Interactive Query in Azure HDInsight
Interactive Query (auch Apache Hive LLAP oder Low Latency Analytical Processing genannt) ist ein Azure HDInsight-Clustertyp. Interactive Query unterstützt speicherinternes Zwischenspeichern, wodurch Apache Hive-Abfragen schneller und viel interaktiver werden. Kunden verwenden Interactive Query, um Daten, die in Azure Storage und Azure Data Lake Storage gespeichert sind, äußerst schnell abzufragen. Interactive Query erleichtert Entwicklern und Data Scientists die Arbeit mit Big Data mit den BI-Tools, die sie am meisten lieben. HDInsight Interactive Query unterstützt verschiedene Tools für den mühelosen Zugriff auf Big Data.
Ein Interactive Query-Cluster unterscheidet sich von einem Apache Hadoop-Cluster. Er enthält nur den Hive-Dienst.
Sie können im Interactive Query-Cluster nur über die Apache Ambari-Hive-Ansicht, Beeline und den Microsoft Hive Open Database Connectivity-Treiber (Hive ODBC) auf den Hive-Dienst zugreifen. Sie können nicht über die Hive-Konsole, Templeton, die klassische Azure-Befehlszeilenschnittstelle oder Azure PowerShell darauf zugreifen.
Erstellen eines Interactive Query-Clusters
Informationen zum Erstellen eines HDInsight-Clusters finden Sie unter Einrichten von Clustern in HDInsight mit Hadoop, Spark, Kafka usw. Wählen Sie den Clustertyp „Interactive Query“ aus.
Wichtig
Die minimale Hauptknotengröße für interaktive Abfragecluster ist Standard_D13_v2. Weitere Informationen finden Sie unter Azure Virtual Machine Dimensionierungscharts.
Ausführen von Apache Hive-Abfragen über Interactive Query
Um Hive-Abfragen auszuführen, können Sie folgende Optionen nutzen:
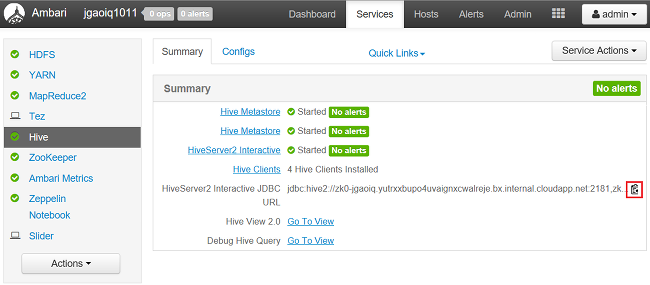
So suchen Sie die Verbindungszeichenfolge für die Java Database Connectivity (JDBC):
Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary, wobeiCLUSTERNAMEder Name Ihres Clusters ist.Wählen Sie das Symbol für die Zwischenablage zum Kopieren der URL aus:
Nächste Schritte
- Erfahren Sie, wie Sie Interactive Query-Cluster in HDInsight erstellen.
- Erfahren Sie, wie Sie Big Data mit Power BI in Azure HDInsight visualisieren.
- Erfahren Sie, wie Sie Apache Zeppelin zum Ausführen von Apache Hive-Abfragen in Azure HDInsight verwenden.