muss dazu das Starten von Tasks für Abfragen einen erheblichen Prozentsatz der gesamten Abfrageausführung einnehmen.
Fügen Sie zum Aktivieren des lokalen Modus den Parameter hive.exec.mode.local.auto dem Bereich „Custom hive-site“ (Benutzerdefinierte Hive-Site) hinzu. Dies wird in Schritt 3 des Abschnitts Aktivieren der Zwischenkomprimierung beschrieben.
Festlegen eines einzelnen MapReduce-Vorgangs (MultiGROUP BY)
Wenn diese Eigenschaft auf „true“ festgelegt ist, generiert eine MultiGROUP BY-Abfrage mit allgemeinen „group-by“-Schlüsseln einen einzelnen MapReduce-Auftrag.
Fügen Sie zum Aktivieren dieses Verhaltens den Parameter hive.multigroupby.singlereducer dem Bereich „Custom hive-site“ (Benutzerdefinierte Hive-Site) hinzu. Dies wird in Schritt 3 des Abschnitts Aktivieren der Zwischenkomprimierung beschrieben.
Zusätzliche Hive-Optimierungen
In den folgenden Abschnitten werden zusätzliche Hive-bezogene Optimierungen beschrieben, die Sie festlegen können.
Join-Optimierungen
Der Join-Standardtyp in Hive ist shuffle join. In Hive lesen spezielle Mapper die Eingabe und geben ein Join-Schlüssel-Wert-Paar für eine Zwischendatei aus. Hadoop sortiert diese Paare in einem so genannten Shuffle-Schritt und führt sie zusammen. Dieser Shuffle-Schritt ist kostenintensiv. Wenn Sie basierend auf Ihren Daten die richtige Join-Auswahl treffen, kann die Leistung erheblich verbessert werden.
| Join-Typ | Wenn | Vorgehensweise | Hive-Einstellungen | Kommentare |
|---|---|---|---|---|
| Shuffle Join |
|
|
Keine nennenswerte Hive-Einstellung erforderlich | Funktioniert immer |
| Map Join |
|
|
hive.auto.convert.join=true |
Schnell, aber begrenzt |
| Sort/Merge-Bucket | Wenn für beide Tabellen Folgendes gilt:
|
Für jeden Prozess gilt:
|
hive.auto.convert.sortmerge.join=true |
Effizient |
Optimierungen des Ausführungsmoduls
Weitere Empfehlungen zum Optimieren des Hive-Ausführungsmoduls:
| Einstellung | Empfohlen | HDInsight-Standard |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
true = sicherer, langsamer; false = schneller | false |
tez.am.resource.memory.mb |
Oberer Grenzwert von 4 GB für die meisten Fälle geeignet | Automatisch optimiert |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20.000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40.000+ | 20000 |